在搜索场景的应用中,存在希望根据某个或某些字段来调整排序评分,从而实现排序沉底或置顶效果的使用需求。以商机管理中的扫街场景为例,当我们在扫街场景中需要寻找一个商户时,希望这个商户离的近、GMV 潜力大、被他人跟进过的次数越少越好。在策略上离的近在排序中的权重要比 GMV 潜力大更大,因为我们希望就近拜访,在距离差不多的情况下优先拜访能带来更多 GMV 的商家。
-
如果这个商家是一个"激励商家"且高转化意愿,可能需要对这样的商家在排序上做置顶;
-
如果这个商家已经被其他人重复开发过了,那这样的商户开发成本就会比较大,被他人跟进的次数越多,排序应该更靠后,所以就需要实现沉底的效果。
下文将介绍 ES 所能够支持的丰富多样的排序能力,以及不同排序能力所具体适用的场景。
提升查询权重 - Boost
在查询时使用 Boost 参数能让一个查询语句比其他语句更重要。所以在相对简单的场景下,用这种方式可以实现低改动成本、快速变更。在这里需要注意的是任何类型的查询都能接受 Boost 参数,Boost 只是对 _score 的一个影响因子,将 Boost 参数设置为2,并不代表 _score 是原来的 2 倍。当没有显示设置 Boost 时,默认值为 1。
GET /_search
{
"query":{
"bool":{
"should":[
{
"match":{
"title":{
"query":"elastic search",
"boost": 2
}
}
},
{
"match":{ 2
"content":"elastic search"
}
}
]
}
}
}修改查询相关度 - 组合查询
查询场景:要查询文档中包含 Elasticsearch or (Golang or Go) or function_score 的文档。
GET /_search
{
"query":{
"bool":{
"should":[
{"term":{"content":"elasticsearch"}},
{"term":{"content":"Golang"}},
{"term":{"content":"Go"}},
{"term":{"content":"function_score"}}
]
}
}
}虽然上述查询能把只要包含了 or 条件中的所有文档都查询出来,而且每个条件的重要程度都一样。但实际 Golang or Go 是一个组合条件,和其他 2 个条件是并列的关系,所以下面是更好的写法。
用 Bool 查询把 Golang or Go 包起来,这样现在的 Golang or Go 跟其他两个条件就处于顶层相互竞争的关系了。原来每个词的重要性是 25%,现在 Elasticsearch 和 function_score 重要性各占 33.3%, Golang or Go 加起来占 33.3%。
GET /_search
{
"query":{
"bool":{
"should":[
{ "term":{"content":"elasticsearch"}},
{ "term":{"content":"function_score"}},
{
"bool":{
"should":[
{"term":{"content":"Golang"}},
{"term":{"content":"Go"}}
]
}
}
]
}
}
}排序沉底 - Boosting 查询
查询场景:文档中要包含 Elasticsearch,但不希望包含 MySQL。
- 方案一:使用must_not
在这个方案里使用的 must_not 过于严格,会把包含了 MySQL 的文档排除出去。但如果一个文档中包含了很多 Elasticsearch,只是恰好包含了一个 MySQL,那就错过了一个"好"的文档。
GET /_search
{
"query":{
"bool":{
"must":{
"match":{
"content":"elasticsearch"
}
},
"must_not":{
"match":{
"content":"mysql"
}
}
}
}
}- 方案二:用 Boosting 查询
通过正向查询确定希望文档匹配哪些内容;在负向查询中,文档如果匹配了这些内容,那么对 _score 需要减分。减分的权重由 negative_boost 来控制,是一个 0-1 的数值。最终的评分 new_score = 正向查询的score * negative_boost。
GET /_search
{
"query":{
"boosting":{
"positive":{
"match":{
"content":"elasticsearch"
}
},
"negative":{
"match":{
"content":"mysql"
}
},
"negative_boost":0.8
}
}
}多查询评分一致 - constant_score 查询
某些场景下,我们可能并不关心 TF/IDF,只关心这个词是否在文档中出现过,比如出差找一个酒店,希望尽可能有如下设施:WIFI、Gym(健身房)、Breakfast(早餐)。
- 方案一:match 查询
这种查询,实际还是用 TF/IDF,会整体去考虑这些词在酒店描述中出现的是否频繁。但实际用户可能并不关心出现是否频繁,只关心这些设施是否尽可能包含了,且包含得越多越好。
GET /_search
{
"query":{
"match":{
"hotel_desc":"WIFI Gym Breadfast"
}
}
}- 方案二:constant_score 查询
通过 constant_score查询,酒店描述中匹配了一个设施评分就进行 +1,设施匹配的越多评分就越高。但不会因为在酒店描述中多次提到 WIFI 评分就提升,因为每个设施的评分最多也只有 1 分。但可能每个设施的重要程度不一样,有些设施更有价值,那么我们就可以为不同的设施增加不同的权重。而给每个权重设置查询权重就是最前面讲的 Boost 参数。
GET /_search
{
"query":{
"bool":{
"should":[
{
"constant_score":{
"query":{
"match":{
"hotel_desc":"WIFI"
}
}
}
},
{
"constant_score":{
"query":{
"match":{
"hotel_desc":"Gym"
}
},
"boost":2
}
},
{
"constant_score":{
"query":{
"match":{
"hotel_desc":"Breakfast"
}
}
}
}
]
}
}
}constant_score 查询的更多应用
上文 Boosting Query 中提到 negative_boost 可以降低原来的评分,但如果 Positive正向查询中用的是 Filter 查询,在根本就没有评分的情况下,可以把 Filter 查询改为 Term 或 Match 查询,但是对于只要过滤不需要评分的查询,比如过滤价格的查询,应该尽可能用 Filter 查询,可利用缓存、跳过评分,执行速度更快。这个时候,也可以用 constant_score 把 Filter 查询包含进去。
GET /_search
{
"query":{
"boosting":{
"positive":{
"constant_score":{
"filter":{
"term":{
"price":50
}
}
}
},
"negative":{
"match":{
"content":"mysql"
}
},
"negative_boost":0.8
}
}
}控制评分的终极武器 - function_score 查询
function_score 查询最适用的场景:一个正向影响因子,一个负向影响因子,比如跟 votes(投票数)和 date(日期)结合起来,投票数越高的越排前面,日期越早的越排后面。
基本概念:
-
**weight:**为每个文档应用一个简单而不被规范化的权重提升值:当 weight 为 2 时,最终结果为 2 * _score。
-
**field_value_factor:**使用这个值来修改_score,如将 votes 热度作为考虑因素。
-
**random_score:**为每个用户都使用一个不同的随机评分对结果排序,但对某一具体用户来说,看到的顺序始终是一致的。
-
衰减函数 - linear、 exp 、gauss:将浮动值结合到评分_score中,例如结果文档的最新发布时间,结合经纬度的距离,给文档一个综合评分。
-
**script_score:**如果需求超出以上函数能够支持的范围,可以自定义脚本来控制评分。
按热度提升权重
查询场景:POI 查询,希望将 POI 在抖音的搜索热度高的排在前面,同时根据 POI 名字全文搜索时,作为主要的排序依据。
用 function_score 包含主查询和函数,fields_value_factor 函数会被应用到每个被主查询查出来的文档上,每个文档的 douyin_hot 字段必须有值供函数计算,如果没有必须使用 missing 属性来提供默认值。
如此配置后,每个文档的最终评分 _score 修改为:new_score = old_score * number_of douyin_hot,这个结果其实是不符合预期的,因为抖音热度的值一般很大,会完全覆盖掉原来的评分。
GET /_search
{
"query":{
"function_score":{
"query":{
"match": {
"query":"烧烤",
"fields":"poi_name"
}
},
"field_value_factor":{
"field":"douyin_hot",
"missing": 0
}
}
}
}Modifier 函数
其中一种优化方式是使用 Modifier 来平滑 douyin_hot 的值,比如热度 0 和热度 1 的差别应该比热度 100 和热度 101 的差别更大,这里可以应用 modifier: "log1p",实际含义是:new_score = old_score * log( 1 + number of douyin_hot )。Modifier 可选的值有:**none(默认状态)、log、log1p、log2p、ln、ln1p、ln2p、square、sqrt、reciprocal。**如下图,使用 Modifier: log1p 后评分曲线就会平缓很多。
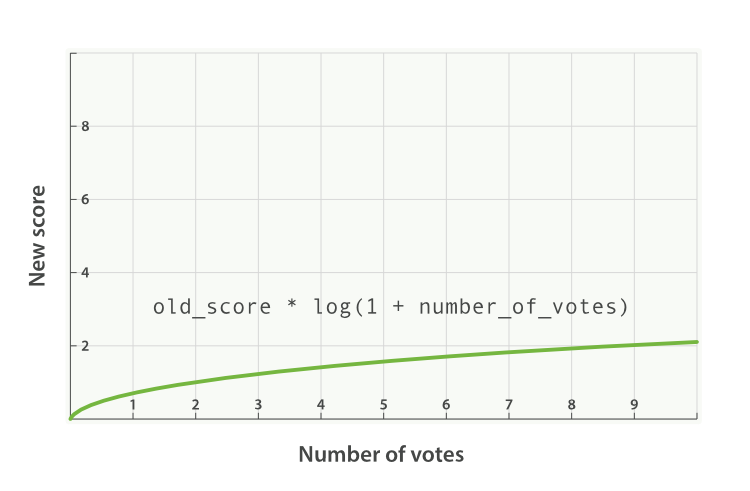
Factor 调节因子
上面通过 Modifier 平滑了 douyin_hot 的值,如果仍然认为辅助因子的影响力不够,曲线过于平缓,那就可以通过 Factor 进行调节。添加了 Factor 后,得到的结果是双倍效果,评分如下:new_score = old_score * log ( 1 + factor * number of douyin_hot )。
GET /_search
{
"query":{
"function_score":{
"query":{
"match": {
"query":"烧烤",
"fields":"poi_name"
}
},
"field_value_factor":{
"field":"douyin_hot",
"missing": 0,
"modifier":"log1p",
"factor":2
}
}
}
}Boost_mode 权重模式
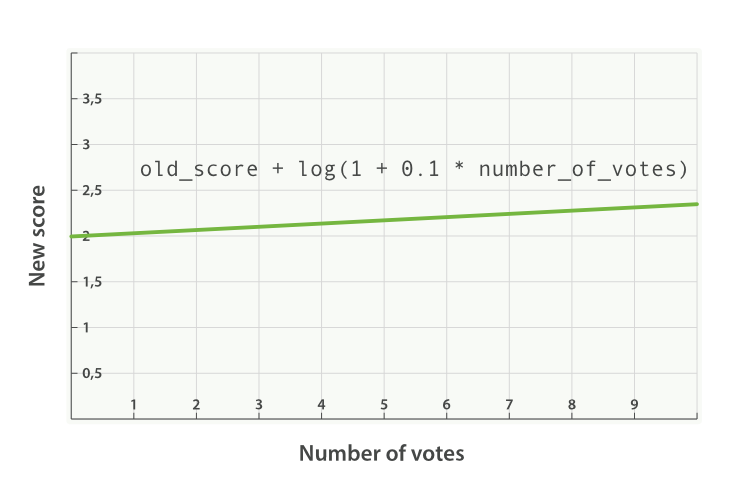
上面在算 new_score 时,都是在 old_score 的基础上乘一个值,如果这个值还是很大评分就会放大很多。因此可以通过 boost_mode 来控制新老分数的结合方式。通过下图可以看到用加和的评分结合方式,评分曲线就会平滑很多。
-
multiply:乘积,默认方式, new_score = old_score * 函数值。这个方式很容易放大老的评分。
-
sum:加和,new_score = old_score + 函数值。这是比较常用的方式。
-
min:取较小值,new_score = min(old_score, 函数值)。
-
max:取最大值。
-
replace:函数值代替 old_score。
Max_boost 权重上限
限制函数的最大效果是起到一个保护的作用,避免辅助评分太高完全压过主查询的评分。这里不管field_value_factor 如何进行计算,函数值最大不会超过 1.5,由此就起到一个保护的作用。
GET /_search
{
"query":{
"function_score":{
"query":{
"match": {
"query":"烧烤",
"fields":"poi_name"
}
},
"field_value_factor":{
"field":"douyin_hot",
"missing": 0,
"modifier":"log1p",
"factor":2
},
"boost_mode":"sum",
"max_boost":1.5
}
}
}越接近越好 - 衰减函数
使用场景:以选择酒店为例,用户可能会考虑远近、价格,如果位置在景区里而且价格也可以接受,那也在选择范围内;如果位置离游玩的位置近,差价可以抵平路途使用的钱,这也是可以选择的。所以酒店的排序,不会是单一维度的,很多都是"智能"排序的。function_score 提供了衰减函数使我们可以在多个维度之间做出权衡。
有三种衰减函数 - Linear 线性、Exp 指数、Gauss 高斯,可以操作数值、时间、经纬度,接受如下参数:
-
origin:中心点或最佳值,落在 origin 上,评分为 1.0。
-
offset:以原点为中心,设置一个非零的偏移量 Offset 覆盖一个数值范围,在这个范围内,评分都是 1.0。
-
scale:衰减率,即一个文档远离 origin-offset, origin+offset 范围时,评分改变的速度。
-
decay:从 origin 衰减到 scale 位置时,评分的值,默认是 0.5。
- 如下图,origin 是 40,offset 是5,scale 也设置为 5,decay=0.5,标识当值偏移到 origin - offset - scale, origin + offset + scale 时,评分 = decay = 0.5,这样就决定了曲线的陡度。
GET /_search
{
"query": {
"function_score":{
"functions":[
{
"gauss":{
"location":{
"origin":{"lat":10.1, "lon":0.11},
"offset":"1km",
"scale":"2km"
}
}
},
{
"gauss":{
"price":{
"origin":"200",
"offset":"50",
"scale":"30"
}
},
"weight":2
},
]
}
}
}总结
通过以上介绍我们可以了解到 ES 可支持的排序能力还是非常丰富的,我们要实现置顶或沉底效果,并不能非黑即白的选择,更多的场景中需要根据实际需要做多个能力的组合,尽管 function_score 表现优异,但越复杂的查询对 ES 的查询压力也越大,当数据量很大时必须要权衡性能和排序效果。上线前,也需要在仿真环境中验证大数据量下的性能表现。