开启tensorboard
在terminal中输入tensorboard --logdir=文件名 文件名中不能含有空格
c
tensorboard --logdir=logs --port=6007#将端口调整为6007
c
tensorboard --logdir=logs --port 0 自动分配一个端口,成功访问打开的时候如果发现没数据可以把logs换成文件夹的绝对路径
打开时发现有多条线的检查一下是不是文件夹下面有多个文件
c
def add_scalar(
self,
tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False,
):scalar_value (float或string/blobname):要保存的值,也就是x轴
global_step (int):记录的全局步长值,也就是y轴
标签(label)、值(value)和步数(step)。
在这个例子中,循环从0到99,对于每个i值,它会将两个值传递给add_scalar方法。第一个值是2i,第二个值是i。这意味着在TensorBoard中,我们会有一个以步数i为x轴、以2i为y轴的数据点。
writer中写入一些新的事件,他也计入了上一个事件当中,导致图像错乱
例如,先写入
c
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter('logs')#创建了一个用于记录训练过程的 SummaryWriter 对象,并指定了日志文件的保存路径为 'logs'
for i in range(100):
writer.add_scalar('y=2x',2*i,i)
writer.close()不改变名称再写入
c
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter('logs')#创建了一个用于记录训练过程的 SummaryWriter 对象,并指定了日志文件的保存路径为 'logs'
for i in range(100):
writer.add_scalar('y=2x',3*i,i)
writer.close()你就会得到一幅错乱的图像
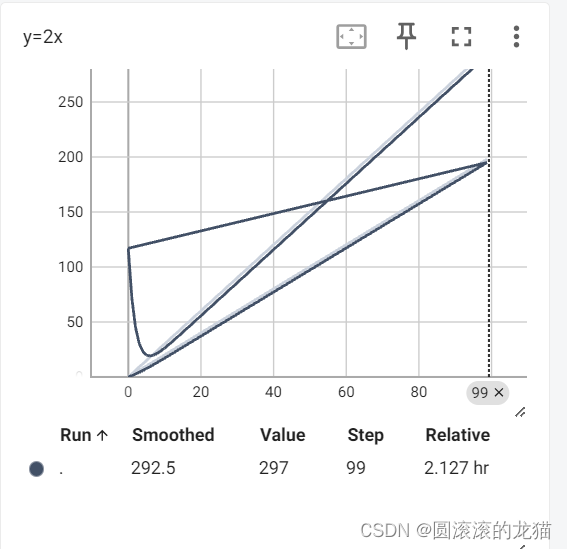
这个时候建议把多的文件删了,然后重跑
这个图像是用来看训练效果的
c
def add_image(
self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"
):这个函数在官方给出的只有
c
img_tensor (torch.Tensor, numpy.ndarray, or string/blobname): Image data以上几种类型可以使用
因此我用PIL读取数据后,使用numpy.array()函数转化类型
c
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter('logs')
image_path=r'D:\python practice demo\pythonProject4\hymenoptera_data\train\ants\0013035.jpg'
img_PIL=Image.open(image_path)
img_array=np.array(img_PIL)
writer.add_image('test',img_array,1,dataformats='HWC')#表示这是三通道
for i in range(100):
writer.add_scalar('y=x',i,i)
writer.close()
torchvision中的transforms主要是对图片进行一些变换。
tranforms对应 tranforms.py 文件,里面定义了很多类,输入一个图片对象,返回经过处理的图片对象。
三、常见的Transforms
常用的输入图片对象的数据类型
PIL : Image.open()
tensor : ToTensor()
ndarrays: cv.imread()
常用的Transform有:
ToTensor() :将图片对象类型转为 tensor
Normalize() :对图像像素进行归一化计算
Resize():重新设置 PIL Image的大小,返回也是PIL Image格式
Compose(): 输入为 transforms类型参数的列表,即
c
Compose([transforms参数1, transforms参数2], ...)目的是将几个 transforms操作打包成一个,比如要先进行大小调整,然后进行归一化计算,返回tensor类型,则可以将 ToTensor、Normalize、Resize,按操作顺序输入到Compose中。