M ETA GPT: M ETA P ROGRAMMING FOR M ULTI -A GENT COLLABORATIVE F RAMEWORK
1.概述
现有的多智能体系统主要面临以下问题:
- 复杂性处理不足:传统的多智能体系统主要关注简单任务,对于复杂任务的处理能力有限,缺乏深入探索和研究。
- 幻觉问题:在多个智能体相互作用时,信息的错误可能会被放大,导致输出质量不稳定,尤其是在复杂问题解决过程中。
- 协作效率低下:现有系统往往难以通过对话和工具基础的互动实现有效协作,这导致协作过程中出现连贯性不足和反馈循环低效等问题。
为了解决上述问题,论文提出了MetaGPT框架,该框架具有以下特点和解决策略:
- 标准操作程序的编码:MetaGPT通过将标准操作程序(SOPs)编码为智能体可以理解和执行的指令,增加了任务处理的结构化和规范化。这有助于智能体更系统、更准确地处理复杂任务。
- 角色和任务分解:每个智能体都有明确的角色和职责,这些角色基于实际工作中的专业知识定义。这种角色定义帮助系统根据各自的专业知识和职责有效分工。
- 模块化输出:智能体生成的输出是模块化的,易于验证和复用。这样的设计减少了错误的累积和传播,提高了最终输出的准确性和可靠性。
- 共享环境和全局内存池:MetaGPT建立了一个共享环境,其中包括一个全局内存池,用于存储和检索智能体间的交互信息。这使得智能体能够基于先前的交互动态调整其行为,提高了信息的利用效率和协作的灵活性。
通过这些策略,MetaGPT能够提高多智能体系统处理复杂任务的能力和效率,使系统在实际应用中更加健壮和有效。这些解决方案为多智能体系统的发展提供了新的方向,尤其是在需要高度协作和信息共享的复杂任务处理场景中。
2.整体架构
下图展示了MetaGPT框架下的软件开发标准化流程,从人类提出需求到最终的产品测试。流程开始于产品经理撰写需求文档,包括市场分析和用户需求。随后,架构师基于需求文档设计软件架构,包括技术选型和接口定义。工程师根据架构设计进行代码实现和测试,最终由质量保证工程师完成系统测试和验证。整个过程中,各角色通过共享的环境和内存池高效交换信息,确保了开发过程的连贯性和产品的高质量。这一流程不仅提高了开发效率,还通过明确的角色分工和协作机制,优化了多智能体系统处理复杂任务的能力。

2.1 整体框架
整个框架被划分为两个层次:基础组件层和协作层,这两者共同工作以支持系统的功能性和模块性。
(1)基础组件层
这一层包含了支持单个智能体操作和系统范围信息交换的核心构建块,如环境(Environment)、内存(Memory)、角色(Role)、行动(Action)和工具(Tools)。其中:
- 环境(Environment):为智能体提供协作空间和通信平台,使它们能够共享信息并进行交互。
- 内存(Memory):使智能体能够存储和检索历史消息和上下文信息,从而支持更加智能的决策过程。
- 角色(Roles):封装基于领域专业知识的特定技能、行为和工作流程。每个角色都有明确的定义,包括职责、目标和限制。
- 行动(Actions):智能体执行的具体任务,用以完成子任务并生成输出。
- 工具(Tools):为智能体提供可用于增强其能力的通用服务和工具。
(2)协作层
建立在基础组件之上,协作层调动个体智能体共同解决复杂问题。这一层包括两个主要机制:知识共享和封装工作流。
- 知识共享:该机制允许智能体有效地交换信息,促进了共享知识库的构建。智能体可以在不同粒度级别存储、检索和共享数据,这不仅增强了协调性,还减少了冗余通信,提高了整体运营效率。
- 封装工作流:利用SOP将复杂任务分解为更小、更可管理的组件,然后将这些子任务分配给适合的智能体,并监督它们的表现以确保行动与总体目标一致。
通过这种设计,MetaGPT不仅提高了模块性,还确保了个体和集体智能体能力的整合,同时促进了目的性的协调。这种结构化和层次化的框架设计使MetaGPT能够有效地处理并协调复杂的多智能体协作任务,如软件开发中从需求分析到最终交付的完整流程。
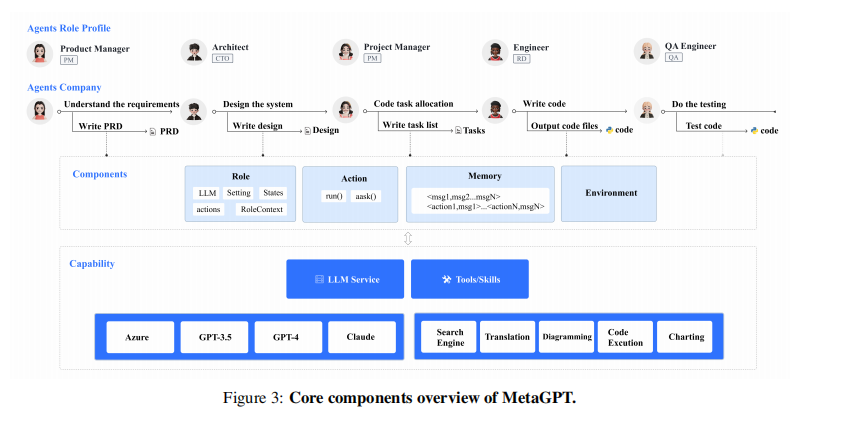
2.2 核心组件设计
(1)角色定义
每个角色根据其特定领域的专业知识被赋予一定的属性,包括名字、目标、限制和描述。这些定义帮助确保每个智能体在其角色范围内能有效执行任务,同时也使得智能体生成的行为与期望功能相匹配。
(2)知识共享机制和定制化知识管理
- 智能体通过检索环境中的信息并根据其角色和任务需要定制知识,提高决策的相关性和效率。
- 环境中的信息被复制并同步更新,确保所有智能体都能访问到一致的最新信息。
- 智能体可以注册并接收对它们有意义的消息类型的更新,从而保持对新信息的敏感性和响应性。
(3)提高决策效率和执行力
MetaGPT通过将这些组件整合到一个统一的框架中,实现了智能体在执行复杂任务时的高效协作和信息共享。通过角色明确的定义和智能体间的有效沟通,每个智能体都能在其专业领域内提供精准的输入,共同推动任务向预定目标前进。这种设计不仅提高了任务执行的效率,还增强了系统的灵活性和智能性。
2.3 实例
多智能体协作环境中如何实现从项目需求到最终执行的整个软件开发流程实例如下:
-
需求与计划阶段:
- Alice (产品经理): 根据给定的项目需求,准备写产品需求文档(Product Requirement Document, PRD),涵盖产品目标、用户故事、竞争分析等内容。
- 文档完成后,Alice 将其工作成果发布到消息队列的"WritePRD"类别中,并由系统通知其他相关智能体及用户当前的API使用情况。

-
设计阶段:
- Bob (架构师): 接收到Alice的需求和可行性分析后,负责撰写系统设计计划,选择技术栈并定义系统架构。
- Bob 生成系统设计相关的文件和目录,包括程序的流程图和数据结构图,并将这些文件上传到"WriteDesign"类别的消息队列中。

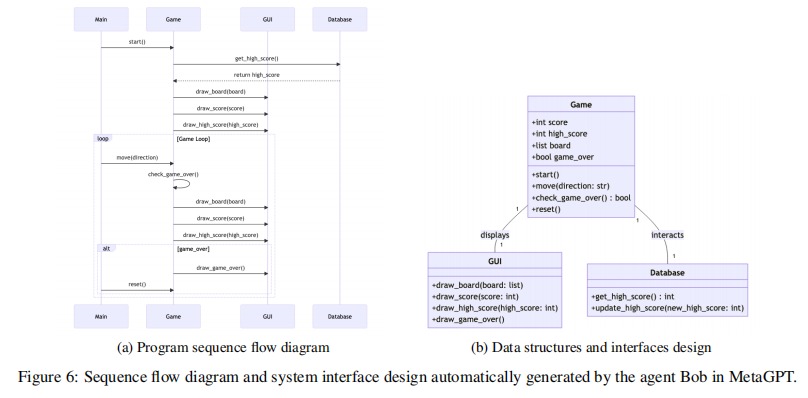
-
任务分解与执行:
- Eve (项目经理): 阅读了"WriteDesign"类别,使用Bob提供的UI设计、系统设计和API设计文档,将项目分解成更简单和具体的任务,通常针对单个代码文件。
- 分解后的任务包括各种代码文件的实现,如主程序、游戏逻辑、GUI处理、数据库管理及其测试。



-
编码与代码审查:
- Alex (工程师): 负责编写和审查代码。Alex根据Eve提供的任务列表编写相应的代码文件,并进行单元测试,确保代码质量。

-
知识共享与项目监控:
- 系统通过共享知识和更新状态来协助项目成员保持同步,确保所有智能体可以访问最新的项目信息,并根据项目进展进行相应的调整。
3.实验
3.1评估指标和方法
-
代码和文档统计:
- 评估基于代码文件的数量、代码行数、文档文件数量和文档行数,以量化编码和文档工作的规模和深度。
- 文档类型总数反映了任务执行中生成的文档多样性。
-
成本统计:
- 通过总提示符和完成令牌的使用量来评估系统交互的级别和输出规模。
- 总成本、任务执行时间和成本修正捕捉了代码的维护努力和成本效率。
-
代码执行质量:
- 代码质量分为F到P的等级,从完全失败到完美匹配规范。
3.2 实验设置
(1)实验环境和配置
- 实验平台:实验在Python环境(版本3.9.6)中进行,确保了编程语言的现代性和适用性。
- 实验限制:为了模拟真实的开发限制,设定了最大token消耗限制为1500,允许充分测试MetaGPT在不同复杂度的任务下的表现。
(2)实验任务和范围
- 任务多样性:实验涵盖了从Python游戏生成到CRUD管理系统的多种任务,包括但不限于像Flappy Bird和2048这样的游戏,这些任务要求框架展现出从逻辑处理到用户界面设计的全方位能力。
- 项目规模:每个项目的具体配置详细记录在实验记录表Appendix B中,提供了完整的透明度和可追溯性。
(3)性能评估
- 定量评估:通过比较MetaGPT与其他框架如AutoGPT和AgentVerse的性能,使用定量指标如代码行数、生成的文档数量和类型、以及任务完成的质量评分。
- 功能执行:每个任务的执行不仅评估基础的运行能力,还评估了代码和工作流是否满足预期规范,这是通过为每个任务设定从0到3的评分标准来实现的,其中3表示完美符合期望。
(4)实验成本和资源使用
- token使用:记录了每个项目中用于提示和完成任务的令牌数,这些数据反映了任务的复杂性和系统交互的深度。
- 时间和成本效率:评估了完成任务所需的总时间和金钱成本,这些指标关键地体现了MetaGPT在实际软件开发过程中的经济效益。
3.3 实验结果
-
功能比较:
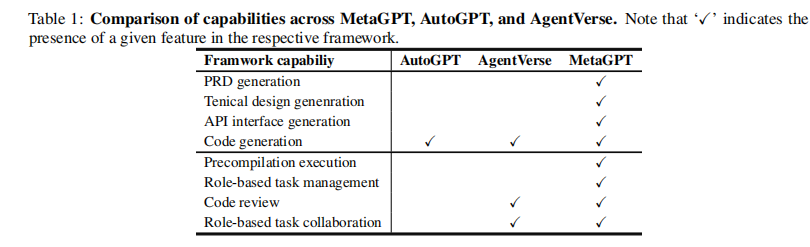
- MetaGPT在生成PRD、技术设计和API接口方面表现突出,显示出比AutoGPT和AgentVerse更全面的项目执行能力。
- 独有的角色基础任务管理和代码审查功能使MetaGPT在多智能体合作和代码质量提升方面具有优势。
-
定量实验比较:
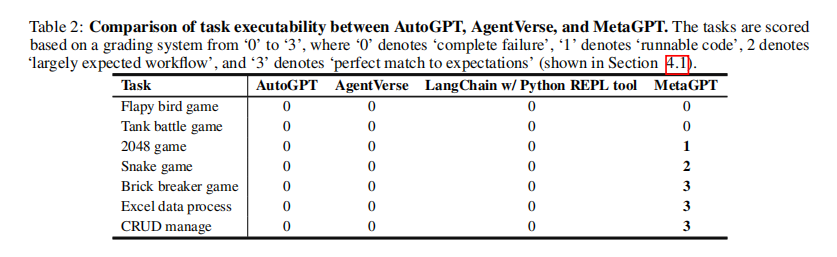
- 实验显示MetaGPT在多种任务(如Python游戏生成和CRUD管理)上展示了强大的性能,能在许多测试中达到完美匹配期望的3分满分。
- 相比之下,AutoGPT和AgentVerse在所有任务中的表现均未达到预期,常因资源限制和任务复杂性问题而失败。
-
运行统计分析:
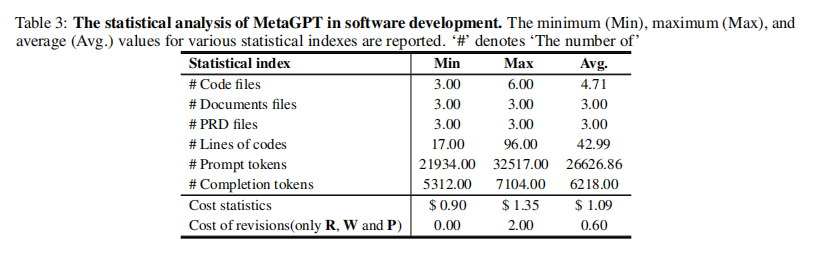
- MetaGPT的项目平均生成了约470行代码,每个项目成本大约为$1.09,整个构建过程平均耗时约518秒。
- 成本分析显示,每个项目平均消耗约26266.86个提示符token和6218.00个完成token。
3.4 角色减少对性能的影响
- 完整团队:初始实验配置包括工程师、产品经理、架构师和项目经理。在这种配置下,项目不仅能够成功完成,而且代码质量和任务执行的成本效率最高。
- 逐步减少角色:实验中逐渐减少团队成员,结果显示,当减少到只有产品经理和工程师时,代码行数有所减少,修订成本也有所增加,但总体任务可执行性得以保持。完全由单一智能体执行时,任务失败,显示出多角色协作对成功执行复杂任务的重要性。
(1)实验结果
-
Brick Breaker游戏开发:
- 从一个角色到四个角色,代码的可执行性从完全失败(F)到完美(P)不等。随着角色的增加,代码行数和修订成本增加,但整体代码质量提高。
- 实验显示,有四个角色参与时,代码不仅能成功执行,而且修订次数减少,代码质量最高。
-
Gomoku游戏开发:
- 与Brick Breaker类似,角色数的减少对项目成本和代码质量有直接影响。虽然代码的可执行性在三个角色时仍然保持在运行状态(R),但到了四个角色时,代码执行性提高到几乎完美(W)。