上一篇文章讲了爬虫的工作原理,这篇文章以后就要重点开始讲编程序了。
简单爬虫的的两个步骤:
- 使用HTTPRequest工具模拟HTTP请求,接收到返回的文本。用于请求的包有: requests、urllib等。
- 对接收的文本进行筛选,获取想要的内容。用户筛选文本的包有: bs4、lxml等。
爬虫的第一步就是向网站发送HTTP请求,本篇文章的主要内容就是用python向网站发送请求,获得网站的响应。
urllib库
在Python的网络编程世界中,urllib库是处理网络请求的基础库之一。无论是获取网页内容、下载文件还是发送POST请求,urllib都能提供强大的支持。
1. urllib库简介
urllib是Python标准库中的一个模块,用于处理网络请求。它包含多个子模块,如urllib.request、urllib.error、urllib.parse等,每个子模块都有其特定的功能和用途。下面我们将逐一介绍这些子模块的使用方法。
2. urllib.request模块
urllib.request模块用于打开和读取URLs。它提供了各种网络请求的类和函数,如urlopen()、Request()等。
使用urlopen()发送GET请求
某度搜索页源代码部分展示:


运行结果展示:
使用Request()发送带有请求头的GET请求
什么是请求头?
请求头(Request Headers) 是HTTP请求的一部分,它包含了关于一个HTTP请求的属性信息。这些属性信息定义了请求的客户端环境、请求的意图以及请求的原始服务器应使用的其他属性。一个HTTP请求通常由请求行、请求头和请求体三部分组成,其中请求头包含了多个属性,每个属性包含一个名字和一个值,两者用冒号:分隔。
在某瓣电影官网按下**F12**进入开发者模式,点击网络,然后点击文档查看我们要爬取页面的接口,我们选择第一个,查看它的请求头。如下图:

这里做个解释:左边的一列其实就是网址的缩写,我们很明显可以看出来第一个就是我们输入的网址,也就是我们要发送HTTP请求的网址,右边就是它的请求头信息。
各种请求头信息:
-
User-Agent:告诉服务器关于客户端的环境信息,如浏览器类型、版本、操作系统、渲染引擎等。这有助于服务器返回与客户端兼容的内容。(经常放到程序中,一般使用的时候随便去网页里复制一个就行)
-
Accept:
Accept请求头告诉服务器客户端能够处理哪些类型的响应内容,如text/html、application/json、image/jpeg等。服务器将使用此信息来确定返回哪种类型的响应内容。 -
Accept-Encoding:
Accept-Encoding请求头列出了客户端支持的压缩编码类型,如gzip、deflate等。服务器可以使用这些编码来压缩响应,以减少传输的数据量。 -
Accept-Language:
Accept-Language请求头告诉服务器客户端首选的语言,以便服务器能够返回用该语言编写的响应内容。这有助于实现内容的国际化和本地化。 -
Content-Type:
Content-Type请求头(在POST或PUT请求中常见)描述了请求体的媒体类型。这告诉服务器请求体的内容格式,以便服务器能够正确地解析数据。例如,对于JSON数据,Content-Type可能设置为application/json。 -
Content-Length:
Content-Length请求头告诉服务器请求体的长度(以字节为单位)。这对于需要知道请求体大小的服务器来说很有用。 -
Authorization:
Authorization请求头包含客户端提供给服务器的身份验证凭据,通常用于HTTP身份验证。例如,在基于令牌的认证中,客户端可能会将令牌作为此头的一部分发送。 -
Host:
Host请求头指定了请求的目标域名和端口号(如果端口号不是默认的80或443)。这允许服务器区分来自不同域名的请求,并在同一IP地址上托管多个网站。 -
Cache-Control:
Cache-Control请求头包含了关于请求缓存的指令。这些指令告诉缓存(如浏览器缓存或代理服务器缓存)如何缓存响应内容,以及何时可以重新验证缓存的内容。 -
Cookie:
Cookie请求头包含了由服务器之前设置的HTTP cookie。这些cookie可以用于会话管理、用户跟踪等目的。
除了上述常见的请求头之外,还有许多其他请求头,如Referer(指示请求的来源页面)、Connection(指定连接类型,如keep-alive)等。这些请求头根据具体的应用场景和需求而有所不同。
这部分不理解的话可以先跳过,知道请求头是用来伪装爬虫程序的就行了,后面实战遇到的时候会再给大家针对案例讲解。
为什么要加请求头?
-
身份认证:一些网站要求用户进行身份认证才能访问某些资源。请求头可以包含认证信息,如用户名和密码(虽然在现代应用中,这种做法通常会被更安全的方法如OAuth或JWT替代)。
-
缓存控制 :请求头中的
Cache-Control字段可以控制浏览器或其他客户端如何缓存请求的资源。例如,它可以指示服务器不要缓存某个资源,或者指示客户端在特定时间后重新验证缓存的资源。 -
内容协商 :请求头中的
Accept字段可以告诉服务器客户端能够处理哪些类型的响应内容。例如,客户端可以指定它期望接收HTML、XML、JSON或图片等类型的响应。 -
自定义请求:通过添加自定义的请求头,客户端可以向服务器传递额外的信息,以便服务器能够生成更符合客户端需求的响应。例如,一个API请求可能会包含一个表示API版本或客户端ID的自定义请求头。
-
跨域资源共享(CORS) :在Web开发中,跨域资源共享(CORS)是一个安全特性,它允许网页从与其来源不同的源加载资源。CORS请求会包含一个名为
Origin的请求头,该头字段用于描述请求的发起源。 -
防止缓存 :通过在请求头中添加特定的字段(如
Pragma: no-cache或Cache-Control: no-cache),可以确保浏览器或其他客户端不会从缓存中加载资源,而是从服务器获取最新的资源。 -
追踪和调试:请求头还可以包含用于追踪和调试的信息,如用户代理(User-Agent)字段可以告诉服务器客户端的类型和版本信息。
比如某瓣电影的网页,假如我们没有加上请求头的话,向网站发送请求是会直接报错的(代码还是上面的代码,只换了一个网址)。如下图:

这时候我们就需要加上请求头来伪装我们的爬虫程序。一般情况下,我们只需要加上一个user-agent,来伪装我们是浏览器,而不是一个爬虫程序。所以我们要在代码中加上请求头,请求头里添加上user-agent伪装我们的程序。
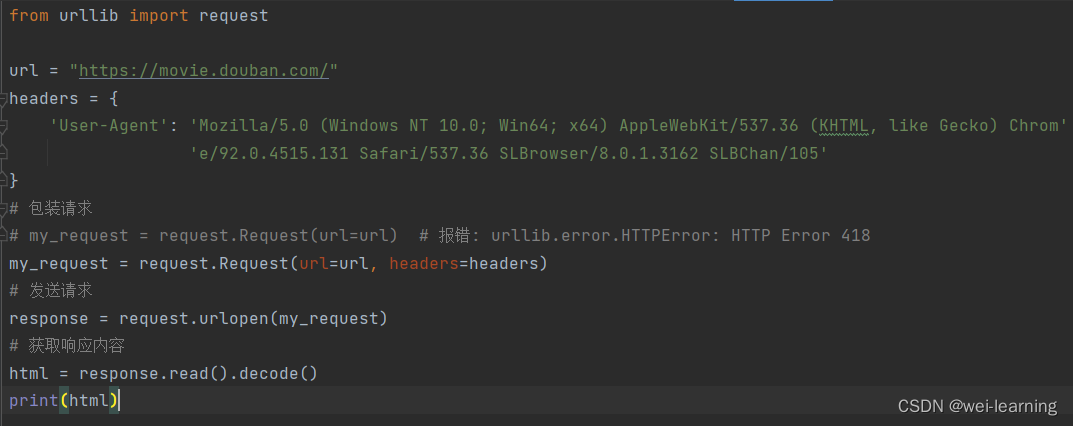
运行结果:
官网源代码如下图:

发送POST请求
HTTP 的 POST 请求是用于提交数据到服务器进行处理的请求方法。与 GET 请求不同,POST 请求通常不会在 URL 中包含数据,而是将数据包含在请求体中。这使得 POST 请求更适合于发送大量数据或敏感数据(如密码),因为数据不会在 URL 中暴露。还有比如大部分网页点赞或者评论等等都是post请求。
我们用下面这个网站来测试post请求。

运行结果如下(可以看到在form表单里有我们发送的数据。):

3. urllib.error模块
urllib.error模块用于处理urllib.request模块抛出的异常。当网络请求出现错误时,如连接超时、服务器无响应等,urllib.request会抛出异常,这时可以使用urllib.error模块中的异常类来捕获和处理这些异常。
4. urllib.parse模块
urllib.parse模块提供了处理URL的功能,如解析URL、构建查询参数等。
上面已经用过urlencode()这个方法了,接下来再说一下quote()和unquote()方法。
quote()对url地址中的中文进行编码,类似于urlencode()方法。

unquote()对url地址进行解码,将编码后的字符串转为普通的Unicode字符串。
python
data = '%E5%92%8C%E5%B9%B3'
result = parse.unquote(data)
print(result) # 运行结果: 和平requests库
requests库支持各种HTTP请求方法,包括GET、POST、PUT、DELETE等,功能非常强大,也是我们写爬虫程序中最常用的库,下面来介绍一些它的使用方法。首先安装requests库,终端输入:pip install requests
注意:由于上面讲urllib库的时候已经讲过get请求,post请求等讲过的我就不讲了,直接教大家使用这个第三方库,有不同的地方我再讲。
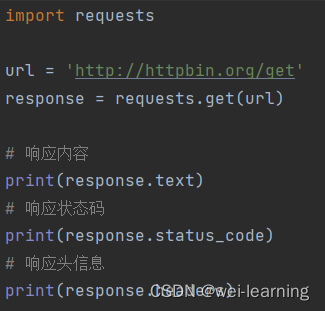
1. 发送GET请求
响应头(Response Headers)包含了关于服务器如何处理请求和返回资源的元数据。这些响应头对于调试、了解资源属性和配置缓存等非常有用。响应头信息用response对象的headers属性就可以获取。
2. 发送POST请求

3. 设置请求头

4. 处理JSON数据
当服务器返回JSON格式的数据时,我们可以使用response.json()方法将其直接解析为Python对象,这样就不需要使用python中的json库来把字符串转为python中的对象了。
不了解json数据的可以这样理解:用了json方法后,长的和python中列表或者字典一样的字符串就转变为了列表或者字典,可以让我们直接用python方法提取信息。

今天就先讲到这里,下一篇文章会讲一下requests库的更多用法,包括会话保持(Session)、SSL证书验证、文件上传、代理设置等稍微高级一点的用法。