该系列笔记主要参考了小土堆的视频教程,传送门:P1. PyTorch环境的配置及安装(Configuration and Installation of PyTorch)【PyTorch教程】_哔哩哔哩_bilibili
涉及到的文件/数据集网盘:
链接:https://pan.baidu.com/s/1aZmXokdpbA97qQ2kHvx_JQ?pwd=1023
提取码:1023
Dataset加载数据
加载数据最主要的就是获取数据及其label,但是在加载不同的数据集时,会面临相同的问题:
- 如何获取每一个数据及其label
- 需要知道有几个数据
Dataset是torch.utils.data下的一个工具,它可以帮助我们解决上述两个问题,学习一门新技术的时候,如果你有足够的英语基础或者熟练使用翻译软件,我会推荐你从看源码开始入手,这是一个非常好的习惯。
下面是Dataset的源码中的描述:
py
class Dataset(Generic[T_co]):
r"""An abstract class representing a :class:`Dataset`.
All datasets that represent a map from keys to data samples should subclass
it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
data sample for a given key. Subclasses could also optionally overwrite
:meth:`__len__`, which is expected to return the size of the dataset by many
:class:`~torch.utils.data.Sampler` implementations and the default options
of :class:`~torch.utils.data.DataLoader`. Subclasses could also
optionally implement :meth:`__getitems__`, for speedup batched samples
loading. This method accepts list of indices of samples of batch and returns
list of samples.大致翻译一下主要内容:所有的子类必须重写_getitem_方法,子类也可以选择重写_len_ 方法。这两个方法就可以解决上述提出的两个问题
【代码示例】将下载好的练手数据集(网盘中的dataset)放在项目目录下,首先观察数据集的目录结构,数据集首先分为train和val两部分,train部分用于训练集数据,val部分用于测试集数据。两者子目录下又分为ants和bees两类数据,每类数据下面即为图片数据,那么ants和bees就可以作为我们的label(标签)使用。此处我们创建自定义的Dataset读取具体的数据。
py
from torch.utils.data import Dataset
from PIL import Image # 用于读取图片信息
import os
# 自定义一个MyData继承自Dataset
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir) # 拼接两个地址
self.img_path = os.listdir(self.path) # os.listdir 将目录中的所有内容存入列表中
def __getitem__(self, index) :
img_name = self.img_path[index] # 根据索引去除列表中的所有名字
img_item_path = os.path.join(self.path, img_name) # 拼接当前的目录和具体的图片名字
# getitem的作用就是获取每一个对象和label并返回
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
img, label = train_dataset[0]
img.show()
print(label)
print(ants_dataset.__len__())
# 因为ants的长度为124,所以下表第124个数据应该为bee
img, label = train_dataset[124]
img.show()
print(label)运行结果:
ants
124
bees熟悉上述代码之后可以自己编写建立一个测试集
TensorBoard可视化
TensorBoard 是 TensorFlow 提供的一个强大的可视化工具,但它不仅仅局限于 TensorFlow,也可以用于其他深度学习框架,如 PyTorch。TensorBoard 的主要目的是帮助研究人员和开发人员更好地理解和调试机器学习模型,以及监控训练过程。
在PyTorch中使用torch.utils.tensorboard.SummaryWriter 类来图形数据写入到日志中,然后在命令行中启动TensorBoard服务并指定读取的日志文件
如果多次执行代码且没有修改不同的图片描述信息(tag),则会出现混乱的画面,这种情况可以把logs文件删除,然后重新运行代码即可。
在TensorBoard中展示函数图像
可以使用SummaryWriter类的add_scalar() 方法在TensorBoard中画函数图像,其函数语法如下:
py
writer.add_scalar(tag, scalar_value, global_step=None)
# tag (str): 这是一个字符串,用于标识记录的是什么数据。例如,你可以使用 "Loss" 或 "Accuracy" 作为标签来区分不同的数据序列。
# scalar_value (float): 要记录的标量值。这个值可以是你想跟踪的任何单个数值,比如训练损失或者验证精度。
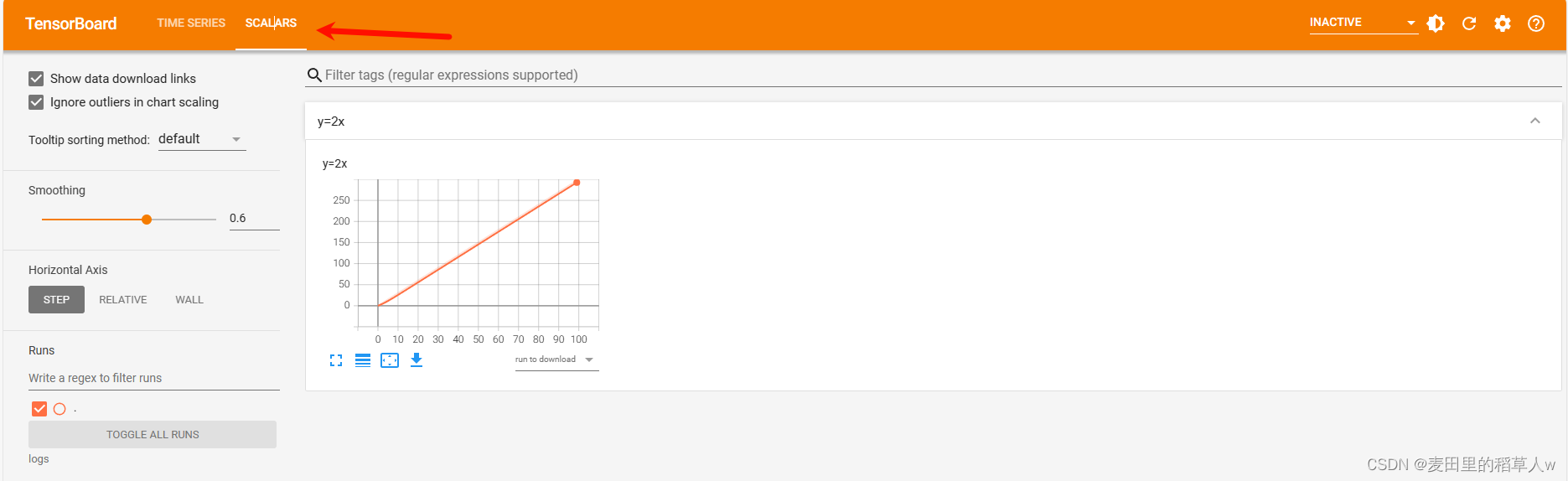
# global_step (int, optional): 这是一个可选参数,用来指定当前的全局步数。这对于按步骤跟踪进度非常有帮助,特别是在训练循环中。默认值是 None,此时会自动递增步数。【代码示例】使用SummaryWriter和TensorBoard可视化工具画出函数y=2x的图像并查看
py
writer = SummaryWriter("logs") #"logs"为指定的存放日志文件的目录路径
# 画出y=2x的图像
for i in range(100):
writer.add_scalar("y=2x", 2*i, i) # "y=2x"作为图片的描述信息
writer.close() # 关闭在终端命令行中启动TensorBoard服务:port指定端口
bash
tensorboard --logdir=path/to/log_directory [--port=6006]然后点击默认的端口链接,进入前端页面

在左上角选择SCALARS, 即可看到我们刚刚画的样例图
 origin_url=D%3A%2Fdocument%2FMachine%20Learning%2Fpytorch%2Fimgs%2F3.png&pos_id=img-DjwI6WjC-1717168151301)
origin_url=D%3A%2Fdocument%2FMachine%20Learning%2Fpytorch%2Fimgs%2F3.png&pos_id=img-DjwI6WjC-1717168151301)
在tensorboard中展示图片
上面的代码中,通过writer.add_scalar我们展示了自定义的标量(函数)图片,如果需要使用tensorboard展示自定义图片则需要使用writer.add_image方法,下面是其基本语法:
py
writer.add_image(tag, img_tensor, global_step=None, dataformats='CHW')
# tag (str): 图像的标签,用于在TensorBoard中区分不同的图像序列。
# img_tensor (Tensor or numpy.array): 要记录的图像数据。它应该是一个形状符合预期格式的张量或NumPy数组。格式可以是 (C, H, W) 或 (H, W, C),具体取决于 dataformats 参数。
# global_step (int, optional): 同样是一个可选参数,用于指定当前的全局步数,有助于按步骤查看图像变化。
# dataformats (str, optional): 指定图像数据的维度顺序,默认为 'CHW'(通道、高度、宽度)。如果你的数据格式是 (H, W, C),则应设置为 'HWC'。img_tensor为你需要展示的图片对象,必须为Tensor类型或者ndarray类型,Tensor类型会在后面详细讲解。
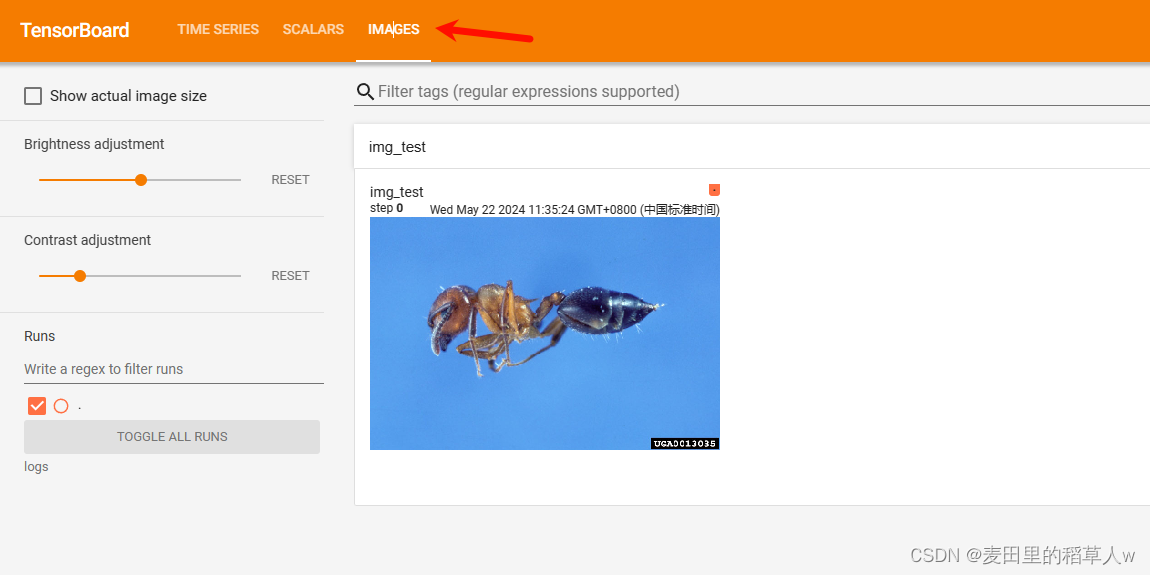
【代码示例】添加一张图片到SummaryWriter日志中,并使用tensorboard服务进行查看
py
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import torchvision
writer = SummaryWriter("logs")
# # y = 2x
# for i in range(100):
# writer.add_scalar("y=2x", 3*i, i)
# 展示图片
img_path="dataset/train/ants/0013035.jpg"
img = Image.open(img_path)
myTotensor = torchvision.transforms.PILToTensor()
img_tensor = myTotensor(img)
writer.add_image("img_test",img_tensor)
writer.close()在命令行中启动tensor服务后,在浏览器中点击左上角IMAGES进行查看
transform
transform是torchvision提供的工具包,主要用来对图像信息进行处理,包括归一化,裁剪等功能。
ToTensor
ToTensor用于将PIL类型图像或者ndarray类型图像转为tensor类型,注意ToTensor是一个类,只用将其实例化后才能进行调用,不能像普通方法直接进行传参调用。
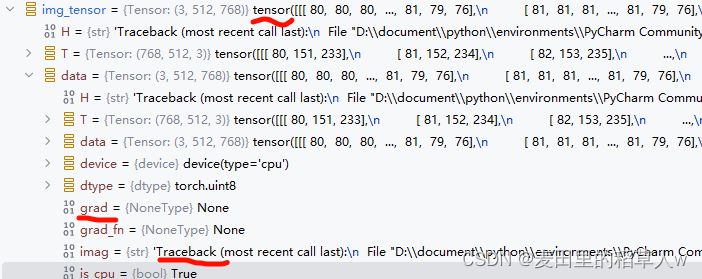
为什么需要使用tensor类型图像?
在python控制台中创建一个tensor类型对象并观察即可发现,tensor类型图像多出了一些属性,如trackback、grad等,这些属性主要用于神经网络的反向传播之中,帮助模型进行快速迭代。
使用opencv读取的图片类型为nparray,Image读取的为PIL,使用这两种常用方法读取的图片信息均可使用ToTensor方法将其转换为tensor类型后再进行后续的神经网络处理。
【代码示例】分别使用opencv和Image读取图片,并输出它们的类型
首先在虚拟环境中安装opencv,打开终端,先确保是否在正确的虚拟环境当中,然后使用
bash
pip install opencv-python安装完毕后,验证是否安装正确
pip list
py
from PIL import Image
import torchvision
import cv2
img_path="dataset/train/ants/0013035.jpg"
img_PIL = Image.open(img_path)
print("img_PIL`s type : " , type(img_PIL))
img_cv = cv2.imread(img_path)
print("img_cv`s type : " , type(img_cv))
myTotensor = torchvision.transforms.ToTensor()
img_tensor1 = myTotensor(img_PIL)
img_tensor2 = myTotensor(img_cv)
print("img_tensor1`s type : " , type(img_tensor1))
print("img_tensor2`s type : " , type(img_tensor2))输出结果:
img_PIL`s type : <class 'PIL.JpegImagePlugin.JpegImageFile'>
img_cv`s type : <class 'numpy.ndarray'>
img_tensor1`s type : <class 'torch.Tensor'>
img_tensor2`s type : <class 'torch.Tensor'>Normalize
Normalize用于将一个tensor类型的图像进行规范化处理,其主要参数为mean(均值)和std(方差),使用(inputchannel - meanchannel) / stdchannel 公式进行处理。
图片的Normalize处理主要应用于深度学习、机器学习和计算机视觉任务的预处理阶段,它的目的是为了使得数据具有更好的数值属性,从而提高模型训练的效率和效果。Normalize的具体作用和目的主要包括以下几点:
- 归一化:通过减去均值并除以标准差(或其它方式),将图片像素值调整到一个特定的范围内(通常是0-1之间,或者-1到1之间)。这样做的好处是可以统一输入数据的尺度,减少不同图片间因亮度、对比度差异带来的影响。
- 加速训练过程:归一化后的数据可以使梯度下降等优化算法更加稳定高效,因为特征值范围缩小后,学习率可以设置得更大而不至于导致权重更新过猛,跳出最优解区域。
- 提升模型性能:标准化数据可以减轻权重初始化对模型训练的影响,使得模型更容易收敛,并可能达到更高的准确率。
- 减少过拟合:某些归一化技术(如Batch Normalization)还能起到正则化的作用,有助于减少过拟合现象,使模型泛化能力更强。
- 简化参数学习:通过Normalization,可以让网络中的权重在训练初期有相近的尺度,这有助于优化算法更快地找到合适的权重值。
总之, Normalize处理是图像处理和深度学习领域中一个非常重要的预处理步骤,它能够显著影响模型的训练速度和最终性能。
【代码示例】对图像进行规范化处理,并使用tensorboard可视化进行展示
py
from PIL import Image
import torchvision
from torch.utils.tensorboard import SummaryWriter
img_path="dataset/train/ants/0013035.jpg"
# 使用Image读取PIL类型的图像
img_PIL = Image.open(img_path)
# 使用ToTensor将PIL转为tensor类型
myTotensor = torchvision.transforms.ToTensor()
img_tensor = myTotensor(img_PIL)
# 将tensor图片进行规范化处理
myNormalize = torchvision.transforms.Normalize([0.5,0.5,0.5], [1,1,1])
img_normalize = myNormalize(img_tensor)
# 可视化
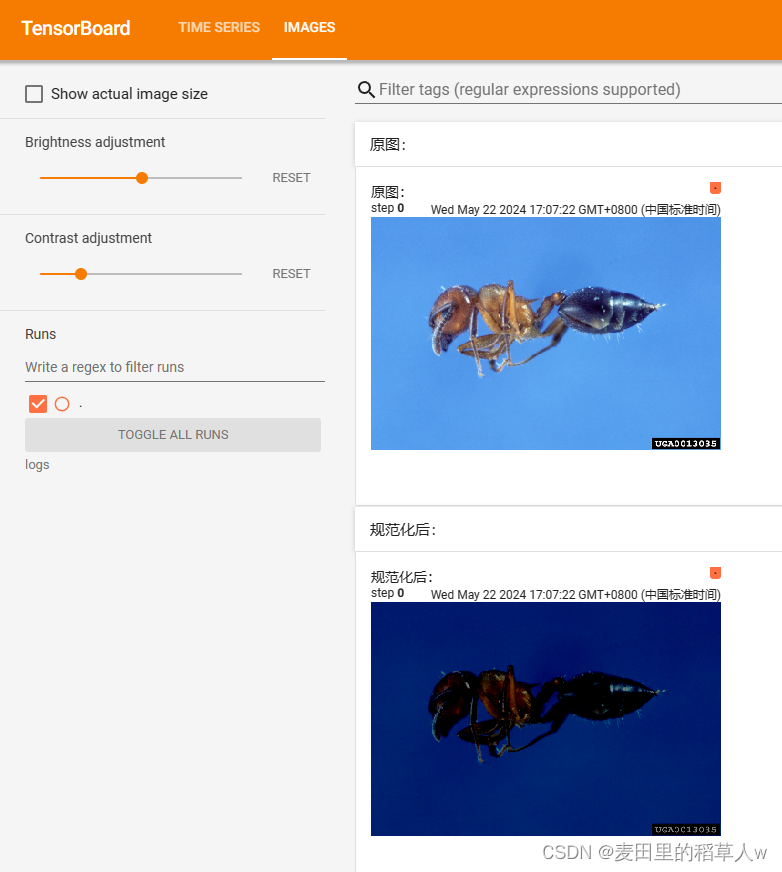
writter = SummaryWriter("logs")
writter.add_image('原图:', img_tensor)
writter.add_image('规范化后:', img_normalize)
writter.close()运行结果:
resize
对于图片尺寸的处理也是图像增强和图像预处理的一个重要步骤,在transform中,用resize进行实现
resize的参数可以有两种表示方法,如果传入了两个数字,则宽高分别变为指定的大小;如果只传入一个数字,则使用最小边匹配,另一条变进行等比缩放
【代码示例】对图片resize操作,并进行可视化展示
py
from PIL import Image
import torchvision
from torch.utils.tensorboard import SummaryWriter
img_path="dataset/train/ants/0013035.jpg"
# 使用Image读取PIL类型的图像
img_PIL = Image.open(img_path)
# 使用ToTensor将PIL转为tensor类型
myTotensor = torchvision.transforms.ToTensor()
img_tensor = myTotensor(img_PIL)
# 将tensor图片进行resize
myResize = torchvision.transforms.Resize((80, 100))
img_resize = myResize(img_tensor)
# 只传一个参数
myResize2 = torchvision.transforms.Resize((50))
img_resize2 = myResize2(img_tensor)
# 可视化
writter = SummaryWriter("logs")
writter.add_image('原图:', img_tensor)
writter.add_image('两个参数变形后:', img_resize)
writter.add_image('一个参数变形后:', img_resize2)
writter.close()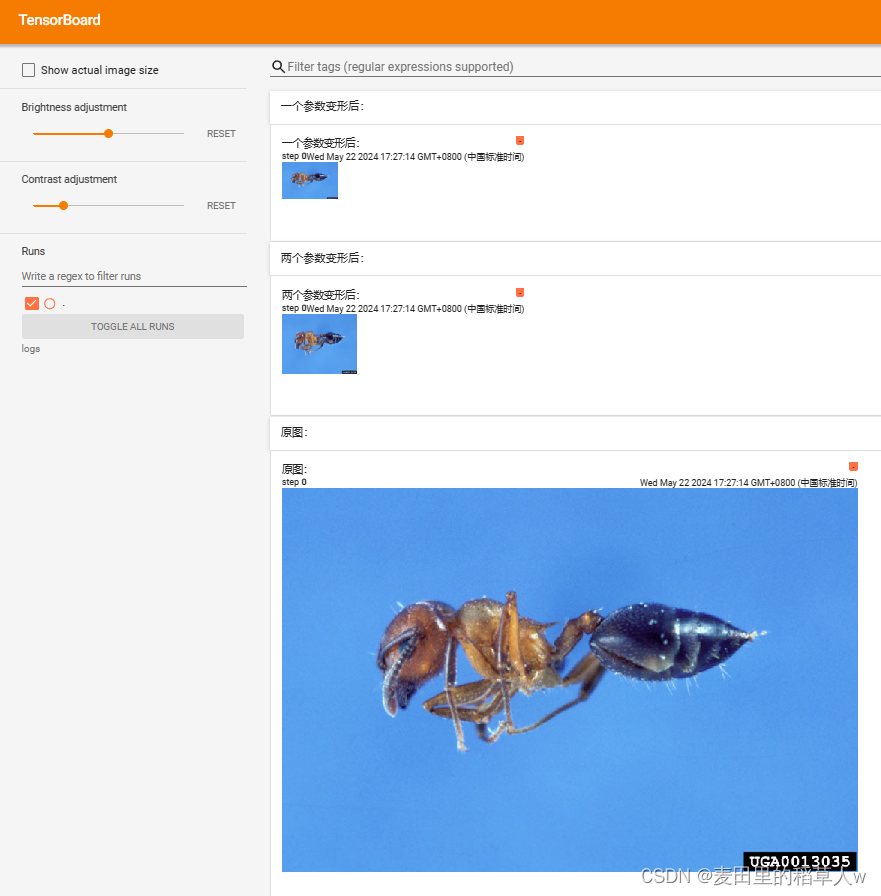
Compose
在上述的多个例子中,我们通常会使用两个transform工具,经常是先使用ToTensor方法将图片转化为Tensor类型,然后再使用别的工具处理Tensor类型数据。Compose的作用就是将两个工具合并起来,让我们的代码更加简洁。
【代码示例】使用compose组合ToTensor和normalize
py
from PIL import Image
import torchvision
from torch.utils.tensorboard import SummaryWriter
img_path="dataset/train/ants/0013035.jpg"
# 使用Image读取PIL类型的图像
img_PIL = Image.open(img_path)
my_totensor = torchvision.transforms.ToTensor()
my_normalize = torchvision.transforms.Normalize([0.5,0.5,0.5], [1,1,1])
mycompose = torchvision.transforms.Compose(
(my_totensor,my_normalize)
)
img_compose = mycompose(img_PIL)
# 可视化
writter = SummaryWriter("logs")
writter.add_image('compose:', img_compose)
writter.close()randomcrop
上面已经介绍了很多工具,这里的randomcrop是进行随机裁剪的,希望大家可以通过自学看源码等方式覅掌握这个工具,下面我只给出一个使用它的简单例子
py
from PIL import Image
import torchvision
from torch.utils.tensorboard import SummaryWriter
img_path="dataset/train/ants/0013035.jpg"
writter = SummaryWriter("logs")
# 使用Image读取PIL类型的图像
img_PIL = Image.open(img_path)
my_totensor = torchvision.transforms.ToTensor()
my_randomcrop = torchvision.transforms.RandomCrop((100.200))
mycompose = torchvision.transforms.Compose(
(my_totensor,my_randomcrop)
)
for i in range(10):
img_randomcrop = mycompose(img_PIL)
writter.add_image('random:',img_randomcrop,global_step=i)
writter.close()torchvision数据集
在pytorch官网页面Datasets --- Torchvision 0.18 documentation (pytorch.org),中详细列出了torchvision中的一些不同功能使用到的公共数据集的,如下图为图像分类使用的数据集
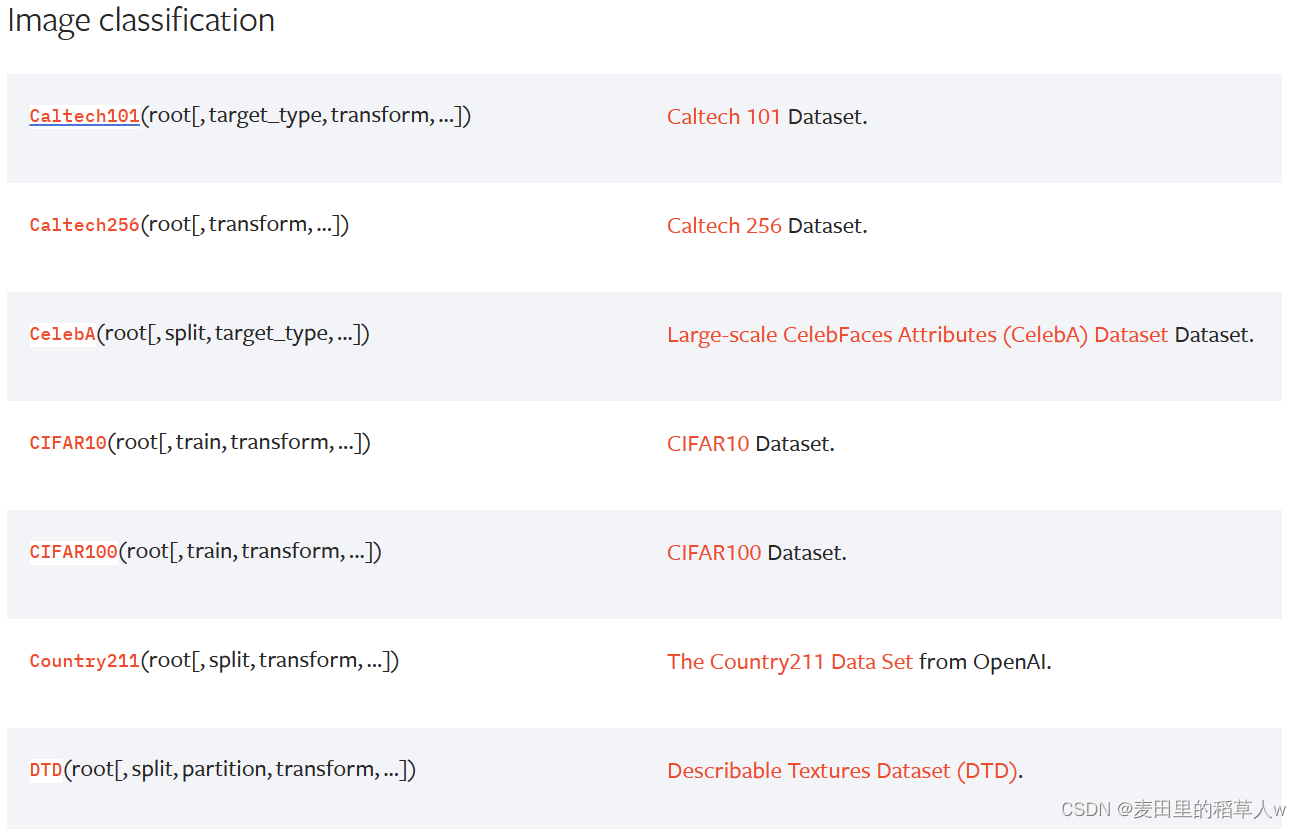
点进去之后可以看到数据集的详细信息,包括数据集大小、分类类型、以及下载方式等,接下来我都会使用CIFAR10数据集为例进行展示,因为其数据量不是很大,下载到本地后对存储的压力不是很大,
CIFAR10数据训练集主要包含了50000张10种类别的32*32图片信息,用于图像分类的使用,它的类别编号如下:
{'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
下载CIFAR10数据集的语法如下:
py
dataset = torchvision.datasets.CIFAR10(root="./dataset", train = True, download = True,transform=torchvision.transforms.ToTensor())
# CIFAR10为数据集的名字
# root为存放数据的目录
# train表示是否为训练数据集
# download表示是否将数据下载到本地
# transform可以指定如何对数据集进行预处理,通常都是使用ToTensor运行后得到的下载链接可以放到迅雷中使用,下载速度更快,下载后将压缩文件复制到当前的目录下面即可,系统再次运行时会对其进行解压使用
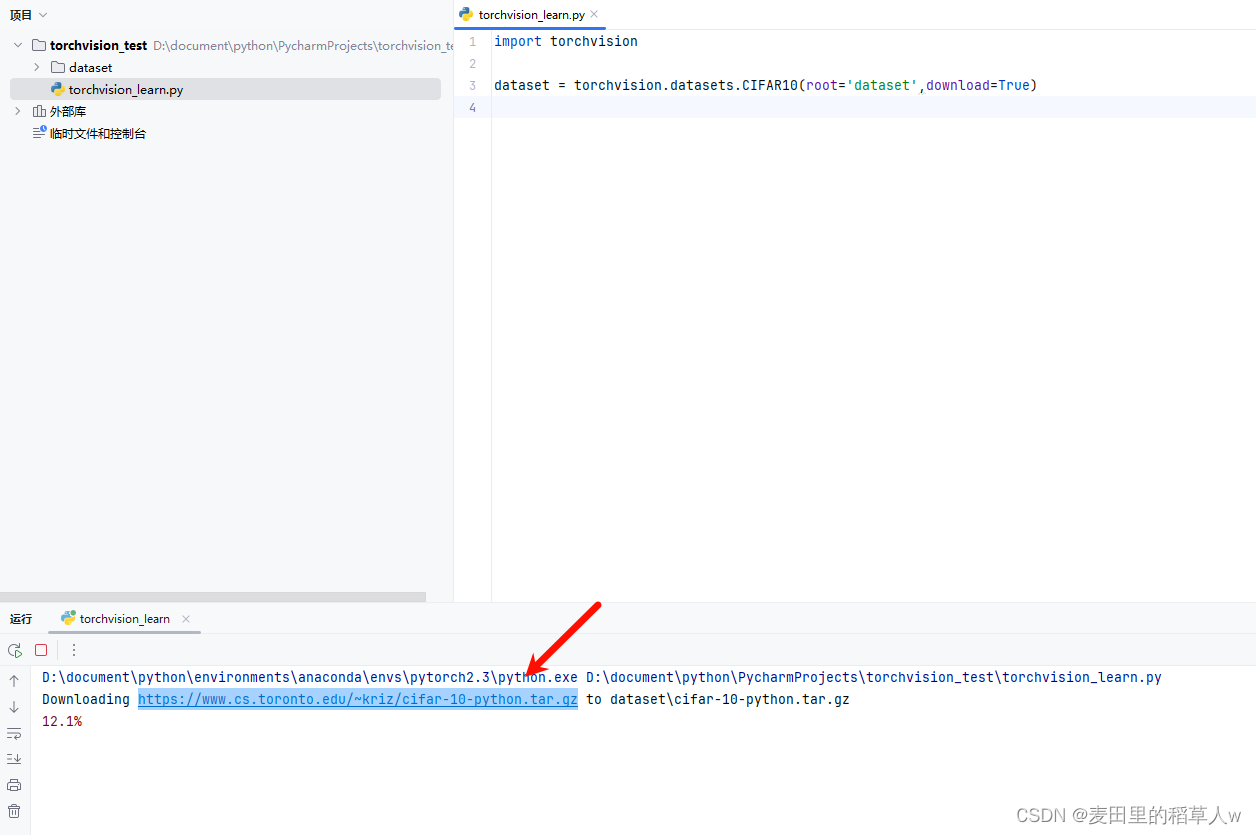
第一次下载后,即使继续打开download运行,系统在检测到之后就不需要继续进行下载了,所以download经常处于打开状态后续也无需进行修改
DataLoader
datalorader主要设置从DataSet中进行取数据的方式,比如每次取多少个数据,是否随机取数等。其基本语法如下:
py
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# dataset指定从哪个DataSet中进行读取数据
# batch_size指定每次读取数据的多少
# shuffle指定是否进行随机抽取
# num_workers指定的多线程数量,在Windows中设置大于0可能出问题
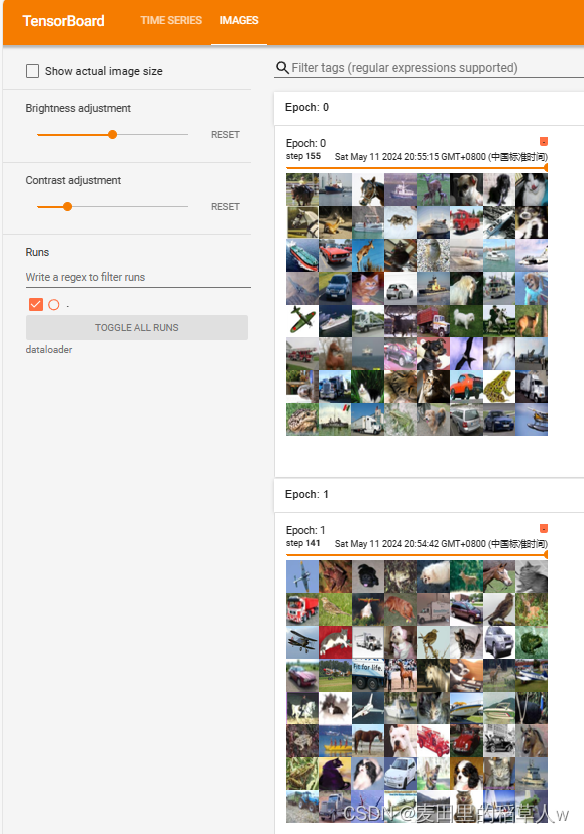
# drop_last表示是否保留最后余出的几个数据,比如一共有1024张图片,batch_size设置为100,最终会余出24个数据【代码示例】使用DataLoader读取CIFAR10数据集,每次读取64张图片
py
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()运行结果: