本文分享自华为云社区《【昇腾开发全流程】AscendCL开发板模型推理》,作者:沉迷sk。
前言
学会如何安装配置华为云ModelArts、开发板Atlas 200I DK A2。
并打通一个Ascend910训练到Ascend310推理的全流程思路。
在本篇章,我们继续进入推理阶段!
推理阶段
B. 环境搭建
AscendCL 开发板 模型推理
Step1 准备硬件
基础硬件
- 开发者套件
- Micro SD 卡(TF卡):容量推荐不小于64GB
- 读卡器
- PC(笔记本或台式机)
所需配件
用于后续连接启动&登录开发者套件。
这里以远程登录模式为例
- RJ45网线
注:
这里使用Windows系统,通过网线以远程登录模式连接启动登录开发者套件。
详细内容or选择其他系统其他模式的用户可参考昇腾官网文档-快熟开始
Step2 制卡
PC下载并安装制卡工具"Ascend-devkit-imager_latest_win-x86_64.exe"
将SD卡插入读卡器的卡槽中,接着一起插入PC的USB接口中
打开制卡工具
-> 在线制卡(镜像版本选择Ubuntu)
-> 选择SD卡(烧录镜像时会自动将SD卡格式化,需要提前检查SD卡是否有数据需要提前备份)
-> 烧录镜像(大概20min)
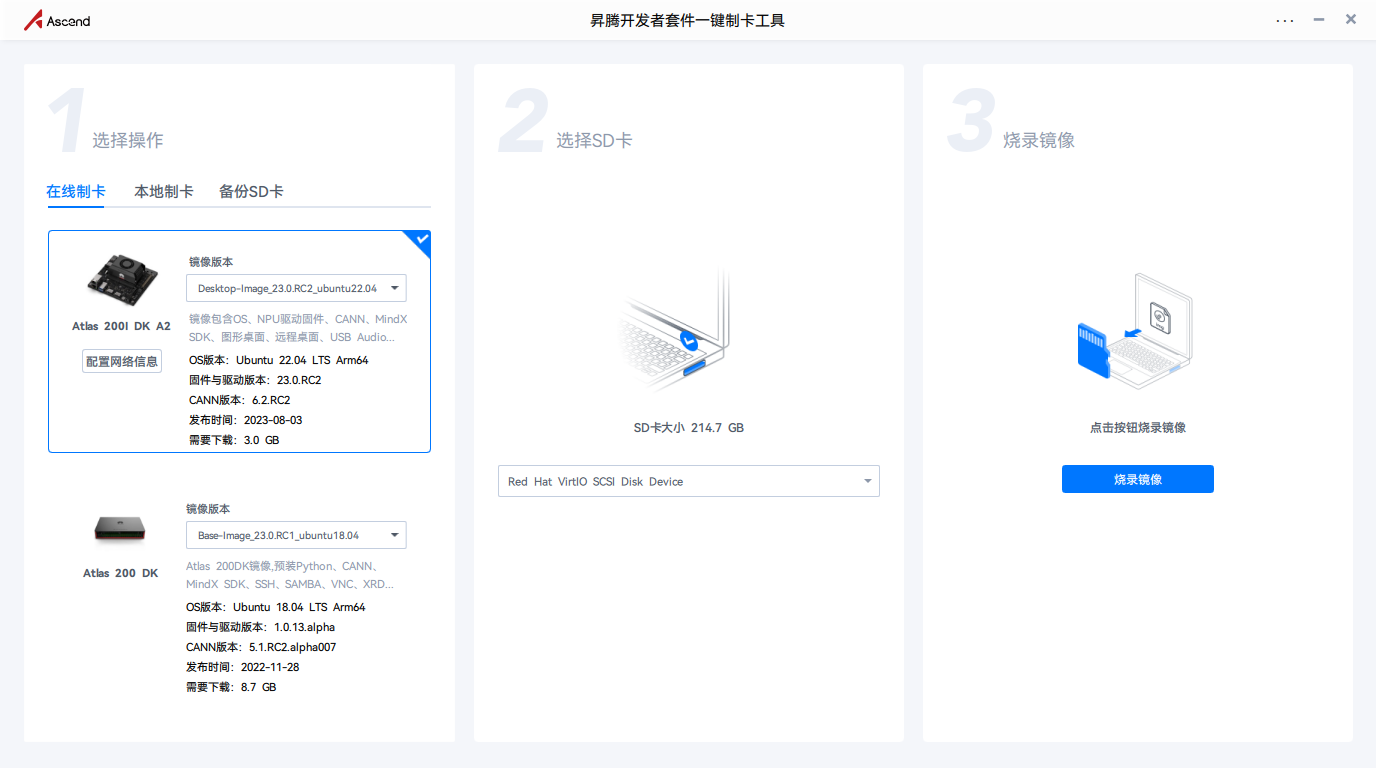
烧录成功后,将SD卡从读卡器中取出。
Step3 连接启动开发者套件
将烧录好的SD卡插入开发者套件的SD插槽,并确保完全推入插槽底部。(推到底是有类似弹簧的触感)
确保开发者套件的拨码开关2、3、4的开关值如图所示:
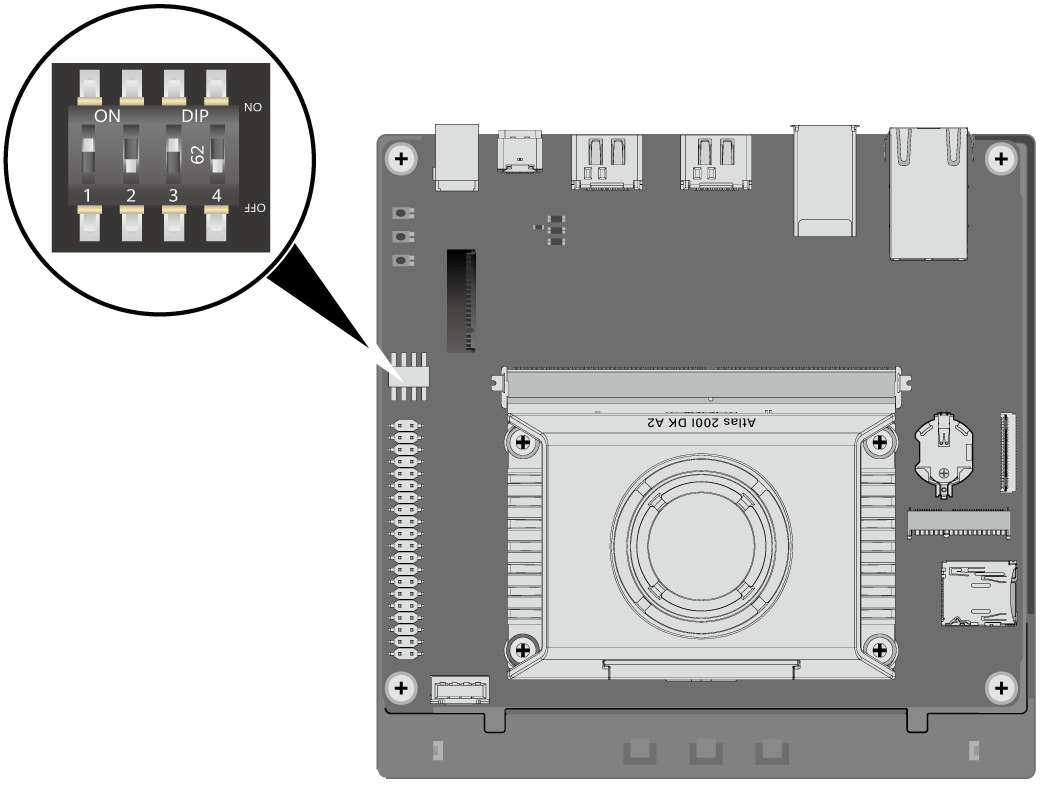
使用网线连接开发板套件和PC。
给开发者套件上电后
Step4 登录开发者套件
通过PC共享网络联网(Windows):
控制面板 -> 网络和共享中心 -> 更改适配器设置 ->
右键"WLAN" -> 属性 ->
进入"共享"界面
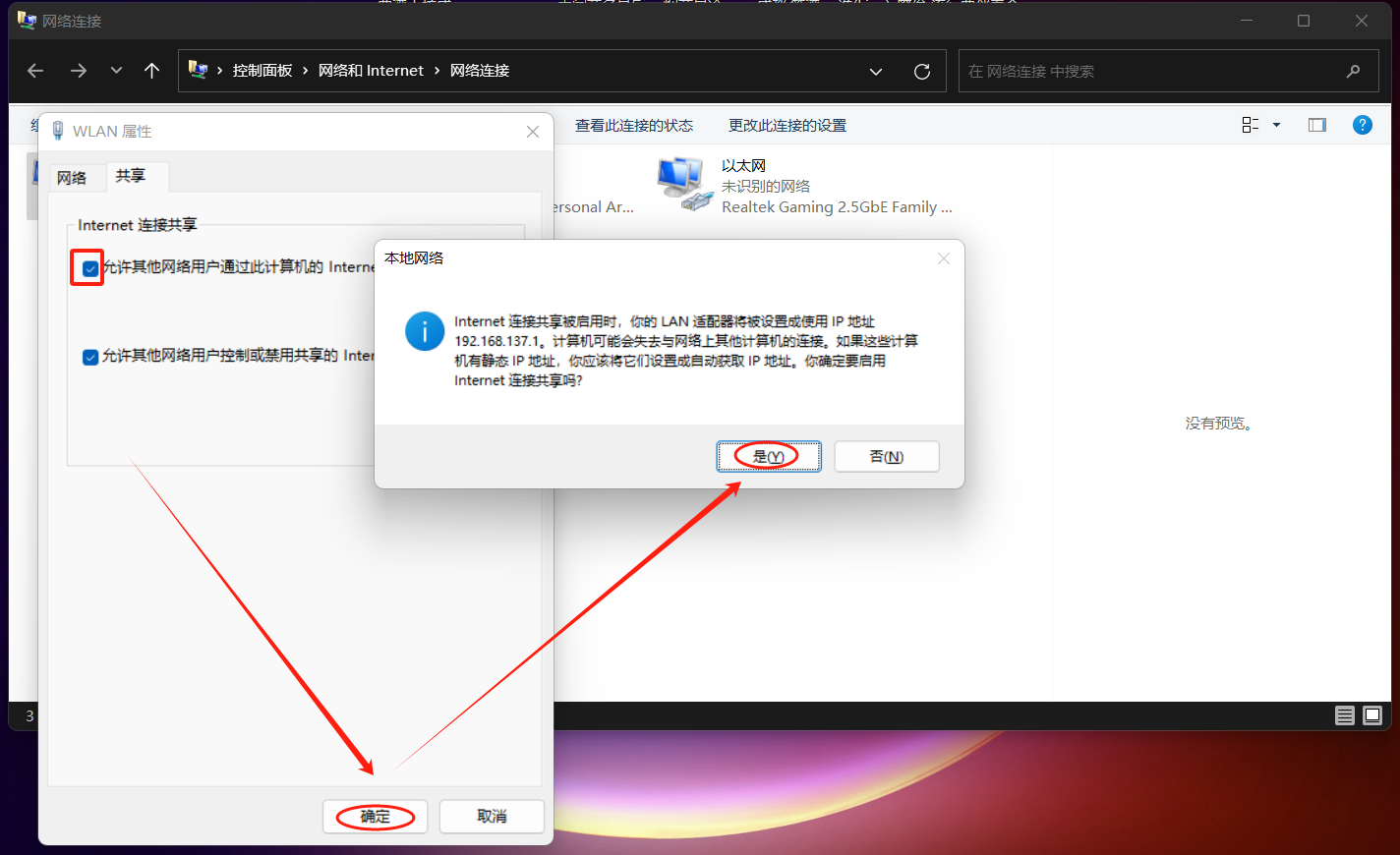
右键"以太网" -> 属性 ->
进入"网络"界面 -> 双击"Internet 协议版本 4(TCP/IPv4)" -> 修改IP地址与子网掩码
(PC需设置IP与开发板处于同一网段。这里使用192.168.137.102为例)

确认保存。
PC下载并解压SSH远程登录工具"MobaXterm_Personal_22.2.exe"(或者进入官网下载)
打开SSH远程登录工具"MobaXterm_Personal_22.2.exe" -> Session -> SSH
-> 填写实际与PC连接的开发者套件网口IP(制卡中配置的IP地址,默认为192.168.137.100)
-> 勾选"Specify username"选项,填写用户名(这里使用root)
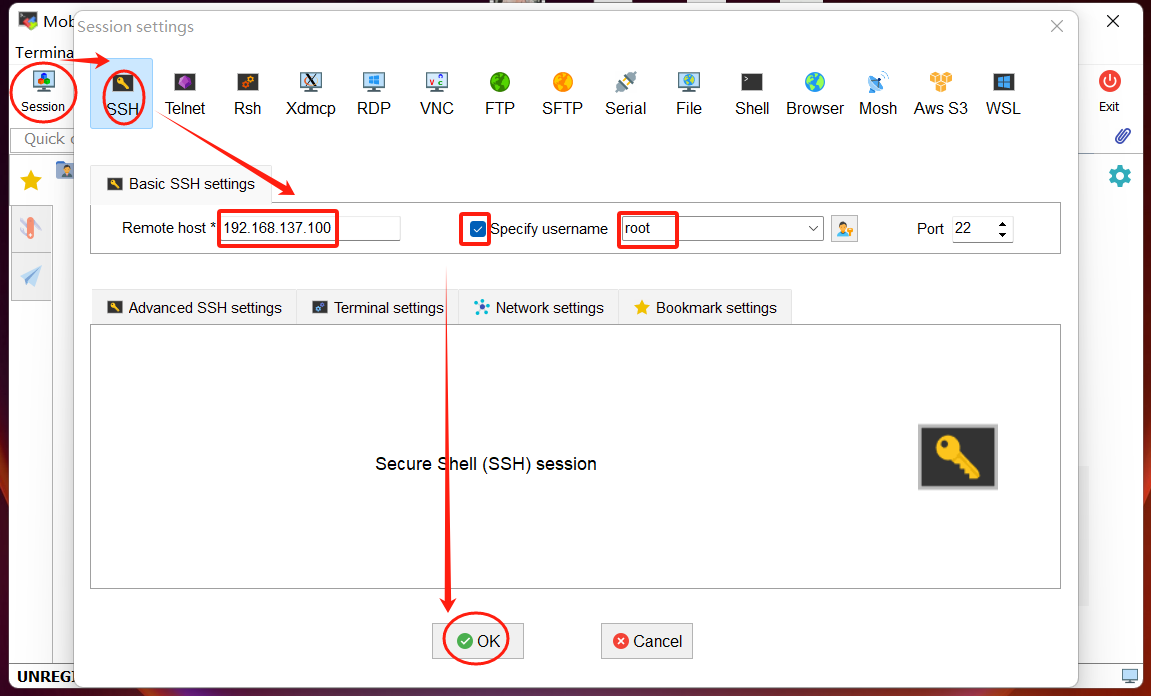
-> Accept
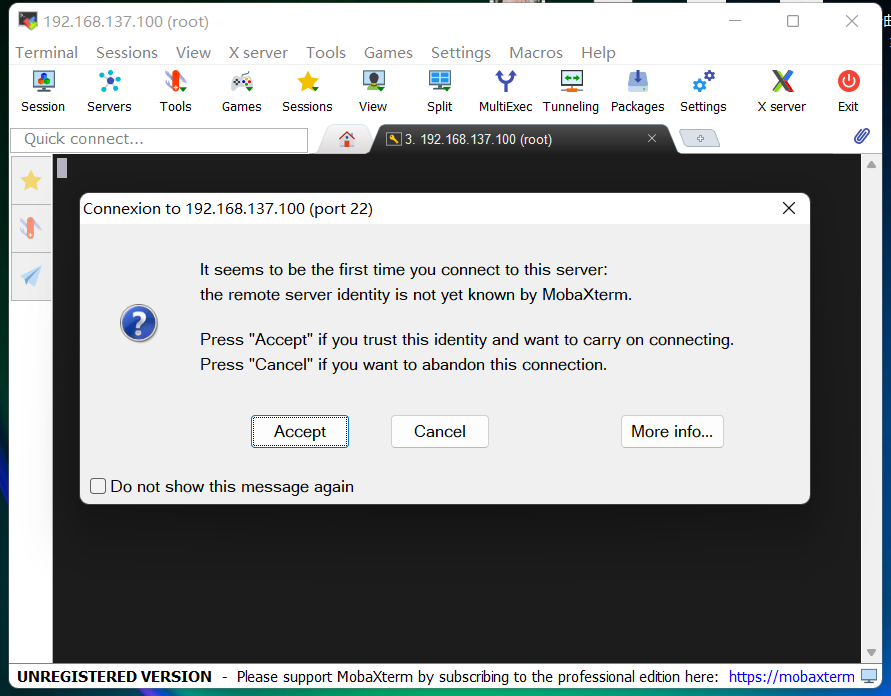
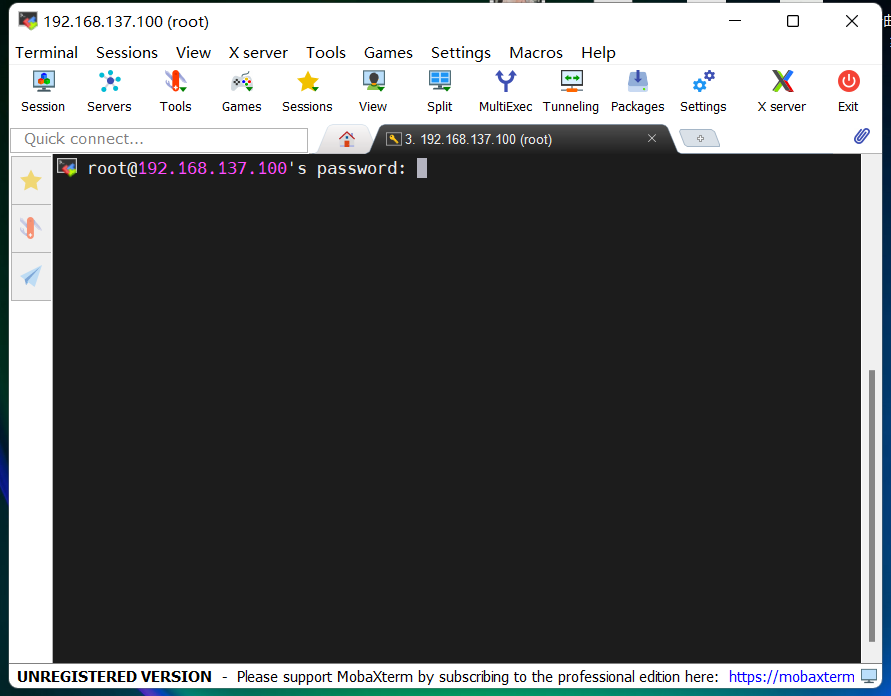
-> 输入root用户名登录密码(默认为Mind@123)
输入密码时,界面不会显示密码和输入位数,输入密码后在键盘按Enter键即可
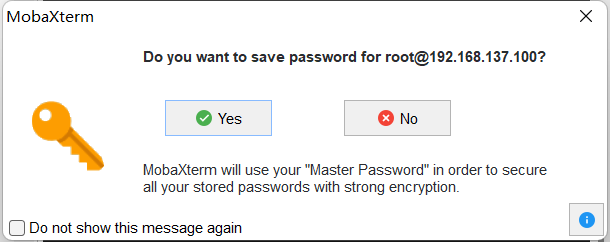
-> 界面会出现保存密码提示,可以单击"No",不保存密码直接登录开发者套件。
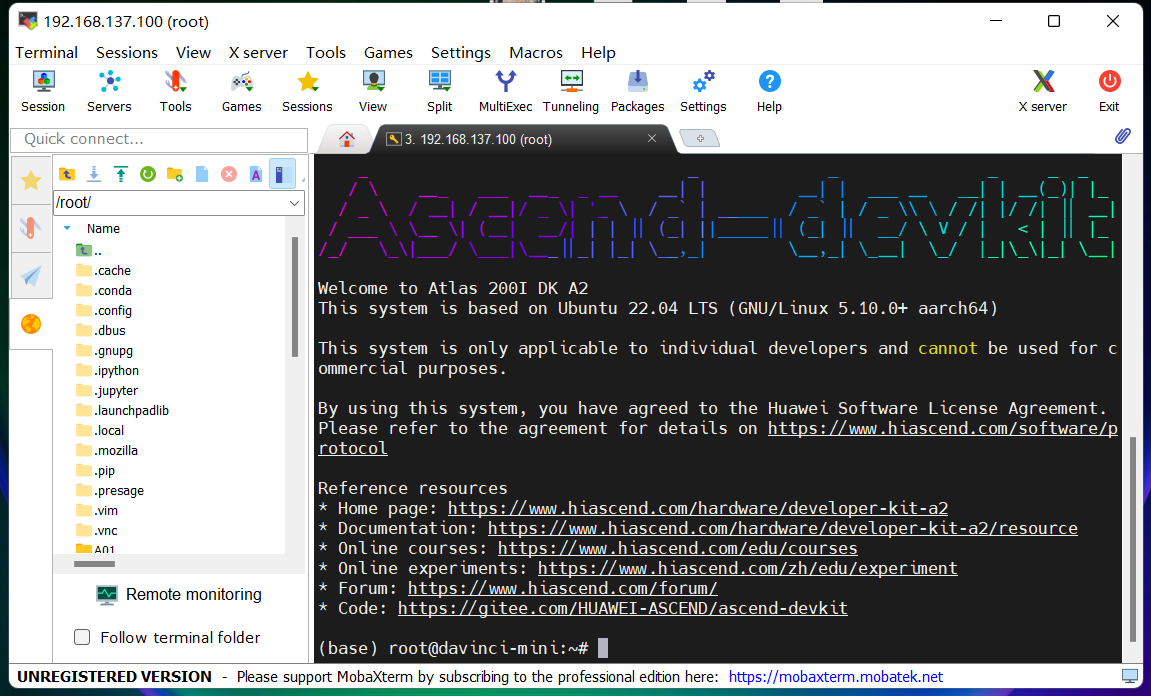
Step5 确认开发者套件成功联网
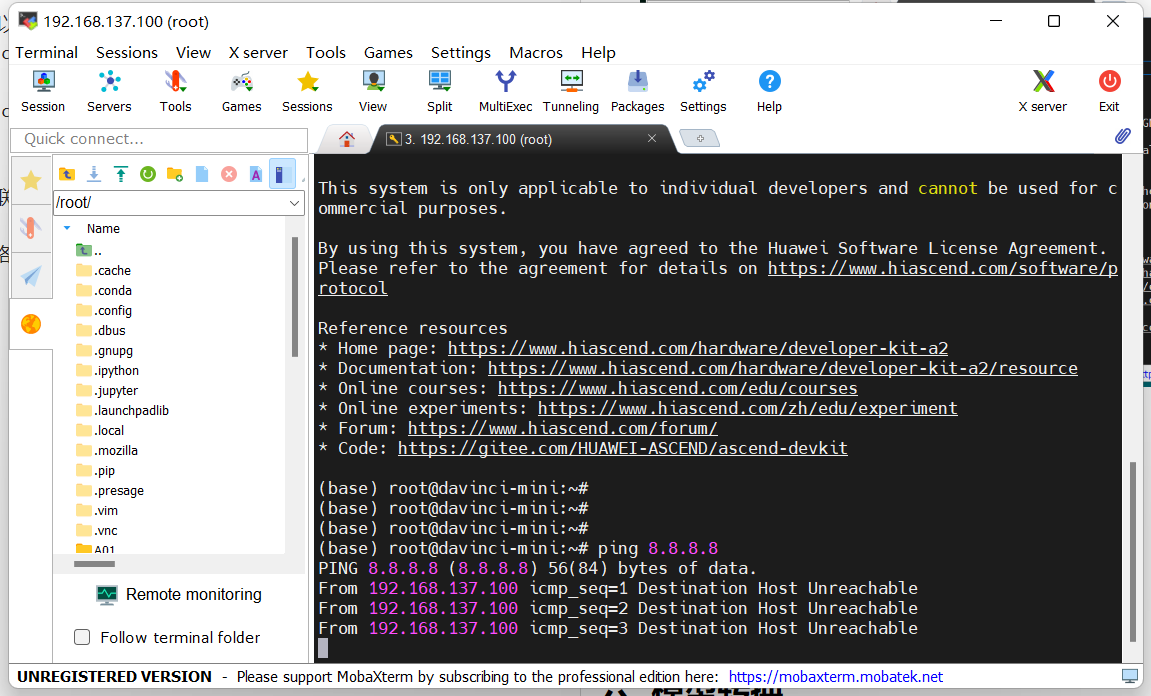
通过能否ping通进行检验网络
输入ping 8.8.8.8或者ping www.baidu.com
若回显如图所示,则说明开发者套件还未成功联网。
请继续后续命令配置操作。
输入ip ro回显如下
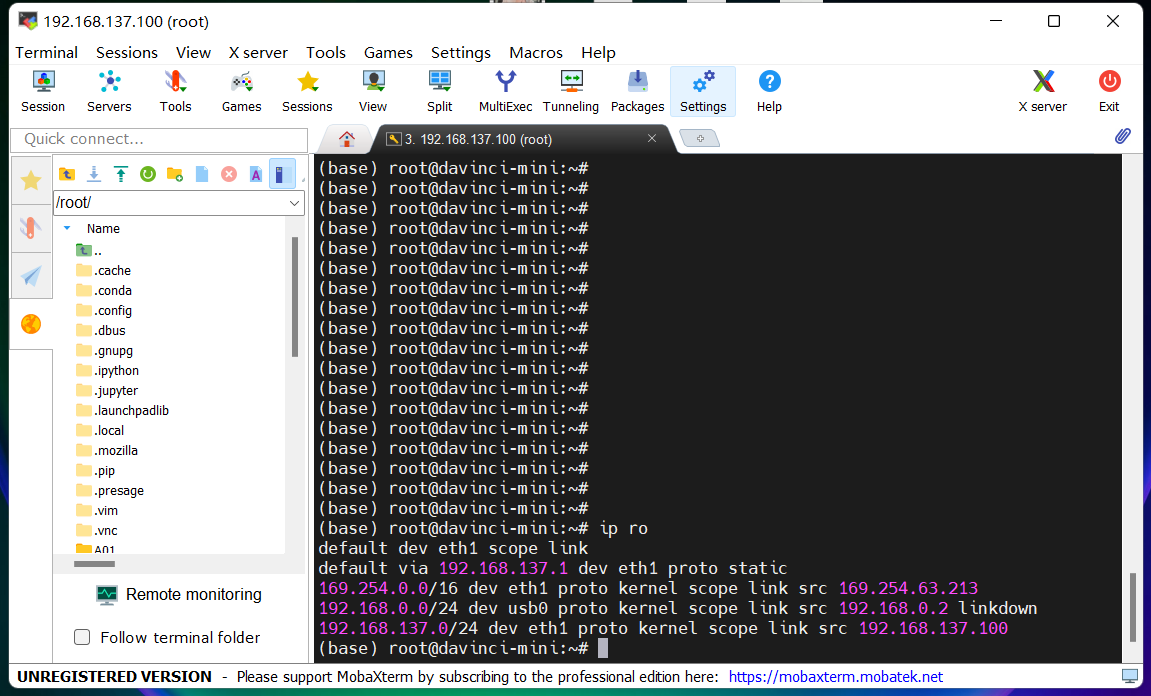
删除多余的路由
输入ip ro del default via 192.168.137.1添加丢失的路由
输入sudo ip route add default via 192.168.137.102 dev eth1 metric 1
注:这里填写的IP是前文控制面板中填写的IP地址
输入ip ro回显如下
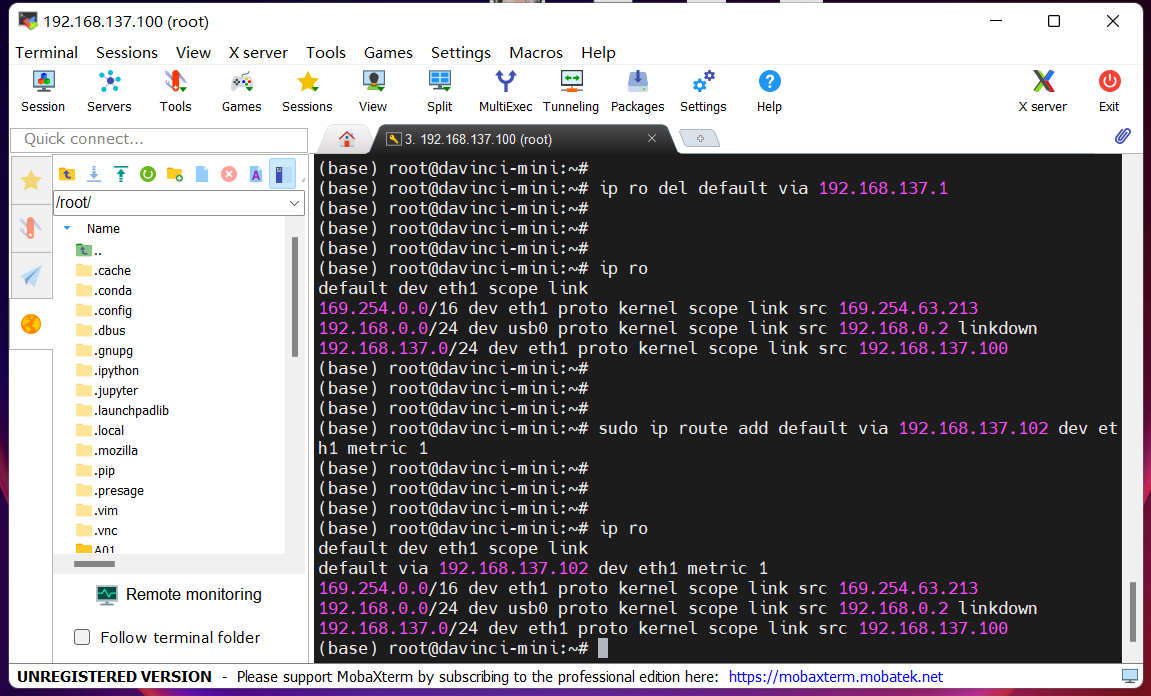
通过能否ping通进行检验网络
输入ping 8.8.8.8或者ping www.baidu.com
若回显如图所示,则说明开发者套件已经成功联网。
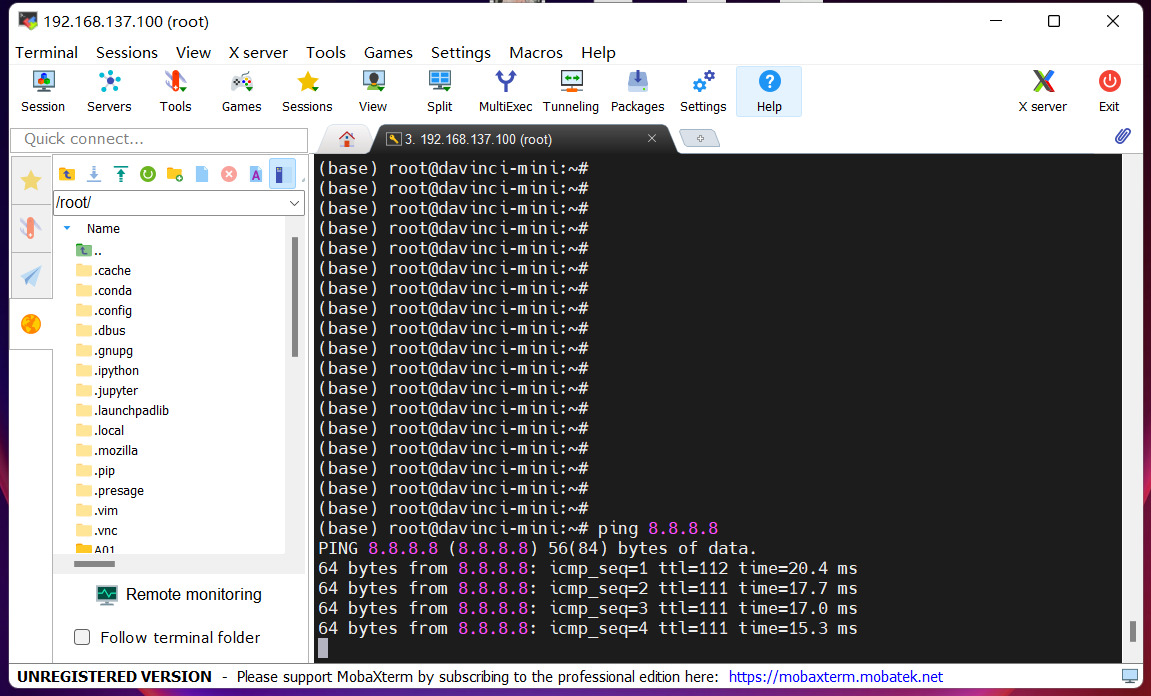

(若正确配置网络后仍无法联网,请参考昇腾官网文档-正确配置网络后仍无法联网)
Step6 为开发者套件添加推理阶段项目工程文件
上传
将推理阶段项目工程文件压缩包上传到开发者套套件
(可以通过拖拽文件的方法上传到MobaXterm)
解压
打开"Terminal"命令行终端界面 ->
执行以下命令,解压项目工程文件压缩包
unzip unet_sdk.zip
unzip unet_cann.zip
模型转换工程目录结构如下:
├── unet_sdk
├── model
│ ├──air2om.sh // air模型转om脚本
│ ├──xxx.air //训练阶段导出的air模型
│ ├──aipp_unet_simple_opencv.cfg // aipp文件
│ ├──xxx.om //训练转换产生的om模型推理阶段工程目录结构如下:
├── unet_cann
├── main.py // 推理文件
├── image.png //图片数据
├── mask.png //标签数据注:
接下来就可以继续旅程,进入推理阶段。
若中途暂停或完成实验,记得将开发者套件关机和下电;
若之后返回或继续实验,再次将开发者套件开机。
如果开发板下电断开连接,重新上电后PC不会主动再次连接,需要更新状态(例如取消网络共享+再次共享)
七. 执行推理
Step1 acl推理脚本
打开unet_cann/main.py文件
内容如下,可根据实际开发情况进行修改。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import cv2 # 图片处理三方库,用于对图片进行前后处理
import numpy as np # 用于对多维数组进行计算
from albumentations.augmentations import transforms # 数据增强库,用于对图片进行变换
import acl # acl 推理文件库
def sigmoid(x):
y = 1.0 / (1 + np.exp(-x)) # 对矩阵的每个元素执行 1/(1+e^(-x))
return y
def plot_mask(img, msk):
""" 将推理得到的 mask 覆盖到原图上 """
msk = msk + 0.5 # 将像素值范围变换到 0.5~1.5, 有利于下面转为二值图
msk = cv2.resize(msk, (img.shape[1], img.shape[0])) # 将 mask 缩放到原图大小
msk = np.array(msk, np.uint8) # 转为二值图, 只包含 0 和 1
# 从 mask 中找到轮廓线, 其中第二个参数为轮廓检测的模式, 第三个参数为轮廓的近似方法
# cv2.RETR_EXTERNAL 表示只检测外轮廓, cv2.CHAIN_APPROX_SIMPLE 表示压缩水平方向、
# 垂直方向、对角线方向的元素, 只保留该方向的终点坐标, 例如一个矩形轮廓只需要4个点来保存轮廓信息
# contours 为返回的轮廓(list)
contours, _ = cv2.findContours(msk, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 在原图上画出轮廓, 其中 img 为原图, contours 为检测到的轮廓列表
# 第三个参数表示绘制 contours 中的哪条轮廓, -1 表示绘制所有轮廓
# 第四个参数表示颜色, (0, 0, 255)表示红色, 第五个参数表示轮廓线的宽度
cv2.drawContours(img, contours, -1, (0, 0, 255), 1)
# 将轮廓线以内(即分割区域)覆盖上一层红色
img[..., 2] = np.where(msk == 1, 255, img[..., 2])
return img
# 初始化变量
pic_input = 'image.png' # 单张图片
model_path = "../unet_sdk/model/unet_hw960_bs1.om" # 模型路径
num_class = 2 # 类别数量, 需要根据模型结构、任务类别进行改变;
device_id = 0 # 指定运算的Device
print("init resource stage:")
# acl初始化
ret = acl.init()
ret = acl.rt.set_device(device_id) # 指定运算的Device
context, ret = acl.rt.create_context(device_id) # 显式创建一个Context,用于管理Stream对象
stream, ret = acl.rt.create_stream() # 显式创建一个Stream, 用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序执行任务
print("Init resource success")
# 加载模型
model_id, ret = acl.mdl.load_from_file(model_path) # 加载离线模型文件, 返回标识模型的ID
model_desc = acl.mdl.create_desc() # 初始化模型描述信息, 包括模型输入个数、输入维度、输出个数、输出维度等信息
ret = acl.mdl.get_desc(model_desc, model_id) # 根据加载成功的模型的ID, 获取该模型的描述信息
print("Init model resource success")
img_bgr = cv2.imread(pic_input) # 读入图片
img = cv2.resize(img_bgr, (960,960)) # 将原图缩放到 960*960 大小
img = transforms.Normalize().apply(img) # 将像素值标准化(减去均值除以方差)
img = img.astype('float32') / 255 # 将像素值缩放到 0~1 范围内
img = img.transpose(2, 0, 1) # 将形状转换为 channel first (3, 96, 96)
# 准备输入数据集
input_list = [img, ] # 初始化输入数据列表
input_num = acl.mdl.get_num_inputs(model_desc) # 得到模型输入个数
input_dataset = acl.mdl.create_dataset() # 创建输入数据
for i in range(input_num):
input_data = input_list[i] # 得到每个输入数据
# 得到每个输入数据流的指针(input_ptr)和所占字节数(size)
size = input_data.size * input_data.itemsize # 得到所占字节数
bytes_data=input_data.tobytes() # 将每个输入数据转换为字节流
input_ptr=acl.util.bytes_to_ptr(bytes_data) # 得到输入数据指针
model_size = acl.mdl.get_input_size_by_index(model_desc, i) # 从模型信息中得到输入所占字节数
# if size != model_size: # 判断所分配的内存是否和模型的输入大小相符
# print(" Input[%d] size: %d not equal om size: %d" % (i, size, model_size) + ", may cause inference result error, please check model input")
dataset_buffer = acl.create_data_buffer(input_ptr, size) # 为每个输入创建 buffer
_, ret = acl.mdl.add_dataset_buffer(input_dataset, dataset_buffer) # 将每个 buffer 添加到输入数据中
print("Create model input dataset success")
# 准备输出数据集
output_size = acl.mdl.get_num_outputs(model_desc) # 得到模型输出个数
output_dataset = acl.mdl.create_dataset() # 创建输出数据
for i in range(output_size):
size = acl.mdl.get_output_size_by_index(model_desc, i) # 得到每个输出所占内存大小
buf, ret = acl.rt.malloc(size, 2) # 为输出分配内存。
dataset_buffer = acl.create_data_buffer(buf, size) # 为每个输出创建 buffer
_, ret = acl.mdl.add_dataset_buffer(output_dataset, dataset_buffer) # 将每个 buffer 添加到输出数据中
if ret: # 若分配出现错误, 则释放内存
acl.rt.free(buf)
acl.destroy_data_buffer(dataset_buffer)
print("Create model output dataset success")
# 模型推理, 得到的输出将写入 output_dataset 中
ret = acl.mdl.execute(model_id, input_dataset, output_dataset)
# 解析 output_dataset, 得到模型输出列表
model_output = [] # 模型输出列表
for i in range(output_size):
buf = acl.mdl.get_dataset_buffer(output_dataset, i) # 获取每个输出buffer
data_addr = acl.get_data_buffer_addr(buf) # 获取输出buffer的地址
size = int(acl.get_data_buffer_size(buf)) # 获取输出buffer的字节数
byte_data = acl.util.ptr_to_bytes(data_addr, size) # 将指针转为字节流数据
dims = tuple(acl.mdl.get_output_dims(model_desc, i)[0]["dims"]) # 从模型信息中得到每个输出的维度信息
output_data = np.frombuffer(byte_data, dtype=np.float32).reshape(dims) # 将 output_data 以流的形式读入转化成 ndarray 对象
model_output.append(output_data) # 添加到模型输出列表
x0 = 2200 # w:2200~4000; h:1000~2800
y0 = 1000
x1 = 4000
y1 = 2800
ori_w = x1 - x0
ori_h = y1 - y0
def _process_mask(mask_path):
# 手动裁剪
mask = cv2.imread( mask_path , cv2.IMREAD_GRAYSCALE )
# [y0:y1, x0:x1]
return mask[y0:y1, x0:x1]
# 后处理
model_out_msk = model_output[0] # 取出模型推理结果, 推理结果形状为 (1, 1, 96, 96),即(batchsize, num_class, height, width)
model_out_msk = _process_mask("mask.png") # 抠图后的shape, hw
# model_out_msk = sigmoid(model_out_msk[0][0]) # 将模型输出变换到 0~1 范围内
img_to_save = plot_mask(img_bgr, model_out_msk) # 将处理后的输出画在原图上, 并返回
# 保存图片到文件
cv2.imwrite('result.png', img_to_save)
# 释放输出资源, 包括数据结构和内存
num = acl.mdl.get_dataset_num_buffers(output_dataset) # 获取输出个数
for i in range(num):
data_buf = acl.mdl.get_dataset_buffer(output_dataset, i) # 获取每个输出buffer
if data_buf:
data_addr = acl.get_data_buffer_addr(data_buf) # 获取buffer的地址
acl.rt.free(data_addr) # 手动释放 acl.rt.malloc 所分配的内存
ret = acl.destroy_data_buffer(data_buf) # 销毁每个输出buffer (销毁 aclDataBuffer 类型)
ret = acl.mdl.destroy_dataset(output_dataset) # 销毁输出数据 (销毁 aclmdlDataset类型的数据)
# 卸载模型
if model_id:
ret = acl.mdl.unload(model_id)
# 释放模型描述信息
if model_desc:
ret = acl.mdl.destroy_desc(model_desc)
# 释放 stream
if stream:
ret = acl.rt.destroy_stream(stream)
# 释放 Context
if context:
ret = acl.rt.destroy_context(context)
# 释放Device
acl.rt.reset_device(device_id)
acl.finalize()
print("Release acl resource success")Step2 执行脚本
打开Terminal命令行终端界面:确保是否在工程目录unet_cann/路径下
输入cd /root/project/unet_cann
运行示例,输入python3 main.py
输出结果:

注:
到此我们就已经走过了从Ascend910训练到Ascend310推理的昇腾开发全流程。
更多内容深入参考下方学习资源推荐
学习资源推荐
昇腾官网
- 文档教程
昇腾官网文档-CANN-推理应用开发 - 视频教程
昇腾官网->在线课程->昇腾推理应用开发及调优
gitee代码仓Ascend / samples
https://gitee.com/ascend/samples/tree/master/inference