1.前言
根据之前的文章学习我们清楚的了解了注意力机制中的实现过程深度学习网络笔记Ⅲ(注意力机制)-CSDN博客
接下来进一步总结Transform的网络架构
根据之前的所整理的知识我们至今已经学习了三种核心架构,每种架构下面有很多网络结构
三种架构
- VGG类型的架构 cp --> cp --> ccp --> fc 类型的串联架构
- detector=backbone+neck+head 目标检测网络架构
- Encode -> Decode 这种Transformer类型的网络架构
2.模型架构
0.Transformer的训练过程
简单理解其训练过程:
Q:人工智能是什么?
A:人工智能(AI)是计算机科学的分支,旨在让机器模拟、延伸和扩展人类智能,执行通常需要人类智慧才能完成的任务。
上面这种QA对就是transformer的训练所需的QA对进行训练。其训练原理并非将整个QA对作为输入和输出进行训练。而是
1.Encode 部分的Input输入 人工智能是什么?
2.Decode 部分的outputs输入 <sos> (<sos>常用于告诉回答开始的标记)
我们可以理解为 X(整个输入) =Encoder 和 Decoder 分工协同≈ 人工智能是什么? + <sos>
而输出label:也就是A中的第一个字符 "人"(此时的"人"的理想情况是词库中概率分布最高的词)-> 进行自回归 -> 第二次输入就是
X = 人工智能是什么? + <sos>人
label = 工(理想情况下的概率最高的词)
专业的理解其训练过程:
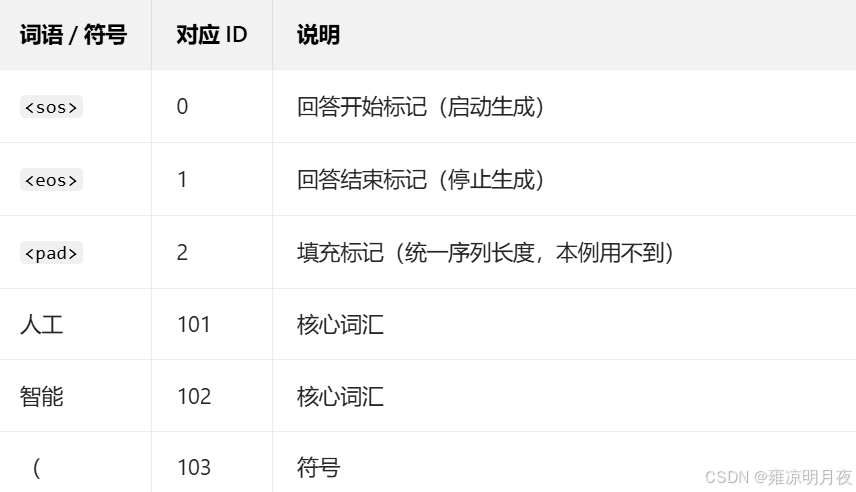
1.词表和编码:将所涉及到的词语符号分配为唯一的整数ID(简化版词表)类似于这样
2.预处理后的序列(模型真正 "读" 的内容)
问题(Q)预处理后:分词→转 ID→添加「词嵌入 + 位置编码」原始 Q:人工智能是什么?分词后:人工智能,是,什么,?转 ID 后:601, 201, 701, 801→ 最终 Encoder 输入(带位置编码的向量):记为「Q 特征」(模型对 "问题的理解")
回答(A)预处理后 :分词→加
<sos>/<eos>→拆分为「Decoder 输入序列」和「label 序列」原始 A:人工智能(AI)是计算机科学的分支分词后:人工智能,(, AI, ), 是,计算机,科学,的,分支加标记后:``, 人工智能,(, AI, ), 是,计算机,科学,的,分支,` 转 ID 后:0, 601, 103, 104, 105, 201, 301, 302, 401, 501, 1` → 拆分结果:
- Decoder 输入序列(前缀序列):0, 601, 103, 104, 105, 201, 301, 302, 401, 501(
<sos>+ 回答前缀,无<eos>)- label 序列(目标序列):601, 103, 104, 105, 201, 301, 302, 401, 501, 1(回答内容 +
<eos>,比输入序列右移 1 位)Transformer 的训练核心是「逐词预测 + 反向传播」,下面按 "每一步生成" 拆解,清晰展示 Encoder、Decoder 的分工与协同:
3.可视化训练过程:自回归生成 + 模块协同
- Encoder 的固定工作:全程只处理「Q 特征」(601, 201, 701, 801 的向量形式),输出 "问题的语义特征矩阵"(比如 "人工智能""是什么" 的核心含义),供 Decoder 参考。
- Decoder 的固定规则 :
- 输入:仅「回答前缀」(从
<sos>开始逐步累加);- 掩码:只能看到前缀中 "已生成的词",看不到 "未来的词"(比如输入
<sos>时,看不到后面的 "人工智能");- 协同:通过「交叉注意力」读取 Encoder 的 "问题语义特征",确保生成的词和问题相关。
该案例的核心逻辑总结
-
模块分工明确:
- Encoder:只 "读问题、懂问题",输出固定的 "问题语义特征",全程不参与生成;
- Decoder:只 "读前缀、生新词",通过交叉注意力 "参考" Encoder 的结果,确保回答不跑偏。
-
自回归的本质 :每一步的输入 = 上一步的输入 + 上一步的预测结果,逐步 "拼凑" 出完整回答,直到生成
<eos>。 -
输入与 label 的关系 :Decoder 输入序列(10 个词)=
<sos>+ 回答核心内容(无<eos>);label 序列(10 个词)= 回答核心内容 +<eos>;两者是 "向右偏移一位" 的对应关系,确保每一步预测的是 "下一个该出现的词"。 -
关键保障机制:
- 掩码:不让 Decoder "偷看未来的词"(比如步骤 2 看不到 "(" 后面的 "AI");
- 交叉注意力:不让 Decoder "答非所问"(比如不会把 "人工智能是什么" 答成 "今天吃米饭")
掩码(Mask):
掩码(Mask)的核心作用是:防止 Decoder 在预测当前词时 "偷看" 未来的词,强制模型只能基于 "已生成的前缀" 和 "Encoder 的问题语义" 进行预测。
核心价值:
- 保证自回归的逻辑一致性:训练时模型 "逐词预测" 的逻辑,和实际生成时 "逐词拼接" 的逻辑完全一致
- 避免模型 "作弊:强制模型学习 "基于已有信息推导未知" 的能力
- 贴合人类语言习惯:人类说话 / 写作也是 "想到前面的词,再推导后面的词"
没有掩码,自回归生成就成了 "作弊式训练",模型看似训练成功,实则毫无用处;有了掩码,模型才能真正学会 "根据已有信息说下一句话"。
1.Transformer的NLP用途
上述为标准的Transform的模型架构,最初我们运用Transform主要用于处理自然语言(NLP)。
NLP处理中神经网络的输入为:sentence,文本等信息。
NLP处理步骤
1.文本 -> Tensor 文本向量化/词嵌入。
- Tokenize : 符号化(拆分基本语义单元 )
- Embedding : 词嵌入(低维稠密向量:将文本的词嵌入到空间中用一个向量来表示词)
注意:Tokenize转换为向量必须考虑到词性和词义关联度强弱问题和词之间的相似性问题,如果使用常规的例如one-hot编码/整数编码无法体现。 我们采取的是词嵌入Embedding的方式进行解决,词义相近时,在空间上也相近(本质上就是将词转换为Tensor)。
注意力机制中的公式:Q = E*W_q 其中E的本质就是词嵌入。其Q的结果就是Tensor。
⭐⭐⭐CV与NLP的tensor称呼的差异
1.在NLP提取特征的方式是注意力机制,其中产出的结果有两个称呼。
表征,表述(representation)/隐状态(Hidden status)
2.CV 提取特征的方式靠卷积,其中的产出的结果称为
特征图(feature_map)
注意力机制在NLP中的本质:更丰富的语义的表征
1.分析句子的结构。
2.分析各词之间的关联。
3.词在句子中特定上下文的具体语义。
代码案例:
python
import torch
import torch.nn as nn
# ===================== 步骤1:构建简单的语料和词汇表(基础准备) =====================
# 1. 定义简单语料(2个句子,模拟NLP任务的输入)
corpus = [
"I love natural language processing",
"Transformer is a powerful model"
]
# 2. 分词(英文简单分词,按空格分割,中文需专用分词工具如jieba)
# 先将所有句子合并,提取所有唯一词汇,构建词汇表
all_words = []
for sentence in corpus:
words = sentence.lower().split() # 转小写+按空格分词
all_words.extend(words)
unique_words = list(set(all_words)) # 去重,得到唯一词汇列表
# 3. 构建词汇-索引映射(NLP中必须将离散的词转为连续的索引ID)
word2idx = {word: idx for idx, word in enumerate(unique_words)} # 词->索引
idx2word = {idx: word for word, idx in word2idx.items()} # 修正:添加 .items(),索引->词(用于后续还原验证)
vocab_size = len(unique_words) # 词汇表大小(后续Token嵌入的输入维度)
# ===================== 步骤2:定义Transformer风格的词嵌入模型 =====================
class TransformerWordEmbedding(nn.Module):
def __init__(self, vocab_size, embedding_dim, max_seq_len):
"""
初始化Transformer词嵌入层
:param vocab_size: 词汇表大小
:param embedding_dim: 嵌入向量维度(所有词将被转为该维度的连续向量)
:param max_seq_len: 最大序列长度(句子的最大词数,用于位置嵌入)
"""
super(TransformerWordEmbedding, self).__init__()
# 1. Token嵌入层(核心:将离散索引ID转为连续向量,可学习参数)
self.token_embedding = nn.Embedding(
num_embeddings=vocab_size, # 词汇表大小
embedding_dim=embedding_dim, # 嵌入向量维度
padding_idx=None # 无padding,简单案例省略
)
# 2. 位置嵌入层(核心:注入位置信息,可学习参数,与Token嵌入维度一致)
# 两种实现方式:① 可学习的位置嵌入(本文采用,简单直观) ② 固定正弦余弦嵌入(Transformer原论文)
self.positional_embedding = nn.Embedding(
num_embeddings=max_seq_len, # 最大序列长度(位置索引范围:0~max_seq_len-1)
embedding_dim=embedding_dim # 必须与Token嵌入维度一致,才能相加
)
# 记录最大序列长度
self.max_seq_len = max_seq_len
def forward(self, x):
"""
前向传播:生成最终的Transformer词嵌入(Token嵌入 + 位置嵌入)
:param x: 输入的词索引序列,形状为 [batch_size, seq_len]
:return: 最终词嵌入结果,形状为 [batch_size, seq_len, embedding_dim]
"""
# 1. 获取Token嵌入结果(将索引转为连续向量)
token_embeds = self.token_embedding(x) # [batch_size, seq_len, embedding_dim]
# 2. 生成位置索引(为每个词的位置分配索引:0,1,2,...seq_len-1)
batch_size, seq_len = x.shape
# 确保序列长度不超过最大限制
if seq_len > self.max_seq_len:
raise ValueError(f"序列长度{seq_len}超过最大限制{self.max_seq_len}")
# 生成位置索引矩阵,形状与输入x一致 [batch_size, seq_len]
pos_indices = torch.arange(0, seq_len).unsqueeze(0).repeat(batch_size, 1)
# 3. 获取位置嵌入结果
pos_embeds = self.positional_embedding(pos_indices) # [batch_size, seq_len, embedding_dim]
# 4. Token嵌入 + 位置嵌入(核心:两者维度一致,逐元素相加,注入位置信息)
final_embeds = token_embeds + pos_embeds
return final_embeds
# ===================== 步骤3:数据预处理(将句子转为索引序列) =====================
def sentence_to_idx(sentence, word2idx, max_seq_len):
"""将单个句子转为索引序列,并做长度对齐(截断/补零)"""
words = sentence.lower().split()
# 词->索引
idx_seq = [word2idx.get(word, 0) for word in words] # 未知词默认取索引0(简单处理)
# 长度对齐(补零到max_seq_len)
if len(idx_seq) < max_seq_len:
idx_seq += [0] * (max_seq_len - len(idx_seq))
else:
idx_seq = idx_seq[:max_seq_len]
return torch.tensor(idx_seq, dtype=torch.long).unsqueeze(0) # 增加batch维度 [1, max_seq_len]
# 定义超参数
embedding_dim = 16 # 嵌入向量维度(可自定义,如32、64、128)
max_seq_len = 6 # 最大序列长度(观察语料,最长句子有5个词,设为6足够)
# 处理语料中的两个句子,转为模型输入格式 [batch_size, max_seq_len]
sentence1_idx = sentence_to_idx(corpus[0], word2idx, max_seq_len)
sentence2_idx = sentence_to_idx(corpus[1], word2idx, max_seq_len)
batch_input = torch.cat([sentence1_idx, sentence2_idx], dim=0) # 合并为batch输入 [2, 6]
# ===================== 步骤4:实例化模型并执行词嵌入 =====================
# 1. 实例化词嵌入模型
embedding_model = TransformerWordEmbedding(vocab_size, embedding_dim, max_seq_len)
# 2. 执行前向传播,获取最终词嵌入结果(无梯度计算,仅用于演示)
with torch.no_grad():
final_embedding_result = embedding_model(batch_input)
# ===================== 步骤5:输出结果验证 =====================
print("=" * 80)
print(f"词汇表大小:{vocab_size},词汇表:\n{word2idx}\n")
print(f"输入批次数据形状:{batch_input.shape}")
print(f"最终词嵌入结果形状:{final_embedding_result.shape}\n")
# 打印第一个句子的词嵌入详情(验证位置信息和Token信息的注入)
print("第一个句子「{}」的词嵌入详情:".format(corpus[0]))
for i, word in enumerate(corpus[0].lower().split()):
word_idx = word2idx[word]
# 包裹在 with torch.no_grad() 中,临时关闭梯度追踪
with torch.no_grad():
token_embed = embedding_model.token_embedding(torch.tensor([word_idx])) # 单独Token嵌入
pos_embed = embedding_model.positional_embedding(torch.tensor([i])) # 单独位置嵌入
final_embed = final_embedding_result[0, i, :] # 最终嵌入(Token+Position)
print(f" 词:{word}(索引:{word_idx})")
print(f" Token嵌入向量(前5维):{token_embed.squeeze().numpy()[:5]}")
print(f" 位置嵌入向量(前5维):{pos_embed.squeeze().numpy()[:5]}")
print(f" 最终嵌入向量(前5维):{final_embed.numpy()[:5]}\n")2.Transformer基础构成
整体框架:
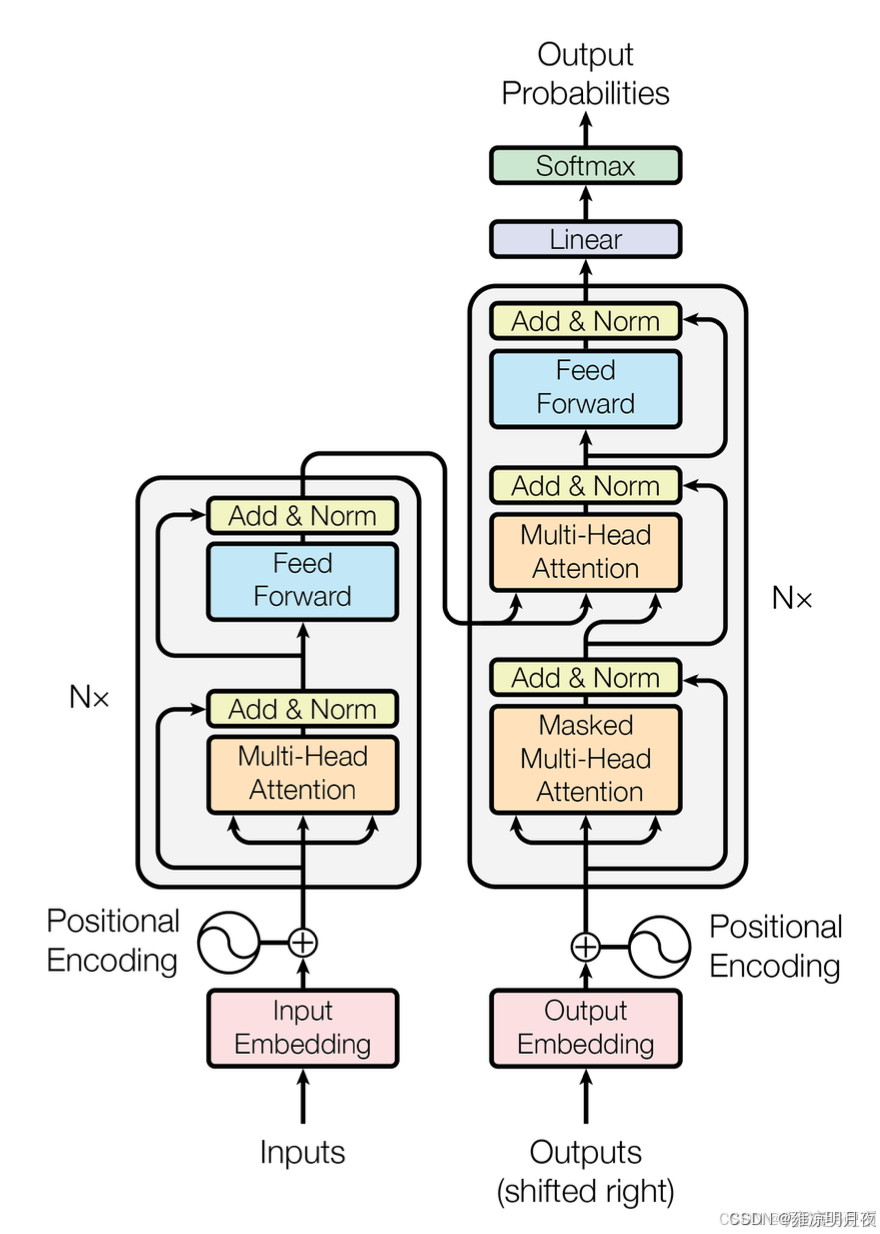
输入 → 嵌入层(Token Embedding)+ 位置编码(Positional Encoding)→ Encoder 栈 → Decoder 栈 → 输出层(Linear + Softmax)
Encoder 栈:负责「理解输入」(双向捕捉全局依赖),N 层堆叠(论文 N=6)
Decoder 栈:负责「生成输出」(单向生成,避免偷看未来信息),N 层堆叠(论文 N=6)
Encoder 单层结构(核心:双向理解)
输入 → 多头自注意力(Multi-Head Attention)→ 残差连接 + 层归一化 → 前馈神经网络(FFN)→ 残差连接 + 层归一化 → 输出.
细节解析:
- 多头自注意力(MHA): 「线性映射→拆分多头( 论文头数 = 8**)→计算注意力→加权求和→拼接多头」。**
- 残差链接+层归一化 :避免梯度消失,加速收敛。
- **前馈神经网络(FFN):**FFN(x) = max(0, xW1 + b1)W2 + b2,中间层维度是输入的 4 倍(论文中 512→2048→512),激活函数用 GELU,更适合 Transformer。
Decoder 单层结构(核心:单向生成)
输入 → 掩码多头自注意力(Masked MHA)→ 残差连接 + 层归一化 → 编码器-解码器注意力(Enc-Dec MHA)→ 残差连接 + 层归一化 → FFN → 残差连接 + 层归一化 → 输出
细节解析:
1.在 Encoder 基础上增加 2 个特殊模块,确保生成时「不偷看未来信息」。
2.Decode的输出是词库中每个词的概率
3.自回归是原始Decode的核心工作模式:单项依赖+逐次生成。
- 掩码多头自注意力(Masked MHA) :下三角掩码矩阵,经过softmax后变为0,相当于隐蔽。作用是生成第i个词时,只能看到前 (i-1) 个词。效果是提速。
- 编码器 - 解码器注意力(Enc-Dec MHA):原理是Q来自Decoder的第n层,K,V来自于n+1层,作用是让Decoder关注Encoder的输出信息。
关键辅助组件:
位置编码(Positional Encoding)
1.自注意力是「无序的」(输入序列打乱后,注意力计算结果不变),必须补充位置信息。
⭐正弦余弦编码(论文方案):无需训练,可无限拓展的长序列。
⭐可学习位置编码(后续优化):与Token Embedding类似,是可训练的参数,效果更好但增加参数量。
词嵌入(Token Embedding)
⭐将离散符号(如单词 ID、图像 Patch)映射为固定维度的向量(论文维度 d_model=512),通常与输出层的线性变换共享权重(减少参数)。
核心优势:
- 并行计算效率高:彻底摆脱 RNN 的串行依赖,训练时可同时处理整个序列,大幅缩短训练时间(这是 Transformer 能做大的关键)。
- 长距离依赖捕捉强:无需像 RNN 那样依赖门控,也无需像 CNN 那样堆叠多层,直接通过注意力权重关联任意两个位置(比如 1000 长度的序列,第 1 个词和第 1000 个词可直接建立依赖)。
- 全局视野 + 动态注意力:每个位置都能看到整个序列,且注意力权重是动态学习的(比如翻译时,"苹果" 会重点关联 "apple",而非固定关联)。
- 模块化 + 迁移性强:Encoder/Decoder 层结构统一,可灵活堆叠;只需修改输入处理(如图像分 Patch、语音转序列),就能迁移到 CV、语音等领域(如 ViT、Whisper)。
潜在缺点:
- 计算复杂度高:注意力机制的时间 / 空间复杂度是 O (n²)(n 是序列长度),长序列(如 n=10000)时开销巨大(后续优化:Sparse Attention、Linear Attention 等)。
- 对位置编码敏感:依赖位置编码提供时序信息,若编码设计不当,长序列性能会下降。
理解
Transformer ---- 超级翻译官
翻译官1(RNN):「逐字读句子」,读得慢还忘记之前的词(长距离依赖差)
翻译官2(CNN):「用放大镜看句子」:每次只能看相邻几个词(局部感受野)
Transformer :
- 「一眼看完整个句子」(并行计算):不用逐字读,瞬间掌握所有词的位置和关系,翻译速度快很多;
- 「自动关注重点」(自注意力):比如翻译 "我在公园散步,它很可爱" 时,会自动知道 "它" 指的是 "小狗"(如果上下文有 "小狗"),而不是 "公园"------ 这就是注意力权重的作用,动态分配每个词的重要性;
- 「分两步干活」(Encoder-Decoder):
- 第一步(Encoder):把要翻译的中文句子「彻底读懂」,搞清楚每个词的意思和上下文关联(比如 "散步" 的主语是 "我",地点是 "公园");
- 第二步(Decoder):根据读懂的意思,「一步步写英文」,同时保证不 "偷看" 还没写的词(比如写 "walk" 时,不能提前看后面的 "it")------ 这就是掩码机制的作用;
- 「记着词的顺序」(位置编码):因为 "一眼看完" 不知道词的先后(比如 "我吃饭" 和 "饭吃我" 意思完全不同),所以会给每个词加一个 "位置标签",告诉模型谁在前谁在后。
核心就是「用注意力机制捕捉全局关系,用并行计算提高效率」
⭐3.问题归纳
**Q1:**CNN具有归纳偏置的特征,Transformer又具有很强的全局归纳建模能力,使用CNN+transformer的混合模型是不是可以得到更好的效果?
A1:
1.CNN的归纳偏置 :CNN 的归纳偏置是局部性和平移不变性,这是它的核心特点,也是优势(适合捕捉局部特征、计算高效),但也是局限(全局依赖弱)。
CNN缺陷:
1.但从未见过的东西那就不会。
2.长距离依赖不强。
3.相对来说语义特征提取没有transformer丰富。
2.Transformer 的全局建模能力来自自注意力,能捕捉长距离依赖,但缺乏归纳偏置,导致数据需求大、计算成本高。
Tranformer缺陷:容易过拟合
1.参数量大,效率低
2.长距离依赖,可能捕获一些无关紧要的特性 -> 解决方法:需要更多更丰富的数据 10w+
3.位置编码 --->(训练后插入一些先验信息),表现:训练人脸识别图像中人脸都在C位,导致别的位置人脸识别不出来。此时CNN中的归纳偏置中的平移不变性就能更好的弥补。
核心正是利用两者的互补性:用 CNN 的归纳偏置解决 "局部特征高效提取",用 Transformer 的全局建模能力解决 "长距离依赖捕捉",在多数复杂 CV 任务(如目标检测、图像分割、视频理解)中确实能显著提升效果。
视频理解常用方法:
1.transformer
2.CNN中输入3C -> NC (通道数)
3.LSTM时间训练
- CNN 像 "显微镜":擅长聚焦局部细节,快速提取图像的边缘、纹理、局部结构(比如猫的耳朵形状、眼睛轮廓),效率高、成本低。
- Transformer 像 "望远镜":擅长观察全局关联,搞清楚不同局部特征之间的关系(比如 "耳朵" 和 "眼睛" 的位置关系,是否属于同一只猫),视野广、关联性强。
- 混合模型就是 "显微镜 + 望远镜":先用显微镜看清局部细节,再用望远镜理清全局关系,自然比单独用一个看得更清楚、更全面。
方案 1:CNN 做 "前端特征提取",Transformer 做 "后端全局建模"(最通用)
应用:目标检测 / ViT 的改进版
方案 2:Transformer 嵌入 CNN 中间层(增强局部特征的全局关联)
应用:图像分割
方案 3:Transformer 借鉴 CNN 的归纳偏置
应用:Swin Transformer(当前 CV 最主流的混合架构)
Q2:注意力计算时为什么要 除sqrt(d)?
A2: 起到归一化作用,能缓解梯度消失。
Q3:怎么理解多头注意力,有什么用?A3:不同的角度维度提取特征,特征的拓展和压缩,提取主要特征。
Q4:Pre Norm 和 Post Norm 区别A4:Post Norm是原模型中先注意力机制+残差再归一化。而Pre Norm 是先归一化再进行注意力机制和残差,效果更好
Q5:为什么需要mask attention?A5:提高计算效率,因为decode是自回归【上一次的输出和历史会作为本次的输入】过程,不应该看到未来。
Q6:全连接有什么用?A6:特征压缩,输出概率
Q7:简单说一下Encoder 过程和Decoder 过程?A7:1.Encode:输入经嵌入 + 位置编码后,通过多层 "双向多头自注意力(捕捉全局依赖)+ 前馈神经网络(非线性特征提炼)",搭配残差连接与层归一化稳定训练,最终输出全局语义特征,完成对输入的 "理解"。
2.以 Encoder 特征为参考,输入为已生成序列(嵌入 + 位置编码),先通过掩码自注意力屏蔽未来信息,再经 Enc-Dec 注意力对齐输入语义,最后通过 FFN 逐次生成下一个 token,直至输出结束符号,完成 "输出生成"。
Q8:为什么需要位置编码?A8:语言本身是一个时序。能够保证关注到重要特征。中间特征层会扰乱,加上位置编码就可以保证这个时序关系
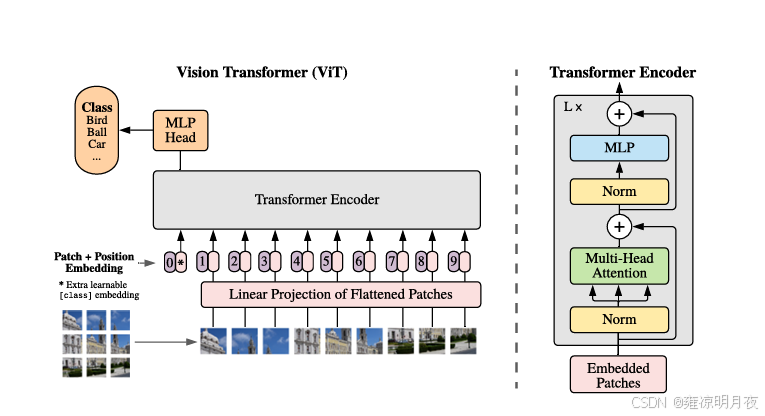
3.Vit(Vision Transformer 2020)
目前在CV行业常用的图像处理是用VIT/Swin transformer,当前的大模型视觉以VIT为主。
1.思想起源
ViT(Vision Transformer)是 2020 年论文
《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》
2010.11929
https://arxiv.org/pdf/2010.11929提出的纯 Transformer 图像分类模型,
核心突破
「将图像拆分为 Patch 序列,用 Transformer Encoder 直接建模全局依赖」
VIT的核心思想:
借鉴 NLP 的 Transformer,将图像转化为 "图像句子",用自注意力机制捕捉全局特征。
核心逻辑为3步骤:
- 图像分块(Patch Embedding):把 2D 图像(如 224×224)分割成固定大小的非重叠 Patch(如 16×16),每个 Patch 相当于 NLP 中的一个 "Token";
- 序列构建:将每个 Patch 展平为 1D 向量,通过线性变换映射到固定维度(如 768),再拼接「Class Token」和「位置编码」,形成 Transformer 可处理的序列;
- 全局建模:用纯 Transformer Encoder(无 Decoder)对序列进行全局依赖建模,最终通过 Class Token 的输出进行分类。
通俗类比:把图像看作 "由 16×16 像素的小图片组成的句子",每个小图片是一个 "词",Class Token 是 "句子的中心思想",Transformer Encoder 负责理解所有 "词" 之间的全局关系(比如 "猫的耳朵" 和 "猫的眼睛" 的位置关联),最后通过 "中心思想" 判断图像类别。
2.VIT架构拆解
以标准 ViT-B/16(ImageNet 分类任务)为例,输入图像尺寸 224×224×3。
python输入图像 (B, 3, 224, 224) [B,C,W,H] → Patch Embedding (分割+线性映射) → Patch序列 (B, 196, 768) → 拼接Class Token → (B, 197, 768) → 叠加位置编码 → (B, 197, 768) → 12层Transformer Encoder → (B, 197, 768) → 提取Class Token输出 (B, 768) → 分类头(Linear) → 类别概率 (B, 1000)详细说明:
1. (B, 3, 224, 224) B,C,W,H
2.Patch Embedding:图像→序列的关键一步->(B,196,768)
- 分块:将224x224 图像按照 16x16分割,得到(224/16) x (224/16) = 14 x 14 = 196个patch。
- 展平:每个16x16x3的patch块展平为16x16x3 = 768维的1D向量。
- 线性映射:用一个线性层(输入 768 维,输出 768 维)将展平后的向量映射到 Transformer 的输入维度(d_model=768)------ 本质是对每个 Patch 进行特征提取,相当于 "Patch 级别的卷积"。
⭐工程实现不用手动分块+展平,直接用卷积替代(计算效率高)
pythonclass PatchEmbedding(nn.Module): def __init__(self, img_size=224, patch_size=16, d_model=768, in_chans=3): super().__init__() self.img_size = img_size self.patch_size = patch_size self.num_patches = (img_size // patch_size) ** 2 # 196 # 用卷积层实现Patch分块+线性映射 self.proj = nn.Conv2d(in_chans, d_model, kernel_size=patch_size, stride=patch_size) def forward(self, x): # x: (B, 3, 224, 224) x = self.proj(x) # (B, 768, 14, 14) → 卷积后得到Patch特征图 x = x.permute(0, 2, 3, 1) # (B, 14, 14, 768) → 调整维度顺序 x = x.reshape(x.shape[0], -1, x.shape[-1]) # (B, 196, 768) → 转为序列 return x3.拼接 Class Token:全局特征的 "聚合器"
- Transformer Encoder 输出 197 个向量(196 个 Patch + 1 个 Class Token),每个向量都包含全局依赖信息;
- Class Token 的初始值是随机可学习参数,经过 12 层 Encoder 后,会 "吸收" 所有 Patch 的全局特征,最终专门用于分类。
Class Token的作用:
- 替代 "全局平均池化":如果直接对 196 个 Patch 向量做平均池化,会丢失 Patch 的位置权重(比如关键 Patch 和无关 Patch 的权重相同);
- Class Token 通过自注意力机制动态聚合全局特征,能自适应关注重要 Patch(比如分类猫时,更关注 "头""身体" 等关键 Patch)。
python# 在ViT初始化时定义Class Token self.cls_token = nn.Parameter(torch.randn(1, 1, d_model)) # (1, 1, 768) → 可学习参数 def forward(self, x): B = x.shape[0] # 生成Batch维度的Class Token:(B, 1, 768) cls_tokens = self.cls_token.expand(B, -1, -1) # 拼接Class Token和Patch序列:(B, 196+1, 768) = (B, 197, 768) x = torch.cat([cls_tokens, x], dim=1) return x4.叠加位置编码 → (B, 197, 768)
- Transformer 的自注意力机制是 "无序的"(Patch 序列打乱后,注意力计算结果不变),但图像的 Patch 有明确空间位置(比如 "左上角 Patch" 和 "右下角 Patch" 的语义不同);
- 位置编码是一个与序列长度(197)和模型维度(768)相同的向量,叠加到 Patch 序列 + Class Token 上,告诉模型每个 Patch 的空间位置。
采用「可学习位置编码」:
- 原因:图像的空间位置关系比文本的时序关系更复杂,可学习编码能更好地适配图像任务;
- 形状:(1, 197, 768) → 与输入序列维度一致,通过加法叠加(
x = x + pos_embed)。
python# 在ViT初始化时定义位置编码 self.pos_embed = nn.Parameter(torch.randn(1, self.num_patches + 1, d_model)) # (1, 197, 768) def forward(self, x): # x: (B, 197, 768) → 拼接Class Token后的序列 x = x + self.pos_embed # 叠加位置编码(广播到Batch维度) return x5.12层Transformer Encoder → (B, 197, 768)
ViT 的 Encoder 与原始 Transformer 的 Encoder 完全一致,采取Pre-Norm结构,每层由多头自注意力(MHA)和「前馈神经网络(FFN)」组成,搭配残差连接。
关键参数(ViT-B/16)
层数:12 层;
多头注意力头数:12 头(d_model=768 → 每个头的维度 = 768/12=64);
FFN 中间层维度:3072(d_model 的 4 倍);
激活函数:GELU(比 ReLU 更平滑,适合 Transformer)。
pythonclass TransformerEncoderLayer(nn.Module): def __init__(self, d_model=768, nhead=12, dim_feedforward=3072, dropout=0.1): super().__init__() # 多头自注意力 self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True) # 前馈神经网络 self.ffn = nn.Sequential( nn.Linear(d_model, dim_feedforward), nn.GELU(), nn.Dropout(dropout), nn.Linear(dim_feedforward, d_model) ) # 层归一化 self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) # Dropout self.dropout1 = nn.Dropout(dropout) self.dropout2 = nn.Dropout(dropout) def forward(self, x): # 多头自注意力 + 残差连接 x_norm = self.norm1(x) # Pre-Norm:先归一化 attn_output, _ = self.self_attn(x_norm, x_norm, x_norm) # 自注意力 x = x + self.dropout1(attn_output) # 残差连接 # 前馈神经网络 + 残差连接 x_norm2 = self.norm2(x) ffn_output = self.ffn(x_norm2) x = x + self.dropout2(ffn_output) return x # 构建12层Encoder self.encoder = nn.Sequential(*[TransformerEncoderLayer() for _ in range(12)])6. 分类头:简单高效的输出层
ViT 的分类头设计非常简洁(区别于 CNN 的复杂全连接层 + 池化):
- 直接提取 Encoder 输出的 Class Token 向量(B, 768);
- 经过一层 Dropout(防止过拟合)和线性层(768→类别数),输出类别概率。
pythonself.head = nn.Sequential( nn.Dropout(0.1), nn.Linear(d_model, num_classes) ) def forward(self, x): # x: (B, 197, 768) → Encoder输出 cls_token_output = x[:, 0, :] # 提取Class Token:(B, 768) output = self.head(cls_token_output) # (B, num_classes) return output
代码实现:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, d_model=768, in_chans=3):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(in_chans, d_model, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # (B, 768, 14, 14)
x = x.permute(0, 2, 3, 1) # (B, 14, 14, 768)
x = x.reshape(x.shape[0], -1, x.shape[-1]) # (B, 196, 768)
return x
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model=768, nhead=12, dim_feedforward=3072, dropout=0.1):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True)
self.ffn = nn.Sequential(
nn.Linear(d_model, dim_feedforward),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(dim_feedforward, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x):
# 多头自注意力
x_norm = self.norm1(x)
attn_out, _ = self.self_attn(x_norm, x_norm, x_norm)
x = x + self.dropout1(attn_out)
# 前馈神经网络
x_norm2 = self.norm2(x)
ffn_out = self.ffn(x_norm2)
x = x + self.dropout2(ffn_out)
return x
class ViT(nn.Module):
def __init__(self, img_size=224, patch_size=16, d_model=768, nhead=12,
num_layers=12, dim_feedforward=3072, num_classes=1000, dropout=0.1):
super().__init__()
# 1. Patch Embedding
self.patch_embed = PatchEmbedding(img_size, patch_size, d_model)
# 2. Class Token
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))
# 3. 位置编码
self.pos_embed = nn.Parameter(torch.randn(1, self.patch_embed.num_patches + 1, d_model))
# 4. Transformer Encoder
self.encoder = nn.Sequential(*[
TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout)
for _ in range(num_layers)
])
# 5. 分类头
self.head = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(d_model, num_classes)
)
# 初始化权重
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.trunc_normal_(m.weight, std=0.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def forward(self, x):
# x: (B, 3, 224, 224)
B = x.shape[0]
# 1. Patch Embedding
x = self.patch_embed(x) # (B, 196, 768)
# 2. 拼接Class Token
cls_tokens = self.cls_token.expand(B, -1, -1) # (B, 1, 768)
x = torch.cat([cls_tokens, x], dim=1) # (B, 197, 768)
# 3. 叠加位置编码
x = x + self.pos_embed # (B, 197, 768)
# 4. Transformer Encoder
x = self.encoder(x) # (B, 197, 768)
# 5. 分类
cls_out = x[:, 0, :] # (B, 768)
output = self.head(cls_out) # (B, 1000)
return output
# 测试模型
if __name__ == "__main__":
model = ViT()
x = torch.randn(2, 3, 224, 224) # 批次大小2,输入图像224×224×3
output = model(x)
print(f"输入形状: {x.shape}")
print(f"输出形状: {output.shape}") # 输出形状: (2, 1000)3.VIT的训练策略
ViT 的核心缺点是「弱归纳偏置」(没有 CNN 的局部性、平移不变性假设),导致其在小数据集上表现不如 CNN,必须依赖「大规模预训练 + 微调」才能发挥优势:
1. 预训练阶段(关键前提)
- 数据要求:需要超大规模图像数据集(如 ImageNet-21K,含 21k 类别、1400 万图像;或 JFT-300M,含 3 亿图像);
- 目标任务:图像分类(监督学习);
- 核心目的:让模型通过海量数据 "学习图像的局部特征和空间关系",弥补弱归纳偏置的缺陷(比如通过数据学会 "边缘、纹理等局部特征的组合方式")。
2. 微调阶段(适配下游任务)
- 数据要求:下游任务数据集(如 ImageNet-1K,1000 类别、120 万图像);
- 操作 :
- 冻结预训练的 Transformer Encoder 部分权重(或用小学习率微调);
- 替换 / 训练新的分类头(适配下游任务的类别数);
- 优势:微调成本低,且能快速适配分类、检测、分割等多种下游任务(只需修改输出头)。
3. 改进策略(解决小数据问题)
- 蒸馏训练(DeiT):用 CNN(如 ResNet)的输出作为 "软标签",指导 ViT 训练,让 ViT 在小数据集上也能快速收敛(DeiT 是 ViT 的主流改进版,无需大规模预训练);
- 混合模型(如 ViT+CNN 前端):用 CNN 提取局部特征,再喂给 Transformer,结合 CNN 的归纳偏置和 ViT 的全局建模能力(适合中小数据集)。
4.ViT 的变体与改进方向
原始 ViT 存在「计算量高(O (n²))、局部特征弱、多尺度建模差」等问题,后续变体主要围绕这些痛点改进,以下是最具代表性的方案:
1. Swin Transformer
(当前 CV 最主流)
- 核心改进:滑动窗口自注意力 + 金字塔结构;
- 解决问题:原始 ViT 的全局自注意力计算量高,且无法建模多尺度特征;
- 关键创新 :
- 滑动窗口自注意力:将特征图分成固定窗口(如 7×7),仅在窗口内计算注意力(O (n²)→O ((n/w)×w²),w 为窗口大小),大幅降低计算量;
- 金字塔结构:借鉴 CNN 的多尺度特征(如 Stage1→4,特征图尺寸逐步缩小),适配目标检测、分割等需要多尺度的任务。
2. PVT
(Pyramid Vision Transformer)
- 核心改进:金字塔结构 + 动态感受野;
- 解决问题:原始 ViT 是单尺度模型,无法处理多尺度目标;
- 关键创新:不同 Stage 的 Patch 大小逐步增大(如 Stage1:4×4,Stage2:8×8),特征图尺寸逐步缩小,同时自注意力的头数逐步增加,兼顾局部细节和全局关联。
3. ConvNeXt
(CNN 的 "Transformer 化" 改进)
- 核心改进:CNN 架构借鉴 Transformer 的设计(如深度卷积、大核卷积、LayerNorm);
- 本质:不是 ViT 变体,而是 "CNN 向 Transformer 靠拢",但性能接近 ViT,且保留 CNN 的计算效率和归纳偏置;
- 启示:ViT 和 CNN 的边界正在融合,混合模型是未来趋势。
5.训练技巧
| 模型规格 | 层数 | 头数 | d_model | Patch 大小 | 适用场景 |
|---|---|---|---|---|---|
| ViT-B/16 | 12 | 12 | 768 | 16×16 | 通用分类、检测(平衡性能与计算量) |
| ViT-L/16 | 24 | 16 | 1024 | 16×16 | 高精度场景(如医学影像分类) |
| ViT-S/8 | 8 | 8 | 384 | 8×8 | 小图像、需要细粒度特征的场景 |
实用技巧:
- 预训练权重 :优先使用 ImageNet 预训练权重(如 Hugging Face 的
vit-base-patch16-224),避免从头训练; - 学习率:Class Token 和位置编码的学习率设为 Transformer 的 10 倍(这两个模块需要快速适配下游任务);
- 数据增强:使用 MixUp、CutMix、RandAugment 等强增强(弥补弱归纳偏置,提升泛化能力);
- 优化器:用 AdamW 优化器(权重衰减 = 0.1),学习率调度用 CosineAnnealingLR
适用场景与不适用场景:
- 适用:图像分类、医学影像分析、细粒度识别(需要全局关联);
- 不适用:低算力设备(如移动端)、小尺寸图像分类(纯 CNN 更高效)、实时性要求高的场景(如视频流检测)
ViT 的核心价值:
不是 "替代 CNN",而是「提供了一种全新的图像建模范式 ------ 用全局自注意力替代局部卷积」,其本质是「将图像的空间关系转化为序列的全局依赖关系」。
4.Transformer和vit的区别和联系
1.两者的特性
1. Transformer(基础架构)
| 维度 | 核心内容 |
|---|---|
| 核心定位 | 通用序列建模架构(不局限于 NLP / 图像,可适配各类序列数据) |
| 核心结构 | 「Encoder + Decoder」双模块设计(可灵活拆分使用) |
| 关键组件 | 自注意力机制(Self-Attention)、交叉注意力机制(Cross-Attention)、位置编码(Positional Encoding)、前馈神经网络(FFN) |
| 核心能力 | 捕捉序列中全局关联(如文本中前后词、图像中不同区域的关系) |
| 适用场景 | - 生成式任务:QA、机器翻译、文本摘要(用 Encoder+Decoder)- 编码式任务:文本分类、情感分析(仅用 Encoder)- 自回归生成:文本创作(仅用 Decoder) |
| 核心逻辑 | 先将数据转为「序列 + 位置编码」,再通过注意力机制建模关联,输出目标结果 |
ViT(Vision Transformer)
| 维度 | 核心内容 |
|---|---|
| 核心定位 | Transformer 在图像领域的适配模型(专门解决图像分类等视觉任务) |
| 核心结构 | 仅使用「Transformer Encoder」(无 Decoder,因视觉分类是判别式任务) |
| 关键组件 | 图像切块(Patch Embedding)、CLS Token(分类标记)、位置编码、Encoder 层 |
| 核心能力 | 将图像转为「Patch 序列」,用 Transformer 捕捉 Patch 间的全局空间关联(替代 CNN 的全局特征提取) |
| 适用场景 | 图像分类(核心场景)、目标检测、图像分割(延伸场景,需修改结构) |
| 核心逻辑 | 图像→切块转序列→加 CLS Token + 位置编码→Encoder 编码全局特征→CLS Token 输出分类结果 |
2.共性与差异
两者本质是「基础架构→领域适配」的关系,共享核心设计思想:
- 依赖 Transformer 核心组件:均以「自注意力机制」为核心,通过 FFN 增强特征表达,且都需要「位置编码」(因 Transformer 本身无顺序感知能力);
- 基于序列建模逻辑:无论输入是文本(天然序列)还是图像(人工转为 Patch 序列),最终都以「序列」形式输入模型处理;
- 擅长全局关联捕捉:都能高效捕捉输入中远距离的关联(Transformer 捕捉文本全局语义,ViT 捕捉图像全局空间关系),弥补了 CNN/RNN 的局部建模缺陷;
- Encoder 模块复用:ViT 直接复用了 Transformer 的 Encoder 结构,仅对「输入处理部分」做了视觉适配(图像→Patch 序列)。
| 维度 | Transformer(QA 任务) | ViT(图像分类) |
|---|---|---|
| 原始数据 | 非结构化文本(字符串) | 非结构化图像(像素矩阵,如 224×224×3) |
| 预处理核心 | 「分词→词嵌入」:将文本拆分为最小语义单位(词 / 子词),转为向量 | 「切块→Patch Embedding」:将图像拆分为固定大小的 Patch,转为向量 |
| 序列来源 | 文本天然是序列(如 "人工智能是什么?"→词的顺序固定) | 图像是二维空间数据,需人工转为一维序列(Patch 按空间位置排序) |
| 特殊标记 | 生成式任务需<sos>(启动生成)、<eos>(结束生成) |
必须添加 CLS Token(专门承载分类信息,无生成标记) |
2. 输出差异(本质是任务目标不同)
| 维度 | Transformer(QA 任务) | ViT(图像分类) |
|---|---|---|
| 输出类型 | 「生成候选」的概率分布(词库) | 「分类选项」的概率分布(标签集) |
| 输出逻辑 | 自回归逐词生成(前一步输出作为后一步输入) | 一次性输出所有标签的概率(无自回归,直接分类) |
| 结果形式 | 连续的文本序列(如 "人工智能(AI)是计算机科学的分支") | 单个分类标签(如 "猫""狗""汽车") |
| 依赖组件 | 必须依赖 Decoder(生成序列)或 Encoder + 全连接层(编码分类) | 依赖 Encoder+CLS Token + 全连接层(CLS Token 是输出核心) |
- Transformer 是「通用序列建模工具」,输入是任意领域的序列(文本 / 图像 Patch 等),输出根据任务灵活调整(词库分布 / 特征向量);
- ViT 是「Transformer 的视觉专用版」,输入是图像(转为 Patch 序列),输出是分类标签概率分布,核心是用 Transformer 替代 CNN 做图像全局特征提取。
5.推理框架
背景:
之前上述将的VIT/Transformer都是【训练阶段】在 GPU 上用大量数据调整模型参数,追求「精度达标」,接下来讲述的是测试集也就是【推理部署阶段】
本质核心:
把训练好的模型(.pt 文件)放到实际场景中(如 APP、服务器、工控机)做预测,追求「速度快、开销小、兼容性强」。
⭐
训练是「造模型」,推理是「用模型」
1.batch 推理
Batch 推理的本质:凑一批样本一起喂给模型做预测,按批次来做预测。单位时间内处理的样本数更多,平均每个样本的推理时间更短。
避坑:
- 样本必须同构,尺寸格式要相同。
- 不能盲目增大 Batch Size(如果cpu内存8G,选择Batch=8/16;GPU显存16G,选Batch=32/64)不能超过64。
- 推理时的 Batch Size ≠ 训练时的 Batch Size,训练时 Batch 大是为了稳定梯度,推理时 Batch 大是为了高效利用硬件,两者无必然关联。
2. 多线程 推理
**CPU 推理的核心优化:**推理流程中的「数据预处理、模型计算、后处理」等环节。
1.单线程推理:「加载图片 1→预处理 1→推理 1→后处理 1→加载图片 2→预处理 2→推理 2→后处理 2......」,前面的步骤没做完,后面的只能等。
2.多线程推理:「线程 1 加载图片 1 + 预处理 1,线程 2 加载图片 2 + 预处理 2,线程 3 负责模型推理(接收线程 1/2 的预处理结果),线程 4 负责后处理」,各环节并行推进,不用互相等。
⭐主要针对CPU推理场景,充分利用CPU的多核资源,提升吞吐量。一般线程数 = CPU 核心数 ×1~2。
3.ONNX 中间件
ONNX本质:训练框架与推理框架的「鸿沟」,训练得到的.pt/.pth文件推理不能直接用,需要一个「模型界的通用翻译官」ONNX。
背景:
- 移动端 APP:需要用 TFLite 推理;
- 服务器端:需要用 TensorRT(GPU 高性能推理)或 OpenVINO(Intel CPU 推理);
- 工控机:需要用 ONNX Runtime 推理。
PyTorch 的.pt 模型,不能直接被 TFLite、TensorRT、OpenVINO 识别!
解决方案:ONNX(Open Neural Network Exchange)就登场了 ------ 它是一个「中立的、标准的模型中间格式」,定义了统一的算子集。
- 中间桥梁:解决「训练框架(PyTorch/TensorFlow)」与「推理框架(ORT/TensorRT/TFLite)」之间的格式不兼容问题。
- **标准算子集:**ONNX 定义了一套通用的神经网络算子(如卷积、池化、多头注意力、GELU 等),训练框架转换为 ONNX 时,会把自身的算子映射为 ONNX 标准算子,避免推理时的算子缺失。
- 与框架、设备无关:一旦模型转为 ONNX 格式,就可以在任意支持 ONNX 的设备 / 框架上运行,无需重新训练。
「PyTorch (.pt) → ONNX (.onnx)」算子转换的核心逻辑:
- 加载 PyTorch 的训练好的模型(必须是「eval 模式」,关闭 Dropout、BatchNorm 的训练特性);
- 构造一个「虚拟输入」(形状与模型输入一致,如
(1, 3, 224, 224));- PyTorch 通过「追踪法」或「脚本法」,遍历模型的计算图,把每个 PyTorch 算子转换为对应的 ONNX 标准算子;
- 保存生成的 ONNX 模型文件(.onnx),包含「模型结构 + 权重参数 + 输入输出信息」。
避坑:
- 模型必须设为
eval()模式:否则 Dropout、BatchNorm 层的行为与训练时一致,推理结果不稳定,且转换时可能出现算子错误。- 避免动态形状输入:转换时尽量用固定形状的虚拟输入(如固定 Batch=1、固定图像尺寸 224×224),动态形状(如任意 Batch、任意尺寸)转换容易失败。
- 算子兼容问题:如果 PyTorch 模型用了自定义算子(如自己写的
my_gelu),ONNX 没有对应的标准算子,转换会失败,需要手动实现 ONNX 算子或替换为 ONNX 支持的算子。
4. ORT(ONNX Runtime)
运行 ONNX 模型的「高效引擎」
ONNX 只是「模型格式文件」,就像一个「mp4 视频文件」,你需要一个「播放器」才能播放它 ------ORT(ONNX Runtime)就是专门运行 ONNX 模型的「高性能推理引擎」
⭐选择使用ORT的原因?
- 更快:ORT 对 ONNX 模型做了大量优化(算子融合、内存优化、多线程并行、GPU 加速等),相同模型,ORT 推理速度比 PyTorch 快 2~10 倍(尤其是 CPU 推理)。
- 更通用:ORT 支持所有 ONNX 标准模型,无需关心原始训练框架(PyTorch/TensorFlow)。
- 更轻量化:ORT 的部署包体积小,适合嵌入式、移动端等资源受限场景,而 PyTorch 的完整包体积大,不适合部署。
- 支持多种优化策略:一键开启 Batch 推理、多线程推理、GPU 加速,无需手动修改模型。
- ONNX 是「模型文件」(.onnx),ORT 是「运行这个文件的引擎」;
- 就像「Word 文档(.docx)」和「Microsoft Word 软件」的关系,文档需要软件才能打开和编辑,ONNX 模型需要 ORT 才能加载和推理。
github案例:
本章节笔者主要阐述了Transformer + VIT的相关知识点,从Transformer的初始原理和训练过程到七基础构造和用途,以及transformer在视觉上的使用vit,其训练原理和策略,最后对比了两者的特征和差异,并在最后阐述了常见的推理框架。