目录
[1. 简介](#1. 简介)
[2. 详解](#2. 详解)
[2.1 数据对齐](#2.1 数据对齐)
[2.2 数据结构填充](#2.2 数据结构填充)
[3. 总结](#3. 总结)
1. 简介
软件开发者写的程序会在 CPU 处理器上运行,而硬件开发者设计的"内核"则会在 FPGA 上运行。这两部分需要通过一个精心设计的接口来沟通,就像两个人用对讲机来交流一样。为了确保这种沟通顺畅,数据必须以一种特定的方式来存储和组织,这就是所谓的存储器模型。这个模型就像是一个书架,告诉你如何摆放你的书籍,以便你能快速找到它们。
在这个过程中,有两个重要的概念:数据对齐和数据结构填充。
数据对齐就像是确保所有的书都准确地靠在书架的边缘,这样你就能更快地找到它们。
数据结构填充则是在书与书之间留出空间,以防它们挤在一起时难以取出。
Vitis HLS 编译器允许开发者调整这些规则,就像你可以调整书架的层板一样,以适应不同大小和形状的书籍。这样,软件和硬件就能更高效地一起工作,就像一个精心组织的图书馆一样。
2. 详解
2.1 数据对齐
打个比方,CPU 内存就像一个巨大的书架,而每本书代表了一块数据。程序员通常会认为这个书架是由一排排紧挨着的书组成的,每本书都可以单独拿出来看。
但实际上,现代的计算机处理器(就像是拿书的人)并不是每次只拿一本书,而是一次拿一整组书,比如一次拿2本、4本、8本,甚至更多。这样做的原因是,一次拿多本书可以更快地找到需要的信息,就像你可以一眼看到一组书的标题一样。
为了让处理器能够高效地拿书,书架上的书需要按照一定的规则摆放。比如,如果处理器一次拿4本书,那么每组书的第一本书的位置就需要是4的倍数。这就是所谓的"对齐"。如果书没有按照这个规则摆放,处理器在拿书时就会遇到麻烦,可能会拿得很慢,或者甚至拿不到想要的书。
如果程序员在编写软件时没有考虑到这些对齐的规则,就**可能会导致软件运行缓慢,或者程序卡住不动,有时候甚至会导致整个操作系统崩溃。**最糟糕的情况是,软件可能会在没有任何提示的情况下出错,给出错误的结果。所以,理解并正确处理内存对齐是非常重要的,它可以确保软件运行得既快速又稳定。
下表显示了 C/C++ 中对应 32 位和 64 位 x86-64 GNU/Linux 机器的基本原生数据类型的大小和对齐(以字节数为单位):
|-------------|----|----|----|----|
| 类型 | 32 位 x86 GNU/Linux || 64 位 x86 GNU/Linux ||
| 类型 | 大小 | 对齐 | 大小 | 对齐 |
| float | 4 | 4 | 4 | 4 |
| double | 8 | 4 | 8 | 8 |
| long double | 12 | 4 | 16 | 16 |
| void* | 4 | 4 | 8 | 8 |
为了在存储器要求和性能之间取得平衡,程序员可能需要更改数据的默认对齐方式。因为在主机与加速器(FPGA)之间往返发送数据时,发射的每个字节都有成本。
GCC C/C++ 编译器提供了一个语言扩展 attribute((aligned(X))),允许程序员为变量、结构体或类指定一个特定的对齐字节数。例如,声明 int x attribute ((aligned (16))) = 0; 会使编译器在16字节边界上分配变量 x。
使用 attribute((aligned(X))) 不会改变变量的大小,但会通过在结构体元素之间添加填充来改变内存布局,从而可能增加结构体的总大小。aligned 属性只能用来增加对齐的字节数,不能减少。C++ 中的 offsetof 函数可以用来确定结构体中每个成员的对齐情况。
如果在使用 attribute((aligned)) 时没有明确指定一个对齐因子(即 X 的值),编译器会自动选择一个对齐值。这个值是目标机器上所有数据类型中最大的对齐要求。例如,如果目标机器上最大的数据类型对齐要求是8字节,那么编译器会将变量或字段对齐到8字节边界。
这样做的好处是可以提高内存访问的效率。因为大多数现代处理器在访问对齐的数据时更加高效,特别是当数据的对齐边界与处理器的内存访问粒度相匹配时。这意味着,如果处理器一次可以高效地读取8字节,那么在8字节边界上对齐的数据可以一次性被读取,而不需要多次内存访问。这就是为什么默认情况下,编译器会选择最大的对齐要求,以期望在不同的内存访问操作中获得最佳性能。
2.2 数据结构填充
在C++中,内置的数据类型(如 int, float 等)有预定义的对齐要求,这些要求确保了数据在内存中的有效访问。对于用户定义的数据类型,如结构体或类,编译器也会自动确保其中的成员变量是正确对齐的。
为了做到这一点,编译器可能会在结构体或类的成员变量之间插入填充字节(也称为"padding")。这是因为每个成员变量可能有不同的对齐要求,而编译器需要确保每个成员都按照其类型的对齐要求放置在内存中。
此外,如果有一个用户定义类型的数组,编译器还会在数组的每个元素之间添加填充,以确保数组中的每个元素都能满足对齐要求。这样做的目的是为了提高数组元素访问的效率。在某些情况下,编译器甚至会在结构体或类的最后一个成员之后添加额外的填充,以确保当这个结构体或类被用作数组元素时,数组中的下一个元素也能正确对齐。
比如以下这个示例:
cpp
struct One
{
short s;
int i;
char c;
}
struct Two
{
int i;
char c;
short s;
}在 struct One 的例子中,short 类型的 s 成员要求在2字节边界上对齐,int 类型的 i 成员要求在4字节边界上对齐,而 char 类型的 c 成员对齐要求最小,通常是1字节。因为 int 类型的对齐要求是最严格的,所以整个结构体会在4字节边界上对齐。
为了满足这些对齐要求,编译器会在 s 和 i 之间插入2个填充字节,以确保 i 在4字节边界上对齐。同样地,为了在 c 之后开始新的对齐块,编译器会在 c 之后插入3个填充字节。因此,struct One 的总大小变为12字节。
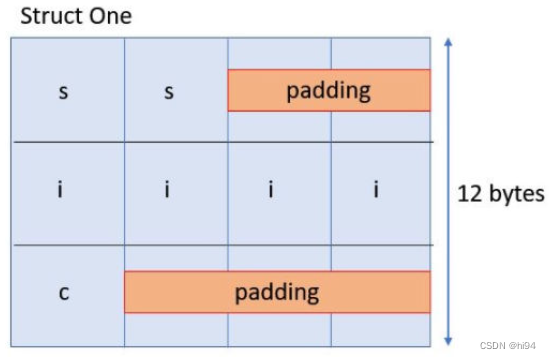
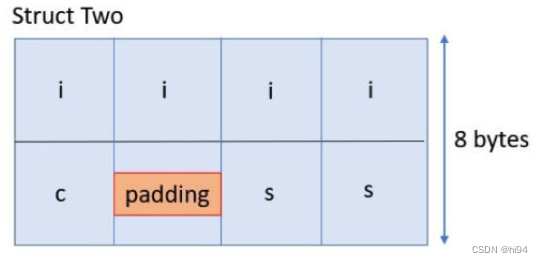
然而,在 struct Two 中,成员的顺序被重新排列,以减少填充的需要。int 类型的 i 成员首先出现,后面紧跟着 char 类型的 c 和 short 类型的 s。c 只需充填一个字节,s 则不需要额外的填充。因此,struct Two 的总大小只有8字节。
3. 总结
在现代计算机系统中,数据对齐和结构填充是确保数据存储和访问效率的关键因素。数据对齐涉及将数据按照处理器优化的边界排列,以加快访问速度。结构填充则是在数据结构中插入额外空间,以保持成员变量的正确对齐。这些概念在硬件设计中尤为重要,因为 FPGA 和其他硬件加速器对数据布局的要求更为严格。Vitis HLS 等工具允许开发者自定义对齐和填充规则,以优化软件与硬件之间的数据交互,从而提升整体性能。理解并应用这些原则,可以帮助开发者在存储器要求和性能之间找到最佳平衡点。
