PyTorch深度学习实战(44)------基于 DETR 实现目标检测
-
- [0. 前言](#0. 前言)
- [1. Transformer](#1. Transformer)
-
- [1.1 Transformer 基础](#1.1 Transformer 基础)
- [1.2 Transformer 架构](#1.2 Transformer 架构)
- [2. DETR](#2. DETR)
-
- [2.1 DETR 架构](#2.1 DETR 架构)
- [2.2 实现 DETR 模型](#2.2 实现 DETR 模型)
- [3. 基于 DETR 实现目标检测](#3. 基于 DETR 实现目标检测)
-
- [3.1 数据加载与模型构建](#3.1 数据加载与模型构建)
- [3.2 模型训练与测试](#3.2 模型训练与测试)
- 小结
- 系列链接
0. 前言
在使用 R-CNN/YOLO 执行目标检测时,利用区域提议/锚框完成目标分类和检测,这些方法通常需要多个步骤流程才能完成目标检测任务。 DETR (Detection Transformer) 是一种基于 Transformer 技术的端到端的管道,可极大的简化目标检测网络架构。Transformer 是在 NLP 中较为流行的技术之一,可以用于执行多种任务和最新的技术之一。在本节中,我们将学习 transformer 和 DETR 的原理,并使用 PyTorch 实现 DETR 以执行目标检测任务。
1. Transformer
1.1 Transformer 基础
Transformer 是用于解决序列到序列问题的高性能架构,当前几乎所有自然语言处理 (Natural Language Processing, NLP) 任务都是基于 Transformer 实现的。这类网络仅使用全连接层和 softmax 创建自注意力机制,自注意力有助于识别输入文本中单词之间的相互依赖关系。输入序列通常不超过 2048 个项,这对于文本应用而言已经足够大了。但是,如果将图像与 Transformer 一起使用,则必须将它们展平,这会创建包含数百万像素的序列(例如 300 x 300 x 3 图像包含 270000 个像素),这并不可行。 为了解决这一限制,可以将尺寸远小于输入图像的特征图作为 Transformer 的输入。
1.2 Transformer 架构
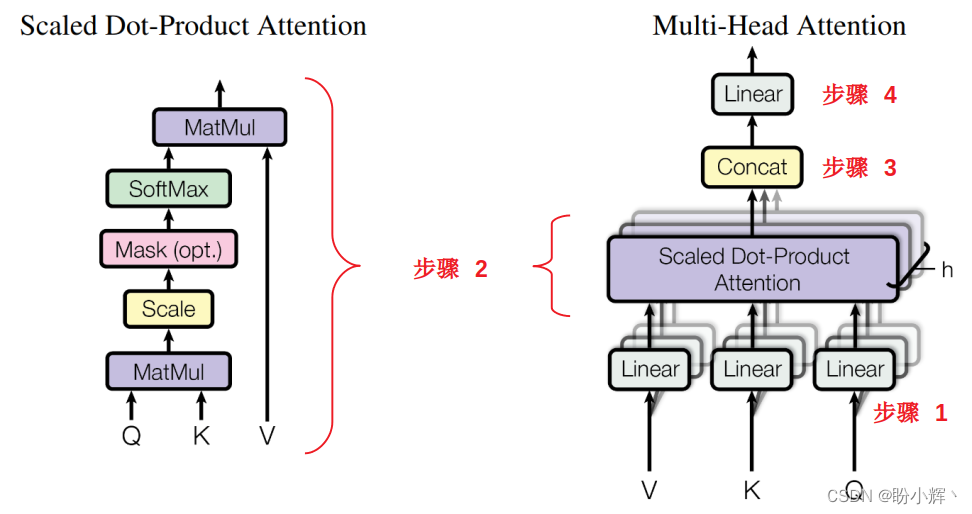
Transformer 的核心是自注意力模块,它以三个二维矩阵(称为查询 (query, Q)、键 (key, K) 和值 (value, V) 矩阵)作为输入,这些矩阵可以具有较大的嵌入大小,矩阵尺寸为 text size x embedding size,其中 text size 表示文本大小,embedding size 表示嵌入大小,因此首先将它们分成较小的部分(多头自注意力图中的步骤 1),然后缩放点积注意力(多头自注意力图中的步骤 2)进行处理。
接下来,通过以下示例了解自注意力的工作原理。假设,序列长度为 3,将三个词嵌入( W 1 W_1 W1、 W 2 W_2 W2 和 W 3 W_3 W3 )作为输入,假设每个嵌入的大小为 512。每个嵌入都被转换为三个附加向量,即与每个输入相对应的查询 (query)、键 (key) 和值 (value) 向量:
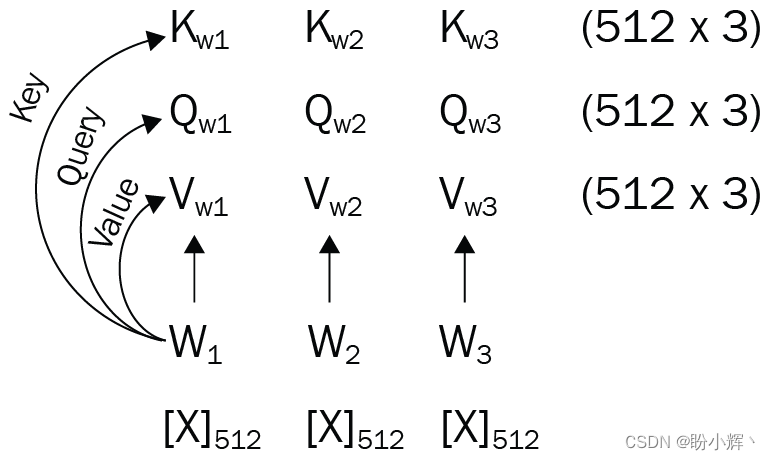
由于每个向量的大小为 512,因此执行矩阵乘法的计算成本很高。因此,我们将每个向量分成八个部分,每个键、查询和值张量都具有八组 (64 x 3) 向量,其中 64 表示 512 (嵌入大小)/8 (多头注意力数),而 3 表示序列长度:
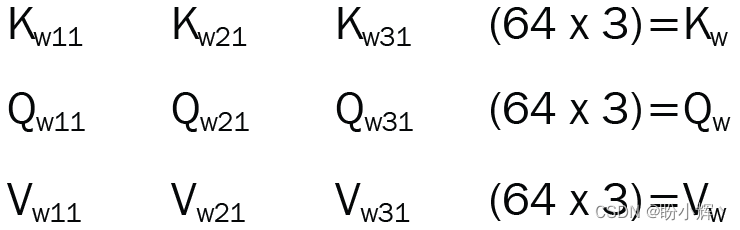
在每个部分中,首先对键和查询矩阵执行矩阵乘法,得到一个 3 x 3 矩阵,然后执行 softmax 激活函数,得到的矩阵用于表示每个单词相对于其他单词的重要性:

最后,对以上张量输出与值张量执行矩阵乘法,得到自注意力操作输出:
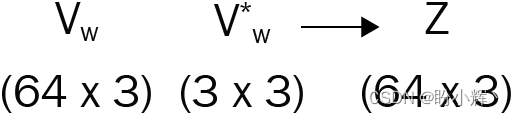
然后组合在上一步中得到的八个输出,使用 concat 层返回(多头自注意图中的步骤 3),最终得到一个大小为 512 x 3 的张量。由于对 Q、K 和 V 矩阵进行了拆分,因此该层也称为多头自注意力:
此架构核心思想如下:
- 值 ( V s V_s Vs) 是需要在键和查询矩阵的上下文中为给定输入进行学习处理的嵌入
- 查询 ( Q s Q_s Qs) 和键 ( K s K_s Ks) 的组合会创建正确的掩码,以便只有值矩阵的重要部分被输入到下一层
在计算机视觉中,当搜索诸如马之类的对象时,查询应包含用于搜索尺寸较大且通常为棕色、黑色或白色的对象信息。缩放点积注意力的 softmax 输出反映键矩阵中图像中包含图像颜色(棕色、黑色、白色等)的部分。因此,自注意力层输出的值将具有大致符合所需颜色且在值矩阵中的图像部分。
在网络中多次使用自注意力模块,如下图所示。Transformer 网络包含一个编码网络(下图左侧部分),其输入是源序列。编码部分的输出用于解码部分的键和查询输入,而值输入则会独立于编码部分由神经网络进行学习:

尽管是一个输入序列,但全连接层没有位置指示,无法确定哪个分词(单词)是第一个,哪个是下一个。位置编码是可学习的嵌入(或硬编码向量),将其添加到每个输入中,将其作为序列中每个输入的位置函数,以便让网络了解哪个单词嵌入在序列中是第一个,哪个是第二个。
在 PyTorch 中可以使用内置方法 nn.Transformer 很方便的创建 Transformer 网络:
python
from torch import nn
transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)其中,hidden_dim 是嵌入大小,nheads 是多头自注意力中的头数,num_encoder_layers 和 num_decoder_layers 分别是网络中编码和解码块的数量。
2. DETR
2.1 DETR 架构
普通 Transformer 网络和 DETR 之间有少数几个关键区别。首先,DETR 输入是图像,而不是序列,DETR 将图像通过 ResNet 主干网络传递,获得大小为 256 的特征向量,然后可以将其视为一个序列。在目标检测任务中,解码器的输入是对象查询嵌入 (object-query embeddings),它们是在训练期间自动学习的,作为解码器层的查询矩阵。类似的,对于每一层,键矩阵和查询矩阵都将为编码器块的最终输出矩阵。Transformer 的最终输出张量形状为 Batch_Size x 100 x Embedding_Size,其中模型训练时的序列长度为 100;也就是说,它学习了 100 个对象查询嵌入,并为每张图像返回 100 个向量,以指示是否存在对象。将大小为 100 x Embedding_Size 的矩阵分别馈送到对象分类模块和对象回归模块,用于独立预测图像中是否存在对象(以及对象类别)以及边界框坐标,两个模块均为简单的 nn.Linear 层。
DETR 的整体架构如下:

2.2 实现 DETR 模型
接下来,使用 PyTorch 实现一个较小规模的 DETR 变体版本。
创建 DETR 模型类:
python
from collections import OrderedDict
class DETR(nn.Module):
def __init__(self,num_classes,hidden_dim=256,nheads=8, num_encoder_layers=6, num_decoder_layers=6):
super().__init__()
self.backbone = resnet50()提取 ResNet 中的指定网络层,并丢弃其余部分,选取的网络层名称以列表形式给出:
python
layers = OrderedDict()
for name,module in self.backbone.named_modules():
if name in ['conv1','bn1','relu','maxpool', 'layer1','layer2','layer3','layer4']:
layers[name] = module
self.backbone = nn.Sequential(layers)
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)在以上代码中,定义了以下内容:
- 按顺序排列的感兴趣的网络层 (
self.backbone) - 卷积操作 (
self.conv) Transformer模块 (self.transformer)- 用于预测目标类别的全连接层 (
self.linear_class) - 用于预测边界框的全连接层 (
self.linear_box)
定义编码器和解码器层的位置嵌入:
python
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))self.query_pos 是解码器层的位置嵌入输入,而 self.row_embed 和 self.col_embed 则形成编码器层的二维位置嵌入。
定义前向计算方法 forward:
python
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos+0.1*h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1)).transpose(0, 1)
return {'pred_logits': self.linear_class(h), 'pred_boxes': self.linear_bbox(h).sigmoid()}加载在 COCO 数据集上训练的预训练模型,并将其用于预测通用类别,也可以在此模型上使用相同的函数进行预测:
python
detr = DETR(num_classes=91)
state_dict = torch.hub.load_state_dict_from_url(url='detr_demo-da2a99e9.pth',map_location='cpu', check_hash=True)
detr.load_state_dict(state_dict)
detr.eval()与 R-CNN 或 YOLO 等模型相比,DETR 可以一次性获取预测,DETR 详细架构如下:

使用主干网络获取图像特征,然后通过编码器将图像特征与位置嵌入连接起来。
在 __init__ 方法中位置嵌入 self.row_embed 和 self.col_embed 用于对图像中各种对象的位置信息进行编码。编码器将位置嵌入和图像特征连接起来作为输入,在 forward 方法中获得隐藏状态向量 h,然后将其作为解码器的输入。Transformer 的输出进一步传递到两个全连接网络中,一个用于目标对象识别,一个用于边界框回归。
模型训练过程使用 Hungarian 损失,它负责将对象识别为一个集合并惩罚冗余预测,这完全消除了对非最大抑制的需求。
解码器采用编码器隐藏状态向量和对象查询的组合。对象查询的工作方式与位置嵌入/锚框类似,可以生成五个预测结果,其中一个用于预测对象类别,另外四个用于预测对象边界框。
3. 基于 DETR 实现目标检测
在本节中,我们将使用 PyTorch 实现 DETR 网络执行目标检测,识别公共汽车与卡车并在图中绘制边界框,所用数据集与R-CNN一节中相同。
3.1 数据加载与模型构建
首先,在 Github 下载 DETR 项目 detr,并下载权重文件 detr-r50-e632da11.pth。
然后,下载并解压数据集后,按照 DETR 所需 COCO 数据集格式调整文件结构:
shell
$ cp open-images-bus-trucks/annotations/mini_open_images_train_coco_format.json open-images-bus-trucks/annotations/instances_train2017.json
$ cp open-images-bus-trucks/annotations/mini_open_images_val_coco_format.json open-images-bus-trucks/annotations/instances_val2017.json
$ ln -s open-images-bus-trucks/images/ open-images-bus-trucks/train2017
$ ln -s open-images-bus-trucks/images/ open-images-bus-trucks/val20173.2 模型训练与测试
(1) 使用下载完成的 DETR 模型与 open-images-bus-trucks 文件夹中的图像和标注信息训练模型:
shell
$ cd detr
$ python main.py --coco_path open-images-bus-trucks --epochs 15 --lr=1e-4 --batch_size=2 --num_workers=4 --output_dir="outputs" --resume="detr-r50-e632da11.pth"(2) 训练模型并保存后,在测试阶段可以直接从文件夹中加载模型:
python
import os
import torch
from matplotlib import pyplot as plt
from torch import nn, optim
from torch import functional as F
from torchvision import transforms as T
import random
from glob import glob
import shutil
from main import get_args_parser, argparse, build_model
CLASSES = ['', 'BUS','TRUCK']
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args, _ = parser.parse_known_args()
model, _, _ = build_model(args)
model.load_state_dict(torch.load("outputs/checkpoint.pth")['model'])(2) 对预测结果进行后处理,获取图像和包围对象的边界框:
python
COLORS = [[0.000, 0.447, 0.741], [0.850, 0.325, 0.098], [0.929, 0.694, 0.125],
[0.494, 0.184, 0.556], [0.466, 0.674, 0.188], [0.301, 0.745, 0.933]]
transform = T.Compose([
T.Resize(800),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# for output bounding box post-processing
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
return b
def detect(im, model, transform):
img = transform(im).unsqueeze(0)
assert img.shape[-2] <= 1600 and img.shape[-1] <= 1600, 'demo model only supports images up to 1600 pixels on each side'
outputs = model(img)
# keep only predictions with 0.7+ confidence
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > 0.7
# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
return probas[keep], bboxes_scaled
def plot_results(pil_img, prob, boxes):
plt.figure(figsize=(16,10))
plt.imshow(pil_img)
ax = plt.gca()
for p, (xmin, ymin, xmax, ymax), c in zip(prob, boxes.tolist(), COLORS * 100):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color=c, linewidth=3))
cl = p.argmax()
text = f'{CLASSES[cl]}: {p[cl]:0.2f}'
ax.text(xmin, ymin, text, fontsize=15,
bbox=dict(facecolor='yellow', alpha=0.5))
plt.axis('off')
plt.show()(3) 预测测试图像:
python
for _ in range(20):
image = Image.open(random.choice(glob('../open-images-bus-trucks/images/*'))).resize((800,800)).convert('RGB')
scores, boxes = detect(image, model, transform)
plot_results(image, scores, boxes)
从上图可以看出,训练后模型能够预测图像中对象。虽然在此简单示例中检测的准确率可能不是非常高。但是,可以将此方法扩展到大型数据集来提高模型性能。
小结
基于 DETR (Detection Transformer) 的目标检测模型是将 Transformer 网络引入目标检测任务中,与传统的基于区域提议的检测方法有所不同。DETR 模型的核心思想是将目标检测问题转化为集合预测问题,通过将图像中的所有位置视为一个集合,并通过 Transformer 完成对整个集合的编码和解码过程,从而在单个前向传递中直接预测出目标的类别和边界框。
系列链接
PyTorch深度学习实战(1)------神经网络与模型训练过程详解
PyTorch深度学习实战(2)------PyTorch基础
PyTorch深度学习实战(3)------使用PyTorch构建神经网络
PyTorch深度学习实战(4)------常用激活函数和损失函数详解
PyTorch深度学习实战(5)------计算机视觉基础
PyTorch深度学习实战(6)------神经网络性能优化技术
PyTorch深度学习实战(7)------批大小对神经网络训练的影响
PyTorch深度学习实战(8)------批归一化
PyTorch深度学习实战(9)------学习率优化
PyTorch深度学习实战(10)------过拟合及其解决方法
PyTorch深度学习实战(11)------卷积神经网络
PyTorch深度学习实战(12)------数据增强
PyTorch深度学习实战(13)------可视化神经网络中间层输出
PyTorch深度学习实战(14)------类激活图
PyTorch深度学习实战(15)------迁移学习
PyTorch深度学习实战(16)------面部关键点检测
PyTorch深度学习实战(17)------多任务学习
PyTorch深度学习实战(18)------目标检测基础
PyTorch深度学习实战(19)------从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)------从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)------从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)------从零开始实现YOLO目标检测
PyTorch深度学习实战(23)------从零开始实现SSD目标检测
PyTorch深度学习实战(24)------使用U-Net架构进行图像分割
PyTorch深度学习实战(25)------从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(26)------多对象实例分割
PyTorch深度学习实战(27)------自编码器(Autoencoder)
PyTorch深度学习实战(28)------卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(29)------变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(30)------对抗攻击(Adversarial Attack)
PyTorch深度学习实战(31)------神经风格迁移
PyTorch深度学习实战(32)------Deepfakes
PyTorch深度学习实战(33)------生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(34)------DCGAN详解与实现
PyTorch深度学习实战(35)------条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(36)------Pix2Pix详解与实现
PyTorch深度学习实战(37)------CycleGAN详解与实现
PyTorch深度学习实战(38)------StyleGAN详解与实现
PyTorch深度学习实战(39)------小样本学习(Few-shot Learning)
PyTorch深度学习实战(40)------零样本学习(Zero-Shot Learning)
PyTorch深度学习实战(41)------循环神经网络与长短期记忆网络
PyTorch深度学习实战(42)------图像字幕生成
PyTorch深度学习实战(43)------手写文本识别