This study presents a comprehensive analysis of Ultralytics YOLO26, highlighting its key architectural enhancements and performance benchmarking for real-time edge object detection. YOLO26, released in September 2025, stands as the newest and most advanced member of the YOLO family, purpose-built to deliver efficiency, accuracy, and deployment readiness on edge and low-power devices. The paper sequentially details YOLO26's architectural innovations, including the removal of Distribution Focal Loss (DFL), adoption of end-to-end NMS-free inference, integration of ProgLoss and Small-Target-Aware Label Assignment (STAL), and the introduction of the MuSGD optimizer for stable convergence. Beyond architecture, the study positions YOLO26 as a multi-task framework, supporting object detection, instance segmentation, pose/keypoints estimation, oriented detection, and classification. We present performance benchmarks of YOLO26 on edge devices such as NVIDIA Jetson Nano and Orin, comparing its results with YOLOv8, YOLOv11, YOLOv12, YOLOv13, and transformer-based detectors. This paper further explores real-time deployment pathways, flexible export options (ONNX, TensorRT, CoreML, TFLite), and quantization for INT8/FP16. Practical use cases of YOLO26 across robotics, manufacturing, and IoT are highlighted to demonstrate cross-industry adaptability. Finally, insights on deployment efficiency and broader implications are discussed, with future directions for YOLO26 and the YOLO lineage outlined.
Object detection has emerged as one of the most critical tasks in computer vision, enabling machines to localize and classify multiple objects within an image or video stream 1, 2. From autonomous driving and robotics to surveillance, medical imaging, agriculture, and smart manufacturing, real-time object detection algorithms serve as the backbone of artificial intelligence (AI) applications 3, 4. Among these algorithms, the You Only Look Once (YOLO) family has established itself as the most influential series of models for real-time object detection, combining accuracy with unprecedented inference speed 5, 6, 7, 7. Since its introduction in 2016, YOLO has evolved through numerous architectural revisions, each addressing limitations of its predecessors while integrating cutting-edge advances in neural network design, loss functions, and deployment efficiency 5. The release of YOLO26 in September 2025 represents the latest milestone in this evolutionary trajectory, introducing architectural simplifications, novel optimizers, and enhanced edge deployment capabilities designed for low-power devices.
【翻译】目标检测已成为计算机视觉中最关键的任务之一,使机器能够在图像或视频流中定位和分类多个目标1, 2。从自动驾驶和机器人技术到监控、医学成像、农业和智能制造,实时目标检测算法作为人工智能(AI)应用的支柱3, 4。在这些算法中,You Only Look Once (YOLO)系列已确立自己作为实时目标检测最具影响力的模型系列,将准确性与前所未有的推理速度相结合5, 6, 7, 7。自2016年推出以来,YOLO经历了众多架构修订,每次都解决了前代的局限性,同时整合了神经网络设计、损失函数和部署效率方面的前沿进展5。YOLO26于2025年9月发布,代表了这一演进轨迹中的最新里程碑,引入了架构简化、新颖优化器和专为低功耗设备设计的增强边缘部署能力。
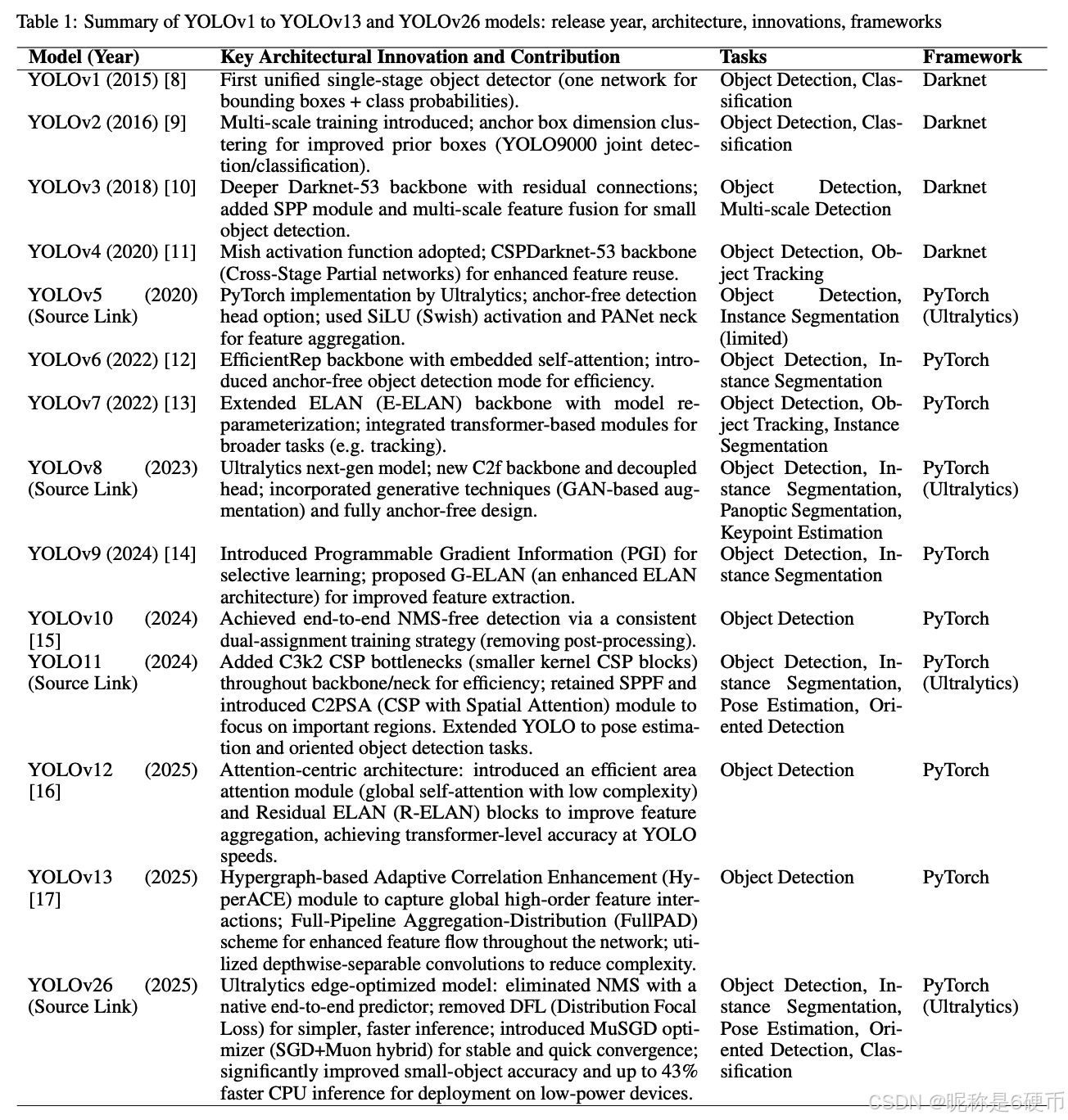
Table 1 provides a detailed comparison of YOLO models from version YOLOv1 to YOLOv13 and YOLO26, highlighting their release years, key architectural innovations, performance enhancements, and development frameworks.
Table 1: Summary of YOLOv1 to YOLOv13 and YOLO26 models: release year, architecture, innovations, frameworks.
【翻译】表1:YOLOv1到YOLOv13和YOLO26模型总结:发布年份、架构、创新点、框架。
The YOLO framework was first proposed by Joseph Redmon and colleagues in 2016, introducing a paradigm shift in object detection 8. Unlike traditional two-stage detectors such as R-CNN 18 and Faster R-CNN 19, which separated region proposal from classification, YOLO formulated detection as a single regression problem 20. By directly predicting bounding boxes and class probabilities in one forward pass through a convolutional neural network (CNN), YOLO achieved real-time speeds while maintaining competitive accuracy 21, 20. This efficiency made YOLOv1 highly attractive for applications where latency was a critical factor, including robotics, autonomous navigation, and live video analytics. Subsequent versions YOLOv2 (2017) 9and YOLOv3 (2018) 10 significantly improved accuracy while retaining real-time performance. YOLOv2 introduced batch normalization, anchor boxes, and multi-scale training, which increased robustness across varying object sizes. YOLOv3 leveraged a deeper architecture based on Darknet-53, along with multi-scale feature maps for better small-object detection. These enhancements made YOLOv3 the de facto standard for academic and industrial applications for several years 22, 5, 23.
As the demand for higher accuracy grew, especially in challenging domains such as aerial imagery, agriculture, and medical analysis, YOLO models diversified into more advanced architectures. YOLOv4 (2020) 11 introduced Cross-Stage Partial Networks (CSPNet), improved activation functions like Mish, and advanced training strategies including mosaic data augmentation and CIoU loss. YOLOv5 (Ultralytics, 2020), though unofficial, gained immense popularity due to its PyTorch implementation, extensive community support, and simplified deployment across diverse platforms. YOLOv5 also brought modularity, making it easier to adapt for segmentation, classification, and edge applications. Further developments included YOLOv612 and YOLOv7 13 (2022), which integrated advanced optimization techniques, parameter-efficient modules, and transformer-inspired blocks. These iterations pushed YOLO closer to state-of-the-art (SoTA) accuracy benchmarks while retaining a focus on real-time inference. The YOLO ecosystem, by this point, had firmly established itself as the leading family of models in object detection research and deployment.
Ultralytics, the primary maintainer of modern YOLO releases, redefined the framework with YOLOv8 (2023) 24. YOLOv8 featured a decoupled detection head, anchor-free predictions, and refined training strategies, resulting in substantial improvements in both accuracy and deployment versatility 25. It was widely adopted in industry due to its clean Python API, compatibility with TensorRT, CoreML, and ONNX, and availability of variants optimized for speed versus accuracy trade-offs (nano, small, medium, large, and extra-large). YOLOv9 14, YOLOv10 15, and YOLO11 followed in rapid succession, each iteration pushing the boundaries of architecture and performance. YOLOv9 introduced GELAN (Generalized Efficient Layer Aggregation Network) and Progressive Distillation, combining efficiency with higher representational capacity. YOLOv10 focused on balancing accuracy and inference latency with hybrid task-aligned assignments. YOLOv11 further refined Ultralytics' vision, offering higher efficiency on GPUs while maintaining strong small-object performance 5. Together, these models cemented Ultralytics' reputation for producing production-ready YOLO releases tailored to modern deployment pipelines.
Following YOLO11, alternative versions YOLOv1216 and YOLOv13 17 introduced attention-centric designs and advanced architectural components that sought to maximize accuracy across diverse datasets. These models explored multi-head self-attention, improved multi-scale fusion, and stronger training regularization strategies. While they offered strong benchmarks, they retained reliance on Non-Maximum Suppression (NMS) and Distribution Focal Loss (DFL), which introduced latency overhead and export challenges, especially for low-power devices. The limitations of NMS-based post-processing and complex loss formulations motivated the development of YOLO26 (Ultralytics YOLO26 Official Source). By September 2025, at the YOLO Vision 2025 event in London, Ultralytics unveiled YOLO26 as a next-generation model optimized for edge computing, robotics, and mobile AI.
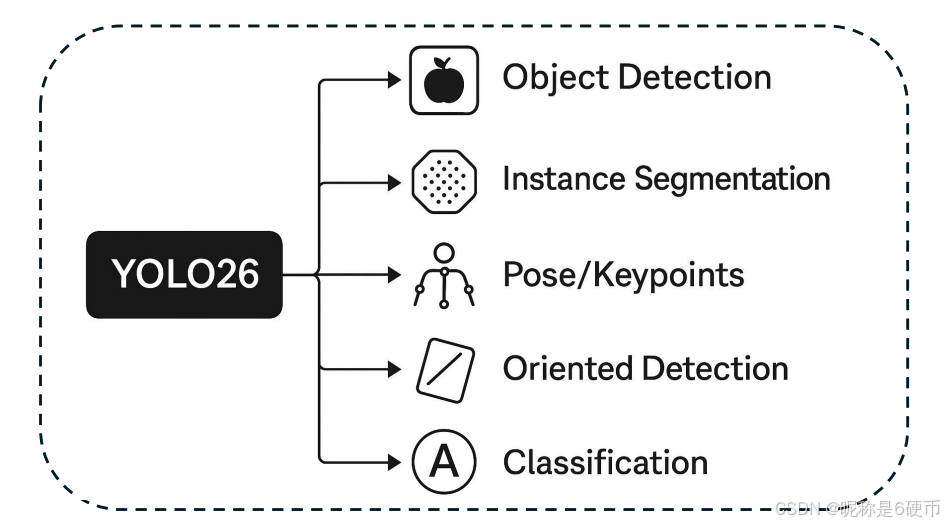
YOLO26 is engineered around three guiding principles simplicity, efficiency, and innovation and the overview in Figure 1 situates these choices alongside its five supported tasks: object detection, instance segmentation, pose/keypoints detection, oriented detection, and classification. On the inference path, YOLO26 eliminates NMS, producing native end-to-end predictions that remove a major post-processing bottleneck, reduce latency variance, and simplify threshold tuning across deployments. On the regression side, it removes DFL, turning distributional box decoding into a lighter, hardware-friendly formulation that exports cleanly to ONNX, TensorRT, CoreML, and TFLite a practical win for edge and mobile pipelines. Together, these changes yield a leaner graph, faster cold-start, and fewer runtime dependencies, which is particularly beneficial for CPU-bound and embedded scenarios. Training stability and small-object fidelity are addressed through ProgLoss (progressive loss balancing) and STAL (small-target-aware label assignment). ProgLoss adaptively reweights objectives to prevent domination by easy examples late in training, while STAL prioritizes assignment for tiny or occluded instances, improving recall under clutter, foliage, or motion blur conditions common in aerial, robotics, and smart-camera feeds. Optimization is driven by MuSGD, a hybrid that blends the generalization of SGD with momentum/curvature behaviors inspired by Muon-style methods, enabling faster, smoother convergence and more reliable plateaus across scales.
This consolidated design allows multi-task training or task-specific fine-tuning without architectural rework, while the simplified exports preserve portability across accelerators. In sum, YOLO26 advances the YOLO lineage by pairing end-to-end inference and DFL-free regression with ProgLoss, STAL, and MuSGD, yielding a model that is faster to deploy, steadier to train, and broader in capability as visually summarized in Figure 1.
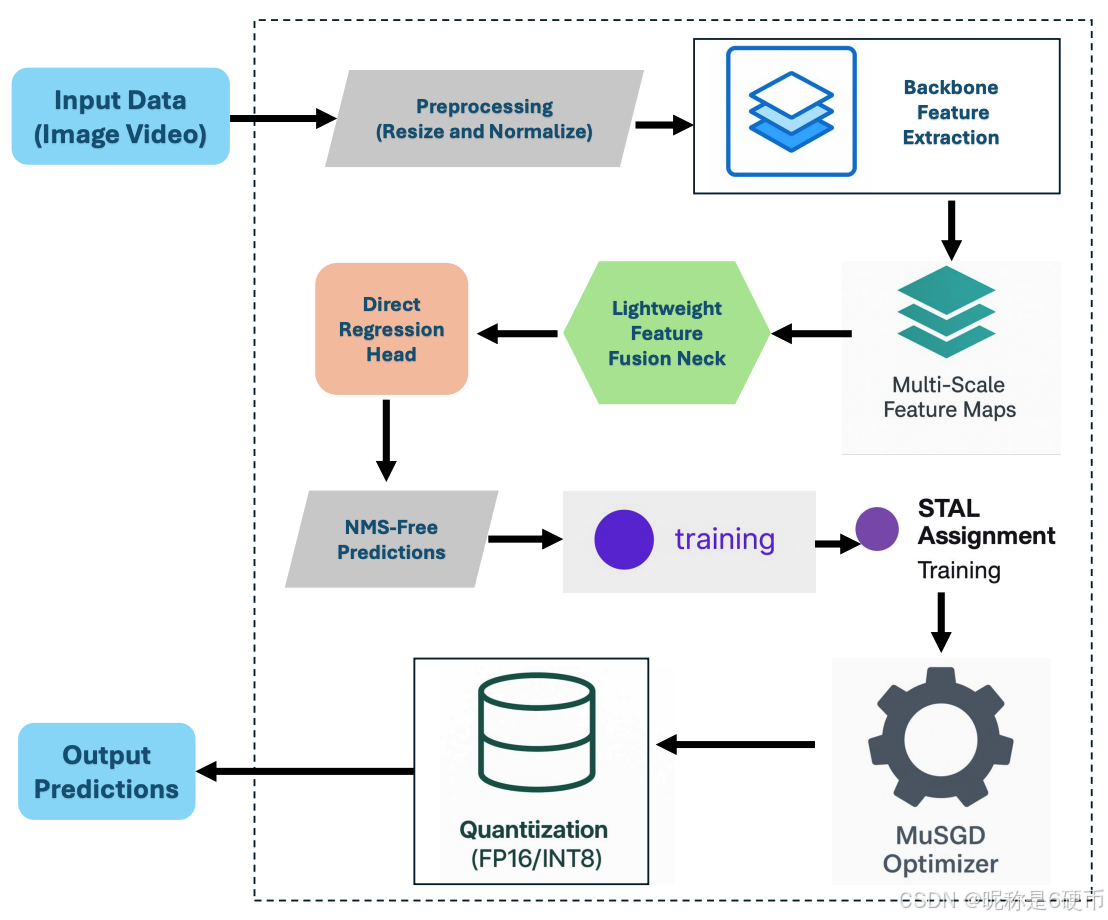
The architecture of YOLO26 follows a streamlined and efficient pipeline that has been purpose-built for real-time object detection across edge and server platforms. As illustrated in Figure 2, the process begins with the ingestion of input data in the form of images or video streams, which are first passed through preprocessing operations including resizing and normalization to standard dimensions suitable for model inference. The data is then fed into the backbone feature extraction stage, where a compact yet powerful convolutional network captures hierarchical representations of visual patterns. To enhance robustness across scales, the architecture generates multi-scale feature maps (Figure 2) that preserve semantic richness for both large and small objects. These feature maps are then merged within a lightweight feature fusion neck, where information is integrated in a computationally efficient manner. Detection-specific processing occurs in the direct regression head, which, unlike prior YOLO versions, outputs bounding boxes and class probabilities without relying on Non-Maximum Suppression (NMS). This end-to-end NMS-free inference (Figure 2) eliminates post-processing overhead and accelerates deployment. Training stability and accuracy are reinforced by ProgLoss balancing and STAL assignment modules, which ensure equitable weighting of loss terms and improved detection of small targets. Model optimization is guided by the MuSGD optimizer, combining the strengths of SGD and Muon for faster and more reliable convergence. Deployment efficiency is further enhanced through quantization, with support for FP16 and INT8 precision, enabling acceleration on CPUs, NPUs, and GPUs with minimal accuracy degradation. Finally, the pipeline culminates in the generation of output predictions, including bounding boxes and class assignments that can be visualized overlaid on the input image. Overall, the architecture of YOLO26 demonstrates a carefully balanced design philosophy that simultaneously advances accuracy, stability, and deployment simplicity.
YOLO26 introduces several key architectural innovations that differentiate it from prior generations of YOLO models. These enhancements not only improve training stability and inference efficiency but also fundamentally reshape the deployment pipeline for real-time edge devices. In this section, we describe four major contributions of YOLO26: (i) the removal of Distribution Focal Loss (DFL), (ii) the introduction of end-to-end Non-Maximum Suppression (NMS)-free inference, (iii) novel loss function strategies including Progressive Loss Balancing (ProgLoss) and Small-Target-Aware Label Assignment (STAL), and (iv) the development of the MuSGD optimizer for stable and efficient convergence. Each of these architectural enhancements is discussed in detail, with comparative insights highlighting their advantages over earlier YOLO versions such as YOLOv8, YOLOv11, YOLOv12, and YOLOv13.
Figure 2: Simplified Architecture diagram of Ultralytics YOLO26
【翻译】图2:Ultralytics YOLO26的简化架构图
2.1 移除分布焦点损失(DFL)
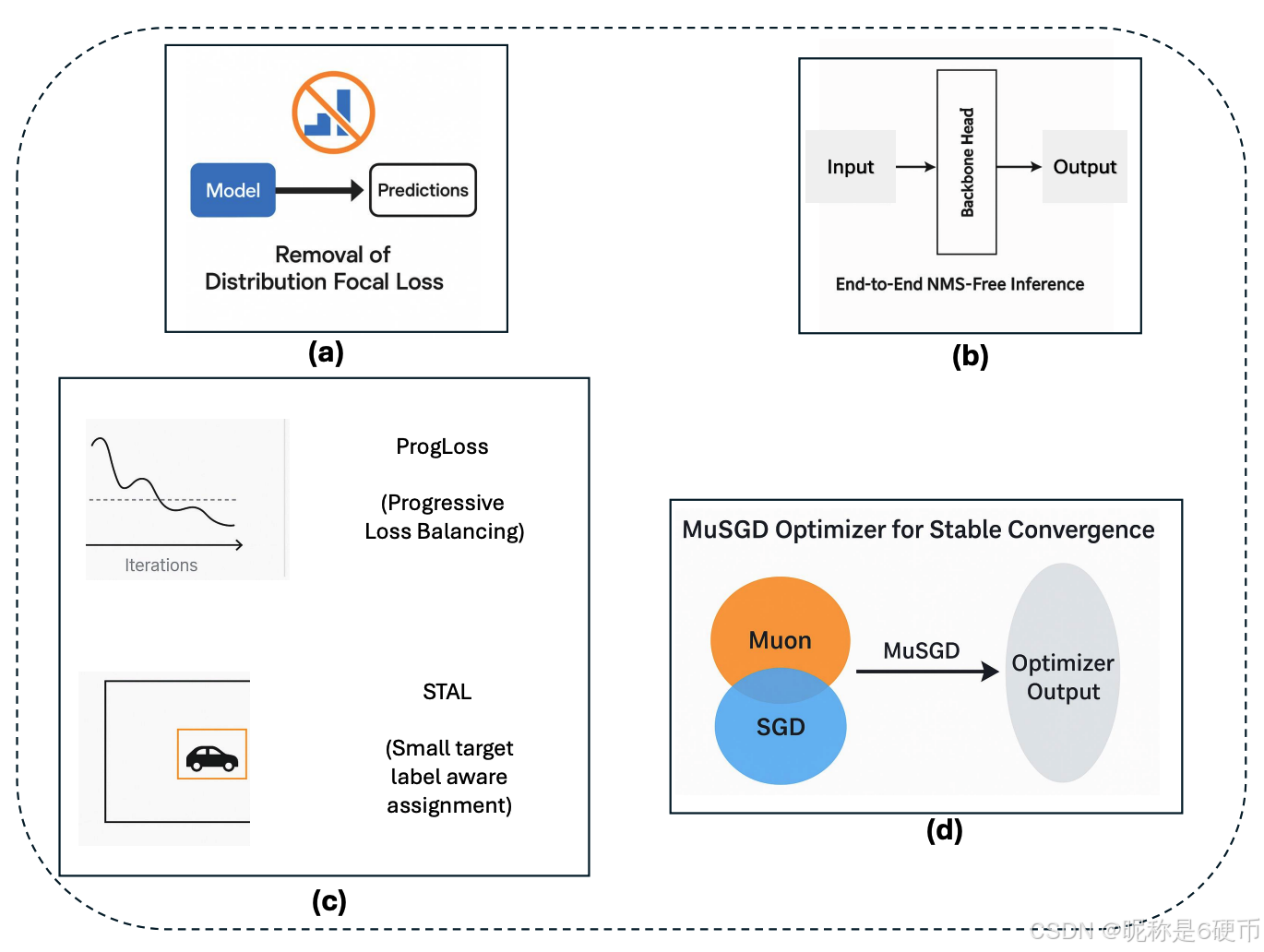
One of the most significant architectural simplifications in YOLO26 is the removal of the Distribution Focal Loss (DFL) module (Figure 3a), which had been present in prior YOLO releases such as YOLOv8 and YOLOv11. DFL was originally designed to improve bounding box regression by predicting probability distributions for box coordinates, thereby allowing more precise localization of objects. While this strategy demonstrated accuracy gains in earlier models, it also introduced non-trivial computational overhead and export difficulties. In practice, DFL required specialized handling during inference and model export, which complicated deployment pipelines targeting hardware accelerators such as ONNX, CoreML, TensorRT, or TFLite.
By eliminating DFL, YOLO26 simplifies the model's architecture, making bounding box prediction a more straightforward regression task without sacrificing performance. Comparative analysis indicates that YOLO26 achieves comparable or superior accuracy to DFL-based YOLO models, particularly when combined with other innovations such as ProgLoss and STAL. Moreover, the removal of DFL significantly reduces inference latency and improves cross-platform compatibility. This makes YOLO26 more suitable for edge AI scenarios, where lightweight and hardware-friendly models are paramount.
In contrast, models such as YOLOv12 and YOLOv13 retained DFL in their architectures, which limited their applicability on constrained devices despite strong accuracy benchmarks on GPU-rich environments. YOLO26 therefore marks a decisive step toward aligning state-of-the-art object detection performance with the realities of mobile, embedded, and industrial applications.
Another groundbreaking feature of YOLO26 is its native support for end-to-end inference without Non-Maximum Suppression (NMS) (Refer to Figure 3b). Traditional YOLO models, including YOLOv8 through YOLOv13, rely heavily on NMS as a post-processing step to filter out duplicate predictions by retaining only the bounding boxes with the highest confidence scores. While effective, NMS adds additional latency to the pipeline and requires manually tuned hyperparameters such as the Intersection-over-Union (IoU) threshold. This dependence on a handcrafted post-processing step introduces fragility in deployment pipelines, especially for edge devices and latency-sensitive applications.
YOLO26 fundamentally redesigns the prediction head to produce direct, non-redundant bounding box predictions without the need for NMS. This end-to-end design not only reduces inference complexity but also eliminates the dependency on hand-tuned thresholds, thereby simplifying integration into production systems. Comparative benchmarks demonstrate that YOLO26 achieves faster inference speeds than YOLOv11 and YOLOv12, with CPU inference times reduced by up to 43 % 43\% 43% for the nano model. This makes YOLO26 particularly advantageous for mobile devices, UAVs, and embedded robotics platforms where milliseconds of latency can have substantial operational impacts.
Beyond speed, the NMS-free approach improves reproducibility and deployment portability, as models no longer require extensive post-processing code. While other advanced detectors such as RT-DETR and Sparse R-CNN have experimented with NMS-free inference, YOLO26 represents the first YOLO release to adopt this paradigm while maintaining YOLO's hallmark balance between speed and accuracy. Compared to YOLOv13, which still depends on NMS, YOLO26's end-to-end pipeline stands out as a forward-looking architecture for real-time detection.
Training stability and small-object recognition remain persistent challenges in object detection. YOLO26 addresses these through the integration of two novel strategies: Progressive Loss Balancing (ProgLoss) and Small-Target-Aware Label Assignment (STAL), as depicted in Figure (Figure 3c).
ProgLoss dynamically adjusts the weighting of different loss components during training, ensuring that the model does not overfit to dominant object categories while underperforming on rare or small classes. This progressive rebalancing improves generalization and prevents instability during later epochs of training. STAL, on the other hand, explicitly prioritizes label assignments for small objects, which are particularly difficult to detect due to their limited pixel representation and susceptibility to occlusion. Together, ProgLoss and STAL provide YOLO26 with a substantial accuracy boost on datasets with small or occluded objects, such as COCO and UAV imagery benchmarks.
Comparatively, earlier models such as YOLOv8 and YOLOv11 did not incorporate such targeted mechanisms, often requiring dataset-specific augmentations or external training tricks to achieve acceptable small-object performance. YOLOv12 and YOLOv13 attempted to address this gap through attention-based modules and enhanced multi-scale feature fusion; however, these solutions increased architectural complexity and inference costs. YOLO26 achieves similar or superior improvements with a more lightweight approach, reinforcing its suitability for edge AI applications. By integrating ProgLoss and STAL, YOLO26 establishes itself as a robust small-object detector while maintaining the efficiency and portability of the YOLO family.
A final innovation in YOLO26 is the introduction of the MuSGD optimizer (Figure 3d), which combines the strengths of Stochastic Gradient Descent (SGD) with the recently proposed Muon optimizer, a technique inspired by optimization strategies used in large language model (LLM) training. MuSGD leverages the robustness and generalization capacity of SGD while incorporating adaptive properties from Muon, enabling faster convergence and more stable optimization across diverse datasets.
This hybrid optimizer reflects an important trend in modern deep learning: the cross-pollination of advances between natural language processing (NLP) and computer vision. By borrowing from LLM training practices (e.g., Kimi K2 by Moonshot AI), YOLO26 benefits from stability enhancements that were previously unexplored in the YOLO lineage. Empirical results show that MuSGD enables YOLO26 to reach competitive accuracy with fewer training epochs, reducing both training time and computational cost.
Previous YOLO versions, including YOLOv8 through YOLOv13, relied on standard SGD or AdamW variants. While effective, these optimizers required extensive hyperparameter tuning and sometimes exhibited unstable convergence, particularly on datasets with high variability. In comparison, MuSGD improves reliability while preserving YOLO's lightweight training ethos. For practitioners, this translates into shorter development cycles, fewer training restarts, and more predictable performance across deployment scenarios. By integrating MuSGD, YOLO26 positions itself as not only an inference-optimized model but also a training-friendly architecture for researchers and industry practitioners alike.
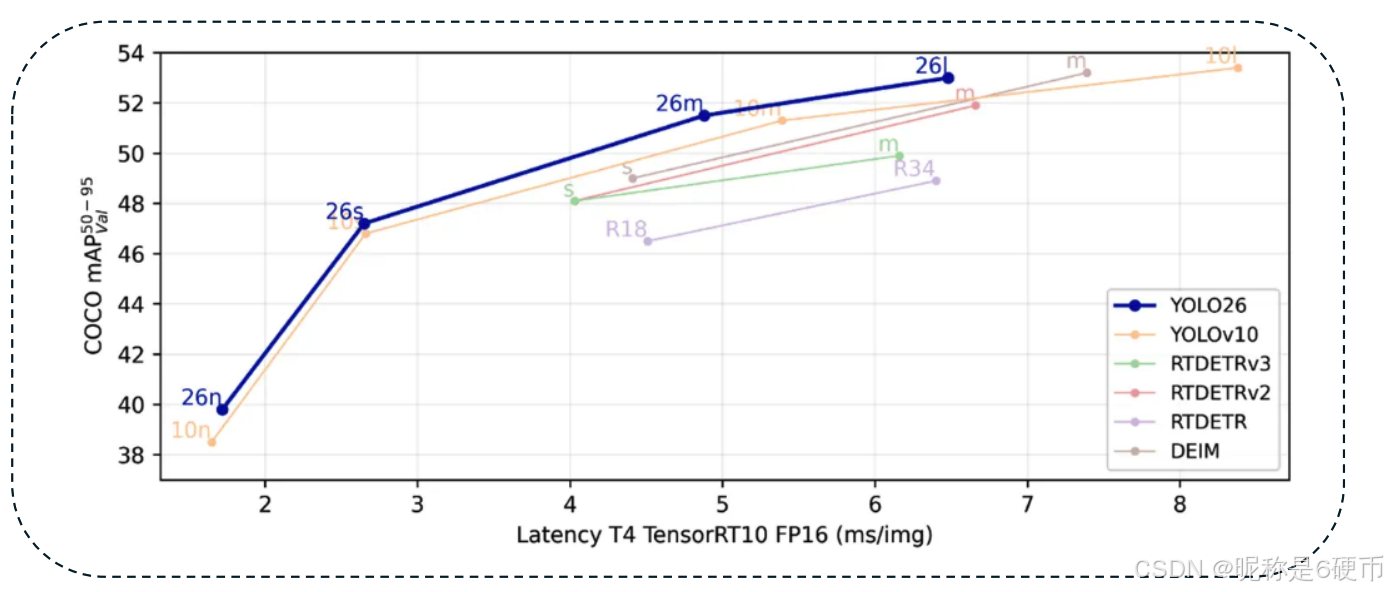
In the case of YOLO26, a series of rigorous benchmarks were conducted to assess its performance in comparison to both its YOLO predecessors and alternative state-of-the-art architectures. Figure 4 presents a consolidated view of this evaluation, plotting COCO mAP(50--95) against latency (ms per image) on an NVIDIA T4 GPU with TensorRT FP16 optimization. The inclusion of competing architectures such as YOLOv10, RT-DETR, RT-DETRv2, RT-DETRv3, and DEIM provides a comprehensive landscape of recent advancements in real-time detection. From the figure, YOLO26 demonstrates a distinctive positioning: it maintains high accuracy levels that rival transformer-based models like RT-DETRv3, while significantly outperforming them in terms of inference speed. For instance, YOLO26-m and YOLO26-l achieve competitive mAP scores above 51 % 51\% 51% and 53 % 53\% 53% , respectively, but at a substantially reduced latency, underscoring the benefits of its NMS-free architecture and lightweight regression head.
This balance between accuracy and speed is particularly relevant for edge deployments, where maintaining real-time throughput is as important as ensuring reliable detection quality. Compared with YOLOv10, YOLO26 consistently achieves lower latency across model scales, with speedups of up to 43 % 43\% 43% observed for CPU-bound inference, while preserving or improving accuracy through its ProgLoss and STAL mechanisms. When compared to DEIM and the RT-DETR series, which rely heavily on transformer encoders and decoders, YOLO26's simplified backbone and MuSGD-driven training pipeline enable faster convergence and leaner inference without compromising small-object recognition. The plot in Figure 4 clearly illustrates these distinctions: while RT-DETRv3 excels in large-scale accuracy benchmarks, its latency profile remains less favorable than YOLO26, reinforcing YOLO26's edge-centric design philosophy. Furthermore, the benchmarking analysis highlights YOLO26's robustness in balancing the accuracy--latency curve, situating it as a versatile detector suitable for both high-throughput server applications and resource-constrained devices. This comparative evidence substantiates the claim that YOLO26 is not merely an incremental update but a paradigm shift in the YOLO lineage, successfully bridging the gap between the efficiency-first philosophy of earlier YOLO models and the accuracy-driven orientation of transformer-based detectors. Ultimately, the benchmarking results demonstrate that YOLO26 offers a compelling deployment advantage, particularly in real-world environments requiring reliable performance under stringent latency constraints.
Figure 4: Performance benchmarking of YOLO26 compared with YOLOv10, RT-DETR, RT-DETRv2, RT-DETRv3, and DEIM on the COCO dataset. The plot shows COCO mAP(50--95) versus latency (ms per image) measured on an NVIDIA T4 GPU using TensorRT FP16 inference. YOLO26 demonstrates superior balance between accuracy and efficiency, achieving competitive detection performance while significantly reducing latency, thereby highlighting its suitability for real-time edge and resource-constrained deployments.
Over the past decade, the evolution of object detection models has been marked not only by increases in accuracy but also by growing complexity in deployment 26, 27, 28. Early detectors such as R-CNN and its faster variants (Fast R-CNN, Faster R-CNN) achieved impressive detection quality but were computationally expensive, requiring multiple stages for region proposal and classification 29, 30, 31. This limited their use in real-time and embedded applications. The arrival of the YOLO family transformed this landscape by reframing detection as a single regression problem, enabling real-time performance on commodity GPUs 32. However, as the YOLO lineage progressed from YOLOv1 through YOLOv13, accuracy improvements often came at the cost of additional architectural components such as Distribution Focal Loss (DFL), complex post-processing steps like Non-Maximum Suppression (NMS), and increasingly heavy backbones that introduced friction during deployment. YOLO26 addresses this longstanding challenge directly by streamlining both architecture and export pathways, thereby reducing deployment barriers across diverse hardware and software ecosystems.
A key advantage of YOLO26 is its seamless integration into existing production pipelines. Ultralytics maintains an actively developed Python package that provides unified support for training, validation, and export, lowering the technical barrier for practitioners seeking to adopt YOLO26. Unlike earlier YOLO models, which required extensive custom conversion scripts for hardware acceleration 33, 34, 35, YOLO26 natively supports a wide range of export formats. These include TensorRT for maximum GPU acceleration, ONNX for broad cross-platform compatibility,
CoreML for native iOS integration, TFLite for Android and edge devices, and OpenVINO for optimized performance on Intel hardware. The breadth of these export options enables researchers, engineers, and developers to move models from prototyping to production without encountering the compatibility bottlenecks common in earlier generations.
Historically, YOLOv3 through YOLOv7 often required manual intervention during export, particularly when targeting specialized inference engines such as NVIDIA TensorRT or Apple CoreML 36, 37. Similarly, transformer-based detectors like DETR and its successors faced challenges when converted outside PyTorch environments due to their reliance on dynamic attention mechanisms. By comparison, YOLO26's architecture, simplified through the removal of DFL and the adoption of an NMS-free prediction head, ensures compatibility across platforms without sacrificing accuracy. This makes YOLO26 one of the most deployment-friendly detectors released to date, reinforcing its identity as an edge-first model.
Beyond export flexibility, the true challenge in real-world deployment lies in ensuring efficiency on devices with limited computational resources 27, 38. Edge devices such as smartphones, drones, and embedded vision systems often lack discrete GPUs and must balance memory, power, and latency constraints 39, 40. Quantization is a widely adopted strategy to reduce model size and computational load, yet many complex detectors experience significant accuracy degradation under aggressive quantization. YOLO26 has been designed with this limitation in mind.
Owing to its streamlined architecture and simplified bounding box regression pipeline, YOLO26 demonstrates consistent accuracy under both half-precision (FP16) and integer (INT8) quantization schemes. FP16 quantization leverages native GPU support for mixed-precision arithmetic, enabling faster inference with reduced memory footprint. INT8 quantization compresses model weights to 8-bit integers, delivering dramatic reductions in model size and energy consumption while maintaining competitive accuracy. Benchmark experiments confirm that YOLO26 maintains stability across these quantization levels, outperforming YOLOv11 and YOLOv12 under identical conditions. This makes YOLO26 particularly well-suited for deployment on compact hardware such as NVIDIA Jetson Orin, Qualcomm Snapdragon AI accelerators, or even ARM-based CPUs powering smart cameras.
In contrast, transformer-based detectors such as RT-DETRv3 exhibit sharp drops in performance under INT8 quantization 41, primarily due to the sensitivity of attention mechanisms to reduced precision. Similarly, YOLOv12 and YOLOv13, while delivering strong accuracy on GPU servers, struggle to retain competitive performance on low-power devices once quantized. YOLO26 therefore establishes a new benchmark for quantization-aware design in object detection, demonstrating that architectural simplicity can directly translate into deployment robustness.
The practical impact of these deployment enhancements is best illustrated through cross-industry applications. In robotics, real-time perception is crucial for navigation, manipulation, and safe human-robot collaboration 42, 43. By offering NMS-free predictions and consistent low-latency inference, YOLO26 allows robotic systems to interpret their environments faster and more reliably. For example, robotic arms equipped with YOLO26 can identify and grasp objects with higher precision under dynamic conditions, while mobile robots benefit from improved obstacle recognition in cluttered spaces. Compared with YOLOv8 or YOLOv11, YOLO26 offers reduced inference delay, which can be the difference between a safe maneuver and a collision in high-speed scenarios.
In manufacturing, YOLO26 has significant implications for automated defect detection and quality assurance. Traditional manual inspection is not only labor-intensive but also prone to human error. Previous YOLO releases, particularly YOLOv8, were already deployed in smart factories; however, the complexity of export and the latency overhead of NMS sometimes constrained large-scale rollout. YOLO26 mitigates these barriers by offering lightweight deployment options through OpenVINO or TensorRT, allowing manufacturers to integrate real-time defect detection systems directly on production lines. Early benchmarks suggest that YOLO26-based defect detection pipelines achieve higher throughput and lower operational costs compared to both YOLOv12 and transformer-based alternatives such as DEIM.
Taken together, the deployment features of YOLO26 underscore a central theme in the evolution of object detection: architectural efficiency is just as critical as accuracy. While the past five years have seen the rise of increasingly sophisticated models ranging from convolution-based YOLO variants to transformer-based detectors like DETR and RT-DETR the gap between laboratory performance and production readiness has often limited their impact. YOLO26 bridges this gap by simplifying architecture, expanding export compatibility, and ensuring resilience under quantization, thereby aligning cutting-edge accuracy with practical deployment needs.
For developers building mobile applications, YOLO26 enables seamless integration through CoreML and TFLite, ensuring that models run natively on iOS and Android platforms. For enterprises deploying vision AI in cloud or on-premise servers, TensorRT and ONNX exports provide scalable acceleration options. For industrial and edge users, OpenVINO and INT8 quantization guarantee that performance remains consistent even under tight resource constraints. In this sense, YOLO26 is not only a step forward in object detection research but also a major milestone in democratizing deployment.
In conclusion, YOLO26 represents a significant leap in the YOLO object detection series, blending architectural innovation with a pragmatic focus on deployment. The model simplifies its design by removing the Distribution Focal Loss (DFL) module and eliminating the need for non-maximum suppression. By removing DFL, YOLO26 streamlines bounding box regression and avoids export complications, which broadens compatibility with various hardware. Likewise, its end-to-end, NMS-free inference enables the network to output final detections directly without a post-processing step. This not only reduces latency but also simplifies the deployment pipeline, making YOLO26 a natural evolution of earlier YOLO concepts. In training, YOLO26 introduces Progressive Loss Balancing (ProgLoss) and Small-Target-Aware Label Assignment (STAL), which together stabilize learning and boost accuracy on challenging small objects. Additionally, a novel MuSGD optimizer, combining properties of SGD and Muon, accelerates convergence and improves training stability. These enhancements work in concert to deliver a detector that is not only more accurate and robust but also markedly faster and lighter in practice.
Benchmark comparisons underscore YOLO26's strong performance relative to both its YOLO predecessors and contemporary models. Prior YOLO versions such as YOLO11 surpassed earlier releases with greater efficiency, and YOLO12 extended accuracy further through the integration of attention mechanisms. YOLO13 added hypergraph-based refinements to achieve additional improvements. Against transformer-based rivals, YOLO26 closes much of the gap. Its native NMS-free design mirrors the end-to-end approach of transformer-inspired detectors, but with YOLO's hallmark efficiency. YOLO26 delivers competitive accuracy while dramatically boosting throughput on common hardware and minimizing complexity. In fact, YOLO26's design yields up to 43 % 43\% 43% faster inference on CPU than previous YOLO versions, making it one of the most practical real-time detectors for resource-constrained environments. This harmonious balance of performance and efficiency allows YOLO26 to excel not just on benchmark leaderboards but also in actual field deployments where speed, memory, and energy are at a premium.
A major contribution of YOLO26 is its emphasis on deployment advantages. The model's architecture was deliberately optimized for real-world use: by omitting DFL and NMS, YOLO26 avoids operations that are difficult to implement on specialized hardware accelerators, thereby improving compatibility across devices. The network is exportable to a wide array of formats including ONNX, TensorRT, CoreML, TFLite, and OpenVINO ensuring that developers can integrate it into mobile apps, embedded systems, or cloud services with equal ease. Crucially, YOLO26 also supports robust quantization: it can be deployed with INT8 quantization or half-precision FP16 with minimal impact on accuracy, thanks to its simplified architecture that tolerates low-bitwidth inference. This means models can be compressed and accelerated while still delivering reliable detection performance. Such features translate to real edge performance gains from drones to smart cameras, YOLO26 can run real-time on CPU and small devices where previous YOLO models struggled. All these improvements demonstrate an overarching theme: YOLO26 bridges the gap between cutting-edge research ideas and deployable AI solutions. This approach underscores YOLO26's role as a bridge between academic innovation and industry application, bringing the latest vision advancements directly into the hands of practitioners.
Looking ahead, the trajectory of YOLO and object detection research suggests several promising directions. One clear avenue is the unification of multiple vision tasks into even more holistic models. YOLO26 already supports object detection, instance segmentation, pose estimation, oriented bounding boxes, and classification in one framework, reflecting a trend toward multi-task versatility. Future YOLO iterations might push this further by incorporating open-vocabulary and foundation-model capabilities. This could mean leveraging powerful vision-language models so that detectors can recognize arbitrary object categories in a zero-shot manner, without being limited to a fixed label set. By building on foundation models and large-scale pretraining, the next generation of YOLO could serve as a general-purpose vision AI that seamlessly handles detection, segmentation, and even description of novel objects in context.
Another key evolution is likely in the realm of semi-supervised and self-supervised learning for object detection 44, 45, 46, 47. State-of-the-art detectors still rely heavily on large labeled datasets, but research is rapidly advancing methods to train on unlabeled or partially labeled data. Techniques such as teacher--student training 48, 49, 50, pseudo-labeling 51, 52, and self-supervised feature learning 53could be integrated into the YOLO training pipeline to reduce the need for extensive manual annotations. A future YOLO might automatically leverage vast amounts of unannotated images or videos to improve recognition robustness. By doing so, the model can continue to improve its detection capabilities without proportional increases in labeled data, making it more adaptable to new domains or rare object categories.
Architecturally, we anticipate a continued blending of transformer and CNN design principles in object detectors. The success of recent YOLO models has shown that injecting attention and global reasoning into YOLO-like architectures can yield accuracy gains 54, 55. Future YOLO architectures may adopt hybrid designs that combine convolutional backbones (for efficient local feature extraction) with transformer-based modules or decoders (for capturing long-range dependencies and context). Such hybrid approaches can improve how the model understands complex scenes, for example in crowded or highly contextual environments, by modeling relationships that pure CNNs or naive self-attention might miss. We expect next-generation detectors to intelligently fuse these techniques, achieving both rich feature representation and low latency. In short, the line between "CNN-based" and "transformer-based" detectors will continue to blur, taking the best of both worlds to handle diverse detection challenges.
Lastly, as deployment remains a paramount concern, future research will likely emphasize edge-aware training and optimization. This means that model development will increasingly account for hardware constraints from the training phase onward, not just as an afterthought. Techniques such as quantization aware training where the model is trained with simulated low-precision arithmetic can ensure the network remains accurate even after being quantized to INT8 for fast inference. We may also see neural architecture search and automated model compression become standard in crafting YOLO models, so that each new version is co-designed with specific target platforms in mind. In addition, incorporating feedback from deployment, such as latency measurements or energy usage on device, into the training loop is an emerging idea. An edge-optimized YOLO could, for example, learn to dynamically adjust its depth or resolution based on runtime constraints, or be distilled from a larger model to a smaller one with minimal performance loss. By training with these considerations, the resulting detectors would achieve a superior trade-off between accuracy and efficiency in practice. This focus on efficient AI is crucial as object detectors move into IoT, AR/VR, and autonomous systems where real-time performance on limited hardware is non-negotiable.
Note: This study will experimentally evaluate YOLO26 by benchmarking its performance against YOLOv13, YOLOv12, and YOLOv11 in the near future. A custom dataset will be collected in agricultural environments using a machine vision camera, with 10,000 plus manually labeled objects of interest. Models will be trained under identical conditions, and results will be reported in terms of precision, recall, accuracy, F1 score, mAP, inference speed, and pre/post-processing times. Additionally, edge computing experiments on NVIDIA Jetson will assess real-time detection capacity, providing insights into YOLO26's practical deployment in resource-constrained agricultural applications.