5. Functional API 搭建神经网络模型
5.1 利用Functional API编写宽深神经网络模型进行手写数字识别
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Input, Dense, concatenate
from tensorflow.keras.models import Model
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=23)
X_train, X_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.2, random_state=12)
print(X_valid.shape)
print(X_train.shape)
inputs = Input(shape=X_train.shape[1:])
hidden1 = Dense(300, activation="relu")(inputs)
hidden2 = Dense(100, activation="relu")(hidden1)
concat = concatenate([inputs, hidden2])
output = Dense(10, activation="softmax")(concat)
model_wide_deep = Model(inputs=inputs, outputs=output)
iris = load_iris():加载iris数据集,这是一个常用的多类分类数据集,包含了150个样本,每个样本有4个特征,属于3个不同的类别。
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=23):将iris数据集分割为训练集和测试集。test_size=0.2表示测试集的大小为原始数据的20%,random_state=23是一个随机种子,确保分割的可重复性。
X_train, X_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.2, random_state=12):进一步将训练集分割为训练集和验证集。同样,test_size=0.2表示验证集的大小为分割后训练数据的20%,random_state=12确保分割的可重复性。
print(X_valid.shape):打印验证集的特征数据的形状。
print(X_train.shape):打印新的训练集的特征数据的形状。
inputs = Input(shape=X_train.shape1:):定义模型的输入层,shape=X_train.shape1:指定输入的形状,由于X_train是一个二维数组,shape1:表示除了第一维(样本数量)之外的所有维度。
hidden1 = Dense(300, activation="relu")(inputs):定义第一个隐藏层,它有300个神经元,并使用ReLU激活函数。
hidden2 = Dense(100, activation="relu")(hidden1):定义第二个隐藏层,它有100个神经元,并使用ReLU激活函数。
concat = concatenate(inputs, hidden2):将输入层和第二个隐藏层的输出拼接起来,形成更宽的网络。
output = Dense(10, activation="softmax")(concat):定义输出层,它有10个神经元(对应于3个类别和一个额外的神经元,这是常见的做法),并使用softmax激活函数输出概率分布。
model_wide_deep = Model(inputs=inputs, outputs=output):创建一个Keras模型,将输入层和输出层连接起来。
使用scikit-learn库中的load_iris函数来加载iris数据集,然后使用train_test_split函数将数据集分割为训练集和测试集,以及进一步的训练集和验证集。接着,它定义了一个宽深网络(wide and deep network)模型,其中包含了输入层、两个隐藏层和一个输出层。
python
model_wide_deep.summary()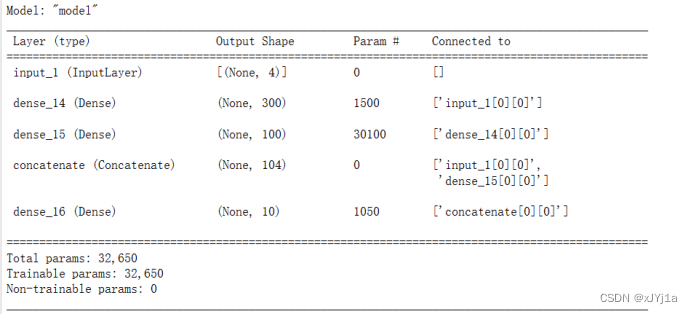
python
model_wide_deep.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
h = model_wide_deep.fit(X_train, y_train, batch_size=32, epochs=30,validation_data=(X_valid, y_valid))
python
# 绘图
pd.DataFrame(h.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()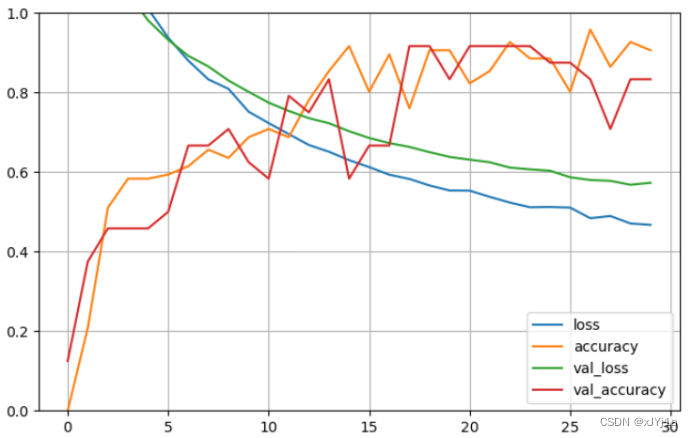
python
# 使用 model_wide_deep 评估测试集
test_loss, test_accuracy = model_wide_deep.evaluate(x_test, y_test, batch_size=32)
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_accuracy}")
6. SubClassing API 搭建神经网络模型
( 以前馈全连接神经网络手写数字识别为例 )
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Input, Dense, concatenate
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=23)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.2, random_state=12)
# 打印验证集和训练集的形状
print(X_valid.shape)
print(X_train.shape)
# 定义 Model_sub_fn 类
class Model_sub_fn(Model):
def __init__(self, units_1, units_2, units_out, activation="relu"):
super(Model_sub_fn, self).__init__()
self.hidden1 = Dense(units_1, activation=activation)
self.hidden2 = Dense(units_2, activation=activation)
self.main_output = Dense(units_out, activation="softmax")
def call(self, inputs):
x = self.hidden1(inputs)
x = self.hidden2(x)
return self.main_output(x)
定义了一个名为Model_sub_fn的类,该类继承自tensorflow.keras.Model。这个类用于创建一个简单的神经网络模型,它包含两个隐藏层和一个输出层。
class Model_sub_fn(Model) ****:****定义一个名为Model_sub_fn的类,它继承自tensorflow.keras.Model。这意味着Model_sub_fn类可以访问和继承Model类的所有属性和方法。
def init(self, units_1, units_2, units_out, activation="relu"):定义类的构造函数__init__,它接受四个参数:units_1(第一个隐藏层的神经元数量)、units_2(第二个隐藏层的神经元数量)、units_out(输出层的神经元数量)和activation(激活函数类型,默认为ReLU)。
super(Model_sub_fn, self).init():调用父类的构造函数,这是继承自Model类的标准做法。
self.hidden1 = Dense(units_1, activation=activation):定义第一个隐藏层,它有units_1个神经元,并使用activation作为激活函数。
self.hidden2 = Dense(units_2, activation=activation):定义第二个隐藏层,它有units_2个神经元,并使用activation作为激活函数。
self.main_output = Dense(units_out, activation="softmax"):定义输出层,它有units_out个神经元,并使用softmax作为激活函数。
def call(self, inputs):定义call方法,这是所有Keras模型必须定义的方法,它用于前向传播。在这个方法中,输入数据通过两个隐藏层,最后通过输出层。
x = self.hidden1(inputs):将输入数据通过第一个隐藏层。
x = self.hidden2(x):将第一个隐藏层的输出通过第二个隐藏层。
r eturn self.main_output(x):将第二个隐藏层的输出通过输出层,并返回结果。
python
model_sub_fn = Model_sub_fn(units_1=64, units_2=32, units_out=3)
# 创建 Model_sub_fn 实例
model_sub_fn = Model_sub_fn(300, 100, 3, activation="relu") # 假设输出层有3个单元,因为Iris数据集有3个类别
# 编译模型
model_sub_fn.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
# 训练模型
history = model_sub_fn.fit(X_train, y_train, batch_size=32, epochs=30, validation_data=(X_valid, y_valid))
python
model_sub_fn.summary()