项目地址:https://github.com/levihsu/OOTDiffusion
试用地址:https://ootd.ibot.cn/
其它项目
本地部署
下载模型
- git lfs安装, 然后国内源下载 git clone https://www.modelscope.cn/AI-ModelScope/clip-vit-large-patch14.git
- 然后国内镜像手动下载 https://hf-mirror.com/levihsu/OOTDiffusion/tree/main 相应模型文件(git 好像访问不到)
- 将模型文件放到项目checkpints下
代码修改
由于只有一个GPU,文件run\gradio_ootd.py中#24~#26原来为:
openpose_model_dc = OpenPose(1)
parsing_model_dc = Parsing(1)
ootd_model_dc = OOTDiffusionDC(1)
把它们改成:
openpose_model_dc = openpose_model_hd
parsing_model_dc = parsing_model_hd
ootd_model_dc = ootd_model_hd
代码运行
- 指定图片运行 python3 run_ootd.py --model_path ren.png --cloth_path clothes2.jpg --scale 2.0 --sample 4
- 网页demo运行 python3 gradio_ootd.py
原理解析
简介
基于图片虚拟试穿(image-based virtual try-on ,VTON)
基于扩散模型全套试穿:Outfitting over Try-on Diffusion (OOTDiffusion)
利用预训练的潜在扩散模型的力量(pretrained latent diffusion models),用于现实和可控的(realistic and controllable)虚拟试穿。在没有明确的衣物形变适应过程(warping process)的情况下,
提出了一个outfitting UNet来学习服装细节特征,在扩散模型去噪过程中,通过我们提出的服装融合outfitting fusion将其与目标人体融合。
前置内容
- clip-vit-large-patch14
- Stable Diffusion v1.5
- VAE
原理
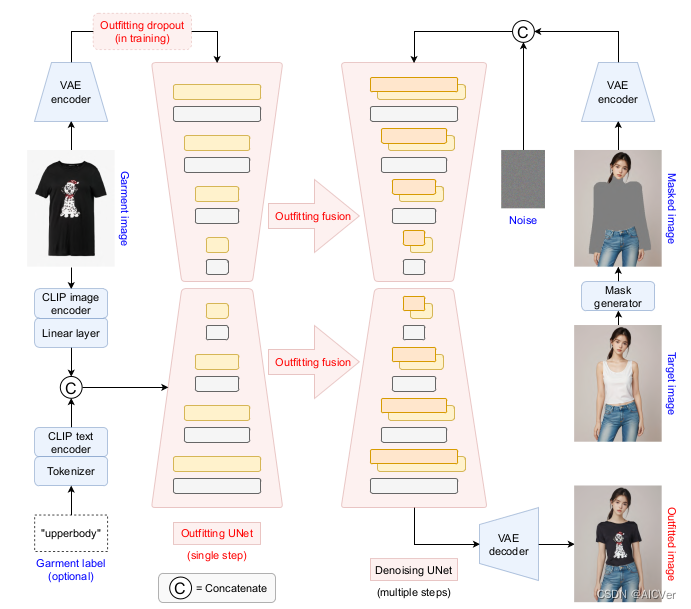
- 在左侧,服装图像被 clip-vit-large-patch14 编码到潜在空间中,并输入到服装UNet中进行单步处理。
- 与CLIP编码器生成的辅助调节输入一起,通过服装融合(outfitting fusion)将服装特征纳入去噪UNet。
- 在训练过程中,为了实现无分类器的指导(classifier-free guidance),对训练过程进行了 outfitting dropout。
- 在右侧,输入的人类图像通过掩码生成模块(mask generator, HumanParsing+OpenPose )将需要换衣以及相近的地方被遮盖为黑色(masked),并与高斯噪声连接在一起,作为多个采样步骤的去噪UNet的输入。
- 去噪后,特征映射被解码回图像空间作为我们的试戴结果。