诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Universal Language Model Fine-tuning for Text Classification
模型简称:ULMFiT
模型全名:Universal Language Model Fine-tuning
ArXiv网址:https://arxiv.org/abs/1801.06146
(论文中提供的代码已经过时了)
本文是2018年ACL论文,反正整体思路也是预训练-微调,先预训练,然后在目标数据集上微调语言模型,然后接分类头微调下游任务。模型基底是AWD-LSTM模型(3层LSTM)。
(当年语言模型还是纯纯的语言模型,不是Transformers)
论文整体思路已经讲烂了。主要比较值得在意的内容是微调阶段的几个trick:discriminative fine-tuning (Discr), slanted triangular learning rates (STLR)("1cycle" Policy), and gradual unfreezing
文章目录
- [1. 背景](#1. 背景)
- [2. ULMFiT](#2. ULMFiT)
-
- [2.1 AWD-LSTM](#2.1 AWD-LSTM)
- [2.2 Discr](#2.2 Discr)
- [2.3 STLR](#2.3 STLR)
- [2.4 下游任务微调](#2.4 下游任务微调)
- [3. 实验](#3. 实验)
-
- [3.1 数据集](#3.1 数据集)
- [3.2 对比实验](#3.2 对比实验)
- [3.3 模型分析](#3.3 模型分析)
- [4. 复现代码](#4. 复现代码)
-
- [4.1 fastai包](#4.1 fastai包)
- 参考资料
1. 背景
预训练-微调模式常用于CV领域,本文将其应用于NLP中的文本分类任务。
本文研究的是inductive迁移学习。
transductive和inductive的区别我主要在GNN那几篇博文里写了,在此不再赘述。
NLP transductive迁移学习((2007 ACL) Biographies, Bollywood, Boom-boxes and Blenders: Domain Adaptation for Sentiment Classification)似乎指的是那种传统的迁移学习方法 SCL (Structural Correspondence Learning),找两个领域的公共特征(Pivot feature)。
inductive迁移学习的前作是word2vec和合并其他任务输出的embeddings到当前模型中([1](#1)和ELMo),但是主模型还是需要从0开始训练,只固定预训练embeddings。
(2015) Semi-supervised Sequence Learning:微调,但需要大量数据
微调:
(2015 SemEval) UNITN: Training Deep Convolutional Neural Network for Twitter Sentiment Classification
(2015) Improving neural machine translation models with monolingual data
(2017 ACL) Question Answering through Transfer Learning from Large Fine-grained Supervision Data
LM直接加分类头在小数据集上微调会导致灾难性遗忘。
2. ULMFiT
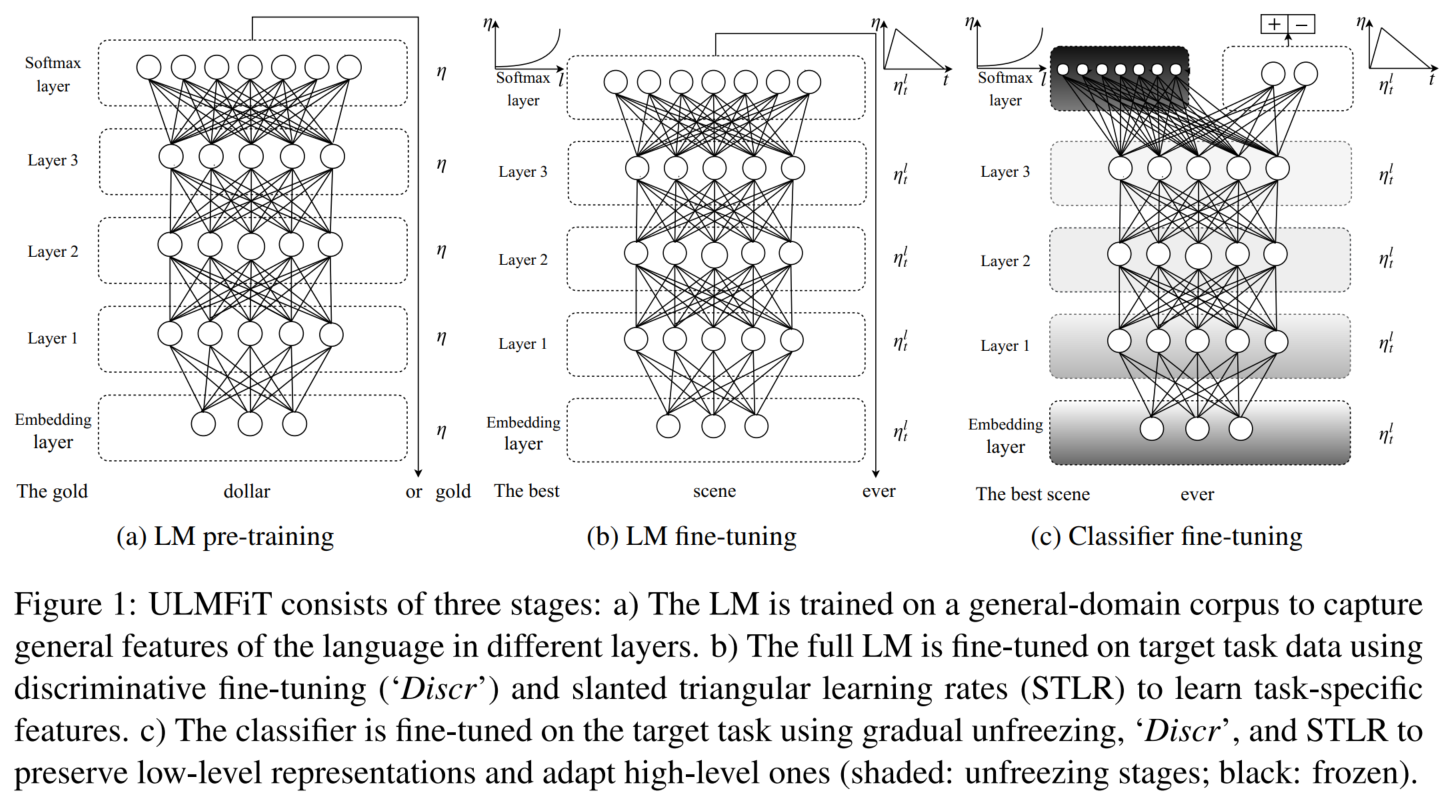
(不知道为什么看这个图我给联想到了verifier......但是性质不一样,我就不延伸了)
原任务:语言模型
优势:能捕捉多样知识,数据充分
微调:
语言模型(discriminative fine-tuning ('Discr') and slanted triangular learning rates (STLR))→ 分类器(gradual unfreezing, 'Discr', and STLR)
2.1 AWD-LSTM
原论文:(2017) Regularizing and Optimizing LSTM Language Models
LSTM + 多样化微调的dropout
2.2 Discr
Discriminative fine-tuning
主旨:不同层用不同的学习率
SGD更新参数:

Discr更新参数:
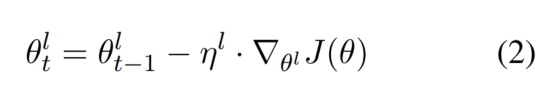
经验之选: η l − 1 = η l / 2.6 \eta^{l-1}=\eta^l/2.6 ηl−1=ηl/2.6
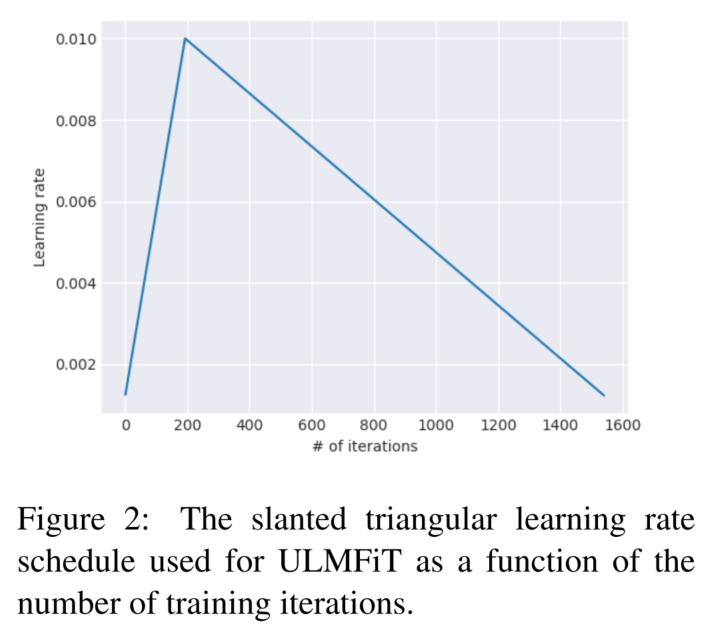
2.3 STLR
slanted triangular learning rates
从低学习率开始线性增长,最后下降回初值。这种方法使模型能够探索更广泛的学习率范围,从而摆脱次优局部极小值,最终获得更好的解决方案。

2.4 下游任务微调
2个线性模块:batch normalization,dropout,ReLU
Concat pooling :
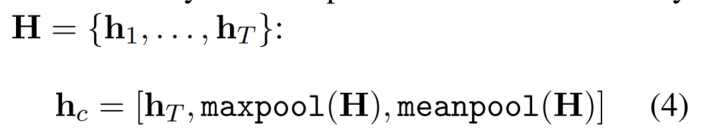
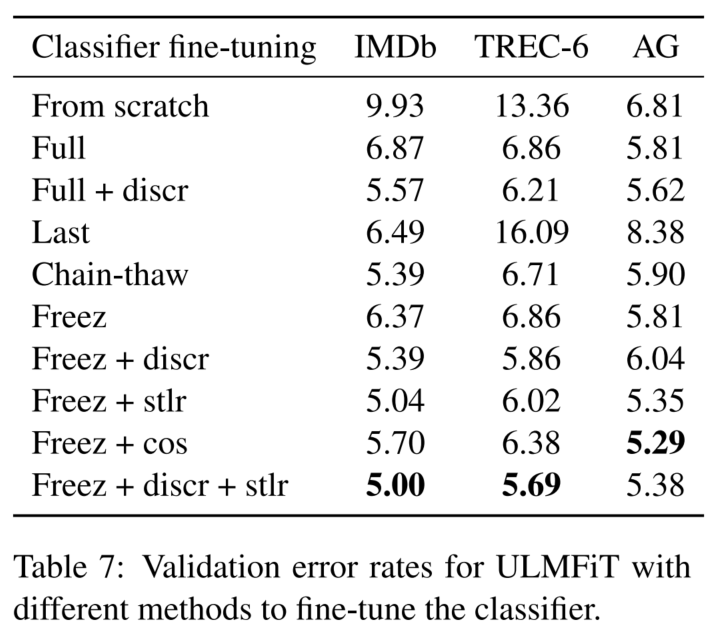
Gradual unfreezing:从最后一层开始解冻,一个epoch解冻一层
BPTT for Text Classification (BPT3C) :
backpropagation through time (BPTT)
Bidirectional language model
3. 实验
详细实验设置略。
3.1 数据集
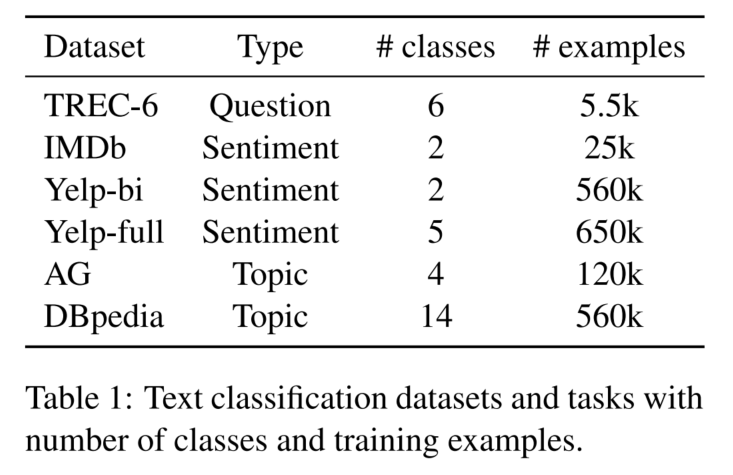
3.2 对比实验
评估指标:error rates
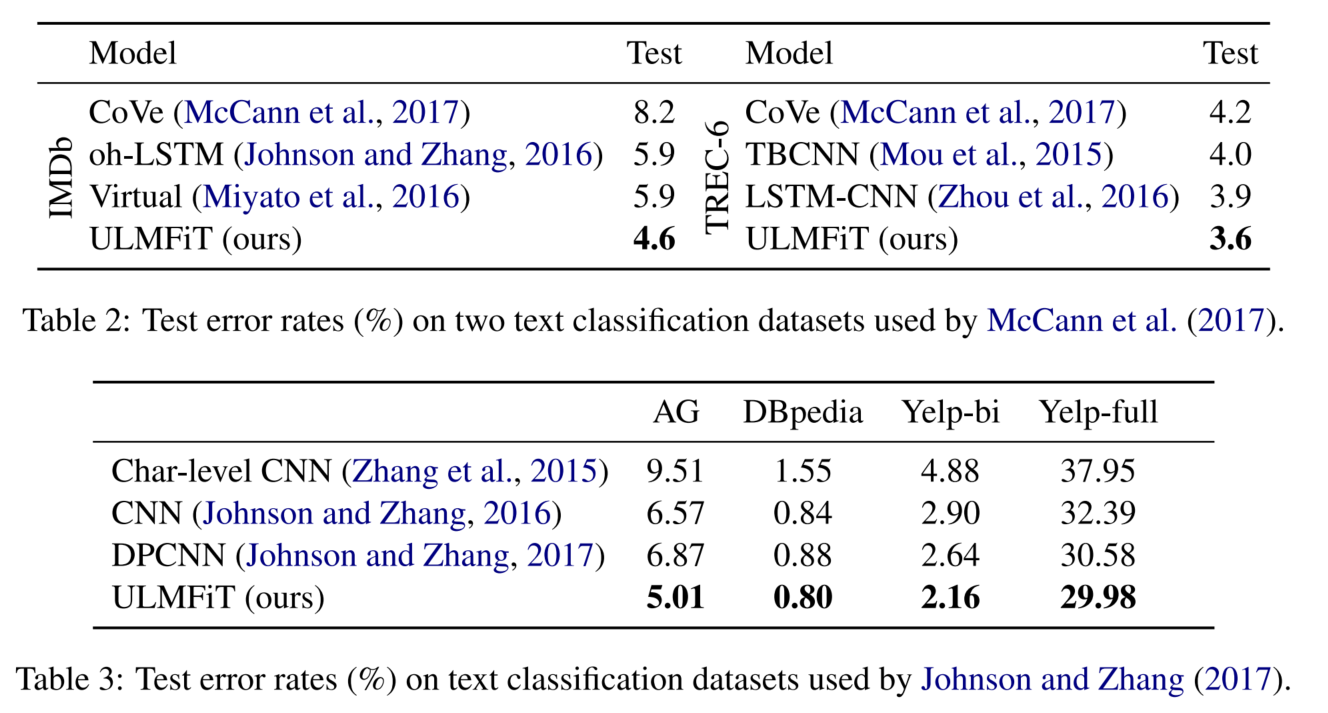
3.3 模型分析
在不同训练集规模下,是否使用预训练-微调范式产生的模型效果差异,以及是否利用无标签数据做语言模型训练(半监督学习)的效果差异:
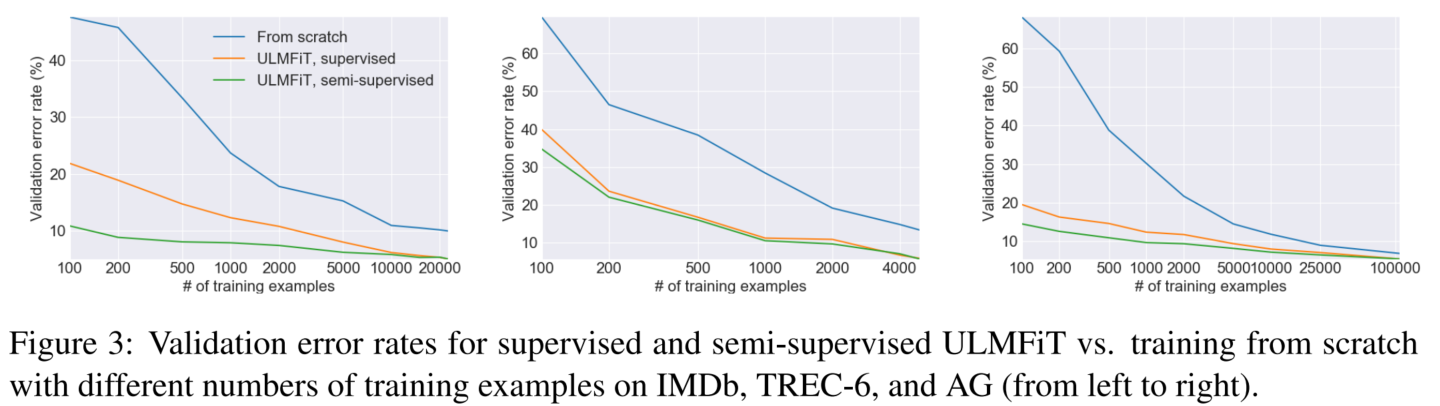
预训练的效果:
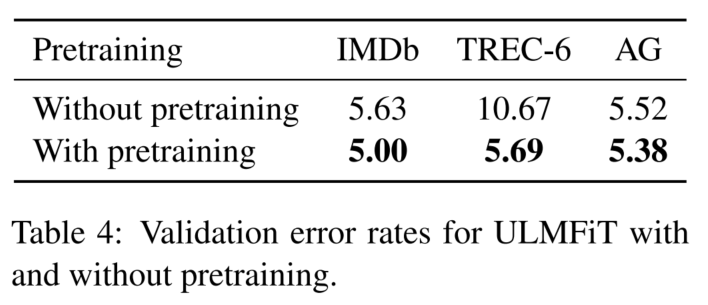
基语言模型的效果:
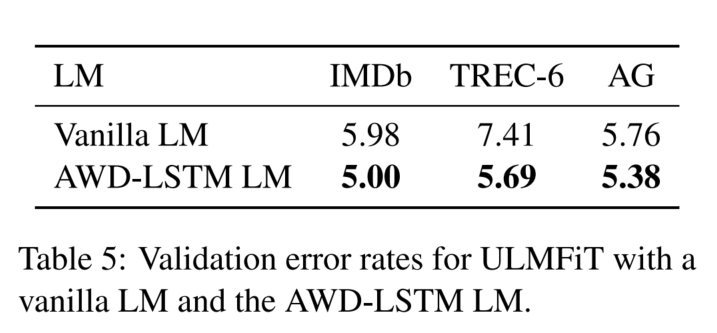
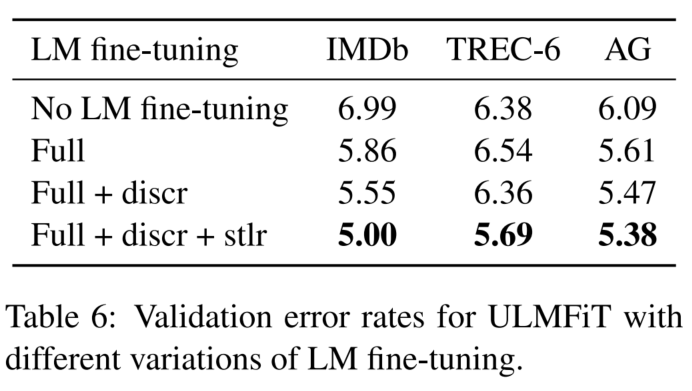
预训练阶段的trick:
(full是直接全量微调)
(freez是gradual unfreezing,cos是aggressive cosine annealing schedule,last常用于CV[2](#2))
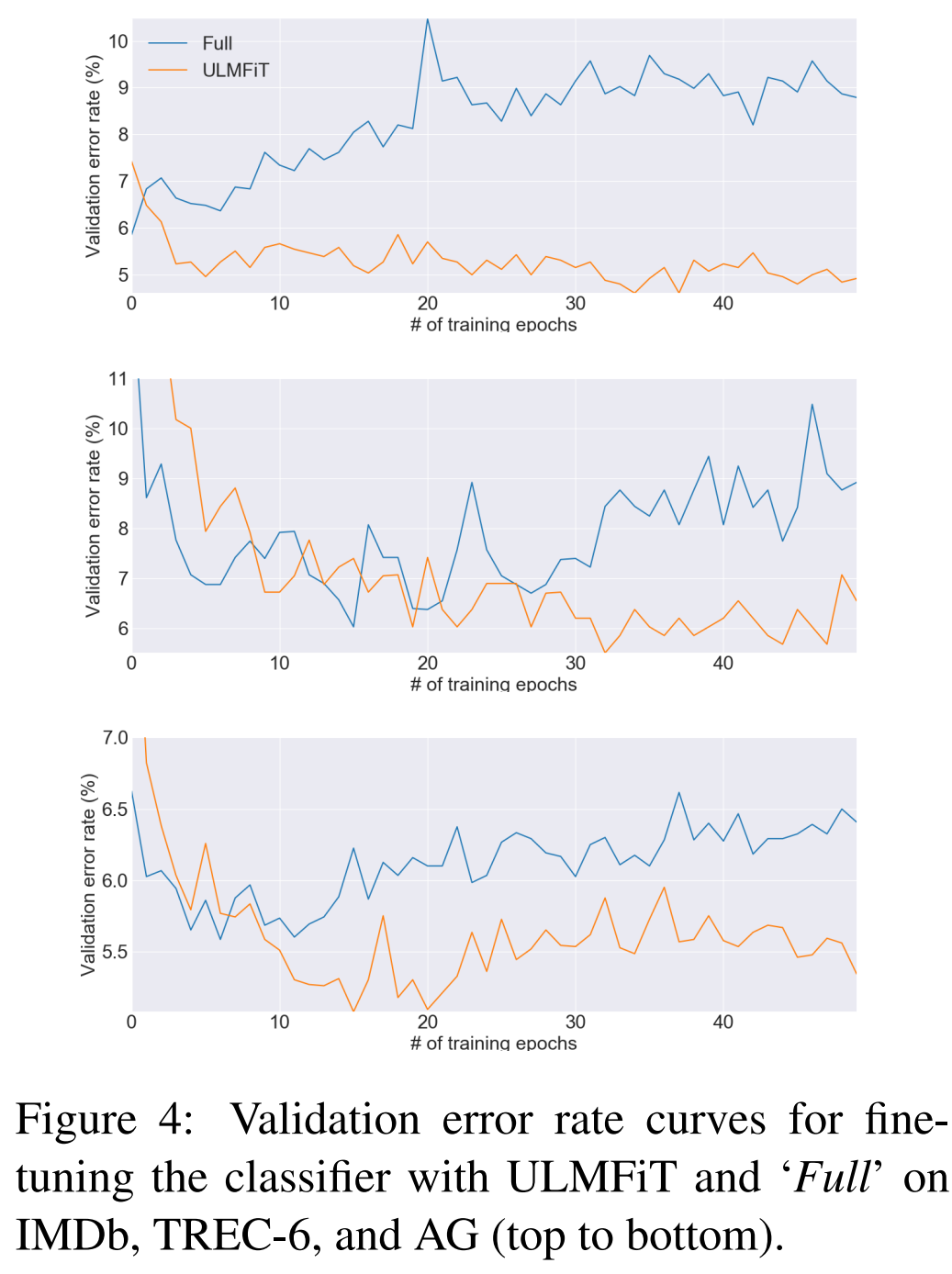
LM的双向性也带来了效果提升
4. 复现代码
4.1 fastai包
参考官方教程:https://docs.fast.ai/tutorial.text.html
我写了个colab文件,可以直接运行(第2个一级标题那里开始是ULMFiT的代码,先在IMDB数据集上预训练语言模型,然后在IMDB数据集上微调分类器):https://colab.research.google.com/drive/1hXYiutt_tTKIB-rP_MvdOjVSa2tk2h6y?usp=sharing
参考资料
- Let's learn about Universal Language Model Fine-tuning, ULMFiT | by Ashley Ha | Medium:这篇文章里面的代码已经老到和最新版的fastai包不兼容了,但是理论还是可供参考的,简单介绍了一下预训练-微调范式是怎么一回事
- 迁移学习_迁移学习简明手册(王晋东)_阅读笔记7-8_structural corresponding learning-CSDN博客
-
(2016 EMNLP) How Transferable are Neural Networks in NLP Applications?
(2017 ACL) Semi-supervised sequence tagging with bidirectional language models
(2017 ACL) Revisiting Recurrent Networks for Paraphrastic Sentence Embeddings
(2017 EMNLP) Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
(2017 Advances in Neural Information Processing Systems) Learned in Translation: Contextualized Word Vectors ↩︎
-
在早期的计算机视觉迁移学习工作中,微调的方法通常分为两种主要模式:固定特征提取和完全微调。
① 固定特征提取 :这一方法通常会冻结预训练网络的大部分层,只对最后一层进行重新训练。例如,在使用预训练的VGG16模型时,常常会冻结所有卷积层,只训练新的全连接层。这种方式利用了预训练模型的已有特征提取能力,仅通过调整最后的分类层来适应新任务。
参考资料:(1) Transfer Learning for Computer Vision Tutorial --- PyTorch Tutorials 2.3.0+cu121 documentation (2) Hands-on Transfer Learning with Keras and the VGG16 Model -- LearnDataSci
② 完全微调 :这一方法会在整个网络上进行训练,但前几层的权重变化通常很小,只在后几层进行较大的调整。一般来说,早期层学到的是通用特征(如边缘、纹理等),这些特征对于大多数视觉任务都是有用的,而后期层则学到的是特定任务的特征
参考资料:迁移学习和微调 | TensorFlow Core
具体来说,微调时常见的操作包括:
① 冻结前几层,只训练最后几层以适应新任务。
② 逐层解冻:首先冻结所有层,然后逐渐解冻靠近输出层的几层,最后解冻更多层,直至整个网络。
③ 部分冻结:有时会只解冻中间几层,保持前几层和后几层的冻结状态,以利用中间层的特征表达。(参考资料:What Is Transfer Learning? A Guide for Deep Learning | Built In)
在不同的任务和数据集上,哪种方法效果最好可能会有所不同,因此实际应用中需要根据具体情况进行实验和调整。 ↩︎