时间:2023年9月4日
会议:AAAI
要解决的问题:针对LLM的数学推理能力,针对问题生成对抗样本问题
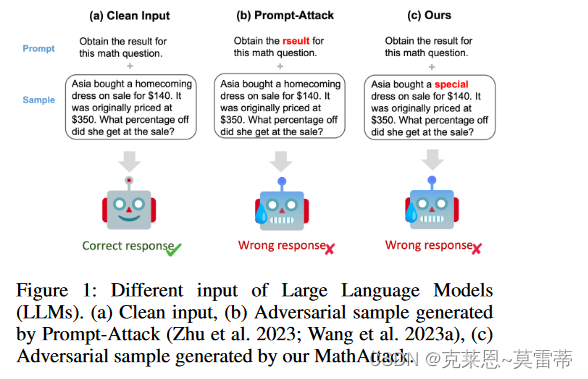
之前的对抗样本是针对prompt,这篇的对抗样本是针对问题
前提:已有文本对抗样本,但是,直接应用一般文本对抗攻击的技术往往会改变数学逻辑
什么意思呢?例如,如果图1(c)中的单词140被修改为另一个数字,则数学逻辑将被改变,并且标签(我们提前知道的标签答案)将不再是正确的答案。因此,保留 MWP 的数学逻辑至关重要,这使得 MWP 对抗性攻击更具挑战性。
方法:提出了 MathAttack 来攻击大型语言模型的数学求解能力
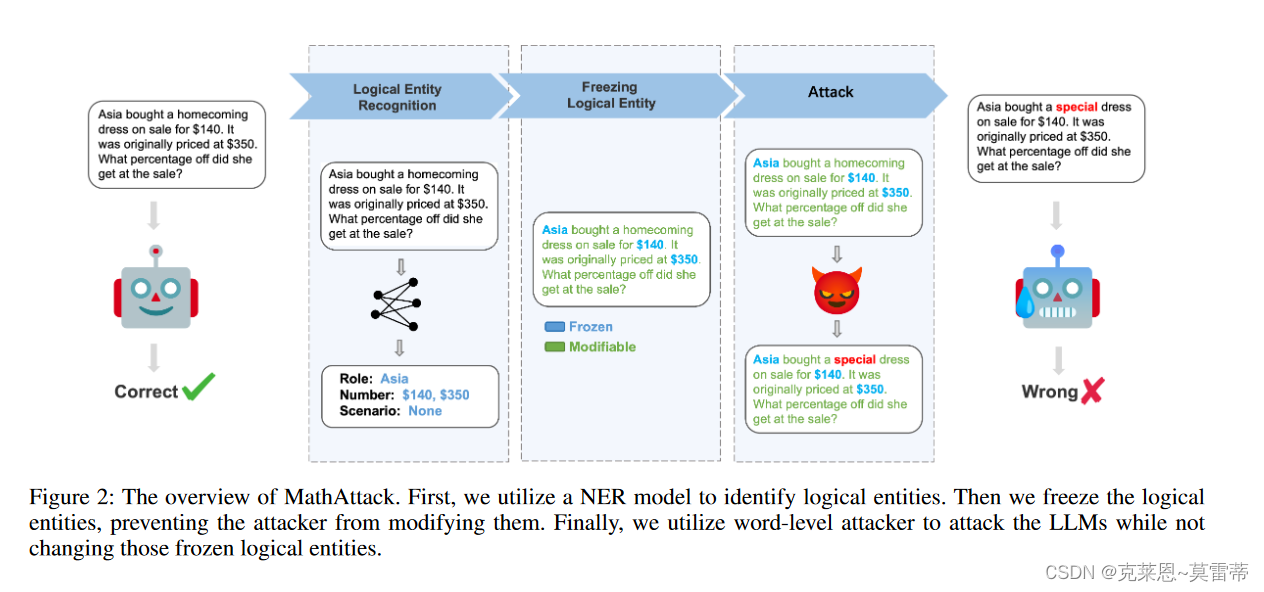
方法过程
目标定义:要对抗样本,逻辑实体相同,标签不同

- 与传统的文本攻击相比,数学应用题攻击需要保留文本样本x的数学逻辑L
- 语义要接近!!
最终目标函数
步骤
-
识别逻辑实体
- 定义为三类:
- role 实体
- Number实体
- Scenario 实体
- 用命名实体识别(NER)(Spacy 1 作为我们的 NER 模型)来识别它
- 定义为三类:
-
冻结逻辑实体
- 就是文本里这些被冻结的词不能被替换
- 文本攻击(BertAttack)
- 文本攻击者一般分为三类:char word sentence :
- 我们选择单词级攻击者是因为字符级攻击者可以扭曲单词的语义(如图1(b)),而句子级攻击者容易破坏MWP的数学逻辑。
- 发现易受攻击词
- 【x1,x2,x3...】每一个x都是一个词,将其依次mask如何送入LLM获得预测正确分数概率下降大小。它下降得越多,这个词就越重要
- 有一些词是给冻住的
 - 词替换
- 词替换 - 找到最重要的词后
- 查找最重要词的所有同义词,找到最像的

- 就是不断找到当前最重要的词然后找到所有同义词中最重要的依次去替换然后尝试
实验
受害者模型

数据集
GSM8K
MultiArith
只选择了简单的问题,删除了很难的问题
评估方法

结果
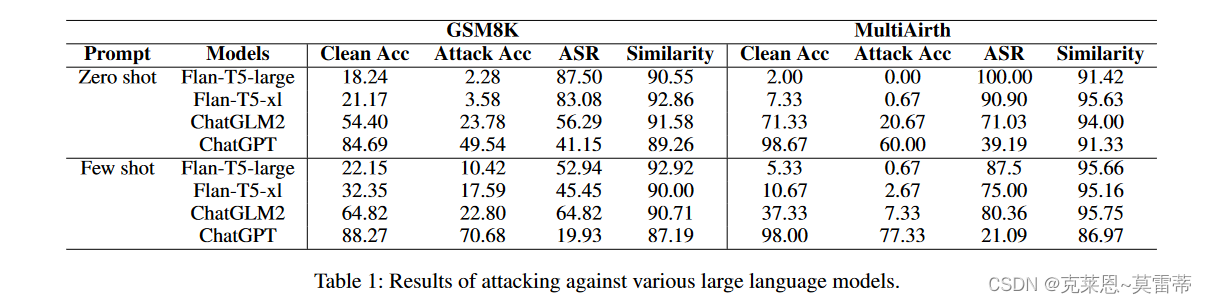
- LLM不同,ASR不同,chatgpt明显比FLAN强
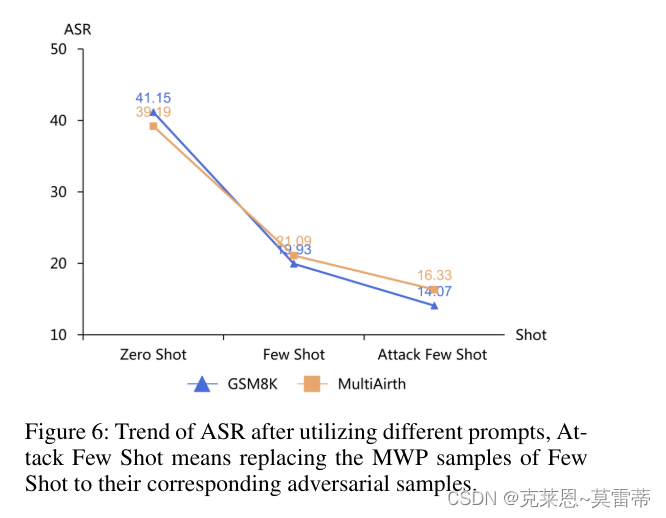
- 比较零样本和少样本,看到采用少样本可以增强LLM的数学求解能力,并使它们更加鲁棒,从而导致较低的 ASR
额外的工作
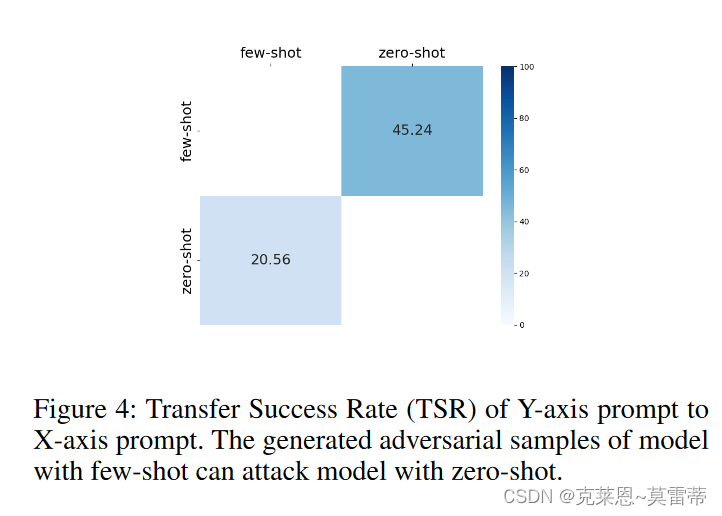
迁移性
选择B能够正确预测的样本作为实验样本。随后,向 B 提供通过攻击 A 的实验样本而生成的对抗性样本。
在这里,我们提出了一个指标:迁移成功率(TSR),如果 A 的对抗样本能够成功攻击模型 B,则意味着迁移成功。
模型大小
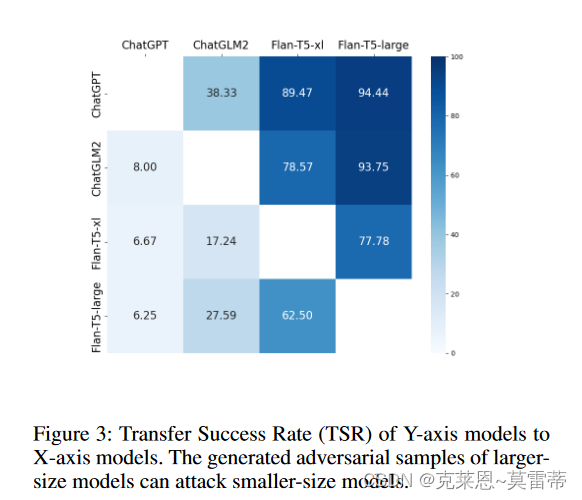
Y轴是A X轴是Bmodel
发现:从较高准确度的 LLM 生成的对抗性样本对于攻击较低准确度的 LLM 也很有效。较小尺寸模型的对抗样本无法攻击较大尺寸的模型
0样本 少样本
问题的研究
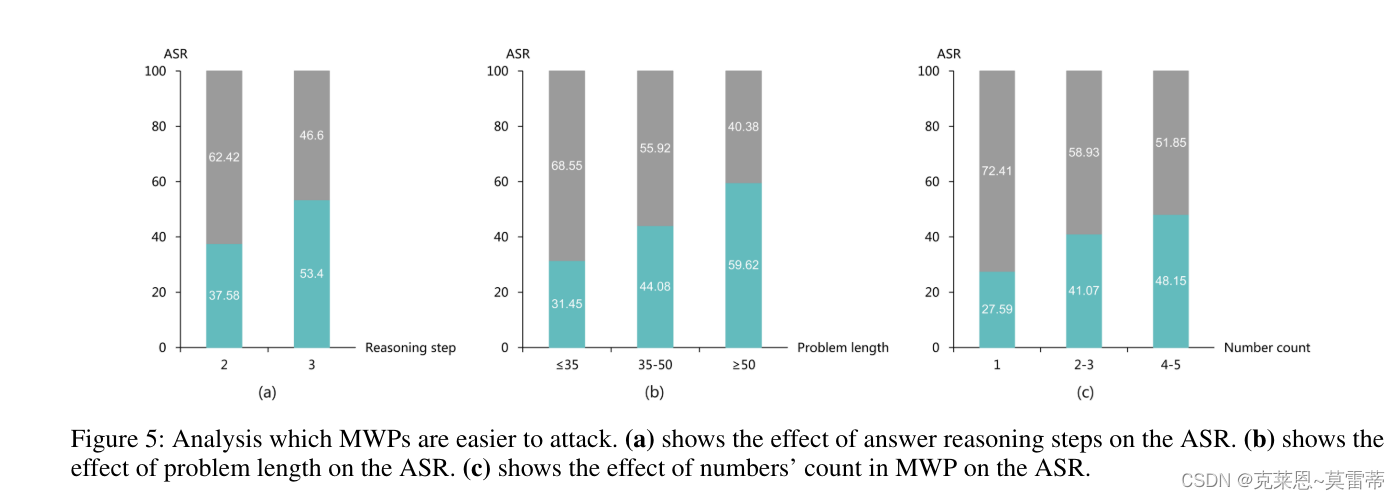
发现复杂的MWP(例如更多的求解步骤、更长的文本、更多的数字)更容易受到攻击
用对抗样本做prompt
一个例子

贡献:
-
MathAttack方法
-
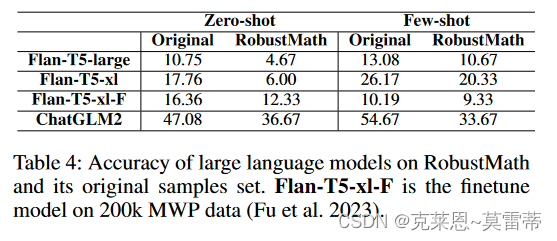
RobustMath数据集 300 个高质量 MWP 对抗样本,用来衡量LLM数学解决能力的稳健性。下图是这个数据集的效果
-
-
三个观察:
- 攻击样本的可传递性。从较高准确度的 LLM 生成的对抗性样本对于攻击较低准确度的 LLM 也很有效(例如,从较大规模的 LLM 转移到较小规模的 LLM,或从少样本提示转移到零样本提示);
- 复杂的MWP(例如更多的求解步骤、更长的文本、更多的数字)更容易受到攻击;
- 我们可以通过在少样本提示中使用我们的攻击样本来提高 LLM 的鲁棒性。
相关工作:
- 解决数学的方法:之前不同结构(树-图)到LLM推理
- LLM攻击:之前的工作针对LLM的prompt,这个针对问题
- MWP 求解器,之前的工作通过基于规则的方法生成一些 MWP 对抗示例,例如重新排序问题描述