大家好,我是白晨,一个不是很能熬夜,但是也想日更的人。如果喜欢这篇文章,点个赞 👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪

文章目录
- [ziplist 与 listpack](#ziplist 与 listpack)
-
- ziplist
-
- [ziplist 的结构](#ziplist 的结构)
- [ziplist 节点结构](#ziplist 节点结构)
- [ziplist 结构解析图](#ziplist 结构解析图)
- [ziplst 的劣势](#ziplst 的劣势)
- listpack
-
- [listpack 的结构](#listpack 的结构)
- [listpack 元素的结构](#listpack 元素的结构)
- [listpack 结构解析图](#listpack 结构解析图)
- [listpack 与 ziplist 结构对比](#listpack 与 ziplist 结构对比)
- [listpack 源码解读](#listpack 源码解读)
- [listpack 的遍历](#listpack 的遍历)
-
- [listpack 中的元素是怎么找到下一个元素的?](#listpack 中的元素是怎么找到下一个元素的?)
- [listpack 的优势](#listpack 的优势)
- 总结
ziplist 与 listpack
ziplist
ziplist 是一种以字节数组形式存在的紧凑数据结构,主要用于存储小型列表。它通过减少内存占用,优化存储空间,提高数据访问的效率。ziplist 适用于元素数量较少且不经常变动的场景。
ziplist 的结构
一个 ziplist 由以下几个部分组成:
- zlbytes :
ziplist的总字节数,4 个字节。 - zltail:到列表尾节点的偏移量,4 个字节。
- zllen :
ziplist中包含的节点数量,2 个字节。 - entry :实际存储的节点,节点数量根据
zllen决定。 - zlend :特殊标记,标识
ziplist的结束,1 个字节,值为 0xFF。
ziplist 节点结构
每个节点简单可以看作三部分组成(具体的实现见下面源码):
- prevlen :前一个节点的长度,用于快速向后遍历,1 或 5 个字节。
- 如果前一个
entry占用字节数小于 254,那么prevlen只用 1 个字节来表示就足够了。 - 如果前一个
entry占用字节数大于等于254,那么prevlen就用 5 个字节来表示,其中第 1 个字节的值是254(作为这种情况的标记),后面 4 个字节存储一个整型值来表示前一个entry的占用字节数。
- 如果前一个
- encoding:当前节点的编码方式,1 个字节。
- entry-data:实际存储的内容,根据编码方式不同,长度可变。

源码如下:
c
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;ziplist 结构解析图

ziplst 的劣势
- 连锁更新
由于
ziplist中的元素存储了上一个元素的长度,当极端情况,插入了一个大于等于254字节的节点,后面的节点一开始长度都为253字节,此时第二个节点的prevlen要扩展为为5个字节,这样会导致第二个节点也更新到254字节以上,后面的节点也要进行上面的更新,直到最后一个节点。
- 紧凑性不足
虽然
ziplist使用紧凑的编码方式存储数据,但它的实现相对复杂,编码和解码的过程需要更多的计算。listpack通过改进的编码方式,在保证紧凑性的同时,简化了实现,提高了操作效率。
- 操作性能不高
listpack对插入和删除操作进行了优化,尤其是在处理大数据量的场景下,相比ziplist有显著的性能提升。其内存布局和操作逻辑使得频繁的插入和删除操作不会导致严重的性能退化。
- 逻辑复杂,维护性不高
listpack的代码实现相对ziplist更为简洁和易于维护。ziplist的实现因为其复杂的编码和内存管理逻辑,导致维护和调试难度较大。而listpack通过更合理的结构设计,减少了代码复杂度,使得维护更为容易。
listpack
在Redis 7之前,ziplist是一种常用的数据结构,用于实现压缩列表和哈希表中的小型数据。然而,随着Redis的发展,ziplist逐渐被listpack取代。listpack是一种更新、更高效的数据存储结构,专为优化内存使用和提高性能而设计。
listpack是一个紧凑的、连续的内存块,用于存储一组小的字符串或整数 。它的设计目标是通过高效的内存布局和紧凑的编码格式,最大限度地减少内存占用。与ziplist相比,listpack在存储密度和访问效率上都有显著提升。
listpack 的结构
一个listpack的基本结构如下:
- Total Bytes :表示整个
listpack的总字节数(包括自身)。 - Number of Elements :表示
listpack中元素的数量。 - Entry 1, Entry 2, ... Entry N:存储的每个元素,可以是字符串或整数。
- End Byte:结束标志,固定为0xFF。
listpack 元素的结构
- encoding-type :定义该元素的编码类型,会对不同长度的整数和字符串进行编码。
- element-data:实际存放的数据。
- element-tot-len:整个元素的长度,包含encoding + data的长度,用于反向遍历。
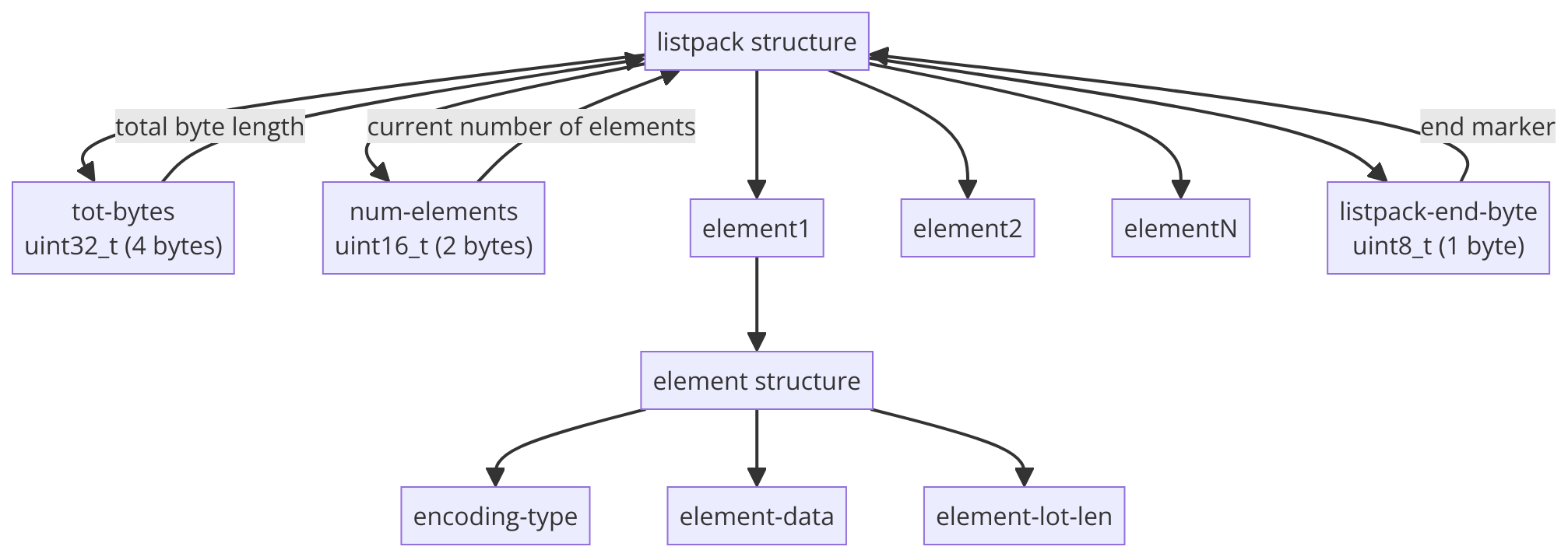
listpack 结构解析图

listpack 与 ziplist 结构对比

listpack 源码解读
为了更深入地理解listpack,我们来看一些关键的源码片段。
初始化 listpack
创建一个新的空的listpack,代码如下:
c
#define LP_HDR_SIZE 6 /* 32 bit total len + 16 bit number of elements. */
/* Create a new, empty listpack. */
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
/* Set the total number of bytes the listpack is composed of. */
void lpSetTotalBytes(unsigned char *lp, uint32_t total_bytes) {
memcpy(lp, &total_bytes, sizeof(total_bytes));
}
/* Set the number of elements inside the listpack. */
void lpSetNumElements(unsigned char *lp, uint16_t num_elements) {
memcpy(lp + sizeof(uint32_t), &num_elements, sizeof(num_elements));
}以上代码展示了listpack的初始化过程:
lp_malloc分配内存,大小为头部加上一个结束标志字节。lpSetTotalBytes设置listpack的总字节数。lpSetNumElements设置listpack中的元素数量为0。- 在
listpack末尾添加结束标志(0xFF)。
编码整数
整数的编码方式取决于其值的大小。
listpack 采用多种编码方式来存储不同范围的整数,通过灵活的编码策略,使得数据存储更为紧凑。具体的整数编码规则如下:
-
单字节整数:
- 范围:0 到 127
- 编码方式:1个字节,直接存储整数值
- 示例:整数5编码为0x05
这种编码方式非常简单高效,因为它直接将数值存储在一个字节中,没有额外的开销。
-
13位整数:
- 范围:-4096 到 4095
- 编码方式 :2个字节
- 第一个字节:高2位固定为
0xC0,其余6位为高位数据 - 第二个字节:存储剩余的8位数据
- 第一个字节:高2位固定为
- 示例:整数2048编码为0xC8 0x00
对于范围更广的整数,使用2字节编码可以有效减少存储空间的浪费。
-
16位整数:
- 范围:-32768 到 32767
- 编码方式 :3个字节
- 第一个字节固定为
0xF1 - 后两个字节存储实际整数值(采用小端序)
- 第一个字节固定为
- 示例:整数10000编码为0xF1 0x10 0x27
使用3字节编码,可以存储更大的正负整数,适合需要较大范围数值的应用场景。
-
24位整数:
- 范围:-8388608 到 8388607
- 编码方式 :4个字节
- 第一个字节固定为
0xF2 - 后三个字节存储实际整数值(采用小端序)
- 第一个字节固定为
- 示例:整数500000编码为0xF2 0x20 0xA1 0x07
采用4字节编码的方式,可以进一步扩大整数的存储范围,适应更大数值的需求。
-
32位整数:
- 范围:-2147483648 到 2147483647
- 编码方式 :5个字节
- 第一个字节固定为
0xF3 - 后四个字节存储实际整数值(采用小端序)
- 第一个字节固定为
- 示例:整数100000000编码为0xF3 0x00 0xE1 0xF5 0x05
5字节编码方式适合非常大的整数,确保存储时的空间效率。
-
64位整数:
- 范围:-9223372036854775808 到 9223372036854775807
- 编码方式 :9个字节
- 第一个字节固定为
0xF4 - 后八个字节存储实际整数值(采用小端序)
- 第一个字节固定为
- 示例:整数1000000000000编码为0xF4 0x00 0x00 0xD0 0xE2 0x1E 0x28 0x6B 0x00
9字节编码方式用于存储极大范围的整数,满足特定情况下的存储需求。
编码规则如下图所示:

源码如下:
c
#define LP_ENCODING_13BIT_INT 0xC0
#define LP_ENCODING_16BIT_INT 0xF1
#define LP_ENCODING_24BIT_INT 0xF2
#define LP_ENCODING_32BIT_INT 0xF3
#define LP_ENCODING_64BIT_INT 0xF4
/* Stores the integer encoded representation of 'v' in the 'intenc' buffer. */
static inline void lpEncodeIntegerGetType(int64_t v, unsigned char *intenc, uint64_t *enclen) {
if (v >= 0 && v <= 127) {
/* Single byte 0-127 integer. */
intenc[0] = v;
*enclen = 1;
} else if (v >= -4096 && v <= 4095) {
/* 13 bit integer. */
if (v < 0) v = ((int64_t)1<<13)+v;
intenc[0] = (v>>8)|LP_ENCODING_13BIT_INT;
intenc[1] = v&0xff;
*enclen = 2;
} else if (v >= -32768 && v <= 32767) {
/* 16 bit integer. */
if (v < 0) v = ((int64_t)1<<16)+v;
intenc[0] = LP_ENCODING_16BIT_INT;
intenc[1] = v&0xff;
intenc[2] = v>>8;
*enclen = 3;
} else if (v >= -8388608 && v <= 8388607) {
/* 24 bit integer. */
if (v < 0) v = ((int64_t)1<<24)+v;
intenc[0] = LP_ENCODING_24BIT_INT;
intenc[1] = v&0xff;
intenc[2] = (v>>8)&0xff;
intenc[3] = v>>16;
*enclen = 4;
} else if (v >= -2147483648 && v <= 2147483647) {
/* 32 bit integer. */
if (v < 0) v = ((int64_t)1<<32)+v;
intenc[0] = LP_ENCODING_32BIT_INT;
intenc[1] = v&0xff;
intenc[2] = (v>>8)&0xff;
intenc[3] = (v>>16)&0xff;
intenc[4] = v>>24;
*enclen = 5;
} else {
/* 64 bit integer. */
uint64_t uv = v;
intenc[0] = LP_ENCODING_64BIT_INT;
intenc[1] = uv&0xff;
intenc[2] = (uv>>8)&0xff;
intenc[3] = (uv>>16)&0xff;
intenc[4] = (uv>>24)&0xff;
intenc[5] = (uv>>32)&0xff;
intenc[6] = (uv>>40)&0xff;
intenc[7] = (uv>>48)&0xff;
intenc[8] = uv>>56;
*enclen = 9;
}
}编码字符串
listpack 中,字符串根据其长度分为三种不同的编码方式:
-
6位长度编码字符串 (长度 < 64):
- 范围:长度小于64字节的字符串
- 编码方式 :1个字节用于存储长度信息,后续字节存储实际字符串内容
- 第一个字节:高2位固定为
0x80,其余6位存储字符串长度
- 第一个字节:高2位固定为
- 示例:长度为5的字符串"Hello"编码为0x85 "Hello"
这种编码方式对短字符串非常高效,仅需一个字节即可存储长度信息。
-
12位长度编码字符串 (长度 < 4096):
- 范围:长度在64到4095字节之间的字符串
- 编码方式 :2个字节用于存储长度信息,后续字节存储实际字符串内容
- 第一个字节:高4位固定为
0xE0,其余4位存储长度的高位部分 - 第二个字节:存储长度的低8位
- 第一个字节:高4位固定为
- 示例:长度为100的字符串编码为0xE0 0x64 "实际字符串内容"
对于中等长度的字符串,使用12位编码可以有效减少存储开销。
-
32位长度编码字符串 (长度 ≥ 4096):
- 范围:长度在4096字节及以上的字符串
- 编码方式 :5个字节用于存储长度信息,后续字节存储实际字符串内容
- 第一个字节固定为
0xF0 - 第二至第五个字节依次存储长度的低8位到高8位(小端序)
- 第一个字节固定为
- 示例:长度为5000的字符串编码为0xF0 0x88 0x13 0x00 0x00 "实际字符串内容"
对于超长字符串,使用32位编码可以确保能存储任意长度的字符串。
编码规则如下图所示:
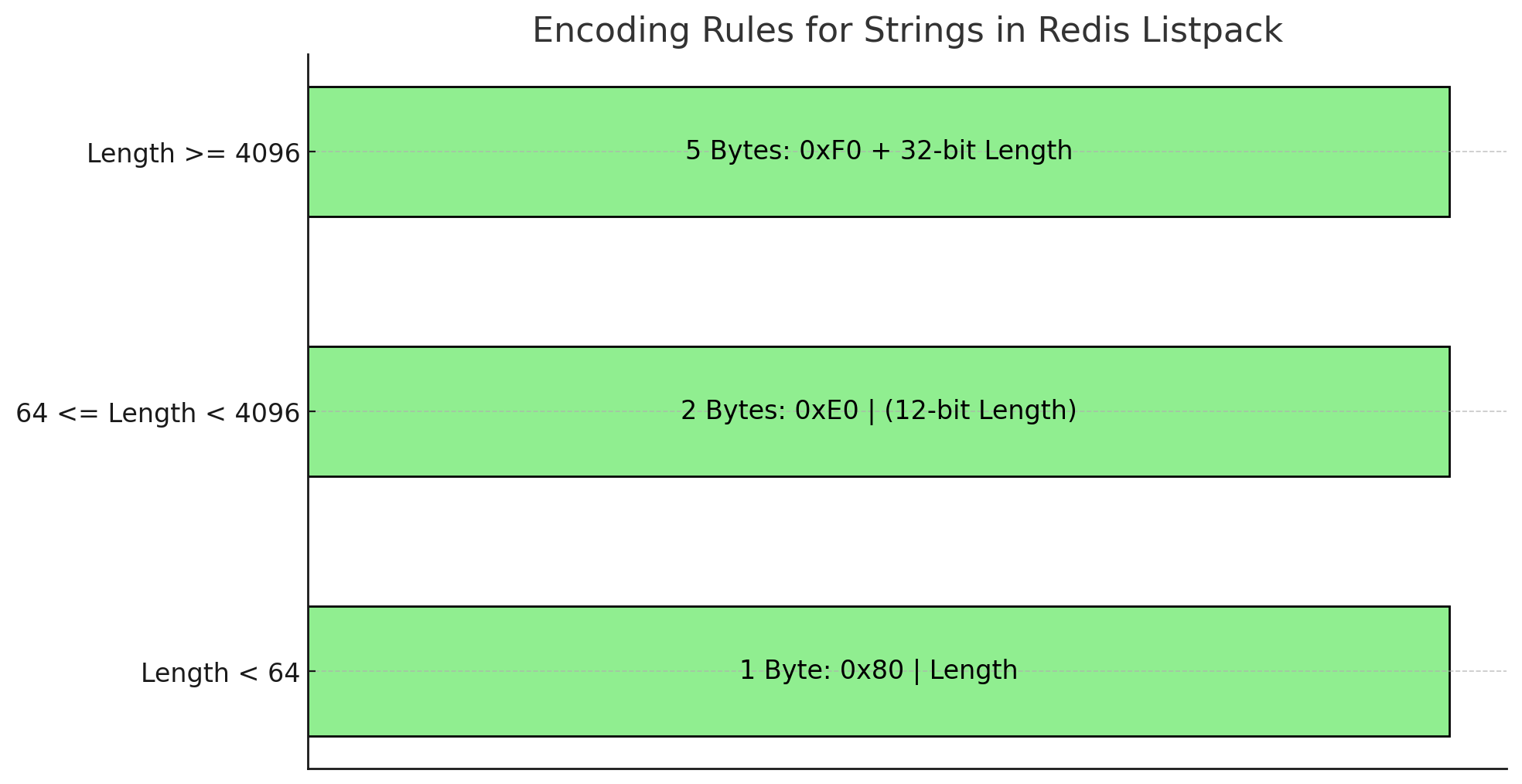
源码如下:
c
#define LP_ENCODING_6BIT_STR 0x80
#define LP_ENCODING_12BIT_STR 0xE0
#define LP_ENCODING_32BIT_STR 0xF0
static inline void lpEncodeString(unsigned char *buf, unsigned char *s, uint32_t len) {
if (len < 64) {
buf[0] = len | LP_ENCODING_6BIT_STR;
memcpy(buf+1,s,len);
} else if (len < 4096) {
buf[0] = (len >> 8) | LP_ENCODING_12BIT_STR;
buf[1] = len & 0xff;
memcpy(buf+2,s,len);
} else {
buf[0] = LP_ENCODING_32BIT_STR;
buf[1] = len & 0xff;
buf[2] = (len >> 8) & 0xff;
buf[3] = (len >> 16) & 0xff;
buf[4] = (len >> 24) & 0xff;
memcpy(buf+5,s,len);
}
}listpack 的遍历
在 listpack 中,正向遍历 从 lpFirst 函数开始,该函数检查 listpack 的总字节数,如果只有头部和结束符,则返回 NULL;否则,返回第一个元素的起始位置。接着,通过 lpNext 函数找到下一个元素,该函数调用 lpSkip 跳过当前元素,定位到下一个元素的起始位置。如果下一个元素是结束符(EOF),则遍历结束并返回 NULL,否则验证该元素的有效性并返回其指针。lpSkip 函数计算当前元素的总长度,包括数据部分和 backlen 部分,并将指针移动到下一个元素的起始位置。通过这种方式,可以高效地依次访问 listpack 中的每个元素,直到遇到结束符为止。
c
unsigned char *lpFirst(unsigned char *lp) {
if (lpGetTotalBytes(lp) == LP_HDR_SIZE + 1) return NULL;
return lp + LP_HDR_SIZE;
}
unsigned char *lpNext(unsigned char *lp, unsigned char *p) {
assert(p);
p = lpSkip(p);
if (p[0] == LP_EOF) return NULL;
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
unsigned char *lpSkip(unsigned char *p) {
unsigned long entrylen = lpCurrentEncodedSizeUnsafe(p);
entrylen += lpEncodeBacklen(NULL,entrylen);
p += entrylen;
return p;
}listpack 中的元素是怎么找到下一个元素的?
要找到下一个元素的位置,需要先计算当前元素的总长度。总长度包括编码标识长度和数据长度以及Backlen(存储当前数据总长度所占的空间)。
- 计算当前元素编码标识长度和数据长度:
根据元素的编码类型计算元素的编码标识长度和数据长度总和。
c
static inline uint32_t lpCurrentEncodedSizeUnsafe(unsigned char *p) {
if (LP_ENCODING_IS_7BIT_UINT(p[0])) return 1;
if (LP_ENCODING_IS_6BIT_STR(p[0])) return 1+LP_ENCODING_6BIT_STR_LEN(p);
if (LP_ENCODING_IS_13BIT_INT(p[0])) return 2;
if (LP_ENCODING_IS_16BIT_INT(p[0])) return 3;
if (LP_ENCODING_IS_24BIT_INT(p[0])) return 4;
if (LP_ENCODING_IS_32BIT_INT(p[0])) return 5;
if (LP_ENCODING_IS_64BIT_INT(p[0])) return 9;
if (LP_ENCODING_IS_12BIT_STR(p[0])) return 2+LP_ENCODING_12BIT_STR_LEN(p);
if (LP_ENCODING_IS_32BIT_STR(p[0])) return 5+LP_ENCODING_32BIT_STR_LEN(p);
if (p[0] == LP_EOF) return 1;
return 0;
}- 计算
Backlen长度:
根据长度 l 编码长度信息,并返回Backlen所需的字节数。
c
static inline unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l) {
if (l <= 127) {
if (buf) buf[0] = l;
return 1;
} else if (l < 16383) {
if (buf) {
buf[0] = l>>7;
buf[1] = (l&127)|128;
}
return 2;
} else if (l < 2097151) {
if (buf) {
buf[0] = l>>14;
buf[1] = ((l>>7)&127)|128;
buf[2] = (l&127)|128;
}
return 3;
} else if (l < 268435455) {
if (buf) {
buf[0] = l>>21;
buf[1] = ((l>>14)&127)|128;
buf[2] = ((l>>7)&127)|128;
buf[3] = (l&127)|128;
}
return 4;
} else {
if (buf) {
buf[0] = l>>28;
buf[1] = ((l>>21)&127)|128;
buf[2] = ((l>>14)&127)|128;
buf[3] = ((l>>7)&127)|128;
buf[4] = (l&127)|128;
}
return 5;
}
}在 listpack 中,反向遍历 从最后一个元素开始,通过 lpLast 函数获取 listpack 的总字节数并定位到结束符(EOF)前的一个字节,然后调用 lpPrev 函数。lpPrev 函数通过递减指针找到当前元素的 backlen 字段,使用 lpDecodeBacklen 函数解码出前一个元素的长度,再调整指针定位到前一个元素的起始位置。这个过程会重复,直至到达 listpack 的头部或找到所需的元素。通过这种方式,可以高效地进行 listpack 的反向遍历。
c
unsigned char *lpLast(unsigned char *lp) {
unsigned char *p = lp+lpGetTotalBytes(lp)-1; /* Seek EOF element. */
return lpPrev(lp,p); /* Will return NULL if EOF is the only element. */
}
unsigned char *lpPrev(unsigned char *lp, unsigned char *p) {
assert(p);
if (p-lp == LP_HDR_SIZE) return NULL;
p--; /* Seek the first backlen byte of the last element. */
uint64_t prevlen = lpDecodeBacklen(p);
prevlen += lpEncodeBacklen(NULL,prevlen);
p -= prevlen-1; /* Seek the first byte of the previous entry. */
lpAssertValidEntry(lp, lpBytes(lp), p);
return p;
}
static inline uint64_t lpDecodeBacklen(unsigned char *p) {
uint64_t val = 0;
uint64_t shift = 0;
do {
val |= (uint64_t)(p[0] & 127) << shift;
if (!(p[0] & 128)) break;
shift += 7;
p--;
if (shift > 28) return UINT64_MAX;
} while(1);
return val;
}
static inline unsigned long lpEncodeBacklen(unsigned char *buf, uint64_t l); // 见上一个代码块listpack 的优势
listpack相比ziplist具有以下几个显著优势:
- 无连锁更新:
现在每个
listpack元素都只存储自己的长度,不会发生像ziplist那样插入一个254字节及以上的元素就引起的连锁更新。
- 内存效率
listpack通过紧凑的编码方式大幅减少了内存占用,特别是对小整数和短字符串的存储进行了优化。
- 操作性能
改进了内存布局,使得插入和删除操作更加高效,避免了大规模的数据移动,提升了操作性能。
- 兼容性和扩展性
作为新的数据结构,
listpack设计时考虑了更多的扩展性和兼容性问题,能够更好地适应 Redis 的未来发展需求。
总结
ziplist
ziplist 是一种紧凑的字节数组数据结构,适用于存储小型列表。它主要包含以下部分:
zlbytes:总字节数(4字节)。zltail:到列表尾节点的偏移量(4字节)。zllen:节点数量(2字节)。entry:实际存储的节点。zlend:结束标记(1字节,值为 0xFF)。
每个节点包括 prevlen(前一个节点的长度)、encoding(编码方式)和 entry-data(实际存储内容)。
ziplist 的劣势
- 连锁更新:插入大于等于254字节的节点可能引发后续节点连锁更新,影响性能。
- 紧凑性不足:编码和解码过程复杂,计算开销较大。
- 操作性能不高:频繁插入和删除操作会导致性能退化。
- 逻辑复杂,维护性不高:实现复杂,维护和调试困难。
listpack
listpack 是一种高效的数据存储结构,用于替代 ziplist。它由连续的内存块组成,包含以下部分:
- Total Bytes:总字节数。
- Number of Elements:元素数量。
- Entry 1, Entry 2, ... Entry N:存储的每个元素(字符串或整数)。
- End Byte:结束标志(0xFF)。
listpack 的优势
- 无连锁更新:避免了连锁更新问题。
- 内存效率:紧凑的编码方式减少内存占用。
- 操作性能:改进的内存布局提升了插入和删除操作的效率。
- 兼容性和扩展性:设计更具扩展性,适应 Redis 的未来发展需求。
listpack 采用多种编码方式存储整数和字符串,根据数据类型和长度进行灵活编码,提高了存储密度和访问效率。正向和反向遍历通过计算元素总长度和 backlen 字段实现,保证了高效的元素访问。
源码示例
listpack 的初始化、整数编码和字符串编码的源码展示了其紧凑的存储方式和高效的操作流程。初始化时分配内存,设置总字节数和元素数量;编码整数和字符串时,根据数据类型选择合适的编码方式,确保存储紧凑。
总结来看,listpack 相比 ziplist 在内存使用和操作性能上都有显著提升,是 Redis 中更优的数据存储结构。
如果讲解有不对之处还请指正,我会尽快修改,多谢大家的包容。
如果大家喜欢这个系列,还请大家多多支持啦😋!
如果这篇文章有帮到你,还请给我一个大拇指 👍和小星星 ⭐️支持一下白晨吧!喜欢白晨【Redis】系列的话,不如关注👀白晨,以便看到最新更新哟!!!
我是不太能熬夜的白晨,我们下篇文章见。