原文:Training Your Own LLM using privateGPT
作者:Wei-Meng Lee
了解如何在不向提供者公开私有数据的情况下训练自己的语言模型
使用公共AI服务(如OpenAI的ChatGPT)的主要问题之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然是考虑采用AI技术的公司最担心的问题。
很多时候,您希望创建自己的语言模型,该模型是根据您的数据集(例如销售见解,客户反馈等)进行训练的,但同时您又不希望将所有这些敏感数据暴露给OpenAI等AI提供商。因此,理想的方法是在本地训练自己的LLM(大语言模型),而不需要将数据上传到公网。
在本文中,我将向您展示如何使用一个名为privateGPT的开源项目来利用LLM,以便它可以根据您的自定义训练数据回答问题(如ChatGPT),而不会牺牲数据的隐私性。
值得注意的是,privateGPT目前还处于概念验证阶段,还没有准备好投入生产。
下载privateGPT
要尝试privateGPT,您可以使用以下链接访问GitHub: https://github.com/imartinez/privateGPT.
您可以通过点击Code | download ZIP按钮下载repository:
或者,如果你的系统上安装了git,在Terminal中使用以下命令克隆repository:
|-----------|-------------------------------------------------------------|
| 1 | $ git clone https://github.com/imartinez/privateGPT |
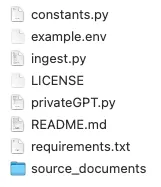
无论哪种情况,一旦repository下载到您的计算机上,privateGPT目录应该有以下文件和文件夹:
安装所需的Python Packages
privateGPT使用许多Python包。它们被封装在requirements.txt文件中:
|------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 | langchain==0.0.171 pygpt4all==1.1.0 chromadb==0.3.23 llama-cpp-python==0.1.50 urllib3==2.0.2 pdfminer.six==20221105 python-dotenv==1.0.0 unstructured==0.6.6 extract-msg==0.41.1 tabulate==0.9.0 pandoc==2.3 pypandoc==1.11 |
最方便的方法就是通过 pip/conda:
|-----------------|--------------------------------------------------------------------------------------------------|
| 1 2 3 4 | $ cd privateGPT $ pip install -r requirements.txt // $ conda install -r requirements.txt |
根据我的经验,执行上述安装时,可能不一定会安装一些必需的Python包。稍后,当您尝试运行摄取.py或privateGPT.py文件时,您就会知道这一点。在这种情况下,只需单独安装丢失的包。
编辑环境(Environment)配置文件
这个example.env文件包含privateGPT使用的几个设置。其内容如下:
|-------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 | PERSIST_DIRECTORY=db MODEL_TYPE=GPT4All MODEL_PATH=models/ggml-gpt4all-j-v1.3-groovy.bin EMBEDDINGS_MODEL_NAME=all-MiniLM-L6-v2 MODEL_N_CTX=1000 |
- PERSIST_DIRECTORY---在加载和处理文档之后将保存本地矢量存储的目录
- MODEL_TYPE---您正在使用的模型的类型。在这里,它被设置为GPT4All(由OpenAI提供的ChatGPT的免费开源替代品).
- MODEL_PATH---LLM所在的路径。这里它被设置为models目录,使用的模型是ggml-gpt4all-j-v1.3-groovy.bin(您将在下一节中了解到在哪里下载这个模型)
- EMBEDDINGS_MODEL_NAME------这指的是转换器模型的名称。这里它被设置为all-MiniLM-L6-v2,它将句子和段落映射到384维的密集向量空间,可以用于聚类或语义搜索等任务。
- MODEL_N_CTX -嵌入模型和LLM模型的最大令牌限制
将example.env 重命名为 .env.
将这个文件变成隐藏模式
下载Model(模型)
为了使privateGPT正常运行起来,它需要预先训练模型(就是LLM)。由于privateGPT使用GPT4All,您可以从https://gpt4all.io/index.html下载LLM。
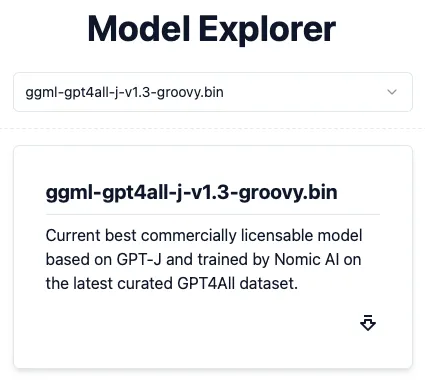
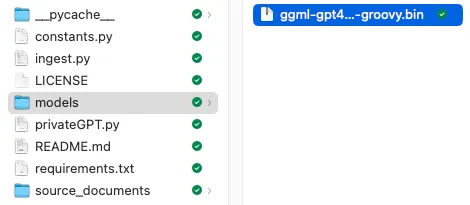
因为默认的环境文件指定了ggml-gpt4all-j-v1.3-groovy.bin LLM,所以下载第一个模型,然后在privateGPT 文件夹中创建一个名为models 的新文件夹。将ggml-gpt4all-j-v1.3-groovy.bin 文件放入models文件夹中:
数据预处理
如果你查看一下ingest.py文件,你会注意到下面的代码片段:
|------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | ".csv": (CSVLoader, {}), # ".docx": (Docx2txtLoader, {}), ".doc": (UnstructuredWordDocumentLoader, {}), ".docx": (UnstructuredWordDocumentLoader, {}), ".enex": (EverNoteLoader, {}), ".eml": (UnstructuredEmailLoader, {}), ".epub": (UnstructuredEPubLoader, {}), ".html": (UnstructuredHTMLLoader, {}), ".md": (UnstructuredMarkdownLoader, {}), ".odt": (UnstructuredODTLoader, {}), ".pdf": (PDFMinerLoader, {}), ".ppt": (UnstructuredPowerPointLoader, {}), ".pptx": (UnstructuredPowerPointLoader, {}), ".txt": (TextLoader, {"encoding": "utf8"}), |
从这个文件上我们可以看到privateGPT支持以下数据文档格式:
.csv: CSV.doc: Word文档.docx: Word文档.enex: EverNote.eml: Email.epub: EPub.html: HTML File.md: Markdown.odt: Open Document Text.pdf: PDF.ppt: PPT.pptx: PPTX.txt: Text (UTF-8)
每种类型的文档都使用各自的加载程序来分别加载。例如,你使用UnstructuredWordDocumentLoader类来加载**.doc和.docx** 这些Word文档。
默认情况下,privateGPT附带位于source_documents 文件夹中的state_of_the_union.txt 文件。我将删除它,并用一个名为Singapore.pdf的文档替换它。
这个文档创建的内容来自于:https://en.wikipedia.org/wiki/Singapore。您可以通过点击 Tools | Download as PDF 从维基百科下载任何页面:
您可以将privateGPT 支持的任何文档放入source_documents文件夹中。在本文的例子中,我只放了一个文档。
为文档创建Embeddings
一旦数据文档就位,就可以为文档做embedding了。
创建embedding是指为单词、句子或其他文本单元生成向量表示的过程。这些向量表示捕获关于文本的语义和句法信息,使机器能够更有效地理解和处理自然语言。
在Terminal(终端)中输入以下内容: (ingest.py 文件在privateGPT文件夹中)
|-----------|----------------------------|
| 1 | $ python ingest.py |
根据您使用的机器和您放入source_documents文件夹中的文档数量,嵌入处理可能需要相当长的时间才能完成。
完成后,您将看到如下内容:
|-----------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 | Loading documents from source_documents Loaded 1 documents from source_documents Split into 692 chunks of text (max. 500 characters each) Using embedded DuckDB with persistence: data will be stored in: db |
Embedding文件保存在db 文件夹中,格式为Chroma db:
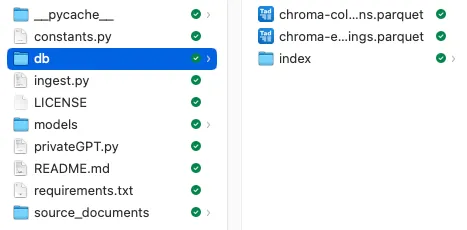
Chroma 是一个开源的向量数据库。
开始提问题吧
您现在可以提问了!
在Terminal中输入以下命令:
|-----------|--------------------------------|
| 1 | $ python privateGPT.py |
加载模型需要一段时间。在此过程中,您将看到以下内容:
|---------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | Using embedded DuckDB with persistence: data will be stored in: db gptj_model_load: loading model from 'models/ggml-gpt4all-j-v1.3-groovy.bin' - please wait ... gptj_model_load: n_vocab = 50400 gptj_model_load: n_ctx = 2048 gptj_model_load: n_embd = 4096 gptj_model_load: n_head = 16 gptj_model_load: n_layer = 28 gptj_model_load: n_rot = 64 gptj_model_load: f16 = 2 gptj_model_load: ggml ctx size = 4505.45 MB gptj_model_load: memory_size = 896.00 MB, n_mem = 57344 gptj_model_load: ................................... done gptj_model_load: model size = 3609.38 MB / num tensors = 285 Enter a query: |
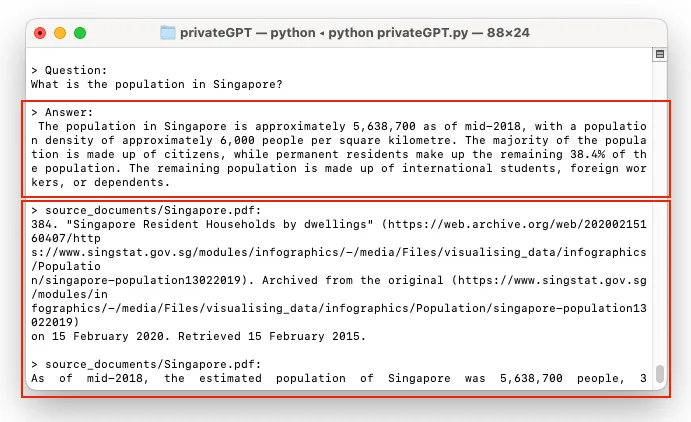
At the prompt, you can type in your question. I asked: "*What is the population in Singapore?*". It took privateGPT quite a while to come up with the answer. Once it managed to find an answer, it give you the answer and cited the source for the answer:
在Enter a query:提示符后面,你可以输入你的问题。问:"新加坡的人口是多少?"。privateGPT可能需要花很长时间才想出了答案。一旦它找到了答案,它就会给出答案并引用答案的来源:
你可以继续问后续的问题:
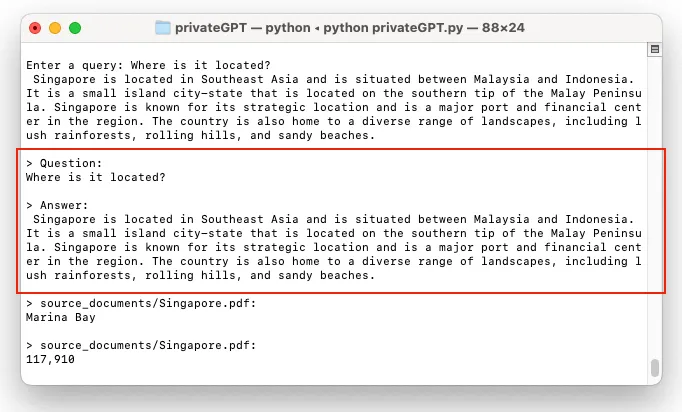
总结
虽然privateGPT目前还处于概念验证阶段,但它看起来很有希望,然而,它还没有准备好投入生产。这里有几个问题:
- 推理缓慢。执行文本嵌入需要一段时间,但这是可以接受的,因为这是一次性的过程。然而,推理很慢,特别是在较慢的机器上。我用的是32GB内存的M1 Mac电脑,仍然花了一段时间才得出答案。
- 占用内存。privateGPT使用大量内存,在问了一两个问题后,我将得到内存不足的错误,如下所示:
segmentation fault python privateGPT.py. /Users/weimenglee/miniforge3/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown. warnings.warn('resource_tracker: There appear to be %d '
在privateGPT的作者修复上述两个问题之前,privateGPT仍然是一个实验,以了解如何在不将私有数据暴露给云的情况下训练LLM。