项目说明
1该项目主要分析通刷卡数据,通过大数据技术来研究地铁客运能力及探索优化服务的方向
2主要讲解Flink流处理实时分析部分,离线部分较简单,暂时略过
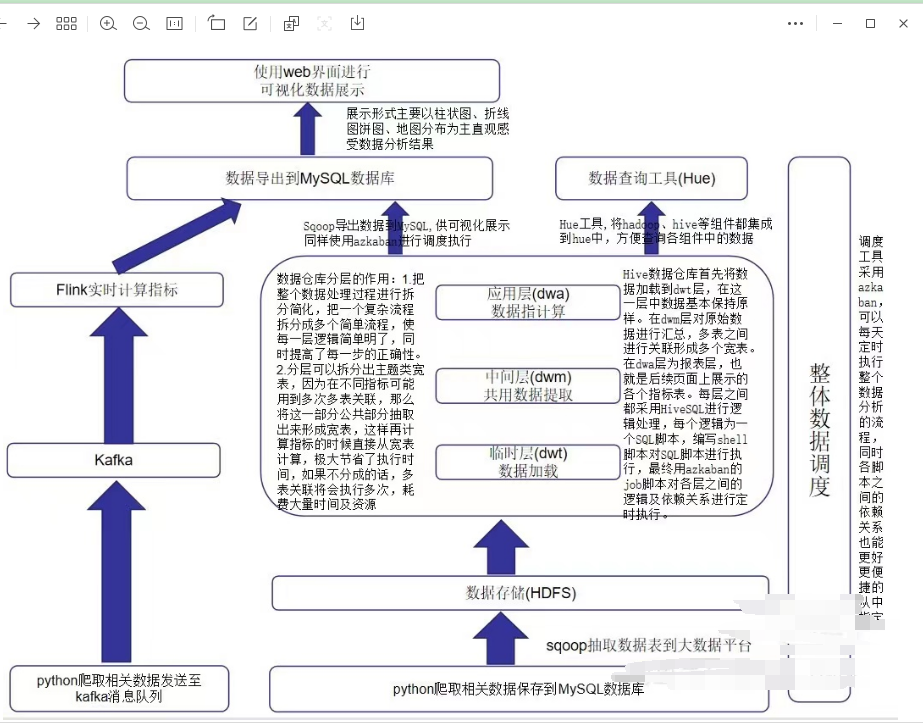
技术架构
项目流程:
采用python请求深圳地铁数据API,将数据发送至Kafka和MySQL。
kafka部分用于实时计算,MySQL部分模仿业务数据,用于离线分析
Flink连接Kafka进行实时统计各站收入情况
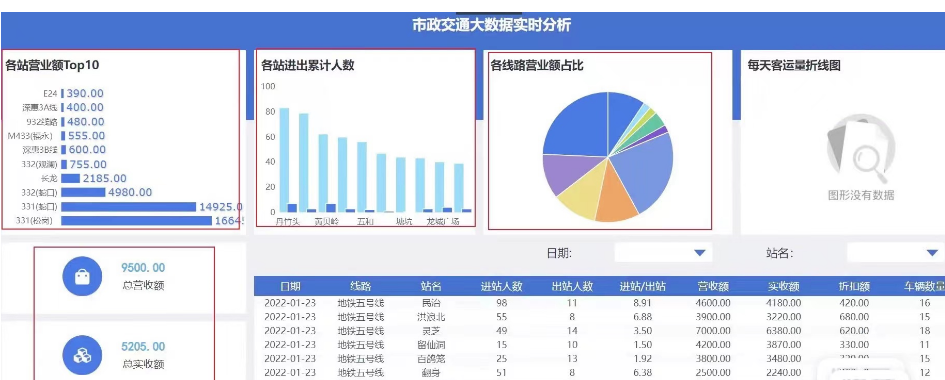
将统计的结果Sink到Mysql进行可视化展示
离线部分用sqoop将业务数据导入到hive中进行分析,最终将分析完的数据导出到MySQL用于可视化展示
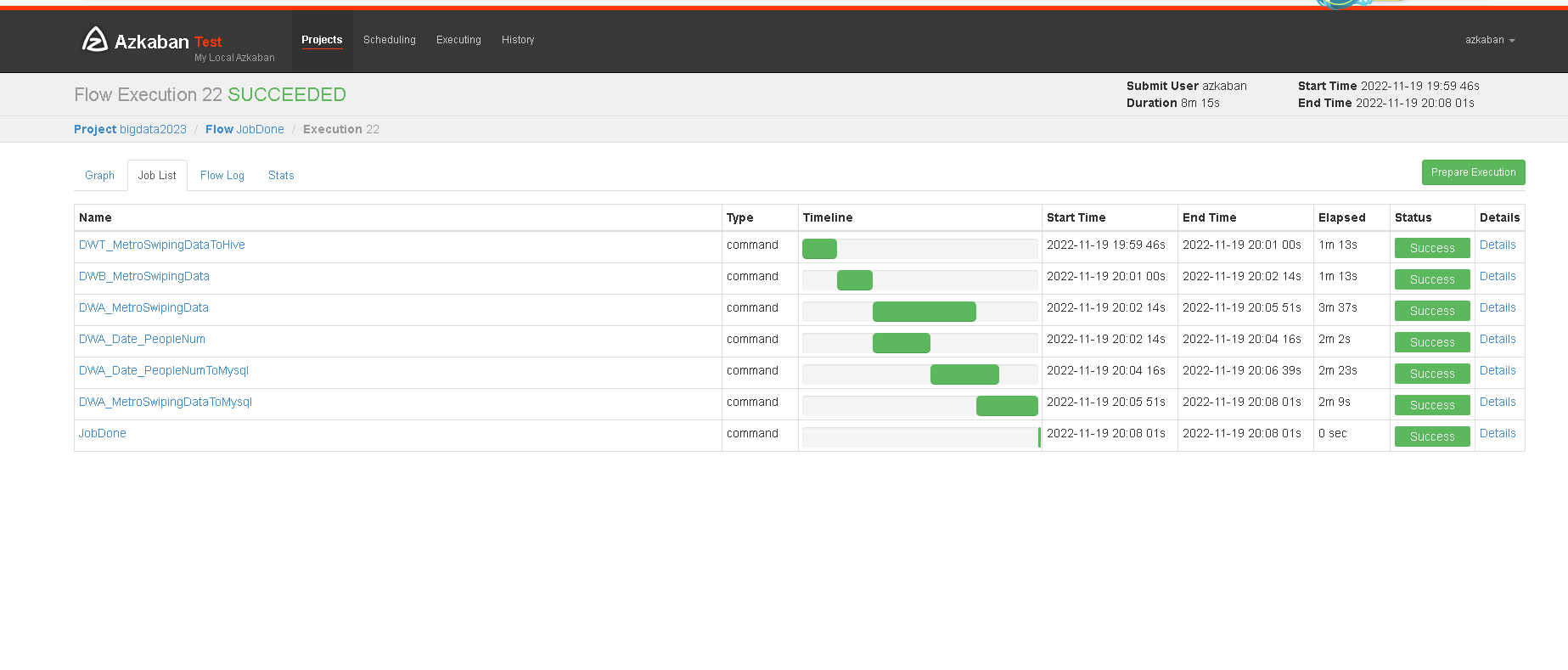
整体使用azkaban进行调度
组件版本:
python 3.6.6
java 1.8
scala 2.11
kafka_2.11-2.4.1
zookeeper_3.4.6
flink 1.14.0
hadoop 2.7.6
sqoop 1.4.6
hive 1.2.1
azkaban 2.5.0
mysql 5.7
FineReport 11
环境安装
注意:虚拟机环境中各组件已经安装完毕,此处不用实操,只是阐述组件安装的步骤。
随意实操导致项目环境不可用需另付费调试,更严重的话会导致数据丢失
虚拟机安装
在VMware里安装Centos7虚拟机是最最最最最最最最最最最最最基本的,不会的话看下方资料
这是整个项目的第一步,这都不会的话建议放弃任何项目。
题外话:最终答辩的话没有哪个老师也会傻到问虚拟机是怎么安装的,因为太简单了
Hadoop安装
## 配置ssh免密
ssh-keygen -t rsa
ssh-copy-id bigdata
## 解压
tar -zvxf hadoop-2.7.6.tar.gz -C /data/
cd /data
mv hadoop-2.7.6/ hadoop
cd /data/hadoop/etc/hadoop
## 配置环境变量
vim /etc/profile
#hadoop environment
export HADOOP_HOME=/data/hadoop
export PATH=PATH:{HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
## 拿到jdk地址
echo ${JAVA_HOME}
vim hadoop-env.sh
## 25行修改 JavaHome
vim core-site.xml
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
vim hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/data/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hadoop/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata:50070</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value> bigdata:10020</value>
</property>
<!-- 历史服务器web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> bigdata:19888</value>
</property>
<!--第三方框架使用yarn计算的日志聚集功能 -->
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata:19888/jobhistory/logs\</value>
</property>
vim yarn-site.xml
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
## 第一次启动前要格式化,后续如果二次格式化前一定要删除data目录和tmp目录
/data/hadoop/bin/hdfs namenode -format
## 启动
## 验证 jps 和新建目录上传文件等
hdfs dfs -mkdir -p /data/input
hdfs dfs -put ./hello.txt /data/input
Mysql安装
(1) 首先查看自己的集群中是否安装mysql数据库
rpm -qa | grep mysql // 这个命令就会查看该操作系统上是否已经安装了mysql数据库
(2)要是安装了 通过 yum -y remove mysql 进行卸载
卸载完之后一定要删除/etc/my.cnf,否则重装会失败
(3)依次安装6个rpm包 安装命令如下:
rpm -ivh mysql-community-common-5.7.19-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-libs-5.7.19-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-libs-compat-5.7.19-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-devel-5.7.19-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-client-5.7.19-1.el7.x86_64.rpm --nodeps --force
rpm -ivh mysql-community-server-5.7.19-1.el7.x86_64.rpm --nodeps --force
(4)启动mysql
systemctl start mysqld
(5) 设置开机自启动mysql
systemctl enable mysqld
(6) 安装成功后 首先将数据库设置成无密码状态
vi /etc/my.cnf
添加 skip-grant-tables 可保证为无密码状态
(7) 重启mysql服务器,保证生效 systemctl restart mysqld
(8)进入数据库 mysql -u root -p 按enter 键进入
(9) 选择数据库 use mysql;
(10) 修改密码为123456 修改命令
update user set authentication_string=password("123456") where user='root';
(11、12) 刷新:flush privileges; 退出 quit;
(13) 在此进入数据库 ,并建几个数据库
mysql -u root -p 密码123456
选择数据库 use mysql;
use mysql; 会报错, 说让你重新设置密码.执行下面这一步,设置密码:
set password = PASSWORD('123456');
上面若设置密码成功,则直接执行这三步:
#ALTER USER 'root'@' localhost' PASSWORD EXPIRE NEVER; ## 这个注释是防止下方字体变色
flush privileges;
quit;
上面若设置密码不成功,报错如下:
mysql> set password = PASSWORD('123456');
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
执行下面这几步:
这个其实与validate_password_policy的值有关。
执行下面命令 修改 即可
mysql> set global validate_password_policy =0;
Query OK, 0 rows affected (0.04 sec)
mysql> set global validate_password_length = 6;
Query OK, 0 rows affected (0.00 sec)
然后重新 执行命令
mysql>SET PASSWORD = PASSWORD('your new password');
Query OK, 0 rows affected (0.00 sec)
## 2.ALTER USER 'root'@' localhost' PASSWORD EXPIRE NEVER
3.flush privileges;
4.quit
(14 )重新登录 mysql -u root -p 123456
use mysql;
create database cmf default character set = 'utf8';
create database amon default character set = 'utf8';
create database hue default character set = 'utf8';
create database oozie default character set = 'utf8';
create database lyz default character set = 'utf8';
(15) 对mysql 数据库赋权,任何服务器都可以连接它,执行下面几步操作:
select host,user from user;
update user set host='%' where user = 'root';
flush privileges;
quit;
Sqoop安装
## 解压
tar -zvxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /data/
cd /data
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
## 配置环境变量
## sqoop配置
cd /data/sqoop/conf
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh ## 在末尾添加,或在中间挨个去找接触注释
export HADOOP_COMMON_HOME=/data/hadoop
export HADOOP_MAPRED_HOME=/data/hadoop
export HIVE_HOME=/data/hive
## 把mysql驱动包拷贝到lib下
cp /data/packages/mysql-connector-java-5.1.36.jar /data/sqoop/lib
## 测试
## 使用sqoop查看mysql中所有的数据库
sqoop list-databases --connect jdbc:mysql://bigdata:3306/testdata?characterEncoding=UTF-8 --username root --password 123456
## 把MySQL中的表导入hdfs中 一定要启动hdfs和yarn
sqoop import -m 1 --connect jdbc:mysql://bigdata:3306/testdata?characterEncoding=UTF-8 --username root --password 123456 --table user --target-dir /data/input/user
Hive安装
PowerShell
## 前提是安装了Mysql
## 解压
tar -zvxf apache-hive-1.2.1-bin.tar.gz -C /data/
mv /data/apache-hive-1.2.1-bin/ /data/hive
cd /data/hive
## 配置环境变量
## 修改配置
cd conf
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
<property>
<name>metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://bigdata:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/data/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive/iotmp</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/data/hive/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
## 把mysql驱动包拷贝到lib下
cp ./mysql-connector-java-5.1.36.jar /data/hive/lib/
## 启动
## 启动前必须先启动hive的两个服务
cd /data/hive
nohup hive --service metastore &
nohup hive --service hiveserver2 &
# 强制删除需要加上cascade关键字
drop database dwa cascade
Azkaban安装
## 先建立一个MySQL库
create database azkaban
## 解压azkaban sql脚本,先在data目录下建好各个azkaban的目录
tar -zvxf azkaban-sql-script-2.5.0.tar.gz -C /data/azkaban/
tar -zvxf azkaban-executor-server-2.5.0.tar.gz -C /data/azkaban/
tar -zvxf azkaban-web-server-2.5.0.tar.gz -C /data/azkaban/
## 执行sql文件 只需执行 create-all-sql-2.5.0.sql 这一个脚本即可创建所有的表
mysql -uroot -p
use azkaban;
source /data/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql;
## 修改web服务器配置
## 在其 主目录下 生成生成KeyStore文件
cd /data/azkaban/azkaban-web-2.5.0
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
## 先设置一个密码
azkaban
## 然后回答一堆问题,随便填,这里都填1
What is your first and last name?
1: 1
What is the name of your organizational unit?
1: 1
What is the name of your organization?
1: 1
What is the name of your City or Locality?
1: 1
What is the name of your State or Province?
1: 1
What is the two-letter country code for this unit?
1: 1
Is CN=1, OU=1, O=1, L=1, ST=1, C=1 correct?
no: yes
## 最后再这块输入yes之后再次输入密码azkaban即可
## 把生成的文件移动到conf中
mv keystore ./conf/
## 启动 单节点启动后无需进行注册,但此处配置了ssl,所以访问地址应该为 https
## 一定要进入到executor目录下启动
## 因为在哪个目录下启动就会在哪个目录下产生一个executions文件夹,用来存放执行过的信息
cd /data/azkaban/azkaban-executor
nohup ./bin/azkaban-executor-start.sh >> ./log.log 2>1 &
cd /data/azkaban/azkaban-web
nohup ./bin/azkaban-web-start.sh >> ./log.log 2>1 &
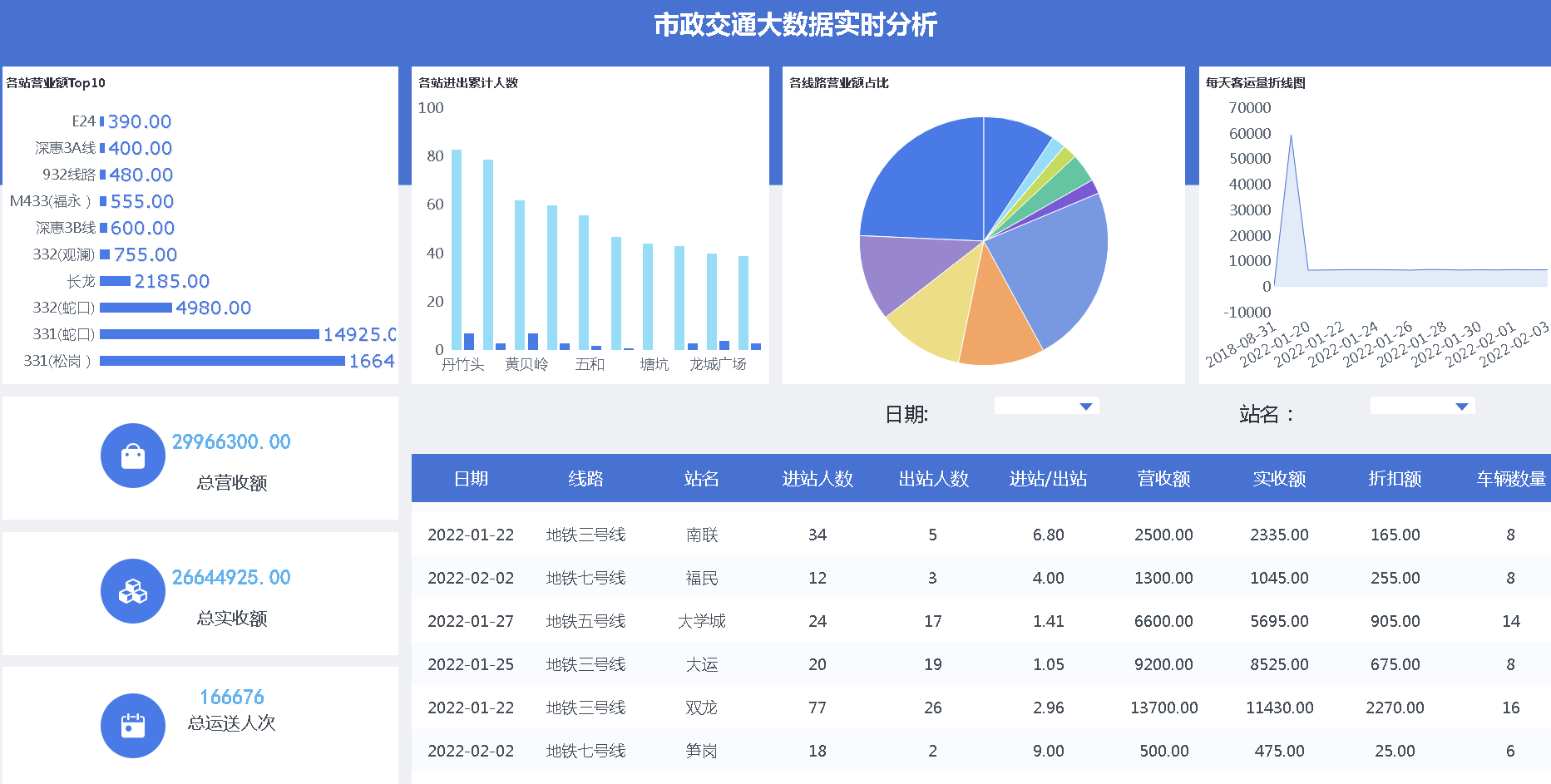
核心算法代码分享如下:
python
# 发送json
data = json.dumps({'page': 1, 'rows': 200})
ret = requests.post(url, headers=header, data=data, timeout=1000)
json_data = json.loads(ret.text)
# print(json_data)
print('請求結果:', json_data)
for row in json_data['data']:
print(row)
# save_info(row)
#save_road(row)
############################################# 解析 json 数据文件 ##########################################################
path = r"2018record3.jsons"
data = []
with open(path, 'r', encoding='utf-8') as f:
for line in f.readlines():
data += json.loads(line)['data']
data = pd.DataFrame(data)
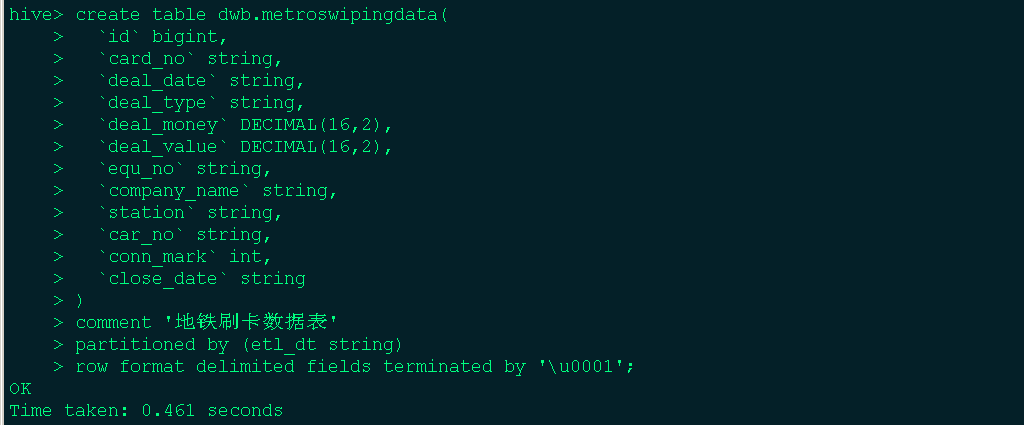
columns = ['card_no', 'deal_date', 'deal_type', 'deal_money', 'deal_value', 'equ_no', 'company_name', 'station', 'car_no', 'conn_mark', 'close_date']
data = data[columns] # 调整字段顺序
data.info()
############################################# 输出处理 ##########################################################
# 全部都是 交通运输 的刷卡数据
print(data['company_name'].unique())
# 删除重复值
# print(data[data.duplicated()])
data.drop_duplicates(inplace=True)
data.reset_index(drop=True, inplace=True)
# 缺失值
# 只有线路站点和车牌号两个字段存在为空,不做处理
# print(data.isnull().sum())
# 去掉脏数据
data = data[data['deal_date'] > '2018-08-31']
############################################# 数据保存 ##########################################################
print(data.info)
# 数据保存为 csv
data.to_csv('SZTcard.csv', index=False, header=None)