文章目录
人脸检测研究现状
这里直接引用了吴伟硕士毕业论文
随着计算能力的飞速提升和创新性的传感、分析、渲染设备和技术的广泛应用,计算机越来越具有智能性。已有许多研究项目和商业产品展示了计算机能够通过摄像头和麦克风与人类进行自然交互,它们能够理解人类的输入并作出友好的反馈。实现这种人机交互的关键技术之一是人脸检测。人脸检测是所有基于人脸特征的分析算法的前提,例如人脸对齐、人脸建模、人脸重建、人脸识别、人脸验证、头部姿态跟踪、表情识别、性别/年龄识别等。给定一幅数字图像,人脸检测的主要目标是判断图像中是否存在人脸,并且如果存在,则给出人脸的位置和范围。这对于人类来说可能是一件轻而易举的事情,但是对于计算机来说却充满了挑战性,这也使得人脸检测成为过去二十年里计算机视觉领域最热门的研究课题之一。影响人脸检测难度的因素包括尺度、位置、姿态、遮挡、光照、模糊等,在面对这些挑战时,过去二十年间研究者们不断地改进和优化了各种人脸检测算法,并取得了巨大的进步。
传统的人脸检测算法
传统的人脸检测算法主要依赖于手工设计的特征。Yang1将这些早期方法分为四大类:基于知识的方法、特征不变方法、模板匹配方法和基于外观的方法。基于知识的方法2利用人类对典型面孔结构的先验知识来检测人脸。一张典型的人脸图像通常由两只相互对称的眼睛、一个鼻子和一张嘴组成,各部分特征之间的关系可以用它们的相对距离和位置来表示。该方法首先提取输入图像中的面部特征,然后根据编码规则识别候选人脸,并通过验证过程减少错误检测。特征不变方法3-6旨在寻找对姿态和光照变化具有鲁棒性的人脸结构特征,该方法首先使用边缘检测器提取面部特征,然后推断出整张脸的存在,并根据提取的特征建立统计模型来描述它们之间的关系,并验证人脸是否存在。这些基于特征的算法存在一个问题,由于光照、噪声和遮挡,图像特征可能会严重损坏。面部边界可能会被削弱,而阴影可能会导致大量明显的错误边缘,这些都会使得感知分组算法失效。模板匹配方法7-8使用预先存储的人脸模板来确定图像中人脸的位置。给定一个输入图像,计算面部轮廓、眼睛、鼻子和嘴巴与标准模式之间相关值,并根据相关值判断是否存在人脸。该方法易于实现但不能有效地处理尺寸、姿势和形状变化等问题。为了实现尺度和形状不变性,后续提出了多分辨率、多尺度、子模板和可变形模板等技术。基于外观的方法9-12从一组代表性训练人脸图像中学习人脸模型,并依靠统计分析和机器学习技术来找到区分人脸和非人脸图像相关特征。所学到的特征以分布模型或判别函数形式呈现,并用于检测是否存在人脸。同时,考虑到计算效率和检测效果两方面因素,通常会对人脸图像进行降维处理。
2001 年,Viola 和 Jones13提出了一种开创性的人脸检测算法,使得人脸检测在实际场景中成为可能。该算法主要利用 Haar14特征和 Adaboost15算法来训练一个强分类器,用于检测图像中是否存在人脸。其检测过程主要包括四个步骤:首先,使用 Haar 特征来描述图像的局部区域,这些特征由黑白矩形块组成,反映了图像区域内的亮度差异。例如,一个 2 × 2 的 Haar 特征由两个黑色矩形和两个白色矩形构成,可以用来检测眼睛所在的位置。其次,使用 Adaboost 算法来训练一个强分类器,该分类器由多个弱分类器组合而成,每个弱分类器都是一个简单的二元分类器,用于判断图像区域是否包含人脸。在训练过程中,Adaboost 算法会对错误分类的样本进行加权处理,使得这些样本更容易被正确分类,在下一轮训练中得到更多关注,从而提高分类器的准确率。第三步,在检测新图像时,使用滑动窗口的方法对图像进行逐像素扫描,并在每个窗口内应用强分类器来判断该窗口是否包含人脸。通过调整窗口大小和位置可以检测不同尺度和方向上的人脸。最后一步,在输出结果时直接给出包含人脸区域的位置和大小信息。Viola-Jones 人脸检测器具有较高速度和准确性等优点,在实时应用中能够快速有效地检测出人脸。但是这种方法也存在一些问题:当图像中存在遮挡、光照不均匀、角度变化较大或表情复杂等情况时容易导致误检或漏检。DPM16-17算法基于可变部件模型 (Deformable Part Model, DPM),将目标对象看作由多个部件构成,并且每个部件都有自己独立且可变形的形状和特征表示方式。通过将这些部件组合起来构建目标对象整体的形状和特征表示方式,并利用它们之间相互约束的关系进行目标对象识别与定位,从而提高了检测器对目标对象复杂变化情况下鲁棒性与准确性等方面表现能力。DPM 算法主要分为两个阶段:第一个阶段是生成候选框,根据输入图像及其尺度空间金字塔等信息生成一系列可能包含目标对象的候选框。第二个阶段是训练和检测,对于人脸的每个部件 (如眼睛、鼻子、嘴巴等),学习其形状和特征表示方式,并用支持向量机 (Support VectorMachines, SVM) 训练出相应的部件分类器。然后,对于每个候选框,通过组合各个部件分类器得到整体人脸分类器,并计算其得分,用于判断该候选框是否包含人脸。在检测过程中,通常采用滑动窗口的方式进行。对于检测到的每个人脸区域,通过比较其得分,筛选出得分较高的区域作为最终结果。与 Viola-Jones 人脸检测相比,DPM 算法能够更好地处理遮挡、光照不均匀、角度变化等复杂情况下的人脸检测问题,并且对尺度变化范围大的图像有更强的适应能力。当然,DPM 算法也存在一些缺点:计算复杂度高、检测速度慢等。
传统的人脸检测算法缺点
这些传统方法都有一个共同问题:它们都依赖于手工设计的特征来描述图像中的人脸信息,这些特征可能不足以捕捉复杂多样化的人脸变化情况,并且难以适应不同场景和数据集下的需求变化,因此限制了它们在实际应用中表现出来的性能。此外,这些方法通常需要调整大量参数来优化模型效果,这需要花费大量时间和经验,并且难以充分利用大规模人脸数据集所提供优势。尽管如此,在一些资源受限或实时性要求高等场景下,传统方法仍然具有一定价值,因为它们通常具有较高效率、较低计算成本和相对可接受精度等特点。例如,在大多数数码相机中都内置了基于 Viola-Jones 算法实现的人脸检测功能,用于自动对焦和拍照。因此,传统方法并不是完全过时或无用,而是在一定程度上被深度学习方法所补充和超越。
深度学习人脸检测算法
随着深度学习技术的发展,基于深度学习的人脸检测方法能够自动学习图像中的复杂特征,相比于传统方法在检测准确率上取得了显著优势,逐渐成为研究的主流。Feng18将基于深度学习的人脸检测器架构分为三类,多阶段检测架构、两阶段检测架构和单阶段检测架构。受传统人脸检测方法的影响,早期深度学习的人脸检测大都采用级联结构。Girshick 等19在 2015 年提出了 Faster-RCNN,以突破性的速度和精度性能成为目标检测领域的里程碑。Faster-RCNN 引入了一个称为区域建议网络 (Region ProposalNetwork, RPN) 的子网络,它可以在图像中生成候选区域,这些区域用于检测目标。RPN 使用卷积神经网络 (Convolutional Neural Networks, CNN) 来提取图像特征,并根据这些特征生成候选区域。RPN 输出每个候选区域的得分和边界框,这些得分可以用来过滤掉低质量的候选区域,并将其提供给后续的分类器和回归器。整个模型采用端到端的训练方式,可以同时学习特征提取、候选区域生成、目标分类和边界框回归。之后,一些研究人员基于人脸数据改进了 Faster-RCNN。同年,Li等20提出了 CascadeCNN。其主要方法是采用级联的 CNN 来进行人脸检测。该模型包括三个级联的 CNN 分类器,每个分类器都使用了级联的检测器。在级联的过程中,前一个分类器用于过滤掉大量的负样本,以提高后续分类器的效率和准确率。Zhang 等21在 2016 年提出了 MTCNN,在单个模型中完成了人脸检测和人脸关键点定位两项任务,在多个公开基准数据集中取得了非常好的效果。它由三个级联的卷积神经网络实现,Proposal Network (P-Net) 生成候选框,Refine Network(RNet) 和 Output Network(O-Net) 对候选框进行进一步地筛选和精细化调整。Wang等22在 2017 年提出了基于 Faster-RCNN 架构的 Face-RCNN。其主要贡献在于将人脸识别中使用的 Center Loss 引入到人脸检测中,并提出在线困难样本挖掘算法(Online Hard Example Mining, OHEM)。另外,为了弱化人脸尺度变化范围大的影响,Face-RCNN 采用多尺度训练策略,即在训练阶段将输入图片进行多尺度缩放。无论是级联的多阶段检测网络架构还是两阶段检测网络架构,其计算速度在很大程度上依赖于图像中人脸的数量,人脸数量的增加也将增加网络内部传递到下一阶段的候选区域数量,导致整体推理时延较高且不稳定。由于一些实际应用场景需要人脸检测任务实时进行,单阶段的人脸检测器更受欢迎,因为它们的处理时间不受图像中人脸数量的影响。单阶段架构只使用一个神经网络来直接生成预测框,通常包括两个部分:特征提取和预测框生成。特征提取部分使用卷积神经网络从原始图像中提取特征,预测框生成部分则将这些特征输入到几个并行的卷积层中,以生成预测框。它们不需要生成候选区域,而是使用密集锚点设计来替代多阶段检测网络架构中的候选区域建议。然而,单阶段人脸检测器也面临着一些挑战:如何处理尺度变化范围大、姿态、光照和遮挡极端变化的人脸;如何平衡正负样本比例,避免过拟合或欠拟合;如何设计有效的特征增强模块和优化方法,提高模型性能。针对这些挑战,一些研究人员提出了各种改进方案。Hu 等23提出了 HR 方法,它是最早的基于锚框机制的单阶段人脸检测器之一,它根据不同尺度范围内的人脸分别训练不同的检测器,并从人脸尺度、分辨率和特征上下文信息三个方面进行优化。Najibi 等24提出了 SSH 方法,它直接在不同层次的特征映射上构建具有丰富感受野的检测模块。Zhang 等25提出了 S3FD 方法,它引入了一种锚框补偿策略,并使用额外的子网络来增强多尺度下的人脸检测结果。Tang 等26提出了 PyramidBox 方法,它采用了一种"数据-锚框"的采样策略来增加小人脸在训练数据中的比例,并使用一个称为 LFPN 的子网络来利用低层次特征进行小人脸检测。Li 等27提出了 DSFD 方法,在主干网络上引入了小人脸监督信号,并使用一个称为 EFPN 的子网络来显著提高特征金字塔性能。Deng 等28提出了 RetinaFace 方法,在原有目标类别和边界框回归任务之外增加了额外任务:关键点回归任务,并采用可变形卷积模块来增强上下文信息。Liu 等29发现训练阶段未匹配到真实目标区域但具有较强定位能力的锚框也可以作为输出候选区域,并基于此设计了一种在线高质量锚框挖掘策略;同时在另一项工作30中采用单路径搜索算法对主干网络和颈部网络进行联合优化。Li 等31在ASFD 方法中提出了一种用于优化特征增强模块的差分架构搜索算法,从而实现高效的多尺度特征融合和上下文增强。这些方法都对人脸检测任务精度和速度方面进行了深入探索,但大多数都是通过使用复杂而沉重的特征增强模块、稠密而技巧性的锚框设计以及复杂而耗时的训练测试策略实现极高精度排名优势。然而,在真实场景中应用时,高昂运行成本和较长推理时延仍然是障碍。为了提高人脸检测模型的实际应用效果,研究人员提出了许多轻量化的方法。例如,Zhang 等32提出了 FaceBoxes 方法,它是最早实现实时检测的单阶段人脸检测方法之一。它的贡献在于提出快速消化 (RDCL) 模块和多尺度卷积 (MSCL)模块来实现快速而有效的特征提取。He 等33提出了 LFFD 方法,它引入残差结构进行特征提取,并根据感受野和有效感受野来设计基于锚框机制的检测策略。YOLO5Face34基于 YOLOv535实现专用的轻量级人脸检测器。Guo 等36提出了SCRFD 方法,它引入样本再分配策略和计算再分配策略来增强训练样本丰富性和优化计算量分配,并且根据不同的计算量标准 (0.5/3.0/10.0 GFLOPs 等) 提出一系列高效人脸检测器。这些方法都大大降低了人脸检测任务的推理延迟,但是也牺牲了一定的检测精度,并且还有进一步轻量化的空间。
人脸识别实战
现代人脸识别流程由 5 个常见阶段组成:检测、对齐、标准化、表示和验证
人脸检测
人脸检测的本质是目标检测,由于人脸检测的精度似乎已经满足了大部分日常使用的要求,目前项目的优化主要是在速度提升方面,项目由于性能的限制对计算速度要求较高,因此大多都是基于 linux 平台的,如 dlib ;
这里发现一个满足全平台运行的库包 deepface
在 deepface 中,进行人脸检测有许多的模型可以使用,['opencv', 'ssd', 'dlib', 'mtcnn', 'fastmtcnn', 'retinaface', 'mediapipe', 'yolov8', 'yunet', 'centerface']
不同模型效果判断代码使用如下
python
import os
import time
import cv2 as cv
from deepface import DeepFace
import matplotlib.pyplot as plt
## 需要检测的图片
img_filename = 'demo.jpg'
## 检查模型方法
detectors = ['opencv', 'ssd', 'dlib', 'mtcnn', 'fastmtcnn', 'retinaface', 'mediapipe', 'yolov8', 'yunet', 'centerface']
os.makedirs('./demoface/', exist_ok=True)
for detector in detectors:
try:
start_time = time.time()
resp = DeepFace.extract_faces(img_filename, detector_backend=detector, enforce_detection=False)
facial_area = [item['facial_area'] for item in resp]
nums = len(facial_area)
img = cv.imread(img_filename)
for item in facial_area:
x = item['x']
y = item['y']
w = item['w']
h = item['h']
cv.rectangle(img, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255), thickness=2)
end_time = time.time()
print(f'{detector.center(20, " ")} ------- {str(nums).center(20, " ")} ------- {end_time - start_time}')
cv.imwrite(f'./demoface/{detector}-{nums}.jpg', img)
except Exception as e:
print(f'./demoface/{detector} ------- {e}')图片保存在当前目录的 demoface 文件夹下,进行可视化如下
python
## 可视化代码
img_paths = [filename for filename in os.listdir('./demoface/') if filename.endswith('.jpg')]
fig = plt.figure(figsize=(20, 7))
for ix, img_path in enumerate(img_paths):
img = cv.imread('./demoface/' + img_path)
plt.subplot(2,4,ix+1)
plt.imshow(img[:,:,::-1])
plt.axis('off')
plt.title(img_path)
plt.tight_layout()
plt.savefig('final.jpg')这里由于 dlib 需要在 linux 上运行, mediapipe 和 现有的 tensorflow==2.10 版本冲突,缺失这两个模型的效果图片,但是好在这两个模型并不是效果最好的模型。

原项目中各个模型的效果如下所示:

人脸对齐
这里以卖瓜哥为例子,提取出来的人脸是歪着的,对了更好的进行人脸识别,最好是将人脸给弄正;这里可以利用眼睛连线水平的关系来扶正人脸,如图所示;

我们只需要将人脸旋转一定角度就可以,角度计算如下: θ = arctan ∣ y 1 − y 2 ∣ ∣ x 1 − x 2 ∣ \theta = \arctan \frac{|y_1 - y_2|}{|x_1-x_2|} θ=arctan∣x1−x2∣∣y1−y2∣
执行代码如下:
python
import math
from PIL import Image
import cv2 as cv
import numpy as np
from deepface import DeepFace
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
# 原图
img_origin = np.asarray(Image.open('./buy watermelon.jpg'))
# 提取图
resp = DeepFace.extract_faces('./buy watermelon.jpg', align=False)
extract_face = resp[0]['face']
# 旋转图
## 计算 degree
x1, y1 = resp[0]['facial_area']['left_eye']
x2, y2 = resp[0]['facial_area']['right_eye']
degree = math.atan(abs(y1-y2)/abs(x1-x2)) / math.pi * 180
## 旋转图像并进行检测
img = Image.open('./buy watermelon.jpg')
img = np.asarray(img.rotate(degree))
resp = DeepFace.extract_faces(img, align=False)
extract_face_aligned = resp[0]['face'][:,:,::-1]
# 提取align图,这里其实默认align为True
resp = DeepFace.extract_faces('./buy watermelon.jpg', align=True)
extract_face_align_True = resp[0]['face']
# 可视化
fig = plt.figure(figsize=(10, 12))
gs = gridspec.GridSpec(2, 3, height_ratios=[3, 1], hspace=0)
plt.subplot(gs[0,:])
plt.imshow(img_origin)
plt.axis('off')
plt.title('origin')
plt.subplot(gs[1,0])
plt.imshow(extract_face)
plt.axis('off')
plt.title('align=False')
plt.subplot(gs[1,1])
plt.imshow(extract_face_aligned)
plt.axis('off')
plt.title('align=False and Fixed')
plt.subplot(gs[1,2])
plt.imshow(extract_face_align_True)
plt.axis('off')
plt.title('align=True')
plt.tight_layout()得到结果如下

人脸标准化
检测和对齐是现代面部识别流程的重要早期强制性阶段。然而,人脸检测依赖于将人脸提取为矩形。因此,即使检测到并对齐的面部图像也会在背景中出现一些噪点。标准化是现代面部识别管道的一个可选阶段,它计划减少输入中的噪声并提高面部识别管道的准确性。人脸标准化阶段主要基于面部椭圆形的面部标志检测。

这里由于 dlib 需要在 linux 上运行,而 mediapipe 和 现有的 tensorflow==2.10 版本冲突,因此在这里展示不进行人脸标准化操作,具体操作可以看下面两篇内容;
- Facial Landmarks for Face Recognition with Dlib - Sefik Ilkin Serengil (sefiks.com)
- Deep Face Detection with Mediapipe - Sefik Ilkin Serengil (sefiks.com)
- Normalization for Facial Recognition with MediaPipe - Sefik Ilkin Serengil (sefiks.com)
人脸表示
书中采取了一个简单的卷积网络对检测出来的人脸进行分类,但是数据量太少,模型层数太低,这就会导致提取的特征不充分,容易出现欠拟合情况,这里采用 Siamese Networks 进行人脸表示;
可以采用的模型有:VGG-Face, Facenet, Facenet512, OpenFace, DeepFace, DeepID, Dlib, ArcFace, SFace, GhostFaceNet,模型性能的对比如下:
| Model | Measured Score | Declared Score |
|---|---|---|
| Facenet512 | 98.4% | 99.6% |
| Human-beings | 97.5% | 97.5% |
| Facenet | 97.4% | 99.2% |
| Dlib | 96.8% | 99.3 % |
| VGG-Face | 96.7% | 98.9% |
| ArcFace | 96.7% | 99.5% |
| GhostFaceNet | 93.3% | 99.7% |
| SFace | 93.0% | 99.5% |
| OpenFace | 78.7% | 92.9% |
| DeepFace | 69.0% | 97.3% |
| DeepID | 66.5% | 97.4% |
VGG-Face:VGG 代表 视觉几何组。VGG 神经网络(VGGNet)是基于深度卷积神经网络最常用的图像识别模型类型之一。VGG 人脸识别模型在流行的野外标记人脸 (LFW) 数据集上实现了97.78%的准确率。Facenet:该模型由谷歌的研究人员开发。FaceNet 被认为是通过深度学习进行人脸检测和识别的最先进的模型。FaceNet 的主要优点是其高效率和高性能,据报道,它在 LFW 数据集上达到了99.63%的准确率。OpenFace:这个人脸识别模型是由卡内基梅隆大学的研究人员建立的。因此,OpenFace 在很大程度上受到 FaceNet 项目的启发,但这更轻量级,其许可证类型更灵活,OpenFace 在 LFW 数据集上实现了93.80%的准确率。DeepFace: 这种人脸识别模型是由 Facebook 的研究人员开发的。Facebook DeepFace 算法是在属于 4000 万张面孔的标记数据集上进行训练的,这是发布时最大的面部数据集。该方法基于具有九层的深度神经网络。Facebook 模型在 LFW 数据集基准测试上实现了97.35%(+/- 0.25%)的准确率。DeepID: DeepID 人脸验证算法基于深度学习进行人脸识别。它是首批使用卷积神经网络并在人脸识别任务上实现优于人类性能的模型之一。Deep-ID 是由香港中文大学的研究人员引入的。基于 DeepID 人脸识别的系统是第一批在这项任务中超越人类表现的系统。例如,DeepID2 在野外标记面孔(LFW)数据集上实现了99.15%。Dlib: Dlib 人脸识别模型将自己命名为"世界上最简单的 python 面部识别 API"。Dlib 的人脸识别工具将人脸图像映射到 128 维矢量空间,其中同一个人的图像彼此靠近,而不同人的图像相距甚远。因此,dlib 通过将人脸映射到 128d 空间,然后检查它们的欧几里得距离是否足够小来执行人脸识别。dlib 模型的距离阈值为 0.6,在标准 LFW 人脸识别基准上实现了99.38%的准确率。ArcFace: 这是模型组合中的最新型号。它的联合设计师是伦敦帝国理工学院和 InsightFace 的研究人员。ArcFace 模型在 LFW 数据集上的准确度达到99.40%。SFace: 是一种人脸识别的预训练模型,它是基于深度神经网络的人脸识别模型。SFace 模型是由中国科学院自动化研究所的研究人员开发的,它在多个人脸识别竞赛中表现出色。SFace 模型采用了一种名为"中心损失"的训练方法,可以使得模型在人脸识别任务中更加准确。
这些人脸识别模型之前是为了在大规模数据集上对人脸图像的身份进行分类而构建的。考虑一个包含 1000 个不同人物的 100 万张图像的数据集。在这种情况下,CNN 模型的输出层将为 1000,并且该模型经过训练以查找输入图像的身份。当训练结束时,输出层被丢弃,输出层的早期层将成为新的输出层。现在,新模型不会对身份进行分类,而是返回面部的表示。我们现在可以提供训练数据集中未出现的新图像。该模型仍然可以找到表征。
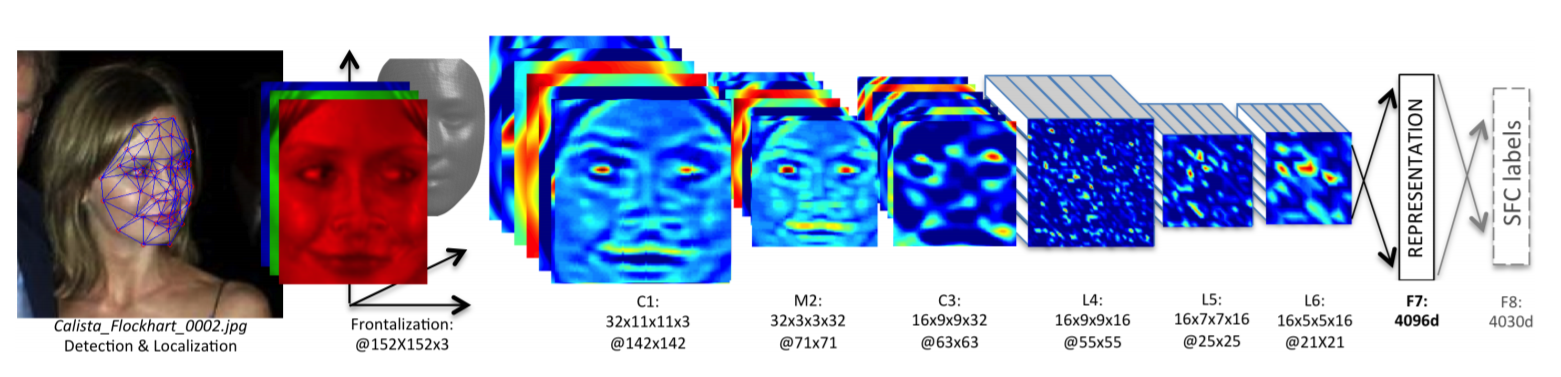
因此,将任何一张人脸图片带入模型得到的特征表示其实质都是这1000个不同人物的变异导致的特征实现的,是基于这些人物进行特征编码;
在 deepface 中,这一任务实现变得非常简单,只需要将原图带入 api 中计算就可以得到表征,其会自动进行人脸检测,人脸对齐以及图片尺寸缩放等等任务;
这里使用 DeepFace 模型对卖瓜哥进行特征表示计算,代码如下:
python
import cv2 as cv
import numpy as np
from deepface import DeepFace
import matplotlib.pyplot as plt
# 获取 represent 结果中的 embedding 和 facial_area
resp = DeepFace.represent('./buy watermelon.jpg', model_name='DeepFace')
# 利用 facial_area 画方框
img = cv.imread('./buy watermelon.jpg')
item = resp[0]['facial_area']
x, y, w, h = item['x'], item['y'], item['w'], item['h']
cv.rectangle(img, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255), thickness=2)
# 可视化表示
fig = plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.imshow(img[:,:,::-1])
plt.axis('off')
plt.subplot(1,2,2)
plt.imshow(np.tile(np.array(resp[0]['embedding']), [800, 1]), interpolation='nearest', cmap=plt.cm.ocean)
plt.axis('off')
plt.colorbar()
plt.show()得到结果如下:

如要进行分类,我们可以利用模型输出的特征向量,在后面链接 dense 层最后再进行分类操作;操作较为简单,这里不进行处理;
人脸验证
人脸验证是绕过分类的形式对两张或者多张图片进行判断,这种方法适用于图片较少,无法进行分类训练的情况,由于通常任务来说目标人脸的图片较少,因此该方法要比分类更为常用;
其核心是通过比较两张图片的人脸表示特征向量的相似度,相似度有很多的计量方法,比较常用的有:cosine,euclidean 和 euclidean_l2
使用 euclidean 的经验阈值有:
| Model | Euclidean Threshold |
|---|---|
| VGG-Face | 0.55 |
| OpenFace | 0.55 |
| Facenet | 10 |
| DeepFace | 64 |
使用代码实现如下
python
import cv2 as cv
import numpy as np
from deepface import DeepFace
import matplotlib.pyplot as plt
# 获取 represent 结果中的 embedding 和 facial_area
resp = DeepFace.represent('./buy watermelon.jpg', model_name='DeepFace')
# > embedding_1
embedding_1 = np.array(resp[0]['embedding'])
# 利用 facial_area 画方框
img = cv.imread('./buy watermelon.jpg')
item = resp[0]['facial_area']
x, y, w, h = item['x'], item['y'], item['w'], item['h']
cv.rectangle(img, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255), thickness=2)
# 可视化表示
fig = plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.imshow(img[:,:,::-1])
plt.axis('off')
plt.subplot(1,2,2)
plt.imshow(np.tile(np.array(resp[0]['embedding']), [800, 1]), interpolation='nearest', cmap=plt.cm.ocean)
plt.axis('off')
plt.colorbar()
plt.show()
# 获取 represent 结果中的 embedding 和 facial_area
resp = DeepFace.represent('./sell watermelon.jpg', model_name='DeepFace')
# > embedding_2
embedding_2 = np.array(resp[0]['embedding'])
# 利用 facial_area 画方框
img = cv.imread('./sell watermelon.jpg')
item = resp[0]['facial_area']
x, y, w, h = item['x'], item['y'], item['w'], item['h']
cv.rectangle(img, pt1=(x, y), pt2=(x + w, y + h), color=(0, 0, 255), thickness=2)
# 可视化表示
fig = plt.figure(figsize=(12, 4))
plt.subplot(1,2,1)
plt.imshow(img[:,:,::-1])
plt.axis('off')
plt.subplot(1,2,2)
plt.imshow(np.tile(np.array(resp[0]['embedding']), [800, 1]), interpolation='nearest', cmap=plt.cm.ocean)
plt.axis('off')
plt.colorbar()
plt.show()
## 计算分数
euclidean = np.sqrt(np.sum(np.abs(embedding_1 - embedding_2)))
# euclidean: 41.536550691276716
很显然,euclidean 是越小越相似,这里 41 < 64 41 < 64 41<64,如果按照经验阈值判断应该是同一个人,但是显然不是;这里有一种更为简单的方法
python
DeepFace.verify(img1_path='./buy watermelon.jpg', img2_path='./sell watermelon.jpg', model_name='DeepFace', distance_metric='euclidean')得到输出结果
json
{'detector_backend': 'opencv',
'distance': 59.595589732220056,
'facial_areas': {'img1': {'h': 202,
'left_eye': (295, 110),
'right_eye': (221, 91),
'w': 202,
'x': 151,
'y': 17},
'img2': {'h': 183,
'left_eye': (282, 130),
'right_eye': (225, 128),
'w': 183,
'x': 161,
'y': 61}},
'model': 'DeepFace',
'similarity_metric': 'euclidean',
'threshold': 64,
'time': 3.27,
'verified': True}这里分数不同的原因是,DeepFace.verify 自动启用了 normalization=base,无法关闭;
参考资料
- ageitgey/face_recognition: The world's simplest facial recognition api for Python and the command line (github.com)
- ShiqiYu/libfacedetection:一个用于图像中人脸检测的开源库。人脸检测速度可达1000FPS。 --- ShiqiYu/libfacedetection: An open source library for face detection in images. The face detection speed can reach 1000FPS. (github.com)
- serengil/retinaface:RetinaFace:Python 的深度人脸检测库 --- serengil/retinaface: RetinaFace: Deep Face Detection Library for Python (github.com)
- Virtual Background with Mediapipe - Sefik Ilkin Serengil (sefiks.com)
- 用于深度学习的大规模人脸识别 - Sefik Ilkin Serengil --- Large Scale Face Recognition for Deep Learning - Sefik Ilkin Serengil (sefiks.com)