0. 引言
从人脸图像中自动去除眼镜的框架是一个具有挑战性的问题,因为它涉及到精确地识别和处理图像中的眼镜以及相关的眩光和有色镜片。以下是该论文可能提出的一些关键点:
(1). 学习框架:
- 数据集构建:创建一个包含戴眼镜和不戴眼镜人脸图像的数据集,其中戴眼镜的图像应包括不同类型和颜色的眼镜。
- 特征提取:开发算法来识别人脸特征,包括眼镜的存在、镜片的颜色和潜在的眩光。
- 眼镜分割:使用图像分割技术来分离眼镜和人脸区域,以便可以独立处理。
- 眼镜去除:设计一个模型来模拟去除眼镜后的人脸外观,可能涉及生成对抗网络(GANs)或其他图像生成技术。
(2). 有色镜片/眩光综合方法:
- 镜片颜色校正:开发算法来估计镜片颜色并将其从人脸图像中中和,以便更清晰地看到眼睛区域。
- 眩光检测与去除:实现技术来识别图像中的眩光区域,并减少或消除其对人脸识别算法的影响。
(3). 人脸识别预处理:
- 数据增强:使用去除眼镜后的图像来增强训练数据集,提高模型对戴眼镜人脸的泛化能力。
- 多任务学习:可能采用多任务学习框架,同时优化眼镜去除和人脸识别任务。
- 模型融合:将眼镜去除模型与现有的人脸识别模型相结合,形成端到端的预处理流程。
(4). 实验和评估:
- 准确率提升:通过对比实验,展示去除眼镜后的人脸识别准确率与原始图像相比的提升。
- 鲁棒性测试:评估算法在不同光照条件、眼镜类型和人脸表情下的鲁棒性。
(5). 实际应用:
- 实时处理:优化算法以实现实时或近实时的眼镜去除,适用于视频监控或实时人脸识别系统。
- 隐私保护:讨论去除眼镜对个人隐私的潜在影响,并提出相应的伦理指导原则。
论文地址:https://arxiv.org/pdf/2008.11042.pdf
1. 概况
人脸识别服务被广泛应用于机场和在线身份识别(eKYC)和智能手机解锁(Face ID)等领域。基于深度学习的最先进的人脸识别技术使这些服务得以投入使用。然而,即使在今天,当眼镜遮住部分人脸时,人脸识别的准确率也会降低。
为了消除眼镜对人脸识别的影响,我们一直在研究摘掉眼镜的技术,并。进行了"改善戴眼镜时训练数据不足的问题,提高眼镜的识别精度"的研究。关于眼镜摘除技术的研究主要采用PCA法和子空间法,但其性能不足,在人脸识别任务中的验证也不够。此外,在改善训练数据缺乏的研究中,研究了一种利用GANs生成戴眼镜的人脸图像的方法,并报道了较高的准确性。
在本文中,我们提出了一个新的框架,在使用GANs的同时,去除眼镜,据报道,GANs是高度准确的。通过使用这个框架对人脸识别进行预处理,我们发现戴上眼镜后,识别准确率明显提高。此外,所提出的框架与传统的GAN方法不同,它可以在不戴眼镜的情况下生成人脸图像,因此它可以用于各种应用,例如用于试用的虚拟化妆。
2. ByeGlassesGAN算法
ByeGlassesGAN的概述如下图所示,ByeGlassesGAN由一个生成器、一个身份提取器和两个鉴别器组成。而生成器(G)由三个编码器(E)、人脸解码器(FD)和分割解码器(SD)组成。
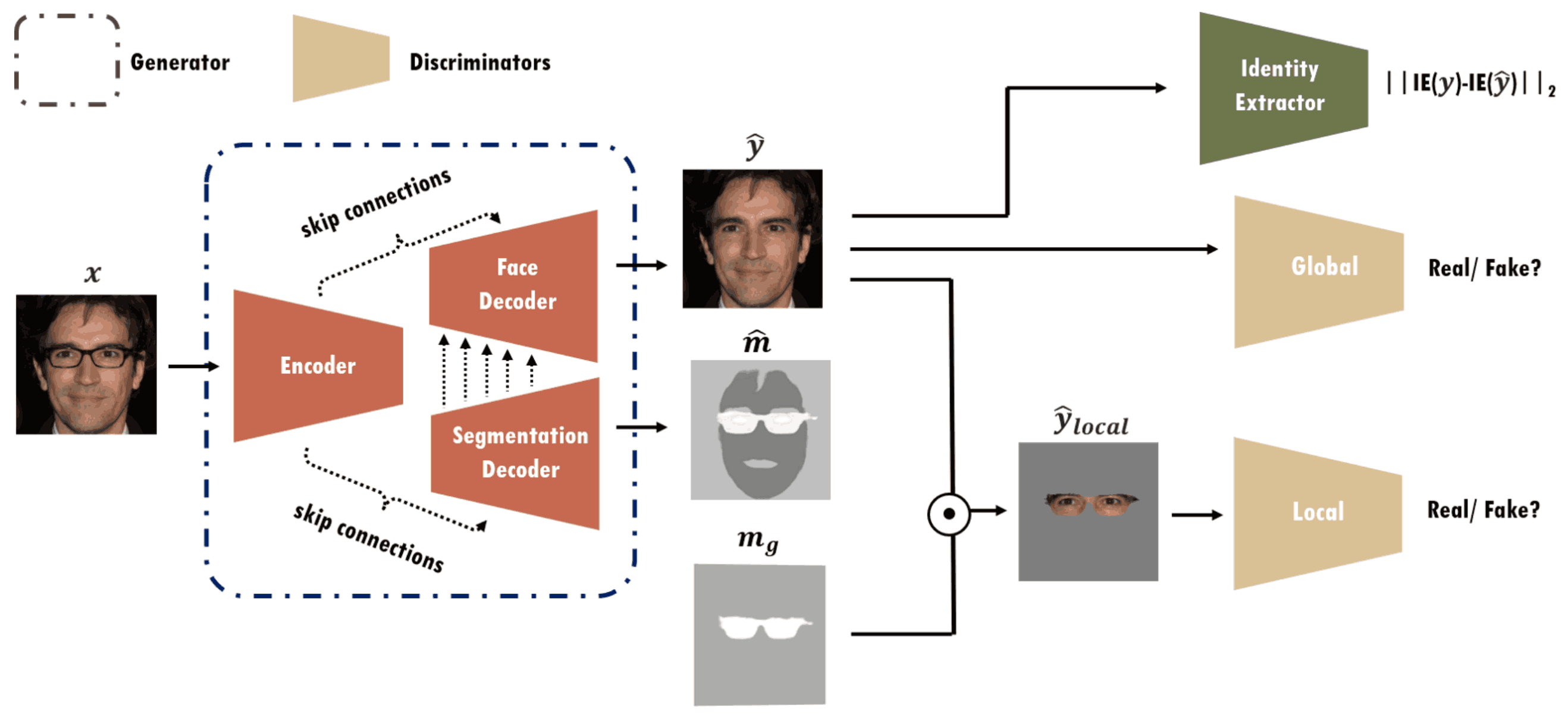
如果你输入一个图像_(x_),你会看到的是编码器_(E)提取人脸特征。那么人脸解码器 (FD_)生成一个被分割解码器(SD)去除眼镜的人脸图像_(y^)。在这种情况下,使用分割解码器(SD_)来分割眼镜和人脸形状的二进制面具。不仅利用眼镜,还利用脸型的二元掩模,我们可以学会更精确地区分眼镜和脸部。该模型可以对眼镜的变化和脸部方向进行稳健的调整。为了提高ByeGlassesGAN的人脸识别准确率,生成的图像(不戴眼镜)是比较真实的图像。(戴上眼镜)且必须与真实形象同一人相认。
为了使生成的图像_(y_)更加真实,我们应用全局和局部判别器来训练它,使其更好地再现整个人脸图像(全局)和更好地再现修复后的眼睛区域(局部)。此外,为了确保即使不戴眼镜也能识别出同一个人,我们使用的是在身份提取器中生成图像_(y)的特征向量与输入图像(y_)之间的距离最小化。
2.用眼镜构建人脸图像数据集
ByeGlassesGAN需要识别同一个人戴眼镜和不戴眼镜。因此,训练模型需要大量的数据集,有眼镜和无眼镜。然而,从被试者那里收集这些数据是不切实际的,所以通过将眼镜与现有的人脸图像相结合来准备数据集。
ByeGlassesGAN使用的是CelebA,CelebA由10177位名人的202599张人脸图像组成,每张图像有40个人脸属性标签。对于这些CelebA人脸图像,首先获得5个地标(左眼、右眼、鼻子、左嘴和右嘴),并将其大小调整为256×256。然后,使用dlib和OpenCV,它将所有图像分为三个人脸方向:正面、左正面和右正面。我们还将CelebA中的1000张戴眼镜的图片的二进制面具手动标注为眼镜池(SG)。其余带眼镜的图像作为测试数据。
这些二进制掩码能准确地知道眼镜在每张图像中的位置,因此可以用来轻松提取1000种不同风格的眼镜。
然后,利用眼镜池(SG)中眼镜的二元掩码和我们刚才分类的人脸方向,将眼镜合成到没有眼镜的图像上(下图左图)。此外,还对镜头颜色、透明度、反射和折射进行了处理,使合成图像看起来更加真实(见下图右图)。

此外,我们使用由CelebAMaskHQ训练的BiSeNet从不戴眼镜的图像中生成人脸形状的二元面具。最后,共获取184862对数据作为训练数据。眼镜池(SG)计划发布数据集,用于眼镜检测、合成和去除的研究。
3.实验
3.1 定性评价
下图是使用CelebA应用EyeGlassesGAN的结果。可以看到,在所有数据中摘掉眼镜,没有任何不适感。生成的二进制掩码还可以分割出准确的区域。
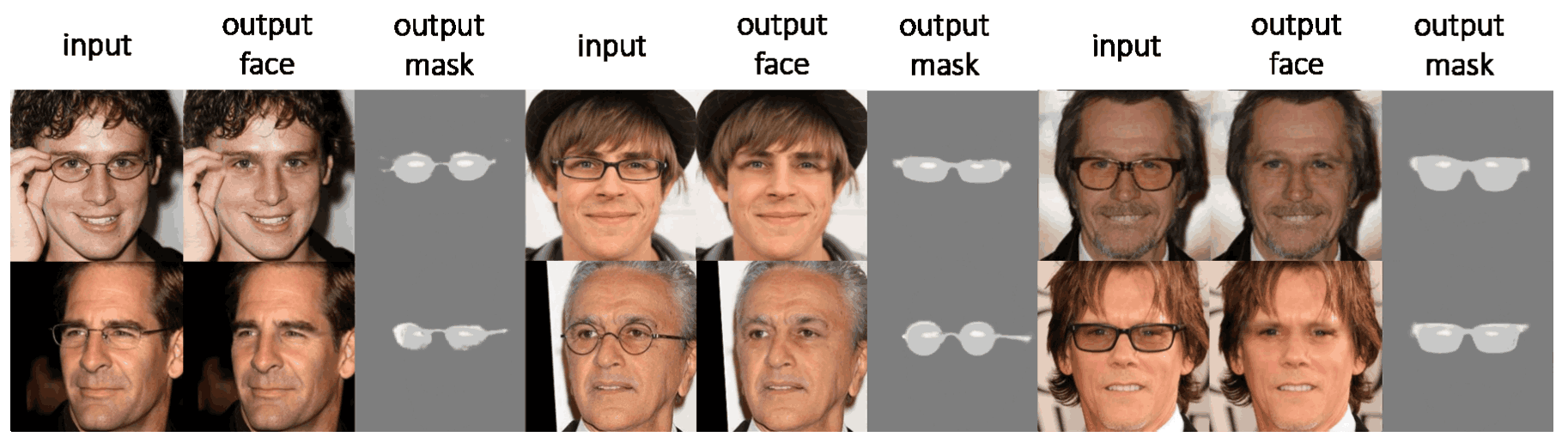
此外,EyeGlassesGAN对不包括在CelebA数据集中的图像的应用也得到了验证。下图是使用Wild数据应用EyeGlassesGAN的结果。

所有这些图片不仅可以摘掉眼镜,还可以很好地配合智能手机和PC等常见摄影设备拍摄的图片。此外,EyeGlassesGAN在合成训练数据时,还考虑到了每张人脸图像的人脸方向,因此系统可以处理非正面的人脸图像。此外,该系统不仅可以去除眼镜框,还可以去除彩色镜片。
另外,在这个实验中,除了ByeGlassesGAN。我们正在用另外两个定制的模型验证分段解码器(SD)。我们正在研究该框架各组成部分的影响。换句话说,我们这里要验证的是三个模型(A、B、C)。(A)是分段解码器(SD)只预测眼镜的二元掩模(Baseline),人脸解码器(FD)和分段解码器(SD)之间没有跳转联系的模型。(B)是一个Segmentation Decoder(SD)预测眼镜和脸型二元面具的模型。同样,BaselineFace Decoder(FD)和Segmentation Decoder(SD)之间没有跳过连接。三)是我们目前看到的完整的EyeGlassesGAN。
结果如下图所示。同样预测脸部形状的模型(B)比只预测眼镜的模型(A)在摘掉眼镜方面的表现要好得多。这被认为是由于脸型提供了暗示,不戴眼镜也能更容易预测脸型。

另外,由于©能够最频繁地摘下眼镜,我们可以看到,在人脸解码器(FD)和分割解码器(SD)之间增加跳过连接,能够更充分地支持人脸解码器(FD).分段解码器(SD)的特征可以与人脸解码器(FD)共享,以确保当人脸不朝前或眼镜不对位时,合成的区域与相邻皮肤区域一致。
此外,我们还将结果与其他现代方法进行了比较,如Pix2pix、CycleGan、StarGAN、ELEGANT、ERGAN和SaGAN。下图是用这些方法取下眼镜的结果。

你可以看到,所有其他方法都比EyeGlassesGAN产生更多的噪音。特别是对比底部三条线的图像,可以看出EyeGlassesGAN能够有效去除镜片反射的眩光。
3.2 量化评估
Frechet Inception Distance(FID)是用来衡量摘镜性能的。FID是量化真实图像和生成图像的分布紧密程度的一种测量方法,假设从初始化得到的特征遵循多变量正态分布,FID距离越近,重现性越好,性能越好。
下表是各种方法的FID。这里我们已经在CelebA和MeGlass两个数据集上进行了测试。真实的图像数据集包含一个没有眼镜的图像,而生成的图像数据集由六个不同的模型组成,应用于带眼镜和摘掉眼镜的人脸图像。如表所示,在CelebA和MeGlass数据集中,在在ByeGlassesGAN中。FID是最小的。

另外,不含分段解码器(SD)的模型。(课时/不含SD)但我们经过验证,经定性评价证实,FID值略高,性能较差,这也是定性评价所证实的。此外,还进行了一项用户研究,将EyeGlassesGAN与其他方法进行比较。从测试集中随机选取7张带眼镜的图像,对所有图像应用不同的眼镜去除模型,结果共有42张图像(=7×6)的眼镜去除。
49名用户被要求对图像进行评分,并计算平均意见分(MOS),即用户对图像质量的评分以5点为单位的加法平均值。
下表是各种方法的MOS,可以看出EyeGlassesGAN的MOS得分最高,被判定为性能最好。
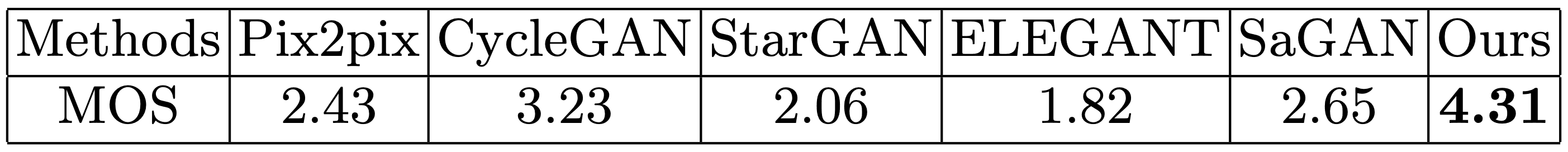
3.3 人脸识别任务的性能评估
应用EyeGlassesGAN作为人脸识别任务的预处理器的效果得到了验证。
首先,我们使用UMDFaces来训练一个人脸识别模型。UMDFaces由367,888张图片组成,收集了8277名被摄者的图片,包括带眼镜和不带眼镜的脸部图片。人脸识别模型是基于MobileFaceNets(PyTorch)。
我们使用MegaFace的子集MeGlass作为测试数据。MeGlass测试集包含1710个被试者的图像,每个被试者有两张带眼镜的图像(图库和探针)和它还包括两个不戴眼镜的图像(画廊和探针)。
本实验的七种实验方案如下。无论协议如何,图库中的所有图像都是不戴眼镜的脸部图像。
- (协议1)探针中的所有图像都是不戴眼镜的图像。
- (协议2)探测器中的所有图像都是带眼镜的图像。
- (协议3~7)探针中的所有图像都是有眼镜的图像,但。应用CycleGAN、SaGAN、ELEGANT、pix2pix和EyeGlassesGAN在人脸识别前摘掉眼镜。
如下表所示。议定书1:探头和画廊都是不戴眼镜的,以上训练的人脸识别模型(实验M)将用于识别(1:N)和验证。(1:1)在这两个任务中都能实现高精度它是还有...作为第2号议定书,当探头换成带眼镜的图像时,精度自然大打折扣。

由于当Probe是带眼镜的人脸图像时,识别精度会降低,所以我们在人脸识别前将Probe中的眼镜去掉,以防止这种情况发生(见议定书3~7).结果如下表所示。
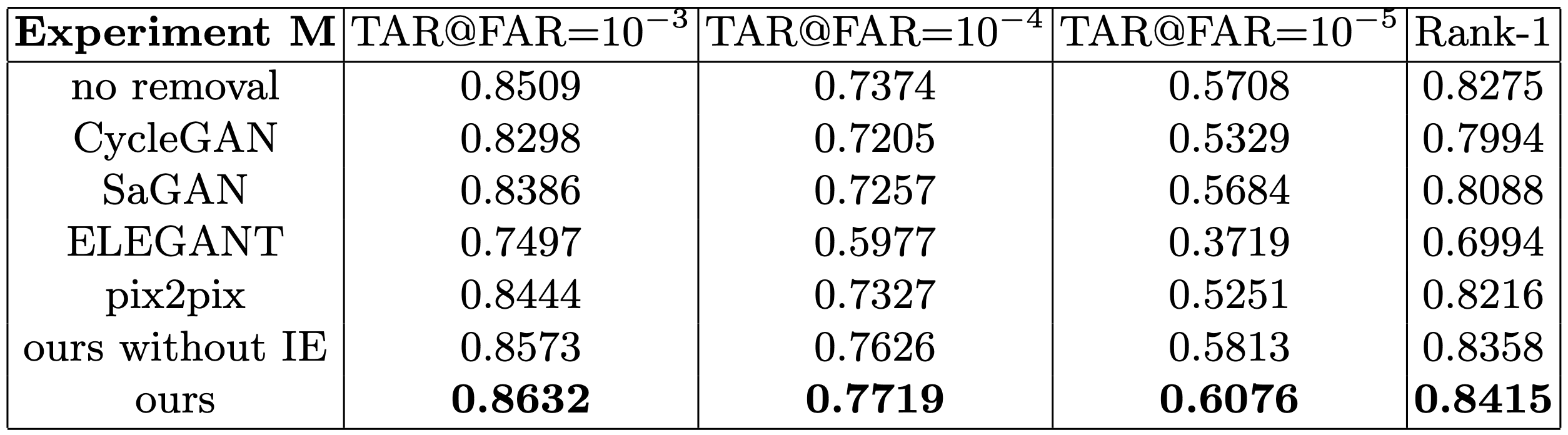
如表中第2~5行所示,使用CycleGAN、SaGAN、ELEGANT和pix2pix去除眼镜,降低了人脸识别的准确率。不过,使用EyeGlassesGAN摘下眼镜可以提高准确率。真接受率(TAR)的提高幅度较大,特别是当假接受率(FAR)较小时。
此外,在第7行,我们的没有IE的情况下。身份提取器我们在没有考虑到EyeGlassesGAN的情况下,对其进行了验证。结果是:人脸识别的改进比较有限,因为Generator不再有机制来限制人脸识别中可能被认为是噪声的痕迹的产生。
不过,为了实用,Probe未必只有带眼镜的图片,Gallery也未必只有不带眼镜的图片。所以,在此,我们验证了以下条件下的人脸识别效果。
- 图库:每个主题有1张不戴眼镜的图片和1张戴眼镜的图片。
- 探针:每个被试有1张不戴眼镜的图像和1张戴眼镜的图像。
- 不去除实验(no removal)使用原始图像,不管图像是否有眼镜。
- 在人脸识别前,使用EyeGlassesGAN对所有探头和图库图像进行去除眼镜的实验(有去除),无论图像是否有眼镜。
结果如下表所示。即使Probe的图像没有眼镜,我们也发现应用去除眼镜作为预处理步骤有助于人脸识别:在FAR为10-5的情况下,TAR高出约7%。

这一实验的结果是再见眼镜GAN到不戴眼镜的图像,图像基本没有变化,说明预处理后的人脸图像特征的身份嵌入保存良好。为了证实预识别图像合成不会损害人脸特征,我们还进行了实验,计算识别模型特征空间中带眼镜和不带眼镜的人脸图像特征之间的余弦距离,以及去掉眼镜的图像特征和不带眼镜的图像特征之间的余弦距离。我们正在进行
结果显示,应用EyeGlassesGAN后,我们能够减少MeGlass数据集中1710个图像对中的1335个余弦距离。
凭借改进的人脸识别和减少近80%图像对的余弦距离,EyeGlassesGAN不仅可以去除具有视觉清晰度的眼镜,还被证明是人脸识别中有用的预处理步骤。
4.总结
基于GAN的系统在不戴眼镜的情况下生成逼真的人脸图像,同时引入身份提取器的机制,使输入和输出的图像保持相同的ID。这种方法还可以预测人脸形状的二元掩模,使我们可以利用空间信息有效地去除人脸图像中的眼镜。
人脸识别的实验表明,在TAR@FAR=10-5时,应用EyeGlassesGAN可以提高人脸识别的准确率约7%。
在未来。可能需要提高鲁棒性,以确保在去除特殊眼镜和极端光照条件下的高精度。还可以将这种技术与人脸分析技术结合起来,可以扩展到去除其他属性,如胡须和帽子。此外:由于该系统可以在不戴眼镜的情况下生成人脸图像,因此可用于虚拟化妆等各种应用。