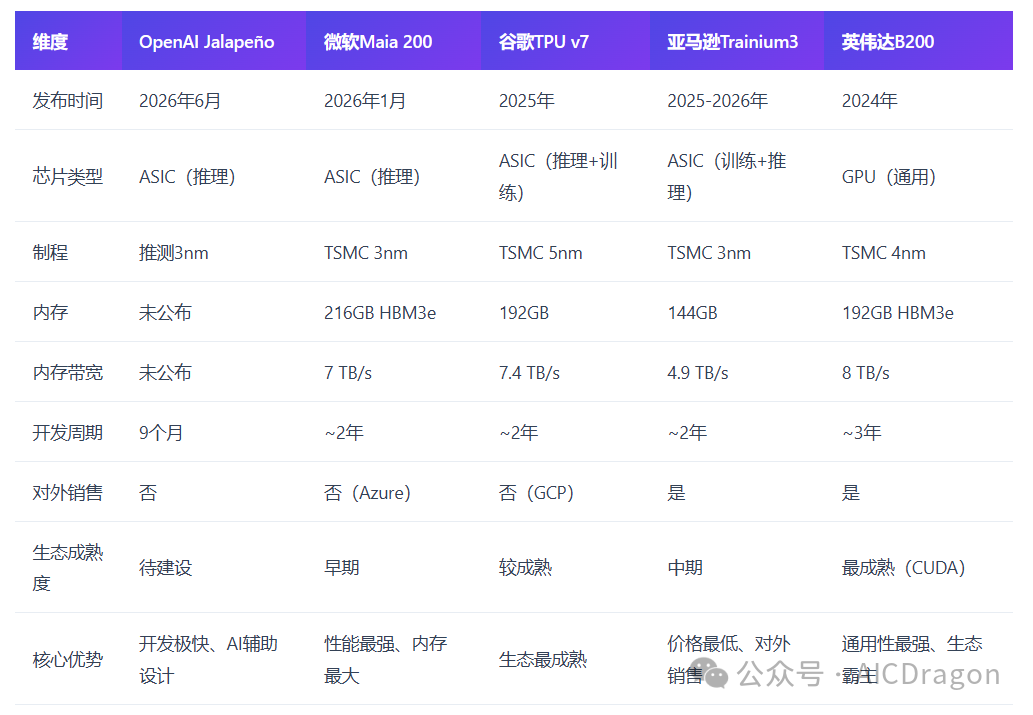
6月24日,OpenAI联合Broadcom(博通)和Celestica,正式发布了首款自研AI推理加速器------Jalapeño。

这不是一个实验项目。工程样片已经在实验室以目标频率和功耗跑着ML负载,包括GPT‑5.3‑Codex‑Spark。2026年底开始部署,而且是千兆瓦级数据中心、多代芯片平台的第一代。
从设计到流片,9个月。OpenAI说这是"高性能先进半导体领域有史以来最快的ASIC开发周期"。这个速度本身就是一个信号------AI设计芯片,不再是PPT上的概念了。
本文信息主要来源:OpenAI官网6月24日《OpenAI and Broadcom unveil LLM-optimized inference chip》、OpenAI 6月26日《Previewing GPT-5.6 Sol》、Cadence官网公开产品资料,以及IEEE/ACM等学术期刊中关于AI驱动EDA的相关研究。
一、Jalapeño是什么
Jalapeño的定位非常明确:LLM推理专用加速器。
不是从通用GPU改装过来的。不是把H100的架构修修改改。OpenAI原话是"blank-slate design"------白纸一张,从零开始,围绕LLM推理的需求从头设计。
几个关键要点:
全栈协同设计。 OpenAI不是只画了个芯片架构图然后丢给Broadcom制造。他们从芯片架构、kernels、内存系统、网络、调度、部署系统到产品体验,每一层都在自己手里。因为全栈都控,每一层都可以围绕同一个目标优化------让模型更快、更可靠、更便宜。这正是"全栈优势"的核心逻辑。
性能远超当前SOTA。 OpenAI说Jalapeño的每瓦性能"substantially better than current state-of-the-art"。具体数字还没公布(承诺未来几个月发布详细技术报告),但从架构描述来看------减少数据移动、平衡计算/内存/网络资源、让实际利用率接近理论峰值------这指向的是系统级效率的质变,而不仅仅是晶体管密度或时钟频率的线性提升。
通用性。 虽然是为OpenAI自家模型优化的,但Jalapeño的设计考虑了"当前和未来的所有LLM"。它不是只能跑GPT的特殊硬件。这一点很重要------如果Jalapeño生态能做起来,它可能成为整个LLM推理市场的基础设施,而不只是OpenAI的内部工具。
千兆瓦级部署。 Broadcom CEO Hock Tan说得很直白:2026年开始,与微软和其他合作伙伴一起部署千兆瓦级数据中心。这是一个产业规模的概念------不是几百台服务器,而是足以改变区域电力基础设施规模的算力集群。
二、9个月流片意味着什么
高性能芯片从设计到流片通常需要18-24个月,甚至更长。Jalapeño只用了9个月。
OpenAI把这种速度归因于三个因素:与Broadcom的深度软硬件协同开发、Broadcom的硅实现专长,以及------用OpenAI自己的模型加速了部分设计和优化流程。
这是一个闭环:"同样的模型在服务用户,也在帮助改进运行未来模型的基础设施。"
但更深层的含义是------这个9个月不是靠堆人堆出来的,而是靠方法论变革实现的。传统的芯片设计流程是串行的:架构设计→RTL编码→功能验证→物理设计→时序收敛→流片。每一步都可能因为发现问题而回退到前一步,迭代周期长。
AI辅助设计改变了这个范式。以Cadence的Cerebrus AI平台为例,它使用强化学习技术,可以同时探索数百种布局布线方案,在数小时内找到人类工程师可能需要数周才能优化的PPA(功耗、性能、面积)配置。Synopsys的DSO.ai也是类似的逻辑------用AI驱动的搜索替代人工试错。
当芯片设计的核心循环从"设计→仿真→人工分析→调整→再仿真"变成"设计→AI自动探索→AI自动优化→验证",整个迭代速度被压缩了不止一个数量级。
Jalapeño的9个月,就是这种范式的一个标志性案例。
三、AI设计芯片:从辅助工具到设计主体
Cadence和Synopsys这两家EDA巨头在过去几年里,完成了一次静默但深刻的转型。
Cadence在2021年推出了Cerebrus AI,最初聚焦于数字IC实现流程的自动化优化。到了2024-2025年,AI能力已经渗透到Cadence的全流程------从JedAI(大数据分析平台)到Verisium(AI驱动验证),再到Allegro X AI(PCB设计)。最新发布的Cadence Reality Digital Twin更是把AI拓展到了数据中心能效优化。
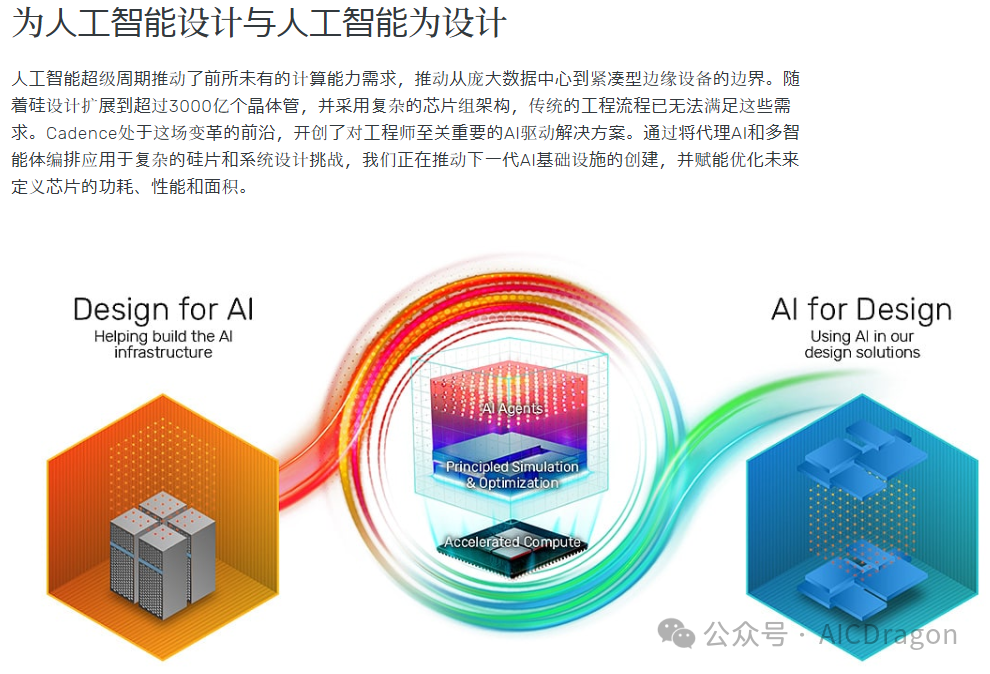
Synopsys的路径类似。DSO.ai在2020年首次商用后,迅速扩展为一个AI驱动的全流程套件------VSO.ai(验证)、TSO.ai(测试),覆盖了芯片设计从架构探索到硅后验证的完整闭环。

一个关键转折点是2024-2025年生成式AI进入EDA领域。传统的AI EDA工具更多是"优化器"------它们在给定约束下寻找最优解。但生成式AI让工具开始具备了"创造"能力:根据自然语言描述生成RTL代码、自动创建测试用例、甚至提出架构替代方案。
学术领域也在快速跟进。IEEE Transactions on CAD、DAC(设计自动化会议)和ICCAD等顶级期刊和会议上,AI驱动的EDA研究已经成为最大的热点。从Google在2021年发表的《A Graph Placement Methodology for Fast Chip Design》(用强化学习做芯片布局规划,登上Nature封面),到近年来涌现的大规模语言模型辅助RTL生成、基于图神经网络的时序预测,AI正在从芯片设计的"辅助轮"变成"发动机"。
Jalapeño的意义在于------它是这个趋势的集大成者和证明者。9个月完成高性能ASIC的设计和流片,这是以前不可想象的速度。如果AI能把芯片设计周期压缩50%以上,整个半导体行业的创新速度都将被重写。
四、为什么OpenAI要自己做芯片
这个问题的答案有三层。
第一层,成本。英伟达GPU的毛利率长期在65%-70%左右。对于OpenAI这种级别的算力消费者,自研芯片带来的单卡成本下降是巨大的。而且Jalapeño是为LLM推理专门优化的------不需要GPU上那些对LLM没用的图形处理单元,光是"去除冗余"就能带来可观的面积和功耗节省。
第二层,控制力。依赖第三方芯片意味着你的产品路线图受制于别人的芯片路线图。当OpenAI想要部署千兆瓦级的数据中心、想要把GPT-5.6 Sol的推理成本降到让每个学生都负担得起的时候,依赖英伟达的供货节奏和定价策略是一种战略脆弱性。自研芯片把这条命脉拿回到了自己手里。
第三层,也是最重要的:飞轮效应。OpenAI已经展示了一个完整的正反馈闭环------更好的模型设计更好的芯片,更好的芯片让训练和推理更高效,更高效的算力让更好的模型成为可能,更好的模型吸引更多用户和收入,更多收入投入到下一代基础设施。Jalapeño就是这个飞轮的关键齿轮。
五、对半导体行业的冲击
Jalapeño的发布对整个半导体产业链都有深远影响。
对英伟达而言,最大的客户变成了竞争对手。虽然短期内OpenAI仍然会大量采购GPU用于训练(Jalapeño目前只做推理),但推理市场是更大的那块蛋糕。如果Jalapeño的每瓦性能真的"远超当前SOTA",它可能从"开源节流"变成"替代方案"。
对Broadcom而言,这是一次战略转型的标志。Broadcom传统上不做标准化的AI加速器芯片,而是凭借其ASIC定制能力服务超大规模客户。Jalapeño证明了这个模式对AI时代同样适用------而且可能比"买现成芯片"更有竞争力。
对整个行业而言,Jalapeño验证了"AI设计芯片"的商业可行性。当9个月流片不再是个例而是新常态,芯片设计的门槛在降低、迭代速度在加快、创新周期在缩短。这对Fabless芯片设计公司(包括中国的半导体创业公司)既是机遇也是挑战------机遇在于可以用更少的工程师做更多的芯片,挑战在于如果跟不上这个速度就会被淘汰。
六、计算驱动的经济
OpenAI总裁Greg Brockman在发布会上说了一句值得深味的话:"世界正在走向一个计算驱动的经济(compute-powered economy)。"
这不是口号。当AI模型的能力以指数级增长、推理成本以指数级下降、芯片设计周期被压缩到9个月时,"计算"正在变成一种和水、电一样的基础设施。而控制基础设施的人,就控制着经济的命脉。
Jalapeño的多代路线图、千兆瓦级数据中心、博通的硅实现能力和Celestica的系统集成专长------这条产业链加上OpenAI的全栈控制力,正在构筑一个"AI基础设施帝国"。
英伟达的护城河依然很深------CUDA生态的锁定效应、训练侧的绝对优势、多年的架构迭代经验都不是短时间内能追上的。但Jalapeño的出现意味着:围墙已经开始出现裂缝。
更重要的是,如果AI真的能把芯片设计周期从18-24个月压缩到9个月甚至更短,那么未来芯片的迭代速度将不再是半导体行业的瓶颈。"用更快的AI设计更快的芯片,用更快的芯片跑更快的AI"------这个飞轮一旦转起来,算力成本的下降速度可能会超出所有人的预期。
而这,才是Jalapeño背后最值得关注的故事。
参考资料
1 OpenAI, "OpenAI and Broadcom unveil LLM-optimized inference chip," Jun. 24, 2026. Online. Available: https://openai.com/index/openai-broadcom-jalapeno-inference-chip/
2 OpenAI, "Previewing GPT-5.6 Sol: a next-generation model," Jun. 26, 2026. Online. Available: https://openai.com/index/previewing-gpt-5-6-sol/
3 Cadence Design Systems, "Cadence Cerebrus AI-Driven Chip Design," Online. Available: https://www.cadence.com/en_US/home/tools/digital-design-and-signoff/cerebrus.html
4 Cadence Design Systems, "Cadence JedAI Platform," Online. Available: https://www.cadence.com/en_US/home/tools/digital-design-and-signoff/jedai-platform.html
5 Synopsys, "Synopsys DSO.ai: AI-Driven Design Space Optimization," Online. Available: https://www.synopsys.com/implementation-and-signoff/ml-ai-solutions/dso-ai.html
6 A. Mirhoseini et al., "A Graph Placement Methodology for Fast Chip Design," Nature, vol. 594, pp. 207--212, Jun. 2021.
7 Broadcom Inc., "Broadcom Tomahawk Networking Silicon," Online. Available: https://www.broadcom.com/products/ethernet-connectivity/switching/strataxgs