节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
SAM(Segment Anything Model),顾名思义,即为分割一切!该模型由Facebook的Meta AI实验室,能够根据文本指令或图像识别,实现对任意物体的识别与分割。它的诞生,无疑是CV领域的一次重要里程碑。

论文地址:https://arxiv.org/abs/2304.02643
项目地址:https://github.com/facebookresearch/segment-anything
SAM Task
SAM借鉴了NLP领域的Prompt策略,通过给图像分割任务提供Prompt提示来完成任意目标的快速分割。Prompt类型可以是**「前景/背景点集、粗略的框或遮罩、任意形式的文本或者任何指示图像中需要进行分割」**的信息。如下图(a)所示,模型的输入是原始的图像和一些prompt,目标是输出"valid"的分割,所谓valid,就是当prompt的指向是模糊时,模型能够输出至少其中一个mask。
这样,可以是的SAM能够适配各种下游任务。例如,给定一个猫的边界框,SAM能够输出其mask,从而和实例分割任务搭配起来。

SAM Model
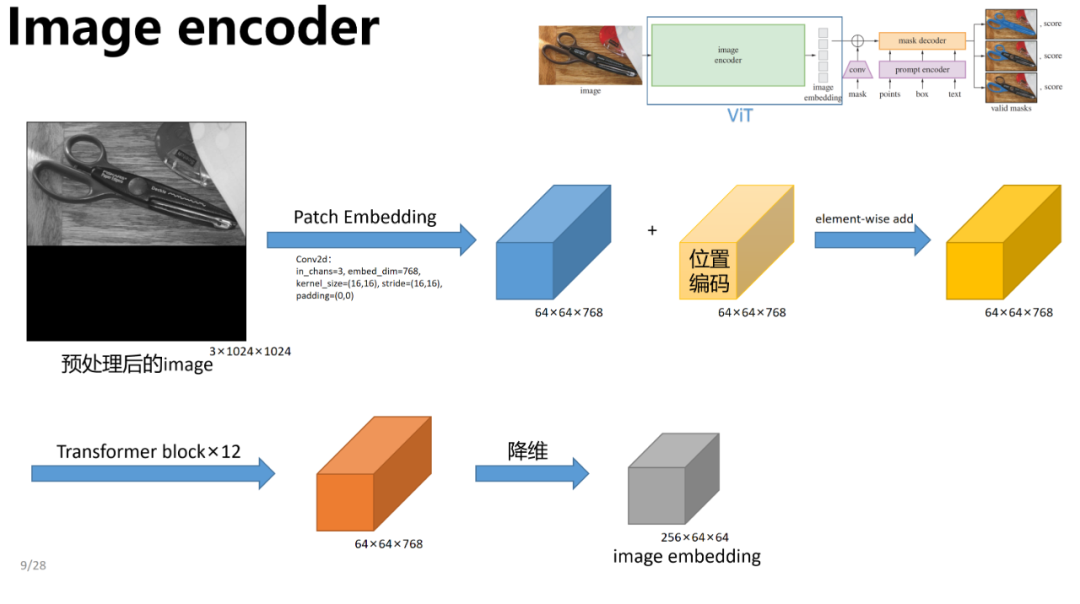
如下图所示,SAM模型包含三个核心组件,Image Encoder、Prompt Encoder和Mask Decoder。图像经过Image Encoder编码,Prompt提示经过Prompt Encoder编码,两部分Embedding再经过一个轻量化的Mask Decoder得到融合后的特征。其中,Encoder部分使用的是已有模型,Decoder部分使用Transformer。
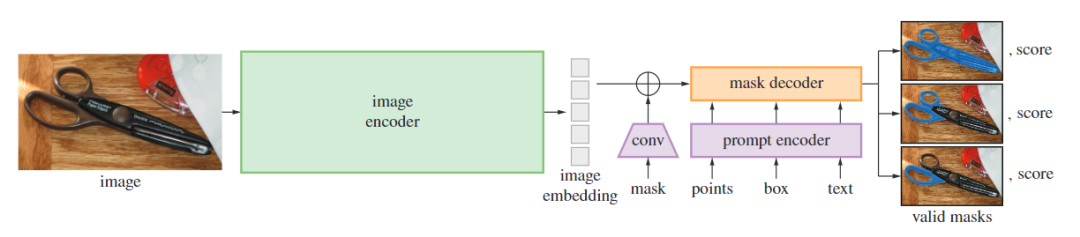
Image Encoder
Image Encoder的作用是把图像映射到特征空间,整体过程如下图所示。
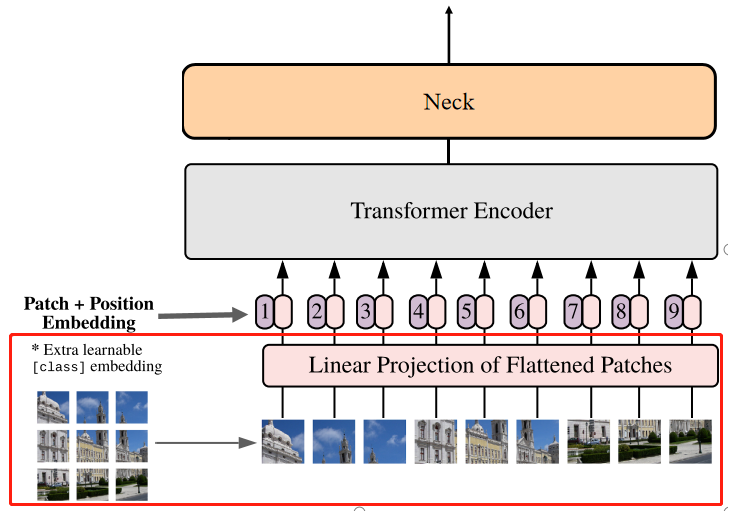
正如论文中所讲,本质上这个Encoder可以是任何网络结构,在这里使用的是微调的Detectron的ViT,当然它也可以被改成传统的卷积结构,非常合理。
输入图像经过ViT结构的过程如下:
1. Patch Embedding
输入图像通过一个卷积base,将图像划分为16x16的patches,步长也为16,这样feature map的尺寸就缩小了16倍,同时channel从3映射到768。Patch Embedding示意图如下所示。

代码实现:
python
'''
将输入的图像转换为序列化的特征向量
'''
class PatchEmbed(nn.Module):
def __init__(
self,
# 卷积核大小
# 这里是 (16, 16),意味着图像将被划分为16x16的patches
kernel_size: Tuple[int, int] = (16, 16),
# 卷积的步长,与kernel_size相同,即(16, 16),
# 意味着每一步移动16个像素,这样图像的尺寸就会减少到原来的1/16
stride: Tuple[int, int] = (16, 16),
# 控制边缘填充,这里设置为 (0, 0),意味着没有额外的填充
padding: Tuple[int, int] = (0, 0),
# 输入图像的通道数,通常为3(RGB图像)
in_chans: int = 3,
# 输出的特征维度,也就是每个patch被编码为的向量的长度,这里设置为768
embed_dim: int = 768,
) -> None:
'''
初始化这个子类实例的属性
'''
# PatchEmbed的子类,继承自nn.Module,用于构建神经网络模块
super().__init__()
self.proj = nn.Conv2d(
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
)
'''前向传播:
接收输入张量 x,形状 (B, C, H, W),其中,
- B表示批次大小
- C 是输入通道数
- H 和 W 是图像的高度和宽度
'''
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 卷积,将输入的通道数从 in_chans 转换为 embed_dim
x = self.proj(x)
# 将张量的维度顺序从 (B, C, H, W) 调整为 (B, H, W, C)
x = x.permute(0, 2, 3, 1)
return xPatch Embedding过程在Vision Transformer结构图中对应下图所示。
2. Positiona Embedding
经过Patch Embedding后输出tokens需要加入位置编码,以保留图像的空间信息。位置编码可以理解为一张map,map的行数与输入序列个数相同,每一行代表一个向量,向量的维度和输入序列tokens的维度相同,位置编码的操作是sum,所以维度依旧保持不变。
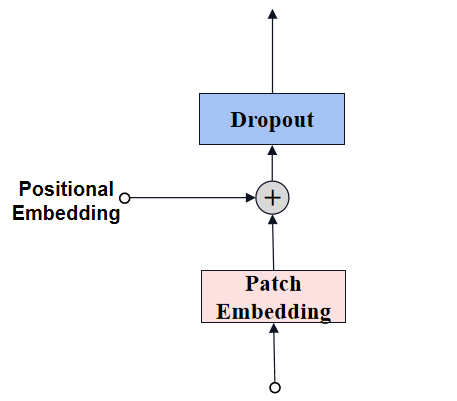
图像尺寸是1024,因此patch的数量是1024/16=64。
代码实现:
python
# 在ImageEncoderViT的__init__定义
if use_abs_pos:
# 使用预训练图像大小初始化绝对位置嵌入
self.pos_embed = nn.Parameter(
torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim)
)
# 在ImageEncoderViT的forward添加位置编码
if self.pos_embed is not None:
x = x + self.pos_embedPositiona Embedding过程在结构图中对应的部分:
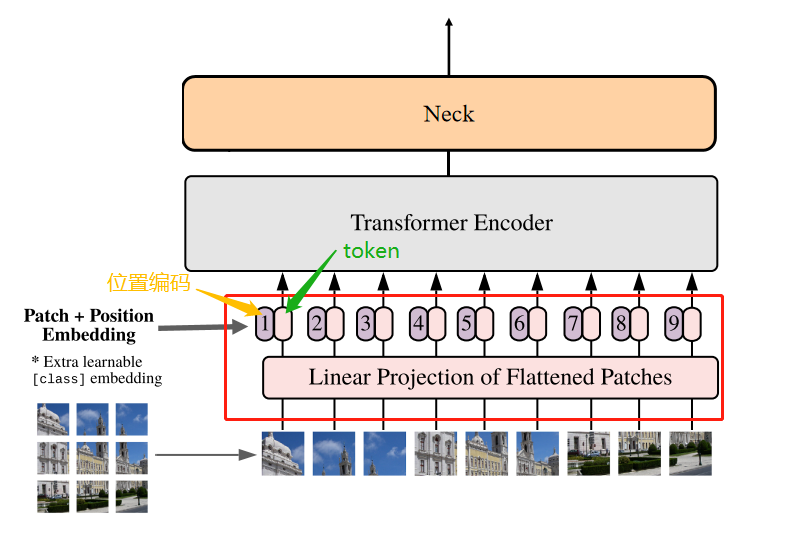
3. Transformer Encoder
feature map通过16个Transformer Block,其中12个Block使用了基于Window Partition(就是把特征图分成14*14的windows做局部的Attention)的注意力机制,以处理局部信息。另外4个Block是全局注意力模块,它们穿插在Window Partition模块之间,以捕捉图像的全局上下文。
python
# 在ImageEncoderViT的__init__定义
# -----Transformer Encoder-----
# 初始化一个ModuleList,用于存储Block实例
self.blocks = nn.ModuleList()
# 循环创建Block,depth是Transformer Encoder层数
for i in range(depth):
# 创建单个Block
block = Block(
# 输入的通道数,即每个patch编码后的向量维度
dim=embed_dim,
# 自注意力机制中的注意力头数
num_heads=num_heads,
# MLP层的通道数相对于输入通道数的比例
mlp_ratio=mlp_ratio,
# 是否在QKV全连接层中使用偏置
qkv_bias=qkv_bias,
# 归一化层
norm_layer=norm_layer,
# 激活函数
act_layer=act_layer,
# 是否使用相对位置编码
use_rel_pos=use_rel_pos,
# 相对位置编码的初始化设置
rel_pos_zero_init=rel_pos_zero_init,
# 如果当前Block不是全局注意力层,则使用窗口大小,否则使用0
window_size=window_size if i not in global_attn_indexes else 0,
# 输入特征的尺寸,基于原始图像大小和patch大小计算得出
input_size=(img_size // patch_size, img_size // patch_size),
)
# 将创建的Block对象添加到self.blocks列表中
self.blocks.append(block)
# -----Transformer Encoder-----Transformer Encoder过程在结构图中对应的部分:
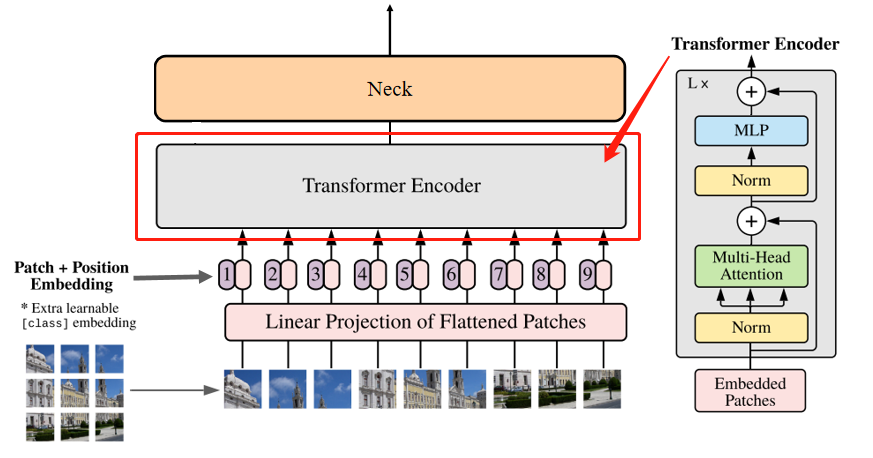
Encoder Block
如上图右所示,Encoder Block从低到高主要由LayerNorm 、Multi-Head Attention和MLP构成。
python
class Block(nn.Module):
def __init__(
self,
dim: int, # 输入通道数
num_heads: int, # attention中head的个数
mlp_ratio: float = 4.0, # MLP层的通道数相对于输入通道数的比例。
qkv_bias: bool = True, # 如果为True,QKV全连接层包含偏置。
norm_layer: Type[nn.Module] = nn.LayerNorm, # 归一化层
act_layer: Type[nn.Module] = nn.GELU, # 激活层
use_rel_pos: bool = False, # 是否使用相对位置编码
rel_pos_zero_init: bool = True, # 相对位置编码的初始化设置
window_size: int = 0, # 注意力层的窗口大小
input_size: Optional[Tuple[int, int]] = None, # 输入特征的尺寸
) -> None:
super().__init__()
self.norm1 = norm_layer(dim) # 第一个归一化层,用于注意力层
self.attn = Attention( # Multi-Head Attention
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
self.norm2 = norm_layer(dim) #第二个归一化层,用于MLP之前
# MLP
self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)
self.window_size = window_size
# 前向传播
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 保存输入张量的副本
shortcut = x
# 对输入张量应用第一个归一化层
x = self.norm1(x)
# Window partition 对X进行padding
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
# Multi-Head Attention
x = self.attn(x)
# 如果 window_size > 0,使用window_unpartition去除窗口分区的padding,恢复原始尺寸
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
# 将注意力层的输出与输入张量相加,实现残差连接
x = shortcut + x
# 对经过第二个归一化层的张量应用MLP层,再次使用残差连接
x = x + self.mlp(self.norm2(x))
# 返回最终的张量 x
return xPartition操作
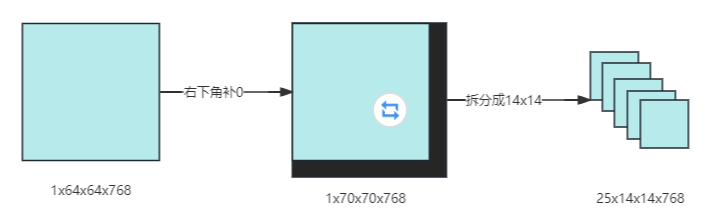
在非全局注意力的Block中,为了适应14x14的窗口大小,输入特征图需要进行补边(padding)和拆分操作。具体流程如下:
-
输入特征图:输入特征图的初始尺寸为 1x64x64x768。
-
确定最小可整除尺寸:窗口大小为14*14,要找到能够被14整除的最小特征图尺寸。对于宽度和高度,我们需要找到大于等于64且能被14整除的最小数。这两个数分别是70(64+6)和70(64+6),所以最小可整除特征图的尺寸是 1x70x70x768。
-
padding:为了将特征图尺寸从 64x64 扩展到 70x70,我们需要在右下角填充 6x6 的区域,因为70-64=6。这种padding方式确保了窗口可以在特征图的边缘正确地划分。
-
拆分特征图:将padding后的特征图1x70x70x768按照窗口大小14x14进行拆分。因为70/14=5,所以特征图可以被拆分为 5x5个14x14的窗口,总共5x5=25个窗口。每个窗口的尺寸为14x14x768。
如下图所示。
python
# 将输入张量x分割成指定大小的窗口
def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]:
# 获取输入张量形状
# B表示批次大小,H和W表示高和宽,C表示通道数
B, H, W, C = x.shape
# 计算填充高度和宽度 pad_h 和 pad_w,以使得输入尺寸能被window_size整除
# 避免在分割时产生非完整的窗口
pad_h = (window_size - H % window_size) % window_size
pad_w = (window_size - W % window_size) % window_size
# 如果需要填充,使用F.pad函数在宽度和高度方向上进行填充
if pad_h > 0 or pad_w > 0:
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
# 更新填充后张量的高度和宽度 Hp 和 Wp
Hp, Wp = H + pad_h, W + pad_w
# 张量重塑为:B,Hp/S,S,Wp/S,S,C,这样可以将输入张量分割成多个窗口
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
# 调整张量的形状,使其由B,Hp/S,Wp/S,S,S,C-->B*Hp*Wp/(S*S),S,S,C
# 这样每个窗口都在张量的连续部分
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
# 返回一个包含所有窗口的张量和原始张量的填充后尺寸 (Hp, Wp)
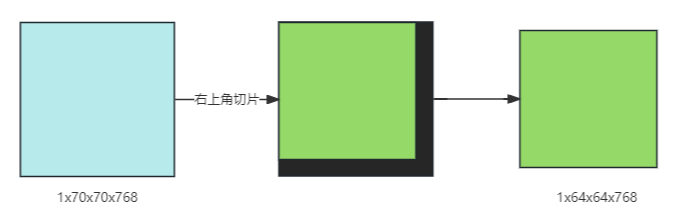
return windows, (Hp, Wp)「Unpartition操作」
在非全局注意力的Block中,将attention层输出的特征图1x70x70x768转化为1x64x64x768的特征图,实际上是通过切片操作x = x:1, :64, :64, :,从1x70x70x768的特征图中取出左上角的1x64x64x768部分。
python
# 用于将window_partition函数分割的窗口重新组合回原始尺寸的张量
def window_unpartition(
# 获取输入张量 windows 的形状,以及窗口大小 window_size
windows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int], hw: Tuple[int, int]
) -> torch.Tensor:
# 原始尺寸的填充高度和宽度
Hp, Wp = pad_hw
# 原始尺寸的无填充高度和宽度
H, W = hw
# 从窗口张量的总大小中计算出原始批量大小 B
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
# 重塑窗口张量:B*Hp*Wp/(S*S),S,S,C-->B,Hp/S,Wp/S,S,S,C
x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)
# 再次重塑张量:B,Hp/S,Wp/S,S,S,C-->B,Hp,Wp,C
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
# 如果原始尺寸小于填充后的尺寸
if Hp > H or Wp > W:
# 通过切片 x[:, :H, :W, :] 去除填充部分,只保留原始大小的区域
x = x[:, :H, :W, :].contiguous()
# B,H,W,C
# 返回合并后的张量,其形状为 (B,H,W,C),即原始的批量大小、高度、宽度和通道数
return xEncoder Block过程如下图所示:
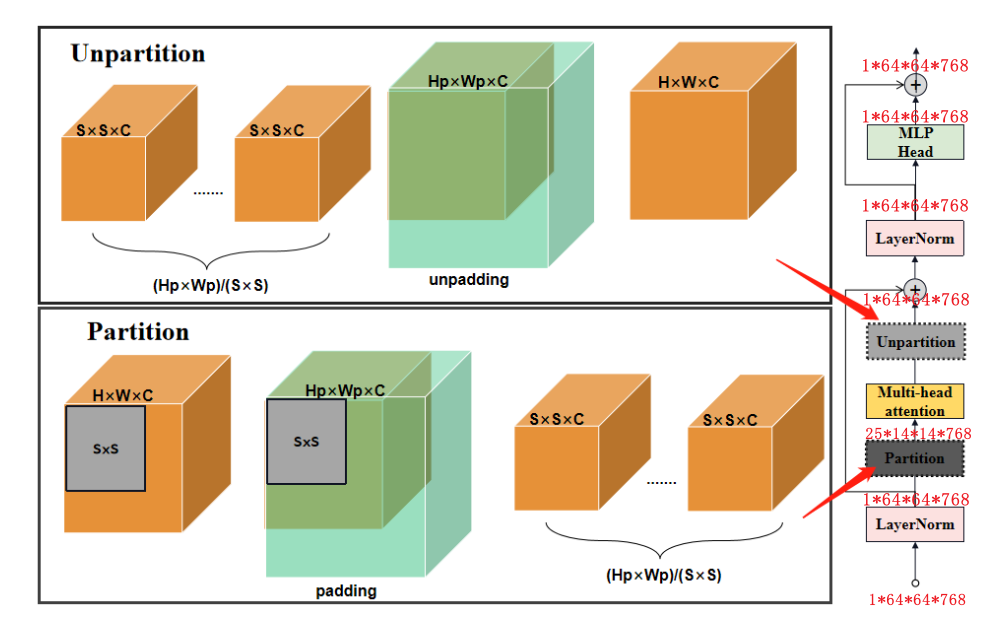
window_partition将输入特征的尺寸从(H, W)调整为(S, S)的窗口,其中S是窗口大小。这种调整是为了在多头注意力(Multi-Head Attention)中将相对位置嵌入添加到注意力图(attn)。然而,并非所有Transformer Block都需要在注意力图中嵌入相对位置信息。 window_unpartition 函数的作用是将经过注意力计算的窗口特征重新组合回原始尺寸(S×S-->H×W)。 Hp和Wp是S的整数倍
Multi-Head Attention
先来看Attention,结构如下图所示。
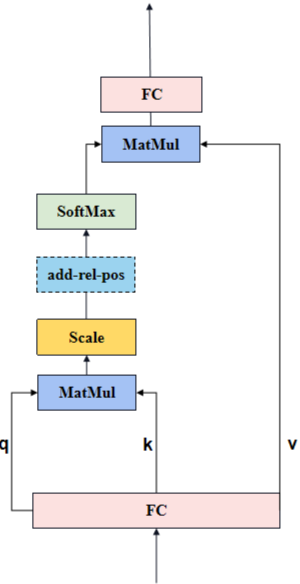
Attention中q、k和v的作用:
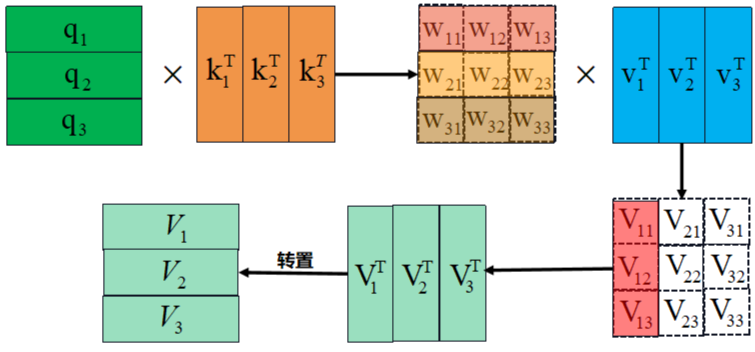
代码实现如下:
python
class Attention(nn.Module):
"""Multi-head Attention block with relative position embeddings."""
def __init__(
self,
dim: int, # 输入通道数
num_heads: int = 8, # head数目
qkv_bias: bool = True, # 是否在QKV线性变换中使用偏置项,默认为True
use_rel_pos: bool = False, #是否使用相对位置编码,默认为False
rel_pos_zero_init: bool = True, #如果使用相对位置编码,是否以零初始化,默认为True
input_size: Optional[Tuple[int, int]] = None, # 可选参数,用于指定相对位置编码的尺寸,只有在使用相对位置编码时才需要
) -> None:
super().__init__()
self.num_heads = num_heads #输入head数目
head_dim = dim // num_heads #每个head维度
self.scale = head_dim**-0.5 #用于缩放注意力得分的因子,以避免数值溢出,取值为head_dim的平方根的倒数
#一个全连接层(nn.Linear),将输入映射到Q、K、V的组合
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
# 一个全连接层,用于将注意力机制的输出投影回原始维度
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos
if self.use_rel_pos: # 使用相对位置编码
assert (
input_size is not None
), "Input size must be provided if using relative positional encoding."
# 初始化水平方向(rel_pos_h)和垂直方向(rel_pos_w)的相对位置嵌入
# 2S-1,Epos
# 输入尺寸为(H, W),则水平方向的位置嵌入长度为2*H-1,垂直方向的位置嵌入长度为2*W-1
# 每个位置嵌入的维度为head_dim
# 这些位置嵌入以模型参数的形式定义(nn.Parameter),意味着它们会在训练过程中被学习和更新
self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 输入张量x的形状为(B, H, W, C),其中B是批次大小,H和W是高度和宽度,C是通道数(即dim)
B, H, W, _ = x.shape
# 使用qkv层将x转换为Q、K、V的组合,然后通过重塑和重新排列来准备多头注意力计算
# qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
# q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
# attn with shape (B * nHead, H * W, H * W)
# 计算注意力分数
# q * self.scale: q是查询向量(query vectors),形状为(B * nHead, H * W, C),其中B是批次大小,nHead是注意力头的数量,H * W是序列的长度,C是每个位置的特征维度
# self.scale是用于缩放注意力分数的因子,通常取head_dim的平方根的倒数,以防止数值过大
# 乘以self.scale是为了稳定计算并防止梯度消失
# k.transpose(-2, -1): k是键向量(key vectors),形状与q相同。transpose(-2, -1)是对k进行转置操作,即将最后一个和倒数第二个维度互换,目的是让q和k在计算点积时的维度匹配。转置后的k形状变为(B * nHead, C, H * W)
# 将q和转置后的k进行矩阵乘法。计算每个查询位置q与所有键位置k的点积,生成一个形状为(B * nHead, H * W, H * W)的注意力分数矩阵attn。每个位置i和j的注意力分数表示q_i与k_j的相似度
attn = (q * self.scale) @ k.transpose(-2, -1)
# 如果启用了相对位置编码
if self.use_rel_pos:
# (H, W)代表输入序列的尺寸,这里假设H和W是相等的(S×S),即输入是一个正方形网格(例如,图像的像素网格)
# attn: 上述计算得到的注意力分数矩阵,形状为(B * nHead, H * W, H * W)
# q: 查询向量,形状为(B * nHead, H * W, C)
# self.rel_pos_h和self.rel_pos_w: 分别表示水平和垂直方向上的相对位置嵌入,形状分别为(2 * S - 1, head_dim)
# (H, W): 输入序列的尺寸,用于指导相对位置嵌入的计算
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
# 生成的注意力分数矩阵attn随后会经过Softmax函数,将每个位置的分数归一化到[0, 1]区间,形成一个概率分布
attn = attn.softmax(dim=-1)
# 加权求和:
# 使用attn @ v计算加权和,其中@表示矩阵乘法,v是值向量(value vectors),形状为(B * nHead, H * W, C)
# 注意力权重矩阵attn(形状为(B * nHead, H * W, H * W))与v按元素相乘后,再进行矩阵乘法,得到加权后的值向量,形状为(B * nHead, H * W, C)
# 使用.view()将加权后的值向量重塑为(B, self.num_heads, H, W, -1),然后使用.permute(0, 2, 3, 1, 4)进行重排,将self.num_heads移动到第四个维度。最后,使用.reshape(B, H, W, -1)将结果进一步重塑为(B, H, W, -1),与输入张量的形状一致,但保留了多头注意力的输出
x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
# 使用self.proj(一个全连接层,形状为(dim, dim))对上述处理后的张量进行线性投影,以将其投影回原始的特征维度
x = self.proj(x)
# 最终,返回经过线性投影的张量x作为注意力模块的输出
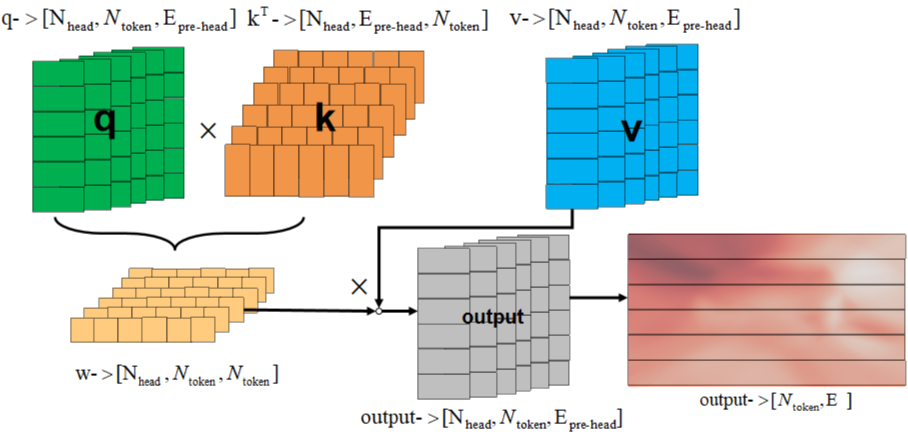
return x在多头注意力(Multi-Head Attention)模块中,输入特征F(N×E)表示一个序列,其中N是序列中的元素数量,E是每个元素的特征维度。具体流程如下。
- 首先将每个token的qkv特征维度embed_dim均拆分到每个head上。
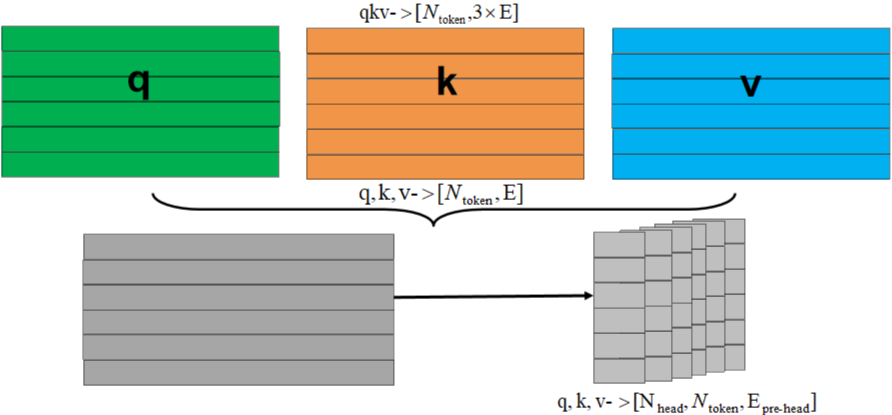
- 每个head分别通过q和k计算得到权重w,权重w和v得到输出output,合并所有head的output得到最终的output。
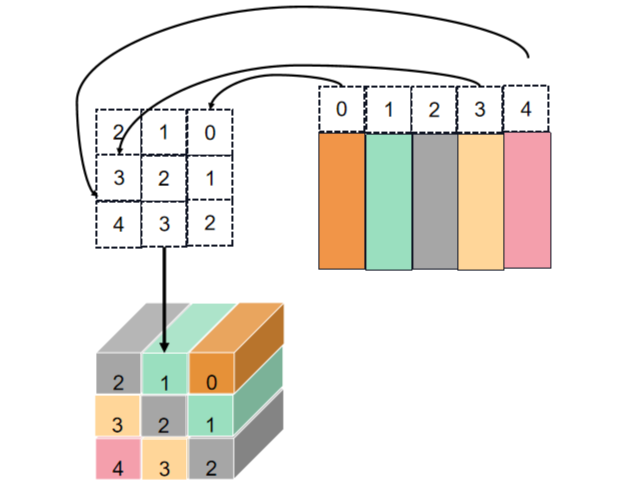
get_rel_pos用于计算查询(query)和键(key)之间在二维空间中的相对位置编码,如下图所示。
实现代码:
python
def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
# 表示查询(query)和键(key)在二维空间中的最大相对距离
# max(q_size, k_size):取查询的宽度q_size和键的宽度k_size中的较大值
# 如果q_size和k_size都为S,则最大的正向距离是S-1,最大的负向距离也是S-1,所以总的最大距离是2 * S
# - 1:减去1是因为在计算相对位置时,0被包含在内,所以最大距离是2 * S - 1
max_rel_dist = int(2 * max(q_size, k_size) - 1)
# 如果rel_pos的形状的第0个维度(即长度)不等于max_rel_dist,说明需要进行插值
if rel_pos.shape[0] != max_rel_dist:
# 使用F.interpolate进行线性插值
rel_pos_resized = F.interpolate(
# 1,N,Ep --> 1,Ep,N --> 1,Ep,2S-1
# 将rel_pos重塑为(1, N, Ep),其中N是原始的长度,Ep是每个位置编码的特征维度
# 通过permute(0, 2, 1)进行转置,使其形状变为(1, Ep, N)
rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
# 设置插值的目标长度为max_rel_dist
size=max_rel_dist,
# 指定插值方法为线性插值
mode="linear",
)
# Ep,2S-1 --> 2S-1,Ep
# 插值后的rel_pos形状为(1, Ep, max_rel_dist),通过reshape(-1, max_rel_dist)将其重塑为(Ep, max_rel_dist)
# 再通过permute(1, 0)转置为(max_rel_dist, Ep)
rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
else:
# 如果rel_pos的长度与max_rel_dist相等,说明已经足够覆盖所有可能的相对位置,因此直接使用rel_pos,不进行任何处理
rel_pos_resized = rel_pos
# 如果q和k长度值不同,则用短边长度缩放坐标
# 创建查询坐标q_coords
# torch.arange(q_size)生成一个从0到q_size - 1的整数序列,表示q_size个位置
# [:, None]在序列末尾添加一个维度,使其形状为(q_size, 1),这样可以方便与一个标量进行逐元素乘法
# max(k_size / q_size, 1.0)计算比例因子,如果k_size大于q_size,则使用k_size / q_size,否则使用1.0
# 这确保了在q_size小于k_size的情况下,q_coords的坐标会被适当放大,以匹配k_coords的尺度
q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
# 创建键坐标k_coords
k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
# S,S
# 计算了查询(query)和键(key)在二维空间中的相对坐标relative_coords
# (q_coords - k_coords):每个查询位置相对于每个键位置的水平距离
# (k_size - 1) * max(q_size / k_size, 1.0):计算了一个偏移量,用于确保相对坐标在正确的范围内
# (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0):将计算出的差值和偏移量相加,得到最终的相对坐标relative_coords
relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
# tensor索引是tensor时,即tensor1[tensor2]
# 假设tensor2某个具体位置值是2,则tensor1[2]位置的tensor1切片替换tensor2中的2
# tensor1->shape 5,5,3 tensor2->shape 2,2,3 tensor1切片->shape 5,3 tensor1[tensor2]->shape 2,2,3,5,3
# tensor1->shape 5,5 tensor2->shape 3,2,3 tensor1切片->shape 5 tensor1[tensor2]->shape 3,2,3,5
# 2S-1,Ep-->S,S,Ep
return rel_pos_resized[relative_coords.long()]add_decomposed_rel_pos为atten注意力特征添加相对位置的嵌入特征,如下图所示。
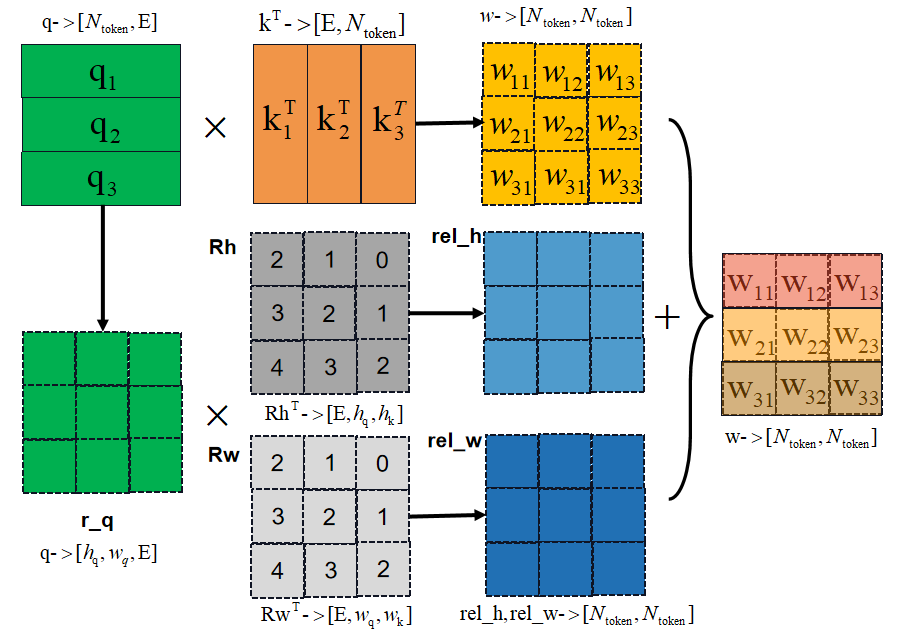
python
def add_decomposed_rel_pos(
# 注意力分数矩阵
attn: torch.Tensor,
q: torch.Tensor,
rel_pos_h: torch.Tensor,
rel_pos_w: torch.Tensor,
q_size: Tuple[int, int],
k_size: Tuple[int, int],
) -> torch.Tensor:
# S,S
q_h, q_w = q_size
k_h, k_w = k_size
# rel_pos_h -> 2S-1×Epos
# 查询(query)和键(key)在高度方向上的相对位置编码
Rh = get_rel_pos(q_h, k_h, rel_pos_h)
# 查询(query)和键(key)在宽度方向上的相对位置编码
Rw = get_rel_pos(q_w, k_w, rel_pos_w)
# 重塑q为(B, q_h, q_w, dim)
B, _, dim = q.shape
r_q = q.reshape(B, q_h, q_w, dim)
# 计算相对位置加权
# 计算rel_h和rel_w,这两个张量表示在每个位置上,查询与相对位置编码的加权和
# B,q_h,q_w,k_h
rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
# B,q_h, q_w, k_w
rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
# 合并注意力分数和相对位置编码
# 将attn重塑为(B, q_h, q_w, k_h, k_w),然后与rel_h和rel_w按元素相加
# 将attn重塑为(B, q_h, q_w, k_h, k_w),然后与rel_h和rel_w按元素相加
attn = (
# B,q_h, q_w, k_h, k_w
attn.view(B, q_h, q_w, k_h, k_w) + rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
).view(B, q_h * q_w, k_h * k_w)
return attnMulti-Head Attention模块为注意力特征嵌入了相对位置特征(add_decomposed_rel_pos):
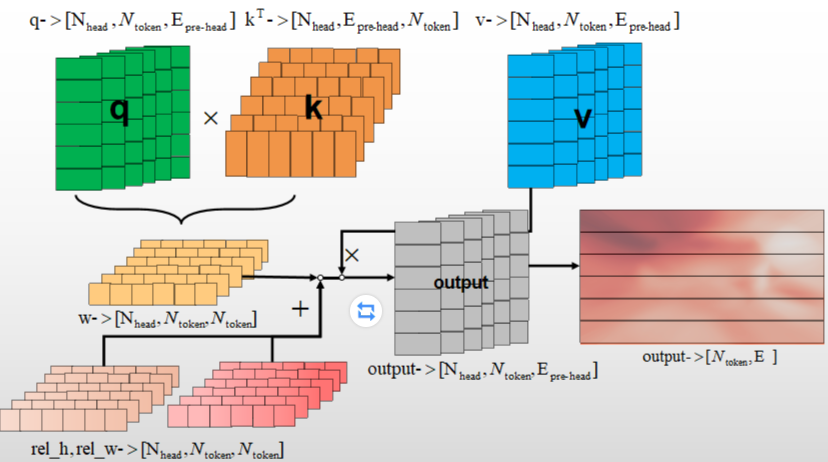
Neck Convolution
最后,通过两层卷积(Neck)将通道数降低至256,生成最终的Image Embedding。其结构图如下所示。
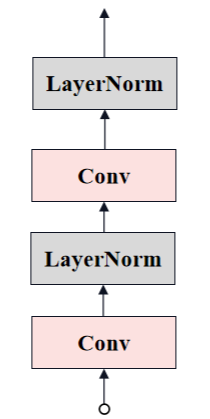
代码实现如下:
python
# neck: nn.Sequential,它包含两个卷积层和两个LayerNorm2d)
self.neck = nn.Sequential(
# 1x1的卷积层,用于将输入通道数从embed_dim减小到out_chans
# 1x1卷积主要用于通道间的信息融合,而不改变特征图的空间尺寸
nn.Conv2d(
embed_dim,
out_chans,
kernel_size=1,
# 不使用偏置项
bias=False,
),
# 归一化层,用于规范化输出通道的均值和方差,提高模型的稳定性和收敛速度
# out_chans:归一化层的通道数
LayerNorm2d(out_chans),
# 3x3的卷积层
nn.Conv2d(
# 使用out_chans作为输入和输出通道数
out_chans,
out_chans,
kernel_size=3,
# 输入和输出的特征图尺寸保持不变,避免尺寸收缩
padding=1,
# 不使用偏置
bias=False,
),
# 第二个归一化层,再次对输出进行规范化
LayerNorm2d(out_chans),
)
python
# 归一化
class LayerNorm2d(nn.Module):
def __init__(self, num_channels: int, eps: float = 1e-6) -> None:
super().__init__()
# 创建了两个可学习的参数:weight和bias
# weight初始化为全1,bias初始化为全0
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 沿着通道维度求均值,keepdim=True保留维度,使得u的形状与x相同,除了通道维度的大小为1
u = x.mean(1, keepdim=True) # dim=1维度求均值并保留通道
# 计算标准化因子 s,即减去均值后的平方差的平均值,也保留通道维度
s = (x - u).pow(2).mean(1, keepdim=True)
# 归一化,将每个像素的值减去均值 u,然后除以标准差的平方根加上一个小的常数 eps 以保证数值稳定性
x = (x - u) / torch.sqrt(s + self.eps)
# 应用可学习的权重和偏置
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return xPrompt Encoder
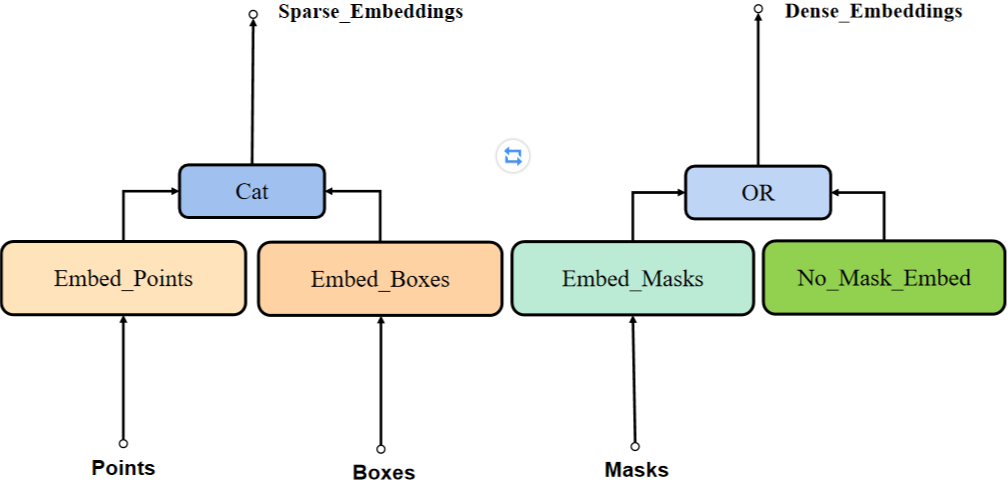
SAM模型中Prompt Encoder网络结构如下图所示。主要包括三步骤:
-
Embed_Points:标记点编码(标记点由点转变为向量)
-
Embed_Boxes:标记框编码(标记框由点转变为向量)
-
Embed_Masks:mask编码(mask下采样保证与Image Encoder输出一致)
Embed_Points
Embed_Points结构如下图所示。
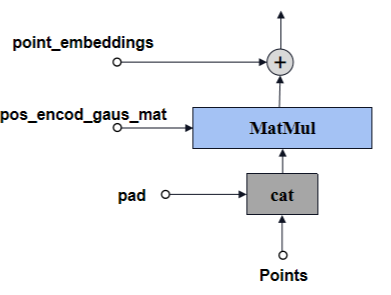
标记点预处理,将channel由2变为embed_dim(MatMul:forward_with_coords),然后再加上位置编码权重。其中,
-
2:坐标(h,w)
-
embed_dim:提示编码的channel
「代码实现:」
python
# 将输入的点坐标和对应的标签转化为高维的嵌入表示,以便于后续的模型处理
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
# 将输入的点坐标points的每个坐标值增加0.5,以将坐标从像素的左上角移动到像素中心
points = points + 0.5
# points和boxes联合则不需要pad
if pad:
# 在点坐标 points 和标签 labels 中添加一个填充项
# 以保持批次处理的一致性,即使某些样本的点数量少于最大数量。
# 填充的点坐标为(0,0),标签为-1
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device) # B,1,2
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device) # B,1
points = torch.cat([points, padding_point], dim=1) # B,N+1,2
labels = torch.cat([labels, padding_label], dim=1) # B,N+1
# 根据调整后的点坐标和输入图像的尺寸生成位置编码
# 生成的嵌入维度:B,N+1,2f
# 2f 表示每个点位置编码的维度,是通过某种函数(如正弦或余弦函数)从原始的2D坐标扩展而来
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
# 根据标签 labels 的值,对每个点的嵌入进行调整。
# labels为-1是非标记点,设为非标记点权重
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
# labels为0是背景点,加上背景点权重
point_embedding[labels == 0] += self.point_embeddings[0].weight
# labels为1是目标点,加上目标点权重
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embeddingEmbed_Boxes
Embed_Boxes结构如下图所示。
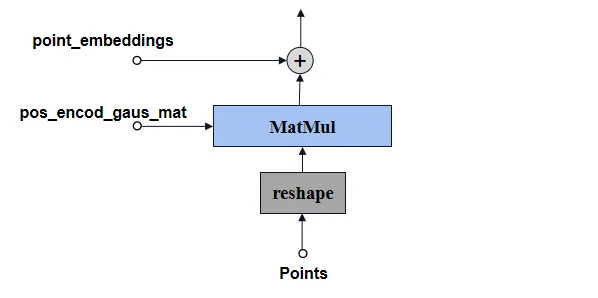
标记框(Bounding Box)一般有两个点,编码步骤如下:
-
将输入的边界框坐标张量boxes从BxNx4转换为BxNx2x2;
-
再使用point embedding编码的方式,得到corner_embedding;
-
加上之前生成的可学习的embeding向量。
最后输出的corner_embedding大小为Nx2x256。
「代码实现:」
python
# 将输入的边界框(boxes)转换为高维的嵌入表示
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
# 将坐标从像素的左上角移动到像素中心
boxes = boxes + 0.5
# 将输入的边界框坐标张量boxes从BxN*4转换为B*Nx2x2
# 其中B是批次大小,N是每个样本中的边界框数量
coords = boxes.reshape(-1, 2, 2)
# 对每个边界框的角点坐标进行位置编码
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size) #
# 分别对每个边界框的起始点和末尾点的嵌入向量加上特定的权重
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
# 返回加权后嵌入向量,形状为 B*Nx2xembed_dim,其中 embed_dim 是位置编码的维度
return corner_embeddingEmbed_Mask
mask提示允许我们直接在原图上指示感兴趣区域来引导模型。这些mask通过卷积操作被转换为与图像嵌入空间相匹配的特征,然后与图像嵌入相加结合,为模型提供分割的精确位置信息。
如果没有使用mask提示,则将一组可学习向量(no_mask_embed,1*256)expand为1x256×64×64后替代,使得在处理序列数据时,即使没有具体的mask信息,也能有一个统一的处理方式。
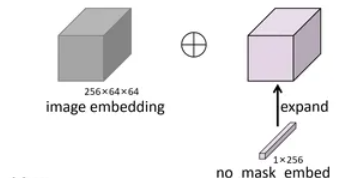
python
# 在PromptEncoder的forward定义
'''
首先获取no_mask_embed权重矩阵,并将其重塑成一个形状为(1, num_embeddings, 1, 1)的四维张量。
再利用.expand方法将这个张量扩展到与图像编码相同的尺寸。bs是batch大小,-1是一个占位符,它会自动计算出
num_embeddings的值以保持张量的元素总数不变。self.image_embedding_size[0]和self.image_embedding_size[1]分别表示图像编码的宽度和高度。
'''
self.no_mask_embed = nn.Embedding(1, embed_dim) # embed_dim=256
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1])
)如果有配置mask,Embed_Masks结构如下图所示。

已知输入mask是Nx1x256x256,经过3层卷积,最后得到与Image Embedding一样的size:
首先,mask进入一个1x2x2x4的卷积,stride=2;LN;再进入一个4x2x2x16的卷积,stride=2;LN;最后再进入一个16x1x1x256的卷积;得到最后的mask_embedding的size为Nx256x64x64,最终mask_embedding作为dense_embedding输出,大小为Nx256x64x64。
mask的输出尺寸是Image Encoder模块输出的图像编码尺寸的4倍,因此为了保持一致,需要4倍下采样。
「代码实现」
python
# 将输入的掩模(mask)张量转换为一个低分辨率的嵌入表示
# 掩模 masks 是一个形状为 BxCxHxW 的张量
# 其中 B 是批次大小,C 是通道数(通常为1,因为掩模通常只有一通道),H 和 W 分别是高度和宽度。
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
# mask下采样4倍
mask_embedding = self.mask_downscaling(masks)
# 返回下采样并转换后的掩模嵌入,其形状为 B*embed_dim*H'*W',其中 H' 和 W' 是下采样后的高度和宽度
return mask_embedding
# mask_downscaling包括多个卷积层、层归一化(LayerNorm2d)和激活函数,目的是减少掩模的空间维度,同时增加通道维度
self.mask_downscaling = nn.Sequential(
# 将通道数从1减少到mask_in_chans//4,同时使用2x2的卷积核和步长2进行下采样,降低了空间分辨率
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
# 规范化通道维度上的特征
LayerNorm2d(mask_in_chans // 4),
# 激活函数,引入非线性
activation(),
# 将通道数恢复到 mask_in_chans,再次使用2x2的卷积核和步长2进行下采样,进一步降低空间分辨率
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
# LayerNorm2d 层和激活函数
LayerNorm2d(mask_in_chans),
activation(),
# 将通道数增加到 embed_dim,通常是为了与模型的其他部分保持一致
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)「PositionEmbeddingRandom」
用于将标记点和标记框的坐标进行提示编码预处理。就是将64x64个坐标点归一化后,与随机高斯矩阵相乘(2x128),再将结果分别进行sin和cos,最后再拼到一起,输出的大小为256x64x64,与image_embedding大小基本一致了。
python
class PositionEmbeddingRandom(nn.Module):
"""
Positional encoding using random spatial frequencies.
"""
def init(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().init()
if scale is None or scale <= 0.0:
scale = 1.0
# 构建一个2x128的随机矩阵作为位置编码高斯矩阵
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)),
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
coords = 2 * coords - 1
# 矩阵乘法:64x64xx2 @ 2x128 ---> 64x64x128
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
# cat, 最后一个维度上拼接:64x64x256
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
# 构造一个64x64的全1矩阵
grid = torch.ones((h, w), device=device, dtype=torch.float32)
# 行、列累加
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
# 行列累加结果归一化
y_embed = y_embed / h
x_embed = x_embed / w
# 行列拼接:64x64x2,编码后的结果是64x64x256
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
# 最后输出256x64x64
return pe.permute(2, 0, 1) # C x H x WMask Decoder
Mask Decoder网络结构参数配置如下。
python
def __init__(
self,
*,
# transformer通道数
transformer_dim: int,
# 用于预测mask的Transformer网络模块
transformer: nn.Module,
# 消除掩码歧义预测的掩码数量,默认为3
num_multimask_outputs: int = 3,
# 激活函数,默认为GELU
activation: Type[nn.Module] = nn.GELU,
# MLP用于预测掩模质量的深度
iou_head_depth: int = 3,
# MLP的隐藏层通道数
iou_head_hidden_dim: int = 256,
) -> None:
super().__init__()
self.transformer_dim = transformer_dim #存储传入的transformer_dim
# 存储传入的transformer模块
self.transformer = transformer
# 存储掩码预测的输出数量
self.num_multimask_outputs = num_multimask_outputs
# 用于表示IoU(Intersection over Union)的嵌入层,大小为1×transformer_dim
# 可学习的iou tokens:1x256
self.iou_token = nn.Embedding(1, transformer_dim)
# 包含IoU token在内的总mask token数量
# # num_mask_tokens = 3 + 1 = 4, transformer_dim = 256
# 输出一个4x256的矩阵
self.num_mask_tokens = num_multimask_outputs + 1
# 存储所有mask token的嵌入层,大小为num_mask_tokens×transformer_dim
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
#----- upscaled -----
# 用于4倍上采样的序列,包含两个转置卷积层,每个上采样2倍,中间夹着LayerNorm和激活函数
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
# ----- upscaled -----
# 多层感知机(MLP)模块
# 一个模块列表,包含了num_mask_tokens个MLP,每个MLP用于处理不同mask的输出
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
# ----- MLP -----
# ----- MLP -----
# 一个MLP,用于预测IoU,输入是transformer_dim,经过iou_head_hidden_dim的隐藏层,输出是num_mask_tokens
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
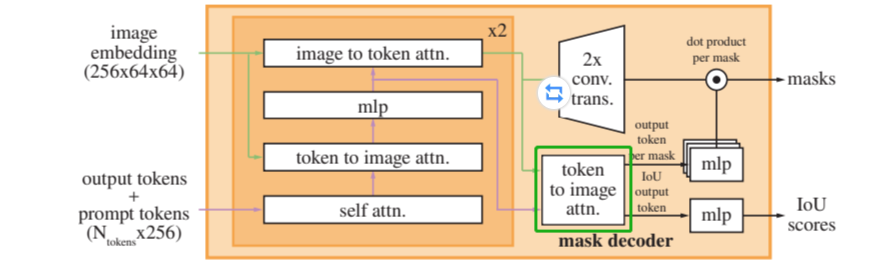
# ----- MLP -----SAM模型Mask Decoder网络结构如下图所示。
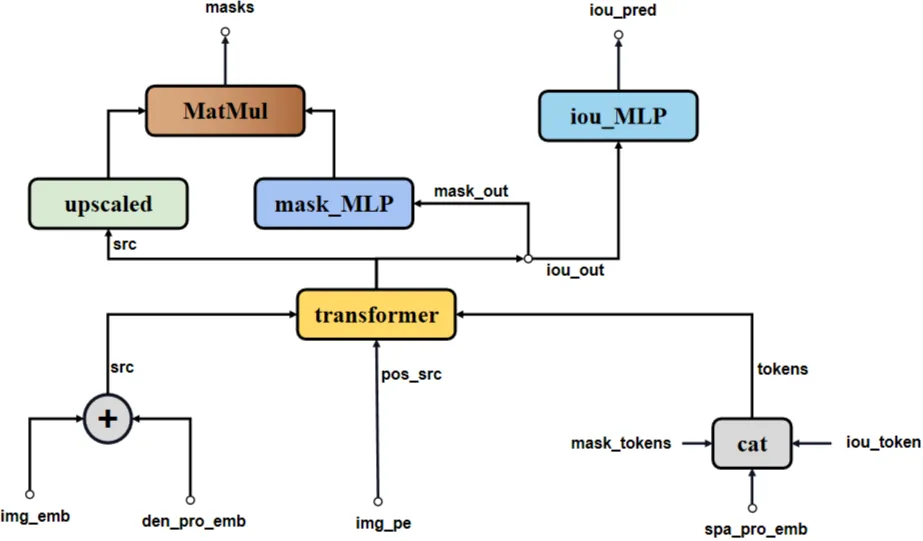
-
spa_pro_emb(sparse embedding)、iou_token、mask_token合并成一个tokens,作为point_embeddings。
-
spa_pro_emb: point、bbox prompt合并后的产物,一般为NxXx256。
-
iou_token:可学习参数,大小为1x256。
-
mask_token:可学习参数,大小为4x256。
原论文中Mask Decoder模块各部分结构示意图如下。
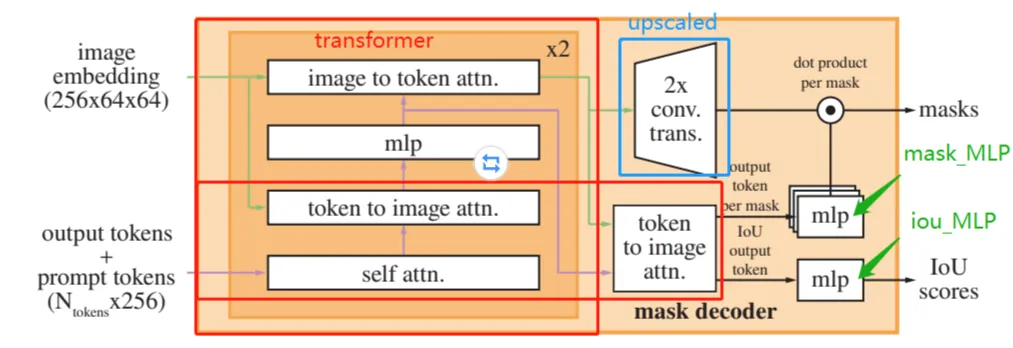
Mask Decoder网络在特征提取中的基本步骤如下:
-
transformer:将来自编码器的图像特征与额外的提示信息(如掩码提示或查询向量)融合,以捕捉目标区域的上下文信息。
-
upscaled:对粗略mask src进行上采样,使其与原始图像尺寸相匹配,以便进行更精细的mask预测。
-
mask_MLP:通过一系列全连接层,对上采样后的特征进行变换,计算出针对每个像素的mask概率。这些层可以设计为学习如何为每个mask通道分配权重,从而生成最终的mask输出。
-
iou_MLP:评估生成的mask与真实mask之间的重叠程度,即预测mask的质量。
python
def forward(
self,
# image encoder 图像特征
image_embeddings: torch.Tensor,
# 位置编码
# 256x64x64
image_pe: torch.Tensor,
# 标记点和标记框的嵌入编码
sparse_prompt_embeddings: torch.Tensor,
# 输入mask的嵌入编码
dense_prompt_embeddings: torch.Tensor,
# 是否输出多个mask
multimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:
# 将这些特征融合,通过Transformer和后续的上采样及MLP层,生成掩膜预测和IoU分数
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
)
# 如果multimask_output为True,表示需要输出多个掩模,选取索引为1到num_multimask_outputs的所有掩模
if multimask_output:
mask_slice = slice(1, None)
# 否则,如果multimask_output为False,仅输出第一个掩模(通常是最高得分的掩模)
else:
mask_slice = slice(0, 1)
# 根据multimask_output选择后的掩模,维度调整为(batch_size, num_selected_masks, height, width)
masks = masks[:, mask_slice, :, :]
# 根据multimask_output选择后的IoU预测,维度调整为(batch_size, num_selected_masks)
iou_pred = iou_pred[:, mask_slice]
return masks, iou_pred
python
def predict_masks(
self,
# image embedding: 是image encoder的输出,大小为为1x256x64x64
image_embeddings: torch.Tensor,
# image_pe位置编码也拓展成Nx256x64x64的矩阵
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
# 首先将iou token和mask token 拼接得到一个5x256的矩阵,再将其拓展到与sparse embedding一个维度Nx5x256
# 1,E and 4,E --> 5,E
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
# 再将拓展后的矩阵与sparse embedding拼接得到tokens,其大小Nx(5+X)x256
# 5,E --> B,5,E
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
# 再与稀疏矩阵拼接,假设稀疏矩阵只有point为Nx2x256,拼接之后则为Nx(5+2)x256
# B,5,E and B,N,E -->B,5+N,E N是点的个数(标记点和标记框的点)
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# 将image embedding(1x256x64x64)拓展成稠密prompt的维度:Nx256x64x64
# B,C,H,W
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
#将拓展后的image embedding直接与稠密prompt相加:Nx256x64x64
# B,C,H,W + 1,C,H,W ---> B,C,H,W
src = src + dense_prompt_embeddings
# # 将256x64x64的位置编码,拓展成Nx256x64x64
# 1,C,H,W---> B,C,H,W
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# ----- transformer -----
# Run the transformer:这里使用的TwoWayTransformer,有必要对输入再说明一下
# src:image_bedding + dense_prompt(mask),Nx256x64x64
# pos_src: 位置编码,Nx256x64x64
# tokens: iou_tokens + mask_tokens + sparse_prompt(point/bbox),Nx(5+x)x256
# B,N,C
hs, src = self.transformer(src, pos_src, tokens)
# ----- transformer -----
# # 后处理
iou_token_out = hs[:, 0, :]
mask_tokens_out = hs[:, 1: (1 + self.num_mask_tokens), :]
# 通过上采样层将Transformer输出的掩模部分恢复到(batch_size, channels, height, width)的形状
# B,N,C-->B,C,H,W
src = src.transpose(1, 2).view(b, c, h, w)
# ----- upscaled -----
# 4倍上采样
upscaled_embedding = self.output_upscaling(src)
# ----- upscaled -----
# 对每个mask token,通过其对应的MLP得到一个权重张量,使用这些权重与上采样后的特征张量进行点乘,得到掩模预测(batch_size, num_mask_tokens, height, width)
hyper_in_list: List[torch.Tensor] = []
# ----- mlp -----
for i in range(self.num_mask_tokens):
# mask_tokens_out[:, i, :]: B,1,C
# output_hypernetworks_mlps: B,1,c
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
# B,n,c
hyper_in = torch.stack(hyper_in_list, dim=1)
# ----- mlp -----
b, c, h, w = upscaled_embedding.shape
# B,n,c × B,c,N-->B,n,h,w
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# ----- mlp -----
# 通过IoU预测头(MLP)对IoU token的输出进行处理,得到(batch_size, num_mask_tokens)的IoU分数
# iou_token_out: B,1,n
iou_pred = self.iou_prediction_head(iou_token_out)
# ----- mlp -----
# 返回预测的掩模和IoU分数
# masks: B,n,h,w
# iou_pred: B,1,n
return masks, iou_pred1. transformer
Mask Decoder由多个重复堆叠TwoWayAttention Block和1个Multi-Head Attention组成。
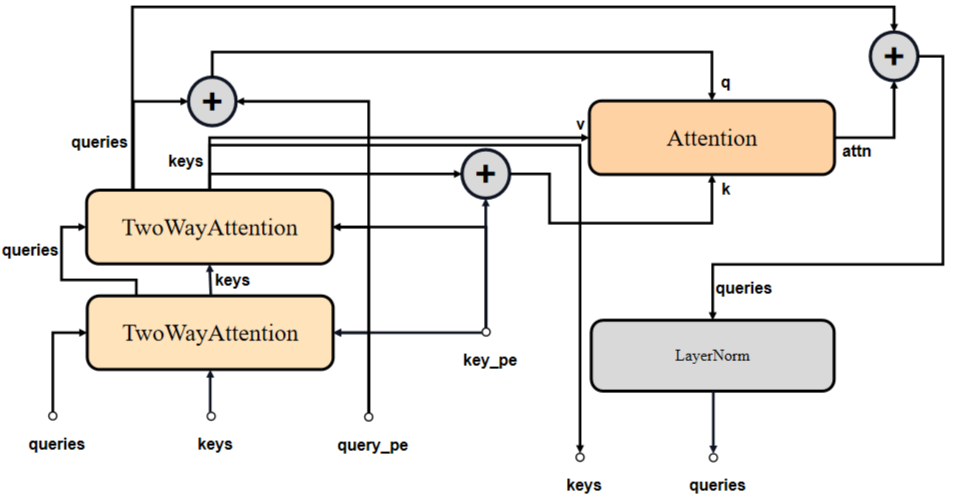
「TwoWayAttention Block」
TwoWayAttention Block由LayerNorm 、Multi-Head Attention和MLP构成。所谓的TwoWay:即是两轮次循环,第一次point_embedding自注意,第二次则加上上一轮输出的queries进行attention。
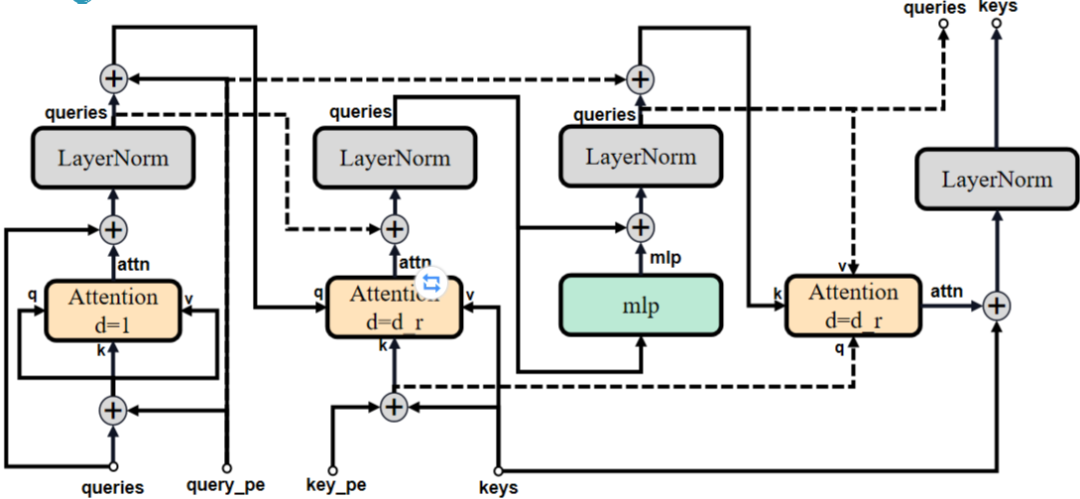
原论文中TwoWayAttention部分示意图。

python
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int, # 输入特征维度
num_heads: int, # 注意力头的数量,决定了注意力机制的并行度
mlp_dim: int = 2048, # MLP(多层感知机)中间层的维度,用于特征变换和非线性增强
activation: Type[nn.Module] = nn.ReLU, # 激活函数类型,默认为ReLU
attention_downsample_rate: int = 2, # 下采样比率
# 是否在第一层自注意力中跳过位置编码的残差连接
skip_first_layer_pe: bool = False,
) -> None:
super().__init__()
# 自注意力模块,用于增强queries内部的信息交互
self.self_attn = Attention(embedding_dim, num_heads)
# norm1/2/3/4: LayerNorm层,用于稳定训练和加速收敛
self.norm1 = nn.LayerNorm(embedding_dim)
# cross_attn_token_to_image和cross_attn_image_to_token: 交叉注意力模块,分别让标记点特征关注图像特征,以及图像特征反过来关注标记点特征
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
# mlp: 多层感知机模块,增加模型的表达能力
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
# 前向传播
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# queries:标记点编码相关(原始标记点编码经过一系列特征提取)
# keys:原始图像编码相关(原始图像编码经过一系列特征提取)
# query_pe:原始标记点编码
# key_pe:原始图像位置编码
# 第一轮本身queries==query_pe没比较再"残差"
# 首先对queries应用自注意力,若skip_first_layer_pe=True,直接使用queries进行自注意力计算;否则,将queries与query_pe相加后进行自注意力计算,并残差连接回queries,之后进行LayerNorm
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# 调整queries和keys(图像特征)加上各自的位置编码,然后通过cross_attn_token_to_image交叉注意力层,使标记点特征关注图像特征,结果与原始queries残差连接并进行LayerNorm
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block:将更新后的queries通过MLP模块进行非线性变换,结果与原queries残差连接并进行LayerNorm
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# 交叉注意力(图像到标记点):再次调整queries和keys加上位置编码,但这次通过cross_attn_image_to_token让图像特征关注标记点特征,更新后的keys与原始keys残差连接并进行LayerNorm
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys「Attention」
Mask Decoder的Attention与ViT的Attention有些细微的不同:
-
Mask Decoder的Attention是3个FC层分别接受3个输入获得q、k和v。
-
ViT的Attention是1个FC层接受1个输入后将结果均拆分获得q、k和v。
如下图所示。
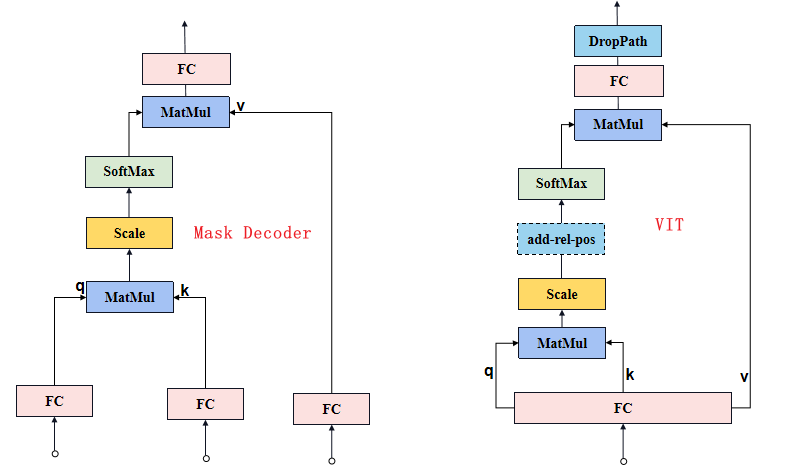
原论文中Attention部分示意图。
python
class Attention(nn.Module):
def __init__(
self,
embedding_dim: int, # 输入特征的维度
num_heads: int, # attention的head数
downsample_rate: int = 1, # 下采样
) -> None:
super().__init__()
self.embedding_dim = embedding_dim
# 内部维度
self.internal_dim = embedding_dim // downsample_rate
self.num_heads = num_heads
assert self.internal_dim % num_heads == 0, "num_heads must divide embedding_dim."
# 四个线性层(全连接层):用于生成query向量、key向量、value向量
self.q_proj = nn.Linear(embedding_dim, self.internal_dim)
self.k_proj = nn.Linear(embedding_dim, self.internal_dim)
self.v_proj = nn.Linear(embedding_dim, self.internal_dim)
# 用于将注意力机制后的输出投影回原始的特征维度
self.out_proj = nn.Linear(self.internal_dim, embedding_dim)
# 将输入张量分解为多头注意力所需的形状
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
b, n, c = x.shape
x = x.reshape(b, n, num_heads, c // num_heads)
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head
# 在注意力计算后重新组合这些头部
def _recombine_heads(self, x: Tensor) -> Tensor:
b, n_heads, n_tokens, c_per_head = x.shape
x = x.transpose(1, 2)
return x.reshape(b, n_tokens, n_heads * c_per_head) # B x N_tokens x C
def forward(self, q: Tensor, k: Tensor, v: Tensor) -> Tensor:
# 输入投影:分别使用q_proj、k_proj和v_proj对query、key和value进行线性变换
q = self.q_proj(q)
k = self.k_proj(k)
v = self.v_proj(v)
# 分离头部:将变换后的query、key和value张量按照num_heads进行重塑,以便进行多头注意力计算
# B,N_heads,N_tokens,C_per_head
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# 注意力计算:
# 计算query和key的点积,然后除以c_per_head的平方根进行归一化,以防止数值过大
_, _, _, c_per_head = q.shape
attn = q @ k.permute(0, 1, 3, 2) # B,N_heads,N_tokens,C_per_head
# 归一化Scale
attn = attn / math.sqrt(c_per_head)
# 应用softmax函数得到注意力权重
attn = torch.softmax(attn, dim=-1)
# 使用注意力权重对value进行加权求和,得到注意力输出
out = attn @ v
# # B,N_tokens,C
# 重新组合头部:将多头注意力输出合并回原始的特征维度。
out = self._recombine_heads(out)
# 输出投影:最后,通过out_proj将输出投影回原始的embedding_dim
out = self.out_proj(out)
return out「transformer_MLP」
transformer中MLP的结构如下图所示。
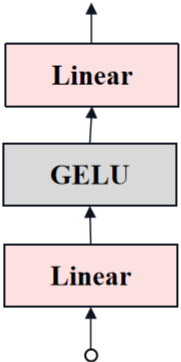
python
# MLPBlock类是一个简单的多层感知机(MLP)模块,由两个全连接层(Linear)和一个激活函数组成
class MLPBlock(nn.Module):
def __init__(
self,
# 输入的维度,通常是特征向量的长度
embedding_dim: int,
# MLP中间层的宽度,可以设置为比输入维度更大的值以增加模型的表达能力
mlp_dim: int,
# 激活函数,这里默认使用GELU
act: Type[nn.Module] = nn.GELU,
) -> None:
super().__init__()
# 第一个全连接层,将输入从embedding_dim维度变换到mlp_dim维度
self.lin1 = nn.Linear(embedding_dim, mlp_dim)
# 第二个全连接层,将mlp_dim维度的结果变换回embedding_dim维度,以保持与输入相同的维度
self.lin2 = nn.Linear(mlp_dim, embedding_dim)
# 激活函数实例,用于在全连接层之间引入非线性
self.act = act()
# 接收输入张量x,将其传递给lin1,然后应用激活函数act。
# 将激活函数的输出传递给lin2,得到最终的输出张量
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.lin2(self.act(self.lin1(x)))「upscaled」
这个上采样过程将Transformer的输出特征图恢复到更接近输入图像的分辨率,以便于生成掩模预测。upscaled的结构如下图所示。

python
# 在MaskDecoder的__init__定义
# output_upscaling是一个序列模块,用于上采样Transformer输出的特征图
self.output_upscaling = nn.Sequential(
# 使用nn.ConvTranspose2d,输入通道数为transformer_dim,输出通道数为transformer_dim // 4,内核大小为2,步长为2
# 将特征图的尺寸放大两倍,同时将通道数减半
# 内核大小为2的转置卷积相当于上采样2倍,步长为2确保输出尺寸翻倍
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), #转置卷积 上采样2倍
# 层归一化(LayerNorm2d)
LayerNorm2d(transformer_dim // 4),
# 激活函数
activation(),
# 再次使用nn.ConvTranspose2d,输入通道数为transformer_dim // 4,输出通道数为transformer_dim // 8,内核大小为2,步长为2。这一步继续将特征图的尺寸放大两倍,同时通道数再次减半
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
# 重复激活函数的过程,以进一步增强非线性表达
activation(),
)
# 在MaskDecoder的predict_masks添加位置编码
upscaled_embedding = self.output_upscaling(src)「mask_MLP」
此处的MLP基础模块不同于ViT的MLP(transformer_MLP)基础模块。
python
# 在MaskDecoder的__init__定义
# output_hypernetworks_mlps是一个nn.ModuleList,包含了多个多层感知机(MLP)。每个MLP的目的是根据输入的mask_tokens_out生成特定掩模的超网络权重
self.output_hypernetworks_mlps = nn.ModuleList(
[
# transformer_dim: Transformer的输出维度,也是输入到MLP的通道数
# transformer_dim // 8: MLP的输出通道数,用于生成超网络的权重
# 3: MLP的中间层维度,用于增加模型的表达能力
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
# 在MaskDecoder的predict_masks添加位置编码
# 对于self.num_mask_tokens个掩模token,遍历output_hypernetworks_mlps列表
for i in range(self.num_mask_tokens):
# mask_tokens_out[:, i, :]: B,1,C
# output_hypernetworks_mlps: B,1,c
# 对每个掩模token,应用对应的MLP,输入是mask_tokens_out中对应位置的特征,输出为B, 1, c形状的张量,其中c是超网络的输出通道数
# 将每个MLP的输出收集到hyper_in_list列表中
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
# B,n,c
# 将hyper_in_list堆叠成一个B, n, c形状的张量hyper_in,其中n是掩模token的数量
hyper_in = torch.stack(hyper_in_list, dim=1)
# 获取upscaled_embedding的形状b, c, h, w,其中b是批次大小,c是通道数,h和w是高度和宽度
b, c, h, w = upscaled_embedding.shape
# B,n,c × B,c,N-->B,n,h,w
# 执行矩阵乘法(@运算符)将hyper_in(B, n, c)与upscaled_embedding(在通道维度上展平为B, c, h * w)相结合
# 计算每个掩模token的超网络权重与上采样特征图的点积,得到B, n, h * w形状的张量
# 通过view操作将结果转换回B, n, h, w形状,生成了masks张量,表示每个掩模token对应的预测掩模
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)「iou_MLP」
此处的MLP基础模块不同于ViT的MLP(transformer_MLP)基础模块。
python
# 在MaskDecoder的__init__定义
# 一个多层感知机(MLP)模块,其目的是预测每个掩模token对应的IoU(Intersection over Union,交并比)值,以评估预测掩模与真实掩模的重合程度
self.iou_prediction_head = MLP(
# transformer_dim: 输入到MLP的特征维度,通常与Transformer的输出维度相同
# iou_head_hidden_dim: MLP中间层的维度,用于增强模型的表达能力
# self.num_mask_tokens: 输出维度,即预测的掩模令牌数量,每个令牌对应一个IoU预测值
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
# 在MaskDecoder的predict_masks添加位置编码
iou_pred = self.iou_prediction_head(iou_token_out)「MaskDeco_MLP」
Mask Decoder中MLP的结构如下图所示。
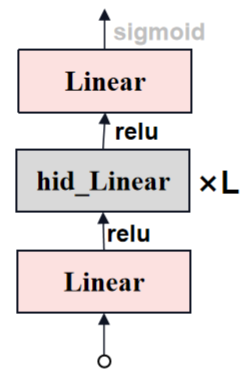
python
'''
定义了一个多层感知机,它包含一个可配置的隐藏层数目、输入和输出维度,并可以选择是否在输出层应用Sigmoid激活函数
'''
class MLP(nn.Module):
def __init__(
self,
input_dim: int, # 输入特征的维度,即输入张量的通道数
hidden_dim: int, # 隐藏层的通道数,中间层的宽度
output_dim: int, # 输出特征的维度,即输出张量的通道数
num_layers: int, # 多层感知机的层数,包括输入层和输出层
sigmoid_output: bool = False, # 一个布尔值,表示是否在输出层应用Sigmoid激活函数,默认为False
) -> None:
'''
内部组件
'''
super().__init__()
# 存储输入的层数
self.num_layers = num_layers
# 一个列表,包含num_layers - 1个hidden_dim,用于构建中间层的线性变换
h = [hidden_dim] * (num_layers - 1)
# 一个nn.ModuleList,包含num_layers个线性层(全连接层),每个层的输入和输出通道数由h和input_dim、output_dim决定
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
def forward(self, x):
# 对输入张量x,遍历layers列表中的每个线性层
for i, layer in enumerate(self.layers):
# 如果当前层不是最后一层,应用ReLU激活函数(F.relu)
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
# 如果sigmoid_output为True,最后对输出应用Sigmoid激活函数
if self.sigmoid_output:
x = F.sigmoid(x)
return x