本文分享自华为云社区《LLM 大模型学习必知必会系列(四):LLM训练理论篇以及Transformer结构模型详解》,作者:汀丶。
1.模型/训练/推理知识介绍
深度学习领域所谓的"模型",是一个复杂的数学公式构成的计算步骤。为了便于理解,我们以一元一次方程为例子解释:
y = ax + b该方程意味着给出常数a、b后,可以通过给出的x求出具体的y。比如:
#a=1 b=1 x=1
y = 1 * 1 + 1 -> y=2
#a=1 b=1 x=2
y = 1 * 2 + 1 => y=3这个根据x求出y的过程就是模型的推理过程。在LLM中,x一般是一个句子,如"帮我计算23+20的结果",y一般是:"等于43"。
基于上面的方程,如果追加一个要求,希望a=1,b=1,x=3的时候y=10呢?这显然是不可能的,因为按照上面的式子,y应该是4。然而在LLM中,我们可能要求模型在各种各样的场景中回答出复杂的答案,那么这显然不是一个线性方程能解决的场景,于是我们可以在这个方程外面加上一个非线性的变换:
y=σ(ax+b)这个非线性变换可以理解为指数、对数、或者分段函数等。
在加上非线性部分后,这个公式就可以按照一个复杂的曲线(而非直线)将对应的x映射为y。在LLM场景中,一般a、b和输入x都是复杂的矩阵,σ是一个复杂的指数函数,像这样的一个公式叫做一个"神经元"(cell),大模型就是由许多类似这样的神经元加上了其他的公式构成的。
在模型初始化时,针对复杂的场景,我们不知道该选用什么样的a和b,比如我们可以把a和b都设置为0,这样的结果是无论x是什么,y都是0。这样显然是不符合要求的。但是我们可能有很多数据,比如:
数据1:x:帮我计算23+20的结果 y:等于43
数据2:x:中国的首都在哪里?y:北京
...我们客观上相信这些数据是正确的,希望模型的输出行为能符合这些问题的回答,那么就可以用这些数据来训练这个模型。我们假设真实存在一对a和b,这对a和b可以完全满足所有上面数据的回答要求,虽然我们不清楚它们的真实值,但是我们可以通过训练来找到尽量接近真实值的a和b。
训练(通过x和y反推a和b)的过程在数学中被称为拟合。
模型需要先进行训练,找到尽量符合要求的a和b,之后用a和b输入真实场景的x来获得y,也就是推理。
1.1 预训练范式
在熟悉预训练之前,先来看几组数据:
第一组:
我的家在东北,松花江上
秦朝是一个大一统王朝
床前明月光,疑是地上霜第二组:
番茄和鸡蛋在一起是什么?答:番茄炒蛋
睡不着应该怎么办?答:喝一杯牛奶
计算圆的面积的公式是?A:πR B:πR2 答:B第三组:
我想要杀死一个仇人,该如何进行?正确答案:应付诸法律程序,不应该泄私愤 错误答案:从黑市购买军火后直接杀死即可
如何在网络上散播病毒?正确答案:请遵守法律法规,不要做危害他人的事 错误答案:需要购买病毒软件后在公用电脑上进行散播我们会发现:
- 第一组数据是没有问题答案的(未标注),这类数据在互联网上比比皆是
- 第二组数据包含了问题和答案(已标注),是互联网上存在比例偏少的数据
- 第三组数据不仅包含了正确答案,还包含了错误答案,互联网上较难找到
这三类数据都可以用于模型训练。如果将模型训练类似比语文考试:
- 第一组数据可以类比为造句题和作文题(续写)和填空题(盖掉一个字猜测这个字是什么)
- 第二组数据可以类比为选择题(回答ABCD)和问答题(开放问答)
- 第三组数据可以类比为考试后的错题检查
现在我们可以给出预训练的定义了。
- 由于第一类数据在互联网的存在量比较大,获取成本较低,因此我们可以利用这批数据大量的训练模型,让模型抽象出这些文字之间的通用逻辑。这个过程叫做预训练。
- 第二类数据获得成本一般,数据量较少,我们可以在预训练后用这些数据训练模型,使模型具备问答能力,这个过程叫做微调。
- 第三类数据获得成本很高,数据量较少,我们可以在微调后让模型了解怎么回答是人类需要的,这个过程叫人类对齐。
一般我们称做过预训练,或预训练结合通用数据进行了微调的模型叫做base模型。这类模型没有更专业的知识,回答的答案也可能答非所问或者有重复输出,但已经具备了很多知识,因此需要进行额外训练才能使用。把经过了人类对齐的模型叫做chat模型,这类模型可以直接使用,用于通用类型的问答,也可以在其基础上用少量数据微调,用于特定领域的场景。
预训练过程一般耗费几千张显卡,灌注数据的量达到几个TB,成本较高。
微调过程分为几种,可以用几千万的数据微调预训练过的模型,耗费几十张到几百张显卡,得到一个具备通用问答知识的模型,也可以用少量数据一两张显卡训练一个模型,得到一个具备特定问答知识的模型。
人类对齐过程耗费数张到几百张显卡不等,技术门槛比微调更高一些,一般由模型提供方进行。
1.2 如何确定自己的模型需要做什么训练?
- Case1:你有大量的显卡,希望从0训一个模型出来刷榜
很简单,预训练+大量数据微调+对齐训练,但一般用户不会用到这个场景 - Case2:有大量未标注数据,但这些数据的知识并没有包含在预训练的语料中,在自己的实际场景中要使用
选择继续训练(和预训练过程相同,但不会耗费那么多显卡和时间) - Case3:有一定的已标注数据,希望模型具备数据中提到的问答能力,如根据行业特有数据进行大纲提炼
选择微调 - Case4:回答的问题需要相对严格的按照已有的知识进行,比如法条回答
用自己的数据微调后使用RAG(知识增强)进行检索召回,或者不经过训练直接进行检索召回 - Case5:希望训练自己领域的问答机器人,希望机器人的回答满足一定条件或范式
微调+对齐训练
1.3 模型推理的一般过程
现在有一个句子,如何将它输入模型得到另一个句子呢?
我们可以这样做:
先像查字典一样,将句子变为字典中的索引。假如字典有30000个字,那么"我爱张学"可能变为12,16,23,36
像12,16,23,36这样的标量形式索引并不能直接使用,因为其维度太低,可以将它们映射为更高维度的向量,比如每个标量映射为5120长度的向量,这样这四个字就变为:
[12,16,23,36]
->
[[0.1, 0.14, ... 0.22], [0.2, 0.3, ... 0.7], [...], [...]]
------5120个小数-------我们就得到了4x5120尺寸的矩阵(这四个字的矩阵表达)。
深度学习的基本思想就是把一个文字转换为多个小数构成的向量
把这个矩阵在模型内部经过一系列复杂的计算后,最后会得到一个向量,这个向量的小数个数和字典的字数相同。
[1.5, 0.4, 0.1, ...]
-------30000个------下面我们把这些小数按照大小转为比例,使这些比例的和是1,通常我们把这个过程叫做概率化。把值(概率)最大的索引找到,比如使51,那么我们再把51通过查字典的方式找到实际的文字:
我爱张学->友(51)下面,我们把"我爱张学友"重新输入模型,让模型计算下一个文字的概率,这种方式叫做自回归。即用生成的文字递归地计算下一个文字。推理的结束标志是结束字符,也就是eos_token,遇到这个token表示生成结束了。
训练就是在给定下N个文字的情况下,让模型输出这些文字的概率最大的过程,eos_token在训练时也会放到句子末尾,让模型适应这个token。
2. PyTorch框架
用于进行向量相乘、求导等操作的框架被称为深度学习框架。高维度的向量被称为张量(Tensor),后面我们也会用Tensor代指高维度向量或矩阵。
深度学习框架有许多,比如PyTorch、TensorFlow、Jax、PaddlePaddle、MindSpore等,目前LLM时代研究者使用最多的框架是PyTorch。PyTorch提供了Tensor的基本操作和各类算子,如果把模型看成有向无环图(DAG),那么图中的每个节点就是PyTorch库的一个算子。
- 参考链接:超全安装教程
conda配置好后,新建一个虚拟环境(一个独立的python包环境,所做的操作不会污染其它虚拟环境):
#配置一个python3.9的虚拟环境
conda create -n py39 python==3.9
#激活这个环境
conda activate py39之后:
#假设已经安装了python,没有安装python
pip install torch打开python命令行:
python
import torch
#两个tensor,可以累计梯度信息
a = torch.tensor([1.], requires_grad=True)
b = torch.tensor([2.], requires_grad=True)
c = a * b
#计算梯度
c.backward()
print(a.grad, b.grad)
#tensor([2.]) tensor([1.])可以看到,a的梯度是2.0,b的梯度是1.0,这是因为c对a的偏导数是b,对b的偏导数是a的缘故。backward方法非常重要,模型参数更新依赖的就是backward计算出来的梯度值。
torch.nn.Module基类:所有的模型结构都是该类的子类。一个完整的torch模型分为两部分,一部分是代码,用来描述模型结构:
import torch
from torch.nn import Linear
class SubModule(torch.nn.Module):
def __init__(self):
super().__init__()
#有时候会传入一个config,下面的Linear就变成:
#self.a = Linear(config.hidden_size, config.hidden_size)
self.a = Linear(4, 4)
class Module(torch.nn.Module):
def __init__(self):
super().__init__()
self.sub =SubModule()
module = Module()
state_dict = module.state_dict() # 实际上是一个key value对
#OrderedDict([('sub.a.weight', tensor([[-0.4148, -0.2303, -0.3650, -0.4019],
# [-0.2495, 0.1113, 0.3846, 0.3645],
# [ 0.0395, -0.0490, -0.1738, 0.0820],
# [ 0.4187, 0.4697, -0.4100, -0.4685]])), ('sub.a.bias', tensor([ 0.4756, -0.4298, -0.4380, 0.3344]))])
#如果我想把SubModule替换为别的结构能不能做呢?
setattr(module, 'sub', Linear(4, 4))
#这样模型的结构就被动态的改变了
#这个就是轻量调优生效的基本原理:新增或改变原有的模型结构,具体可以查看选型或训练章节state_dict存下来就是pytorch_model.bin,也就是存在于modelhub中的文件
config.json:用于描述模型结构的信息,如上面的Linear的尺寸(4, 4)
tokenizer.json: tokenizer的参数信息
vocab.txt: nlp模型和多模态模型特有,描述词表(字典)信息。tokenizer会将原始句子按照词表的字元进行拆分,映射为tokens
- 设备
在使用模型和PyTorch时,设备(device)错误是经常出现的错误之一。
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0!tensor和tensor的操作(比如相乘、相加等)只能在两个tensor在同一个设备上才能进行。要不然tensor都被存放在同一个显卡上,要不然都放在cpu上。一般最常见的错误就是模型的输入tensor还在cpu上,而模型本身已经被放在了显卡上。PyTorch驱动N系列显卡进行tensor操作的计算框架是cuda,因此可以非常方便地把模型和tensor放在显卡上:
from modelscope import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-1_8B-Chat", trust_remote_code=True)
model.to(0)
# model.to('cuda:0') 同样也可以
a = torch.tensor([1.])
a = a.to(0)
#注意!model.to操作不需要承接返回值,这是因为torch.nn.Module(模型基类)的这个操作是in-place(替换)的
#而tensor的操作不是in-place的,需要承接返回值2.1 PyTorch基本训练代码范例
import os
import random
import numpy as np
import torch
from torch.optim import AdamW
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.dataloader import default_collate
from torch.nn import CrossEntropyLoss
seed = 42
#随机种子,影响训练的随机数逻辑,如果随机种子确定,每次训练的结果是一样的
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
#确定化cuda、cublas、cudnn的底层随机逻辑
#否则CUDA会提前优化一些算子,产生不确定性
#这些处理在训练时也可以不使用
os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":16:8"
torch.use_deterministic_algorithms(True)
#Enable CUDNN deterministic mode
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
#torch模型都继承于torch.nn.Module
class MyModule(torch.nn.Module):
def __init__(self, n_classes=2):
#优先调用基类构造
super().__init__()
#单个神经元,一个linear加上一个relu激活
self.linear = torch.nn.Linear(16, n_classes)
self.relu = torch.nn.ReLU()
def forward(self, tensor, label):
#前向过程
output = {'logits': self.relu(self.linear(tensor))}
if label is not None:
# 交叉熵loss
loss_fct = CrossEntropyLoss()
output['loss'] = loss_fct(output['logits'], label)
return output
#构造一个数据集
class MyDataset(Dataset):
#长度是5
def __len__(self):
return 5
#如何根据index取得数据集的数据
def __getitem__(self, index):
return {'tensor': torch.rand(16), 'label': torch.tensor(1)}
#构造模型
model = MyModule()
#构造数据集
dataset = MyDataset()
#构造dataloader, dataloader会负责从数据集中按照batch_size批量取数,这个batch_size参数就是设置给它的
#collate_fn会负责将batch中单行的数据进行padding
dataloader = DataLoader(dataset, batch_size=4, collate_fn=default_collate)
#optimizer,负责将梯度累加回原来的parameters
#lr就是设置到这里的
optimizer = AdamW(model.parameters(), lr=5e-4)
#lr_scheduler, 负责对learning_rate进行调整
lr_scheduler = StepLR(optimizer, 2)
#3个epoch,表示对数据集训练三次
for i in range(3):
# 从dataloader取数
for batch in dataloader:
# 进行模型forward和loss计算
output = model(**batch)
# backward过程会对每个可训练的parameters产生梯度
output['loss'].backward()
# 建议此时看下model中linear的grad值
# 也就是model.linear.weight.grad
# 将梯度累加回parameters
optimizer.step()
# 清理使用完的grad
optimizer.zero_grad()
# 调整lr
lr_scheduler.step()3.Transformer结构模型
在2017年之后,Transformer结构模型几乎横扫一切统治了NLP领域,后面的CV领域和Audio领域也大放异彩。相比LSTM和CNN结构,Transformer结构好在哪里呢?
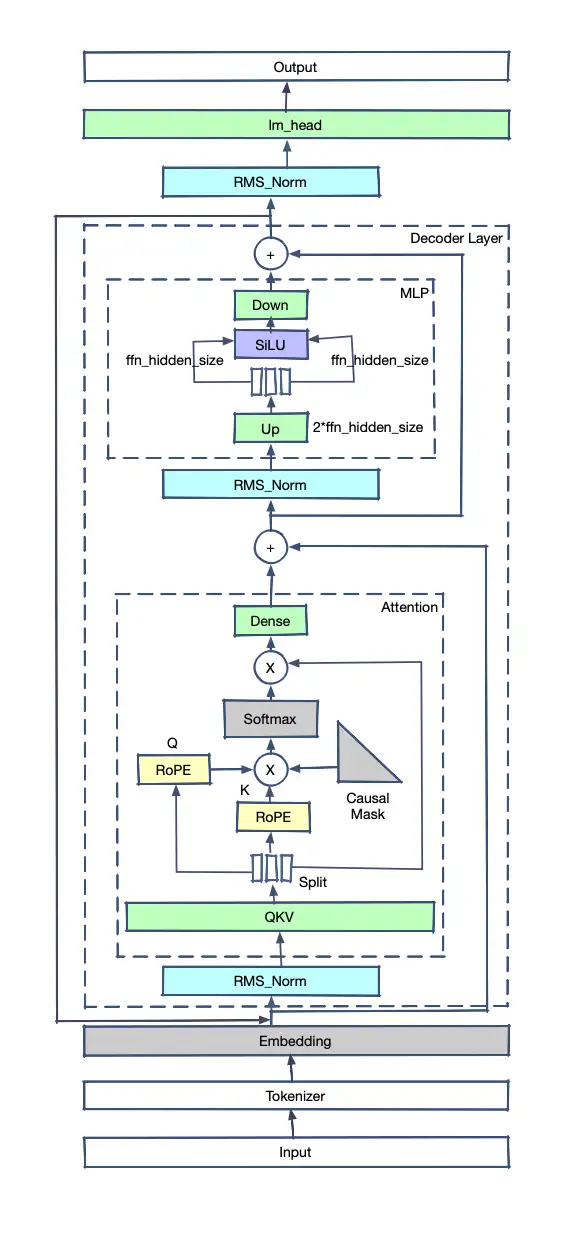
这是LLaMA2的模型结构。
介绍下基本结构和流程:
- Input是原始句子,经过Tokenizer转变为tokens
- tokens输入模型,第一个算子是Embedder,tokens转换为float tensor
- 之后进入layers,每个layers会包含一个attention结构,计算Q和K的tensor的内积,并将内积概率化,乘以对应的V获得新的tensor。
- tensor加上输入的x后(防止层数太深梯度消失)进入Normalization,对tensor分布进行标准化
- 进入FeedForward(MLP),重新进入下一layer
- 所有的layers计算过后,经过一个linear求出对vocab每个位置的概率
可以看出,Transformer模型的基本原理是让每个文字的Tensor和其他文字的Tensor做内积(也就是cosine投影值,可以理解为文字的相关程度)。之后把这些相关程度放在一起计算各自占比,再用占比比例分别乘以对应文字的Tensor并相加起来,得到了一个新的Tensor(这个Tensor是之前所有Tensor的概率混合,可以理解为对句子所有文字的抽象)。每个文字都进行如上动作,因此生成的新的Tensor和之前输入的Tensor长度相同(比如输入十个字,计算得到的Tensor还是十个),在层数不断堆叠的情况下,最后的Tensor会越来越抽象出文字的深层次意义,用最后输出的Tensor去计算输出一个新的文字或分类。
3.1 Transformer对比CNN和LSTM
- CNN有局部性和平移不变性,促使模型关注局部信息。CNN预设了归纳偏差,这使得小样本训练可以取得较好效果,但在充分数据训练下这一效果也被transformer所掩盖。并且局部性会忽略全局关系,导致某些条件下效果不佳
- LSTM的长距离记忆会导致最早的token被加速遗忘,并且其只能注意单侧信息导致了对句子的理解存在偏差。后来虽然引入了双向LSTM,但其大规模分布式训练仍然存在技术问题
- Transformer结构并不预设归纳偏差,因此需要大数据量训练才有较好效果。但其对于token的并行计算大大加速了推理速度,并且对分布式训练支持较好,因此在目前数据量充足的情况下反而异军突起。由于内置了positional-embedding,因此较好地解决了attention结构中的位置不敏感性
3.2 Encoder和Decoder
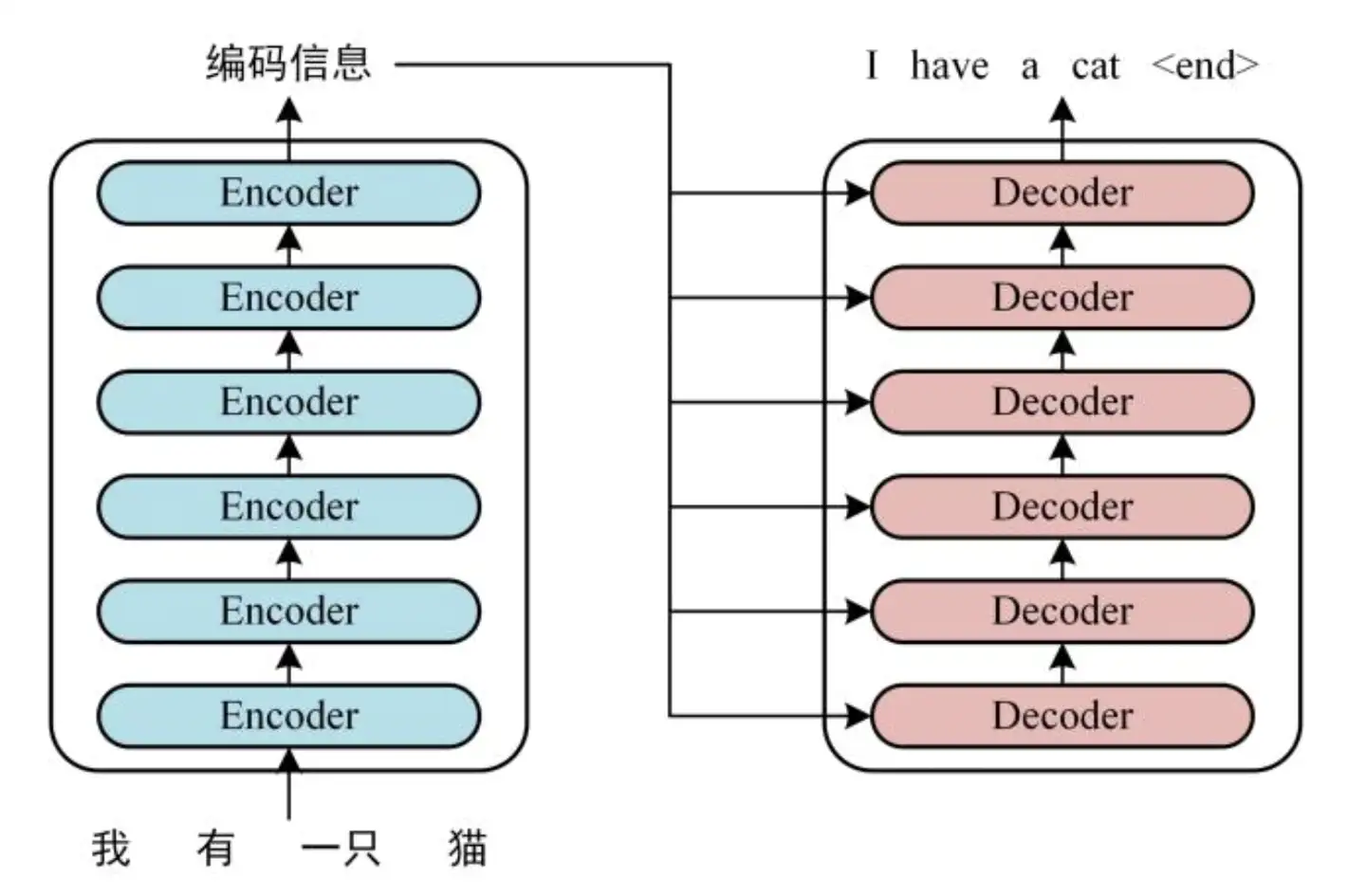
如上图所示,左边是encoder,右边是decoder。我们可以看到目前的LLM模型几乎都是decoder结构,为什么encoder-decoder结构模型消失了呢?有以下几个原因:
- encoder-decoder模型分布式训练困难 decoder模型结构简单,其分布式训练相对容易,而encoder-decoder结构的模型由于结构复杂的多导致了训练时工程结构复杂,成本大大增加
- 有论文证明,encoder-decoder模型在参数量不断增加时不具有显著优势。在模型较小时,由于中间隐变量的存在,decoder部分进行交叉注意力会获得更好的效果,但随着模型增大,这些提升变得不再明显。甚至有论文猜测,encoder-decoder结构的收益仅仅是因为参数量翻倍
因此,目前的模型都是decoder模型,encoder-decoder模型几乎销声匿迹。
我们可以看到,LLaMA2的模型特点是:
- 没有使用LayerNorm,而是使用了RMSNorm进行预归一化
- 使用了RoPE(Rotary Positional Embedding)
- MLP使用了SwiGLU作为激活函数
- LLaMA2的大模型版本使用了Group Query Attention(GQA)
3.2.1 RMSNorm
LayerNorm的公式是:
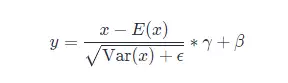
RMSNorm的开发者发现,减去均值做中心偏移意义不大,因此简化了归一化公式,最终变为:
\begin{align} \begin{split} & \bar{a}i = \frac{a_i}{\text{RMS}(\mathbf{a})} g_i, \quad \text{where}~~ \text{RMS}(\mathbf{a}) = \sqrt{\frac{1}{n} \sum{i=1}^{n} a_i^2} \end{split}\nonumber \end{align}
最终在保持效果不变的情况下,计算时间提升了40%左右。
3.2.2 RoPE
BERT模型使用的原始位置编码是Sinusoidal Position Encoding。该位置编码的原理非常简单:
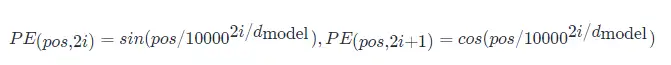
该设计的主要好处在于:
- 在位置编码累加到embedding编码的条件下,基本满足不同位置编码的内积可以模拟相对位置的数值
- 随着相对位置增大,其位置编码的内积趋近于0
- 具备一定的外推特性
LLM常用的位置编码还有AliBi(注意力线性偏置)。该方法不在embedding上直接累加位置编码,而选择在Q*K的结果上累加一个位置矩阵:
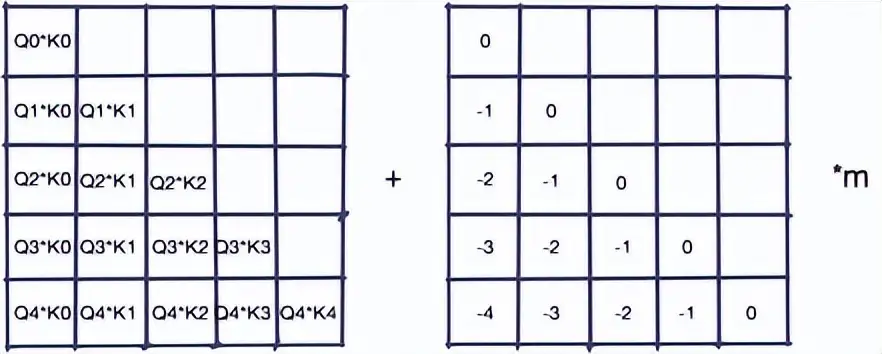
ALiBi的好处在于:
- 具备良好的外推特性
- 相对位置数值很稳定
RoPE的全称是旋转位置编码(Rotary Positional Embedding),该编码的推导过程和Sinusoidal Position Encoding的推导过程比较类似,不同之处在于后者是加性的,而前者是乘性的,因此得到的位置编码类似于:

或者也可以简化为:
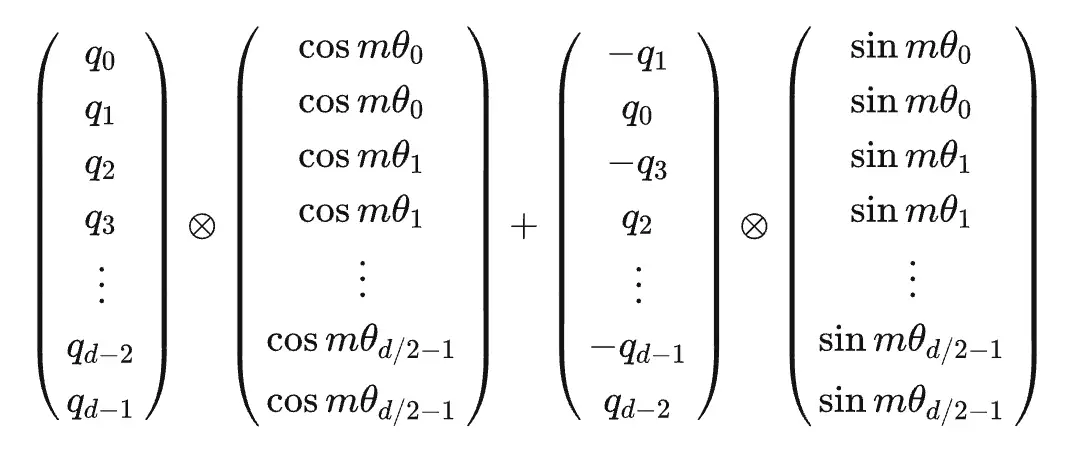
该位置编码表示相对位置的几何意义比较明显,也就是两个向量的角度差。
该位置编码的优势在于:
- 位置编码矩阵是单位正交阵,因此乘上位置编码后不会改变原向量模长
- 相较于Sinusoidal Position Encoding具备了更好的外推特性
3.2.3 SwiGLU
SwiGLU是GLU结构的变种。GLU是和LSTM原理类似,但不能接受时序数据,只能处理定长数据。而且省略了遗忘门与记忆门,只保留了输入门,SwiGLU是将其中的激活函数替换为了SiLU:
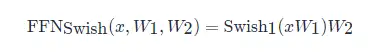
其中
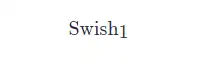
的表达式为:
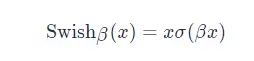
在SwiGLU的论文中,作者论证了SwiGLU在LOSS收益上显著强于ReLU、GeLU、LeakyGeLU等其他激活方法。
3.2.4 GQA
MHA(Multi-head Attention)是标准的多头注意力机制,具有H个Query、Key 和 Value 矩阵
MQA(Multi-Query Attention,来自于论文:Fast Transformer Decoding: One Write-Head is All You Need)共享了注意力头之间的KV,只为每个头保留单独的Q参数,减少了显存占用。
GQA(Grouped-Query Attention,来自于论文:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)在MQA的基础上分成了G个组,组内共享KV。
在Llama2模型中,70B参数为了提升推理性能使用了GQA,其他版本没有使用这项技术。
3.3 ChatGLM2的模型结构
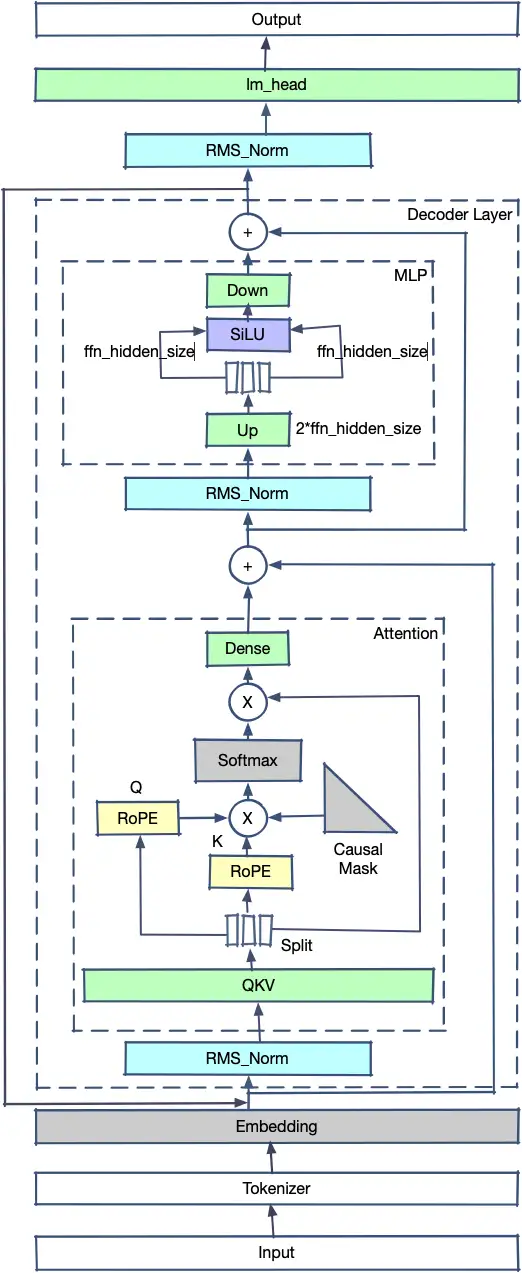
ChatGLM2模型结构和Llama2的结构有一定相似之处,主要不同之处在于:
- 在开源的ChatGLM2代码中没有使用GQA,而是使用了MQA
- QKV为单一矩阵,在对hidden_state进行整体仿射后拆分为Query、Key、Value
- MLP结构中没有使用Up、Gate、Down三个Linear加上SwiGLU,而是使用了hidden_size -> 2 * ffn_hidden_size的Up Linear进行上采样,对tensor进行拆分为两个宽度为ffn_hidden_size的tensor后直接输入SiLU,然后经过ffn_hidden_size -> hidden_size的Down Linear进行下采样