全连接神经网络
上一篇文章中我们介绍了自动微分的基本概念,现在可以介绍神经网络更通用的形式了。
一个 L层的带偏置项的全连接神经网络(也叫多层感知机),通过下面的迭代式定义:
zi+1=σi(WiTzi+bi), i=1,...,Lhθ(x)≡zL+1z1≡x
参数是 θ={W1:L,b1:L}, σi(x)是一个非线性激活函数。
矩阵形式写法中广播的奥秘
我们思考一下上面式子中的矩阵形式
Zi+1=σi(ZiWi+1biT)
细心的话可以注意到,由于 Zi+1∈Rm×n,为了使矩阵维度相匹配的话,那么 1biT∈Rm×n,但是实际上 biT∈Rm×n。
在实际操作中,我们可以通过广播(broadcast) 操作将 biT的维度扩充。
- 对于一个 n×1的向量(或者更高维度的张量),broadcast操作将它看作一个 n×p的矩阵,将原来的向量重复p次
- 因此我们可以写成这种矩阵形式 Zi+1=σi(ZiWi+1biT)
- broadcast操作并不拷贝数据
全连接网络中关键问题
为了训练一个全连接神经网络(或者任何其它的深度神经网络),我们需要弄清楚如下几个特定的问题:
- 我们应该怎么选择网络的宽度和深度?
- 我们怎么优化我们的目标?("SGD"是最简单的答案,但是这不是实践中最常用的方法)
- 我们怎么初始化网络的权重参数?
- 我们怎么可以确保网络在经历了多轮迭代优化后,还可以继续训练下去?
这些问题(仍然)没有明确的答案,对于深度学习来说,它们最终会针对特定问题,但我们将介绍一些基本原则。
优化器
梯度下降
我们考虑一个针对某一个函数 f的通用梯度下降参数更新策略,可以写成如下形式:
θt+1=θt−α∇θf(θt)
其中 α>0(学习率), ∇θf(θt)是 f对参数 θt的梯度。
梯度下降方法在局部区域内是函数值下降最快的地方,但是从更大的时间跨度来看,其下降值可能在振荡。
梯度下降图解
对于 θ∈R2,考虑二次函数 f(θ)=21θTpθ+qTθ, P是正定的矩阵(所有特征值都是正数)
下面是采取不同学习率,不断迭代梯度下降的图示说明: 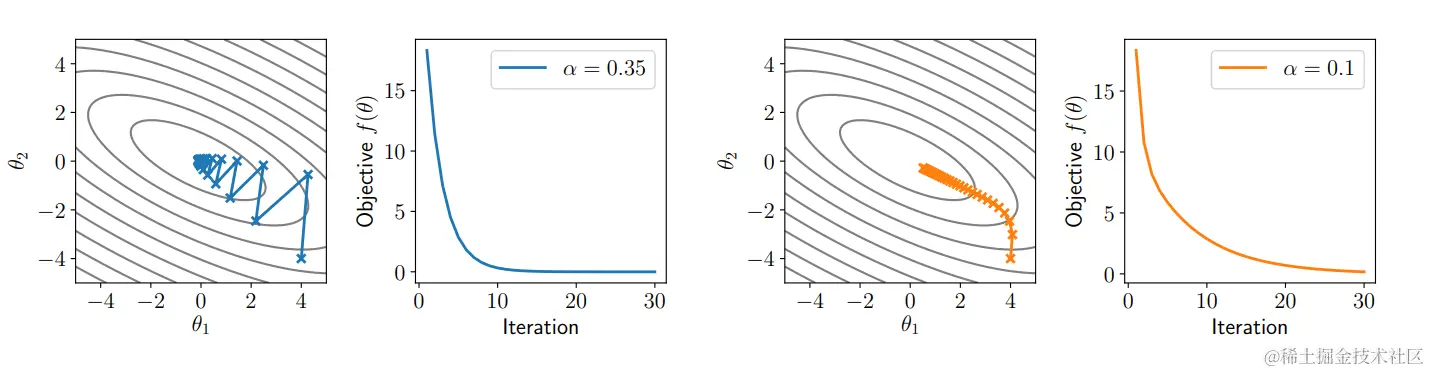
牛顿法
一种能够把握更多全局信息的方法是"牛顿法",通过黑塞矩阵(矩阵的二阶导)的逆来缩放梯度:
θt+1=θt−α(∇θ2f(θt))−1∇θf(θt)
其中 ∇θ2f(θt)就是黑塞矩阵, n×n的矩阵大小,矩阵元素是 n个参数的二阶导。
相当于使用二阶泰勒将函数近似为二次函数展开,然后求解最优解。
如果取 α=1,则是称为"整步牛顿法"否则称为"阻尼牛顿法"。
牛顿法图解
在这个问题中,如果取 α=1,那么只需要迭代一次就可以达到最优解。 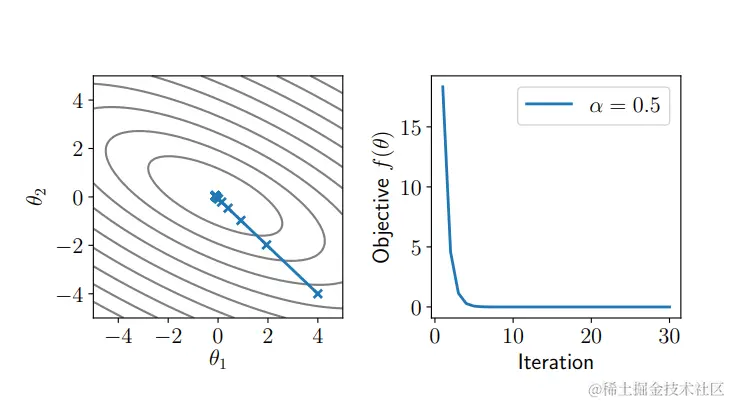
但是这个方法在深度学习中没有太大的实际意义,主要有下面一些原因:
- 局部最优性:牛顿法通常只能找到局部最优解,而不是全局最优解。在非凸优化问题中,可能存在多个局部最优解,牛顿法可能会陷入这些局部最优解中的一个,而无法找到全局最优解。
- Hessian矩阵的正定性:牛顿法要求目标函数在迭代点附近是二次可微的,并且其Hessian矩阵(即二阶导数矩阵)是正定的,这样才能保证当前迭代点是一个局部最小点。在非凸问题中,Hessian矩阵可能不是正定的,或者在某些区域是不定的,这使得牛顿法无法保证收敛到局部最小点。
- 计算复杂性:牛顿法需要计算和存储目标函数的Hessian矩阵,这在高维问题中可能导致计算复杂性和存储需求非常高。对于大规模的非凸优化问题,这种计算和存储成本可能是不可接受的。
- 数值稳定性:在非凸问题中,Hessian矩阵可能存在病态情况,导致牛顿法的迭代过程不稳定,甚至可能发散。
- 收敛速度:牛顿法的收敛速度依赖于初始点的选择和目标函数的性质。在非凸问题中,由于可能存在多个局部最小值,牛顿法的收敛速度可能会很慢,或者在某些情况下根本不收敛。
动量(momentum)
有没有一种折中的方案,使得可以像梯度下降方法一样计算简单,然后又能够像牛顿法那样能更具有全局性呢?
答案就是使用动量来更新参数,动量考虑了先前梯度的移动平均值:
ut+1=βut+(1−β)∇θf(θt)θt+1=θt−αut+1
其中 α还是前面提到的学习率参数, β是动量的参数。
- 通常将动量写成这两种形式 ut+1=βut+∇θf(θt) 或者 ut+1=βut+α∇θf(θt),但是用上面那种写法更能体现出 u是对梯度的放缩尺度的感觉
带动量的梯度下降法图解
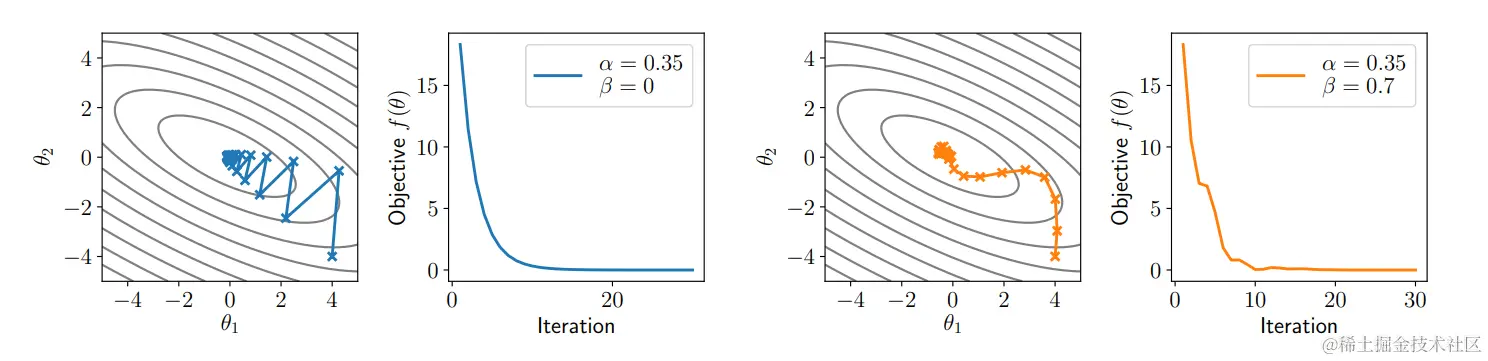
从图中可以看到,带动量的梯度下降方法比单纯的梯度下降方法更平滑,但是还是存在振荡和函数值不下降的情况。
尽管如此,在实践中训练深度网络时经常有用。
无偏动量
动量 ut (如果初始化为零,这是常见的),在初始迭代中会比在后面的迭代中小。
为了消除这种"偏差"使得更新在所有迭代中具有相同的预期幅度,我们可以使用下面的方式:
θt+1=θt−αut+1/(1−βt+1)
无偏动量和上述带动量的优化对比图如下: 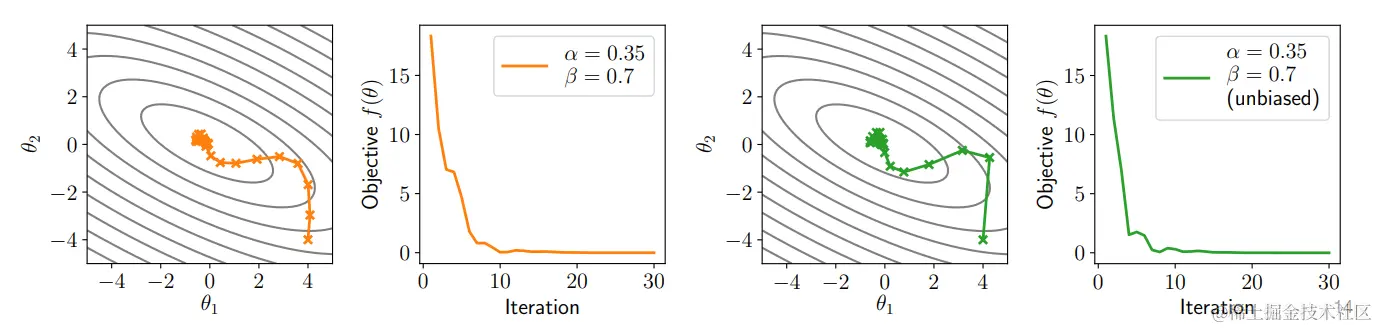
Nesterov 动量
Nesterov 动量概念中的一个有用技巧,可以计算"下一个"点的动量来进行参数更新:
ut+1=βut+(1−β)∇θf(θt)θt+1=θt−αut+1⟹ut+1=βut+(1−β)∇θf(θt−αut)θt+1=θt−αut+1
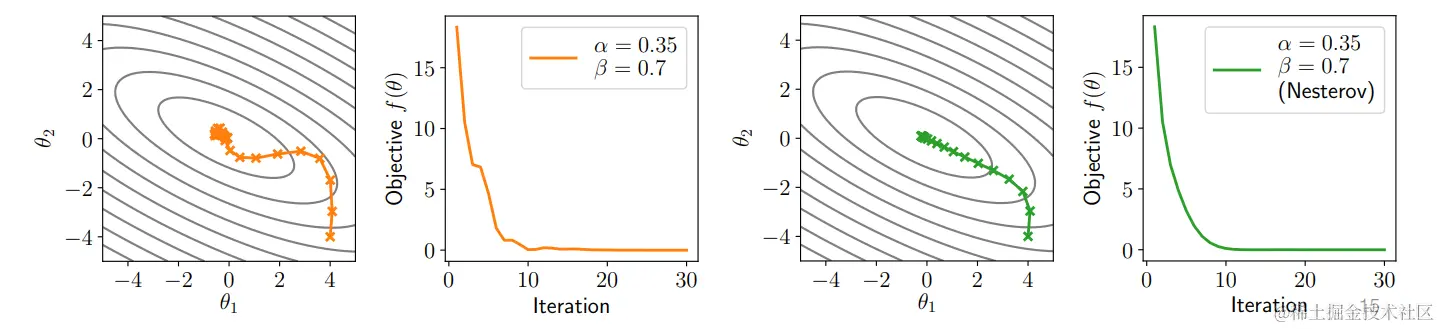 这种方式对凸优化来说是件 "好事",对深度网络也有帮助。
这种方式对凸优化来说是件 "好事",对深度网络也有帮助。
Adam
对于不同的参数,梯度的大小可能会有很大的不同,尤其是在不同的深度网络层、不同的层类型等情况下。
深度网络的不同层、不同层类型等,所谓的自适应梯度方法试图在迭代过程中估计这一比例 然后相应地重新调整梯度更新的规模
深度学习中最广泛使用的自适应梯度方法是Adam算法、它结合了动量和自适应规模估计
ut+1=β1ut+(1−β1)∇θf(θt)vt+1=β2vt+(1−β2)(∇θf(θt))2θt+1=θt−αut+1/(vt+11/2+ϵ)
Adma是否是 "好 "的优化器在深度学习领域争论不休,但它在实践中似乎经常运行得很好。 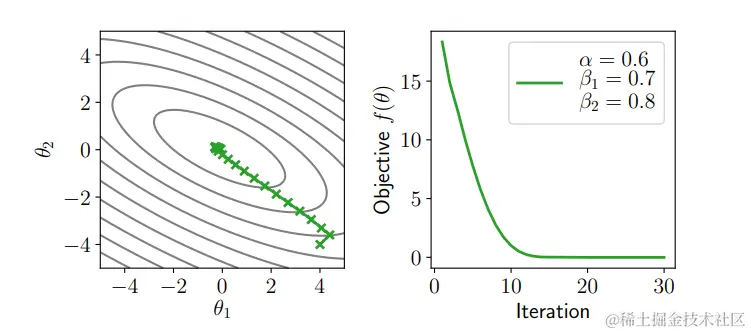
随机变量
前面的例子都考虑了参数的批量更新,但最重要的优化选择是使用随机变量。最重要的优化选择是使用随机变量。
回忆我们机器学习的优化问题:
θminimizem1i=1∑mℓ(hθ(x(i)),y(i))
即对损失的经验期望最小化.
我们只需计算一个例子子集(称为minibatch)的损失梯度,就能得到梯度的噪声估计值(但无偏)。
随机梯度下降
这样,我们就又回到了 SGD 算法,重复进行批次 B⊂{1,...,m}的运算。
θt+1=θt−Bαi∈B∑∇θℓ(h(x(i)),y(i))
与其采取几个昂贵、无噪音的步骤,我们不如采取许多便宜、又噪音的步骤,这样每台计算机的性能就会大大提高 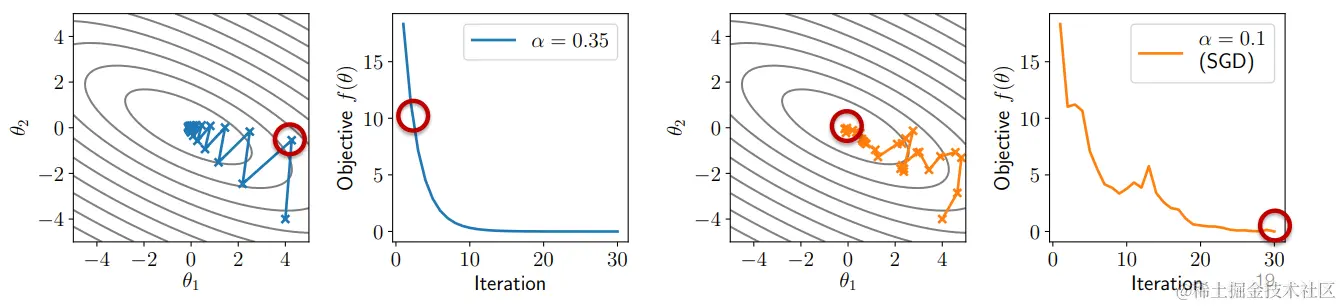
最重要的收获
- 迄今为止,您所看到的所有优化方法实际上只是以随机形式使用。
- 从简单的(凸、二次)优化问题中,你能获得的关于这些优化方法的有效直觉是有限的。对这些优化方法的有效直觉是有限的。
- 您需要不断尝试,才能理解/直观地了解这些方法对不同类型深度网络的实际影响。
初始化
初始化权重
回忆我们使用随机梯度下降方法迭代优化参数的公式:
Wi:=Wi−α∇Wiℓ(hθ(X),y)
但是我们应该怎样选择什么样的值来初始化 Wi, bi呢?(直接使用0来初始化?)
我们来看当时手动推导反向传播算法的前向传播和反向传播的过程(不带偏置项):
Zi+1=σi(ZiWi)Gi=(Gi+1 ∘ σi′(ZiWi))WiT
如果 Wi=0,那么 Gj=0,对于 j≤i⟹∇Wiℓ(hθ(X),y)=0,因此取 Wi=0,会使得梯度消失从而更新不了参数。
不同初始化对训练的影响
我们简单的把权重随机初始化为一个正态分布 Wi∼N(0,σ2I)
选择不同的方差 σ2将会影响下面两个部分:
- 前向激活函数输出 Zi的范数
- 梯度的范数
下面是对方差取不同值使用MNIST数据集,隐藏层神经元100个,激活函数为relu总共50层的神经网络进行训练,对比上述两个范数的区别。 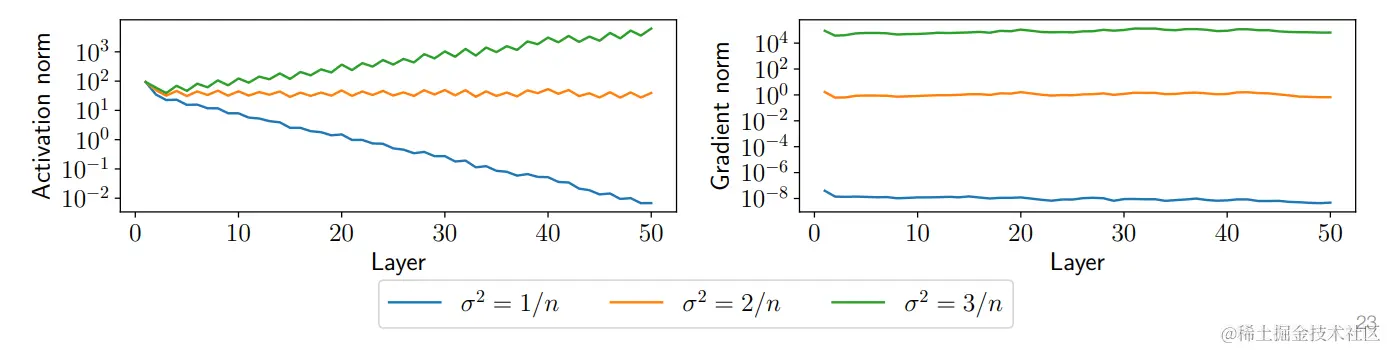
权重更新的并不大
- 你可能会认为,无论初始化如何,网络参数都会收敛到某个相似的点区域。
- 事实并非如此......权重往往更接近其初始化值,而不是经过优化后的 "最终"点。
- 最终结论:初始化对于神经网络训练很重要。
是什么导致了这种影响
考虑独立随机变量 x∼N(0,1), w∼N(0,n1),那么有
Exiwi=ExiEwi=0,Varxiwi=VarxiVarwi=n1
故 EwTx=0,VarwTx=1 ( wTx→N(0,1)有中心极限定理可得)
因此,如果我们使用一个线性激活函数并且有 zi∼N(0,I),Wi∼N(0,n1I),那么有 zi+1=WiT∼N(0,I)
如果我们使用ReLU非线性激活函数,假设有 zi一半的分量将会被置0,因此为了保证 Wi+1和 Wi有同样的方差,需要将 Wi方差乘2,也就是 Wi∼N(0,n2I)(这也是kaiming normal initialization)