AIGC 008-IP-Adapter文本兼容图像提示适配器用于文本到图像扩散模型!
文章目录
-
- [0 论文工作](#0 论文工作)
- [1 论文方法](#1 论文方法)
- [2 效果](#2 效果)
0 论文工作
这篇论文介绍了 IP-Adapter,一种 高效地将预训练的图像到图像转换模型适应到新领域 的方法。它通过在预训练模型的 输入端 添加一个 小的适配器网络 来实现,使得模型能够学习领域特定的转换,而无需改变原始模型的权重。这种方法提供了一种 快速且资源高效 的方式来适应图像到图像转换模型以应对新领域。
近年来,我们已经见证了大型文本到图像扩散模型的强大力量,它具有创建高保真图像的生成能力。然而,仅使用文本提示符来生成所需的图像是非常棘手的,因为它通常涉及到复杂的提示符工程。文本提示的另一种方法是图像提示 ,俗话说:"一个图像值千言万语"。虽然现有的从预先训练过的模型中进行直接微调的方法是有效的,但它们需要大量的计算资源,并且与其他基本模型、文本提示模型和结构模型不兼容控制。在本文中,作者提出了ip-adapter,一种有效的和轻量级的适配器,以实现预训练的文本到图像扩散模型的图像提示能力。ip-adapter的关键设计是解耦的交叉注意机制,它分离了文本特征和图像特征的交叉注意层。尽管该方法很简单,但一个只有22M参数的ip适配器可以实现与完全微调的图像提示模型相当甚至更好的性能。当冻结预先训练的扩散模型时,所提出的ip适配器不仅可以推广到其他从同一基模型进行微调的自定义模型,而且还可以推广到可控生成现有可控工具。利用解耦的交叉注意策略,图像提示符也可以正常工作l与文本提示符一起,以实现多模态图像的生成。
有点像lora又有点像T2I-adapter。
论文链接
github
1 论文方法
IP-Adapter 由两部分组成:
预训练的图像到图像转换模型: 使用预训练的模型
输入投影适配器: 在预训练模型的输入之前添加一个小的、轻量级的网络("IP-Adapter")。该适配器负责学习领域特定的转换,将源域的图像映射到更适合目标域的空间。
训练过程涉及微调 IP-Adapter,同时保持预训练模型冻结。这将最小化适应后的模型输出与目标域期望图像之间的差异。
用了一个解耦的交叉注意力机制。
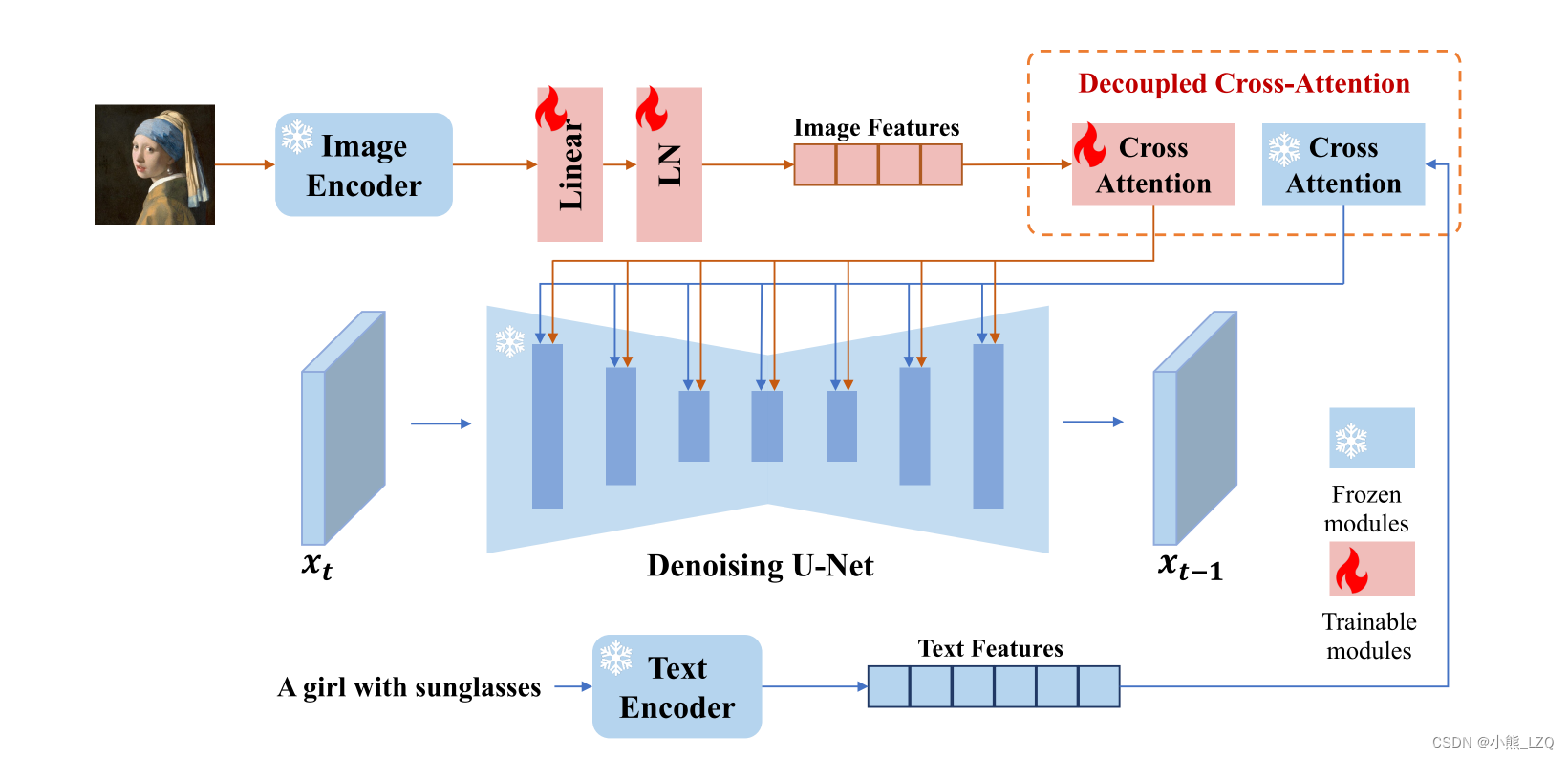
实现:
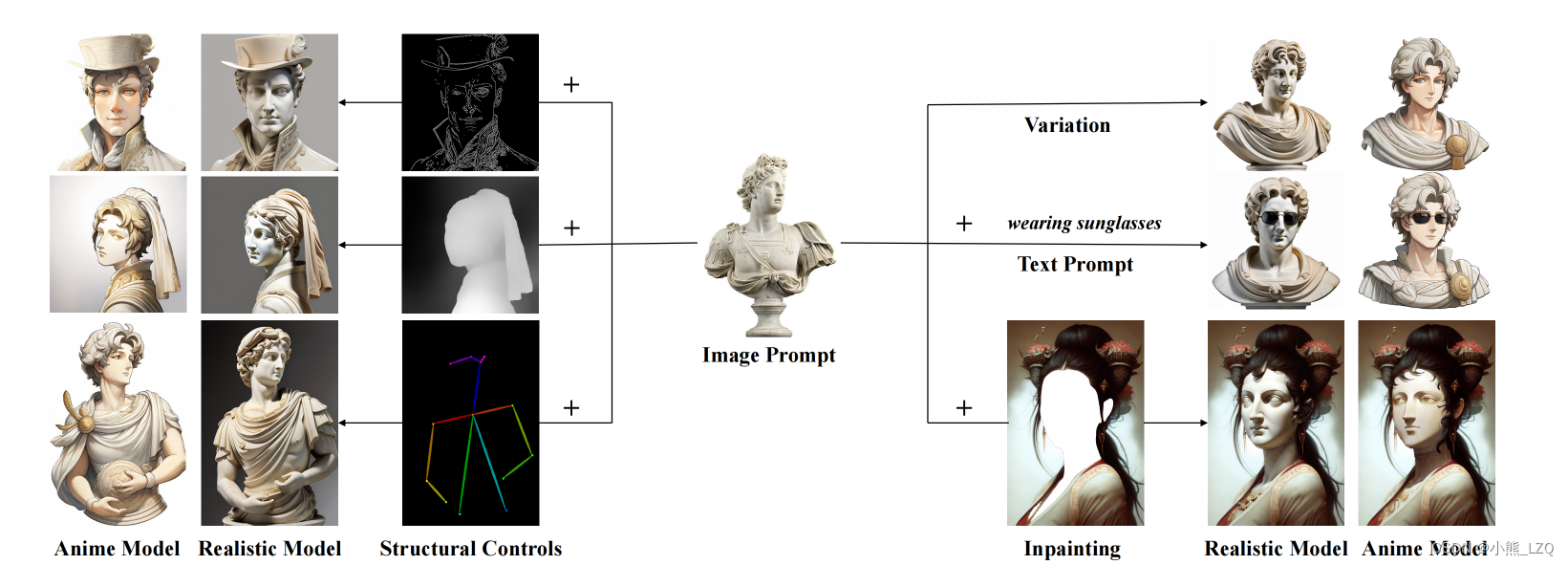
论文展示了 IP-Adapter 在各种图像到图像转换任务上的有效性,包括风格迁移、物体变形和图像着色。实现中使用了一个简单的卷积神经网络作为 IP-Adapter,展示了其简单性和效率。
优点:
快速适应: 仅微调 IP-Adapter 显著减少了训练时间,与重新训练整个模型相比快很多。
资源高效: 轻量级的 IP-Adapter 需要极少的计算资源和数据来训练。
对预训练模型的影响最小: 预训练模型保持冻结,保留其学习到的知识,同时适应新的领域。
泛化性: IP-Adapter 可以应用于不同领域各种图像到图像转换任务。
缺点:
适应性有限: IP-Adapter 的有效性取决于预训练模型的质量和适用性。对于需要显著改变模型底层架构的任务,它可能会遇到困难。
可能存在次优性能: 适应过程仅限于输入层,可能限制了模型学习复杂转换的能力。
预训练模型的偏差: 预训练模型可能包含偏差,可能会传播到领域特定编码器中。
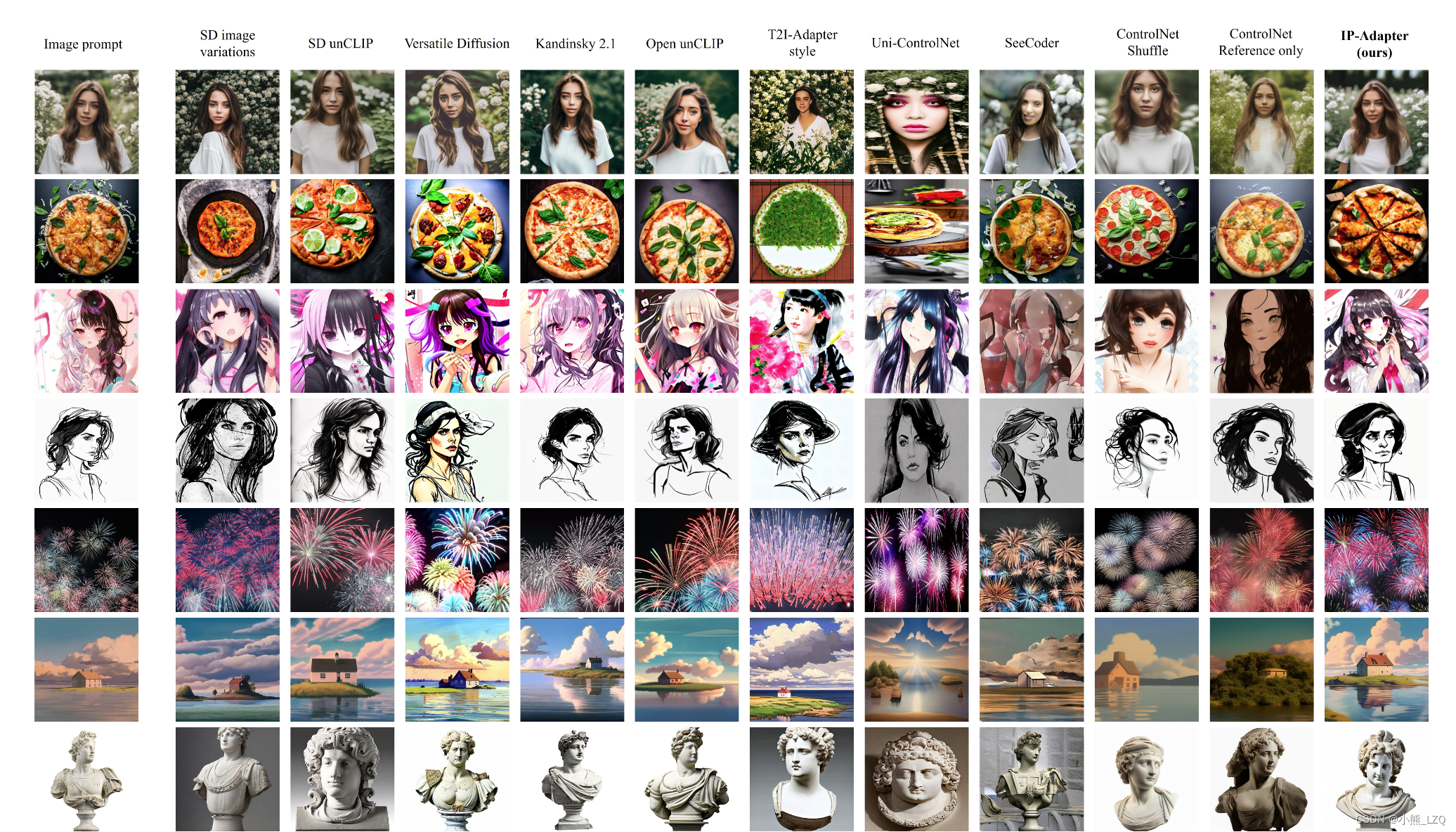
2 效果
对该方向感兴趣可以看看他的对比方法。