23年12月,上海交通大学、国防科技大学、北京工业大学联合发布Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications。
本文提出了一种仅摄像机4D占用预测的新基准Cam4Occ,利用现有nuScenes、nuScenes-Ocuplication 和 Lyft-Level5数据集构建。同时,引入了一种新的端到端时空网络OCFNet,其接收过去连续环视摄像头图像来预测当前和未来4D占用状态。它利用多帧特征聚合模块提取3D体素特征;利用未来状态预测模块,预测未来占用和后向向心流。
实验证明,端到端时空网络OCFNet可能是仅摄像头4D占用预测最有前途的研究方向。
数据集和代码已经开源:https://github.com/haomo-ai/Cam4DOcc.
Abstract
了解周围环境的变化对于在自动驾驶应用中安全可靠地执行下游任务至关重要。最近仅使用摄像机图像作为输入的占用估计技术可以提供基于当前观测的大规模场景的密集占用表示。然而,它们大多局限于表示当前的3D空间,没有考虑周围物体沿时间轴的未来状态。为了将仅摄像机占用估计扩展到时空预测,我们提出了Cam4Occ,这是一种用于仅摄像机4D占用预测的新基准,用于评估在不久的将来周围场景变化。我们基于多个公开可用数据集构建我们的基准,包括 nuScenes、nuScenes-Ocuplication 和 Lyft-Level5,它提供了一般可移动和静态对象的时序占用状态,以及它们的 3D 后向向心流。为了通过综合比较为未来的研究建立基准,我们从不同基于摄像机感知和预测实现中引入了4种基线类型,包括静态世界占用模型、点云体素化预测、基于2D-3D实例预测以及我们新提出的端到端4D占用预测网络。此外,还提供了预设多个任务的标准化评估协议,比较4种基线在目前和未来占用估计方面的性能,以应对自动驾驶场景中感兴趣的对象。
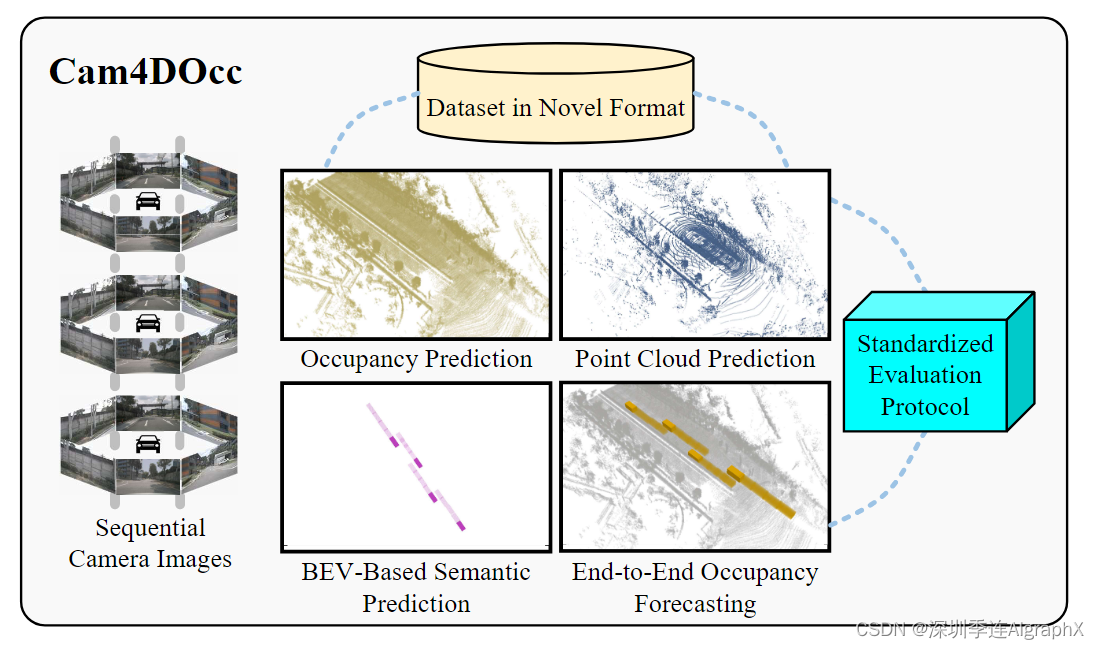
Fig. 1: Cam4DOcc focuses on providing a novel dataset format,creating four baselines and proposing a standardized evaluation protocol for the 4D occupancy forecasting task.
I. INTRODUCTION
利用摄像头准确感知周围环境中物体的状态,对于自动驾驶汽车或机器人做出合理的下游规划和行动决策至关重要。传统的基于摄像头的物体检测方法,如语义分割以及全视分割侧重于预定义的特定物体类别,因此在识别不常见物体时效果较差。为了解决这一限制,出现了一种转向基于摄像机的占用估计,通过对特定物体分类来估计空间占用状态。该方法降低了多类任务的复杂性,强调了总体占据状态估计,提高了自动驾驶系统的可靠性和自适应性。
尽管基于摄像机的占用估计越来越受到关注,但现有的方法只能估计当前和过去的占用状态。然而,自动驾驶汽车采用的先进避碰和轨迹优化方法要求具有预测未来环境条件的能力,以确保驾驶的安全性和可靠性。有些方法提出了一些语义/实例预测算法来预测感兴趣的物体运动,但它们大多局限于2D鸟瞰(BEV)格式,只能识别特定的物体,主要是车辆类别。现有的占用率预测算法在不考虑语义的情况下,需要LiDAR点云作为必要的先验信息来感知周围的空间结构,而基于LiDAR的解决方案比摄像机的解决方案更耗费资源,成本更高。很自然地,自动驾驶的下一个重大挑战将是仅靠摄像头的4D暂用预测。该任务不仅旨在扩展以摄像机图像为输入的时间占用预测,而且还将语义/实例预测扩展到BEV格式和预定义类别之外。为此,我们提出了Cam4DOcc,如图 1 所示,这是第一个仅摄像机的4D占用预测基准,包括新的数据集格式,各种类型的基线和标准化的评估协议,以促进这一新兴领域的发展。在本基准测试中,我们通过从原始的nuScenes、nuScenes- occupancy和Lift-Level5中提取沿时间轴的连续占用变化来构建数据集。该数据集包括时序语义、实例标注,以及指示占用网络运动的3D后向向心流。此外,为了实现基于摄像机的4D占用预测,我们引入了四种基线方法,包括静态世界占用率模型、点云体素化预测、2D-3D实例预测和端到端4D占用预测网络。最后,我们提出一个标准化协议来评估这些基线方法在当前和未来占用估计中的性能。
本文的主要贡献有四个方面:
- 提出了第一个基于摄像机的4D占用预测基准Cam4DOcc,为未来预测工作提供了便利。
- 利用该领域现有数据集,提出了一种新的自动驾驶场景预测数据集。
- 为基于摄像机的4D占用预测提供了四种新基线。其中三个是现成方法的扩展。此外介绍了一种新颖的端到端4D占用预测网络OCFnet,该网络具有较强的性能,可以为未来的研究提供有价值的参考。
- 引入了一种新的标准化评估协议,并在该协议的基础上用Cam4Occ进行了全面的实验和详细的分析。
II. RELATED WORK
Occupancy prediction
**Occupancy prediction占用率预测/估计是一种综合估计周围环境占用状态的新兴技术。**用几何细节来表现空间,大大增强了复杂场景的表现力。MonoScene首先解决了来自摄像机图像的3D场景语义补全问题,但只考虑了前视体素。相比之下,TPVFormer代替MonoScene的Feature Line of Sight Projection,提高了基于交叉注意机制的环视占用预测的性能。UniOcc将基于体素的神经辐射场(NeRF)与占用预测相结合,实现几何和语义渲染。OpenOccupancy建立了具有高分辨率占用地面真值nuScenes-Occupancy数据集,并进一步使用不同模式提供了几个基线。OpenOcc提出了另外一种占用预测基准,并将其估计的占用用于各种任务,包括语义场景补全、3D物体检测、BEV分割和运动规划。最近,Occ3D利用遮挡推理和图像引导细化来进一步提高标注质量。与OpenOcc类似,SurroundOcc也产生密集占用标签,并利用空间注意力将2D摄像机特征重新投影回3D Volumes。
Occupancy forecasting
**Occupancy forecasting占用率预测是用来预测在不久的将来周围的占用是如何变化的。**现有的占用预测方法主要使用LiDAR点云作为输入来捕捉周围结构的变化。例如,Khurana等人提出了一种可微分光线投射方法,通过姿态对准的激光雷达扫描来预测2D占用状态。最近,Point Cloud Forecasting as a Proxy for 4D Occupancy Forecasting提出用估计的占用渲染未来伪激光点云。其他点云预测方法直接预测未来的激光点云,可以体素化到未来的占用估计。然而,它们仍然需要连续的激光点云,并且在预测过程中失去语义一致性。与上述基于Lidar的占用预测相比,仅使用大规模场景中的摄像机图像直接预测未来具有多个语义类别的3D占用仍然具有挑战性。因此,一些仅摄像头的语义/实例预测方法转向预测感兴趣物体的运动,例如,基于2D BEV占用表示的一般车辆类别。例如FIERY直接从多视图2D摄像机图像中提取BEV特征,然后结合时间卷积模型和递归网络来估计未来的实例分布。在此之后,提出了StretchBEV、BEVerse,以便在更长的时间范围内进一步增强。针对具有冗余输出的过度监督,最近提出的PowerBEV提高了预测的准确性和效率。
以上方法不能直接实现仅摄像头的4D占用预测任务。针对这个主题,我们提出了一个新基准。其中通过转换现有的最先进的占用预测、点云预测和基于BEV的语义/实例预测算法的实现来创建几个基线。此外,我们开发了一种新颖的基于摄像头的4D占用预测网络,可以端到端地同时预测一般可移动和静态物体的未来占用状态。最后,提出了标准化的数据集格式和评估协议来训练和测试所有基线,这可以进一步支持本文献的未来工作。
III. CAM4DOCC BENCHMARK
Task Definition

Cam4DOcc考虑了两类运动特征,一般可移动对象(GMO)和一般静态对象(GSO),作为被占用体素网格的语义标签。与GSO相比,GMO通常具有更高的运动特性,因此出于安全考虑,在交通事故中需要更多的Attention。
准确估计GMO的行为并预测其潜在的运动变化对自车决策和运动规划有重要影响。与之前考虑多个语义类别的语义场景补全任务相比,我们更侧重于研究可移动物体体素状态的持续变化,因为我们认为在自动驾驶应用的背景下,交通参与者的运动特征值得更多关注。相较于现有的语义/实例预测任务,我们不仅强调对相邻前景目标的预测,而且注重对周围环境背景的占用估计,以满足自动驾驶汽车更可靠的导航需求。
Dataset in New Format
Cam4DOcc基准引入了一种基于原始nuScenes、nuScenes- occupancy和Lyft-Level5的新数据集格式。

Fig. 2: Overall pipeline of constructing dataset in our Cam4DOcc based on the original nuScenes and nuScenes-Occupancy. The dataset is reorganized into a novel format that considers both general movable and static categories for the unified 4D occupancy forecasting task.
如图 2 所示:
首先将原始nuScenes数据集(同样操作也适用于Lift-Level5数据集)拆分为时间长度为N = Np + Nf + 1的序列。然后为每个序列提取可移动对象的时序语义和实例标注,并将其收集到GMO类中,包括自行车、公共汽车、汽车、建筑、摩托车、拖车、卡车和行人。它们都被转换为当前的坐标系 (t = 0)。
其次,我们对当前的3D空间进行体素化,并使用边界框标注将语义/实例标签附加到可移动对象的网格上。值得注意的是,无效实例在此过程中被丢弃:(1)在6个相机图像中的可见度低于40%,如果它是在Np个历史帧中新出现的对象。(2)首次出现在Nf个传入帧中,或者(3)超出了在t = 0时预定义的范围(H, W, L)。可见性通过在相机图像中显示实例的所有像素可见比例来量化。基于等速假设,利用时序标注来填补缺失的中间实例。
最后,我们使用标注中的实例关联生成3D后向向心流。PowerBEV为了提高2D实例预测的效率,引入了2D后向心流。受此启发,我们计算了从 t 时刻体素指向 t−1 时刻对应3D实例中心的3D后向向心流。我们利用这种3D流来提高基于摄像头4D占用率预测的准确性。
我们的目的不仅是预测未来GMO的位置,而且估计GSO的占用状态和安全航行所需的自由空间。因此,我们进一步将来自原始nuScenes的时序实例标注与从nuScenes- occupancy转换到当前帧的时序占用标注连接起来。这种组合平衡了自动驾驶应用中下游导航的安全性和精度。GMO标签借鉴了原始nuScenes的边界框标注,可以看作是对可移动障碍物进行了扩展操作。nuScenes-Occupancy提供GSO和空域标签,专注于周围大尺度环境中更细粒度的几何结构。
Evaluation Protocol
为了充分获取仅摄像头的4D占用预测性能,我们在Cam4DOcc中建立了各种复杂程度不同的评估任务和指标。
Multiple tasks
在标准化评价方案中引入4个级别占用预测任务:
(1)预测扩展的GMO:将所有占用网格类别划分为GMO和其他,其中nuScenes和LyftLevel5的实例边界框内的体素网格标注为GMO。
(2)预测细粒度GMO:类别也分为GMO和其他,但GMO的标注直接来自第3.2节引入的nuScenes-Occupancy体素标记,去除无效网格。
(3)预测扩展的GMO、细粒度GSO和自由空间:将类别分为边界框标注的GMO、细粒度标注后的GSO和自由空间。
(4)预测细粒度GMO、细粒度GSO和自由空间:将分类分为细粒度标注后的GMO和GSO,以及自由空间。由于Lift-Level5数据集缺少占用标签,我们只对其进行第一个任务的评估。
Metrics
对于所有四个任务,我们使用 intersection over union (IoU) 作为性能指标。我们分别评估当前时刻 t = 0 占用估计和未来时间 t∈1,Nf 预测。

我们还提供单一的定量指标来评估整个时间范围内的预测性能,计算如下:

靠近当前时刻时间戳的 IoU 对最终Io ̃Uf 的贡献更大。这与在接近时间戳的占用预测对于后续的运动规划和决策更为关键的原则是一致的。
Baselines
我们提出了四种方法作为Cam4DOcc的基线,以帮助未来对仅相机的4D占用预测任务进行比较,如图 3 所示。

Static-world occupancy model
现有的基于摄像头的占用率预测方法只能根据当前观测值估计当前占用率网格。因此,最直接的基线之一是假设环境在很短的时间间隔内保持静态。因此,我们可以使用当前估计的占用网格作为基于静态世界假设的所有未来时间步长的预测,如图 3a。
Voxelization of point cloud prediction点云预测的体素化
另一种类型的基线可以是占用网格体素化,基于现有点云预测方法的结果。在这里,我们使用环视图深度估计来生成跨多个摄像机的深度图,然后使用光线投射来生成3D点云,并将其与点云预测相结合来获得预测的未来伪点。在此基础上,我们应用基于点云语义分割来获取每个体素的移动和静态标签,从而得到最终的占用率预测,如图 3b。
2D-3D instance-based prediction
许多现成的基于2D BEV的实例预测方法都可以用环视相机图像预测未来语义。第三类基线是通过沿 z 轴将BEV占用网格复制到车辆高度来获得3D空间中预测的GMO,如图3c所示。可以看出,该基线假设驾驶表面是平坦的,所有运动物体的高度相同。我们没有对预测GSO的基线进行评估,因为与GMO相比,通过复制来提高2D结果不适合模拟具有更复杂结构的大规模背景。
End-to-end occupancy forecasting network
以上基线均不能直接预测3D空间的未来占用状态。它们都需要基于某些假设进行额外的后处理,将现有结果扩展和转换为4D占用率预测,这不可避免地会引入固有的伪影。为了填补这一空白,我们提出了一种如图 3d 所示的新方法,以端到端方式实现仅摄像头的4D占用率预测,下一章将详细介绍。
IV. END-TO-END 4D OCCUPANCY FORECASTING
据我们所知,现有的仅摄像头4D占用率预测基线无法同时预测未来占用并以端到端方式提取3D通用对象。在本文中,我们介绍了一种新的端到端时空网络,称为OCFNet,如图 4 所示。OCFNet接收过去连续环视摄像头图像来预测现在和未来占用状态。它利用多帧特征聚合模块提取 Warped 3D 体素特征;利用未来状态预测模块,预测未来占用和3D后向向心流。

Multi-Frame Feature Aggregation Module
多帧特征聚合模块以过去的环视相机图像序列作为输入,利用图像编码器骨干网络提取二维特征。这些2D特征随后被2D-3D lifting module提升并集成到3D体素特征中。所有生成的3D特征体通过应用6自由度 6-DOF Ego-Car姿态转换到当前坐标系,得到聚合特征 Fp∈R*(Np +1)c×h×w×l* 。在这里,我们将时间和特征维度折叠成1D维度来实现3D时空卷积。随后,我们将其与相邻帧之间的 6-DOF Ego-Car姿态连接起来,从而得到运动感知特征Fpm∈R*(Np +1)(c+6)×h×w×l*。
Future State Prediction Module
未来状态预测模块future state prediction module以运动感知特征Fpm作为输入,使用两个头同时预测未来占用率和网格运动。

在这里,我们需要根据第3.3节中描述的评估方案同时估计当前和预测未来通用对象的语义占用率。此外,OCFNet除了预测占用率外,还将3D向心流预测为空间内的网格运动,可用于实现实例预测。
Loss function
我们使用交叉熵损失作为占用预测Locc损失,并使用平滑L1距离作为流量预测Lflow损失。我们也采用了显式深度损失Ldepth,但这里只是为了监督当前占用(t = 0),以提高训练效率,减少内存消耗。训练OCFNet的总损失为

其中 ^D0, D0 分别是由2D-3D提升模块估计的深度图像和从激光雷达数据真值范围的图像投影。
λ1、λ2和λ3是用于平衡占用率预测、流量预测和深度重建优化的权重。
V. EXPERIMENTS ON CAM4DOCC
使用提出的Cam4DOcc基准,我们评估了所提出基线的占用估计和预测性能,包括我们的OCFNet,用于自动驾驶场景中的四个任务。
Experimental Setups
遵循OpenOccupancy,我们在nuScenes和nuScenes- occupancy数据集中使用了850个场景中的700个带有ground-truth标注,在Lift - Level5中使用了180个场景中的130个来训练提出的基线和我们的OCFNet。剩下的场景用于评估。我们的基准中每个序列的长度N设置为7 (Np = 2, Nf = 4),这意味着我们使用3个观测值,包括当前的观测值,来预测4个未来时间步长的占用。由于nuScenes的标注频率为2hz,而Lift - Level5的标注频率为5hz,因此我们报告了不同时间间隔的预测性能。每个序列的预定义范围设置为x轴和y轴-51.2 m, 51.2 m, z轴-5 m, 3 m。体素分辨率为0.2 m,每个序列在当前坐标系下的占用网格尺寸为512 × 512 × 40。我们的Cam4DOcc基准数据重组后,nuScenes和nuScenes- occupancy的训练和测试序列数分别为23930和5119,Lift - Level5的训练和测试序列数分别为15720和5880。
4D Occupancy Forecasting Assessment
Evaluation on forecasting inflated GMO

Evaluation on forecasting fine-grained GMO

Evaluation on forecasting inflated GMO, fine-grained GSO, and free space

Evaluation on forecasting fine-grained GMO, finegrained GSO, and free space

Ablation Study on Multi-Task Learning

VI. CONCLUSION
在本文中,我们提出了一个新的基准,即Cam4DOcc,用于自动驾驶应用中仅摄像头的4D占用预测。具体来说,我们首先基于几个公开可用的数据集建立了新格式的设计数据集。在此基础上,进一步提出了标准化的评估方案和四种类型的基线,为我们的Cam4DOcc基准测试提供基础参考。此外,我们提出了第一个基于摄像头的4D占用率预测网络OCFNet,以端到端方式估计未来的占用状态。基于我们的Cam4DOcc基准进行了四种不同任务的多次实验,以彻底评估提出的基线以及我们的OCFNet。实验结果表明,OCFNet优于所有基线,即使使用有限的训练数据,仍然可以产生合理的未来占用。
见解:通过比较四种不同类型的基线,我们证明了端到端时空网络可能是仅摄像头占用预测最有前途的研究方向。此外,利扩展的GMO标注和额外的3D向心流也被证实有利于4D占用预测。
局限性和未来的工作:虽然OCFNet已经取得了显著的成果,但仅靠相机进行4D占用预测仍然具有挑战性,特别是在预测长时间间隔的许多移动物体时。我们的Cam4DOcc基准和综合分析旨在增强对当前占用感知模型的优势和局限性的理解。我们将这个基准作为一个有价值的评估工具,OCFNet可以作为未来4D占用预测任务研究的基础代码库。
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删,转发请注明出处。