目录
- 回顾
-
- 数据库的问题
- [如何提高 mysql 能承担的并发量?](#如何提高 mysql 能承担的并发量?)
- 缓存解决方案应对的场景
- 缓存更新
- 内存淘汰策略
- 缓存预热
- 缓存和数据库数据同步问题
- 缓存一致性解决方案
回顾
数据库的问题
- 数据库的访问操作速度相对来说比较慢,尤其是一旦短时间内有大量请求来临,就有可能使数据库压力过大,导致宕机。
- 这里通常指的是服务器每次处理一个请求,都要消耗一些硬件资源(cpu、内存、硬盘、网络...)
- 任何一种资源的消耗超出了机器提供的上限,就很容易出现故障了.
如何提高 mysql 能承担的并发量?
-
开源:引入更多的机器,构成数据库集群,例如 主从复制(即使主节点宕机,也可以通过提升从节点为主节点来解决)、分库分表...
-
节流:引入缓存,就是典型的方案. 把一些频繁的读取的热点数据保存到缓存上,后续再查询数据的时候,如果缓存已经存在了,就直接把从缓存上读到的数据返回,也就不在访问 mysql 了.
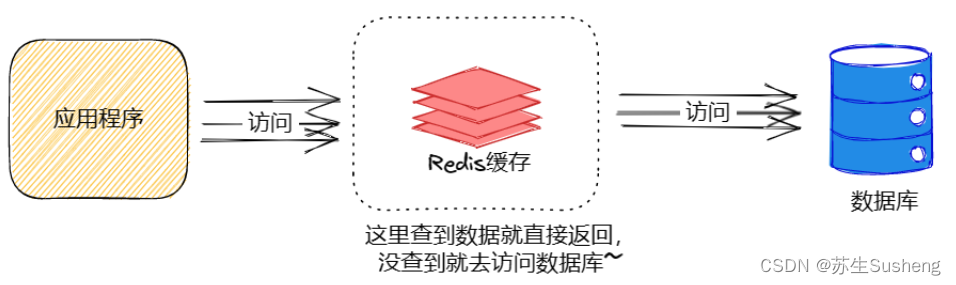
缓存解决方案应对的场景
- 即时性、数据一致性要求不高:引入缓存就会引入一致性问题,因为我们一般都会先去缓存上去读取数据,如果缓存上没有才去数据库中读. 这就导致一旦数据库中的数据发生变化,需要通过 异步/同步 的方式(具体要看业务要求强一致,还是最终一致)来更新缓存上是数据. 如果是异步更新缓存,就可能出现短暂的不一致现象.
- 访问量大,并且更新频率不高的数据(读多写少):更新频率高的数据为了保证数据一致性,会带来更大开销.
例如,电商系统中,商品分类,热门的商品等都适合缓存并设置一个过期时间(根据数据更新频率而定). 比如后台发布一个商品,买家需要 5 分钟才能看到一个商品一般还是可以接受的.
缓存更新
问题
在实际的工作中,如何知道 redis 中应该存储哪些数据?如何知道哪些数据是热点数据呢
定期生成
- 每隔⼀定的周期 (比如⼀天/⼀周/⼀个⽉) , 对于访问的数据频次进⾏统计,并以日志的形式记录下来,最后挑选出访问频次最⾼的前 N% 的数据,放到缓存中。例如搜索引擎:
- 搜索引擎的 "查询词" 就是要关注的 "访问的数据",通过日志,把每天(也可以按一周、一月)都使用到了哪些词,给记录下来,就可以针对这些日志进行统计
- 这里的统计数据量非常大,需要写个程序来统计,数量大到可能需要使用分布式系统来存储日志 HDFS,统计这一天中,每个词出现的频率,再根据频率降序排序,提取出 前 20% 的词,就可以认为这些词是 "热点词" 。
- 接下来就可以把这些热点词,以及涉及到的搜索结构都提前拎出来,放到类似 " redis" 这样的缓存中了。
如何定期统计
- 可以写一套离线流程(往往使用 shell,python 写脚本代码),然后通过 定时任务 来触发(一天更新一次、一个月更新一次等),具体如下:
- 完成统计热词的过程.
- 根据热词,找到搜索结果的数据.
- 把得到缓存数据同步到缓存服务器上.
- 控制这些缓存服务器自动重启.
定期生成的优缺点
-
优点:实现起来比较简单,过程可控(缓存中有什么东西,是比较固定的),方便排查问题.
-
缺点:实时性不够,如果出现一些突发性的事件,出现了一些新的热点词,新的热词就可能对数据库带来较大的压力(缓存中查询没有,直接打到数据库),例如,过年的前几天,"春节晚会" 这个词就会变的特别高频、或者是某个突发的新闻等
实时生成
- 先给缓存设定容量上限(可以通过 Redis 配置⽂件的 maxmemory 参数设定)。之后用户每次查询:
- 如果在 Redis 中查到了,就直接返回.
- 如果 Redis 中没有,就从数据库查询,在把查到的结果写入 Redis.
- 经过一段时间的 "动态平衡" ,redis 中的 key 就逐渐变成了热点数据。
- redis.conf中的maxmemory这个值表示对redis的内存使用,maxmemory为0的时候表示我们对Redis的内存使用没有限制。
maxmemory 设置成多少合适呢?
合适的maxmemory设置取决于你的具体场景和需求。以下是一些考虑因素:
-
系统内存容量:首先需要考虑系统的内存容量。maxmemory的值不能超过系统的可用内存,否则可能导致系统性能下降或崩溃。
-
数据规模:maxmemory的设置也要考虑数据规模。如果你的数据量很大,可以设置较大的maxmemory值,以便更多的数据可被缓存。但是如果数据量较小,设置过大的maxmemory可能会导致过度消耗系统资源。
-
缓存需求:根据你的缓存需求,确定需要缓存的数据量和存活时间。如果需要缓存大量的数据且存活时间较长,可能需要更大的maxmemory。如果只需缓存一小部分数据或数据存活时间较短,可以设置较小的maxmemory。
-
可扩展性:考虑到未来的数据增长,可以根据预估的增长率来设置较大的maxmemory,以便保证在未来一段时间内不会出现内存不足的情况。
项目类型上来说
- 小型项目:对于内存需求较小的小型项目,通常可以将maxmemory设置为较低的值,例如100MB到500MB。这样的设置可以满足基本的缓存和存储需求,同时不会消耗过多的系统资源。
- 中型项目:对于中型项目,可能需要处理更多的数据和请求,因此建议将maxmemory设置在500MB到2GB之间。这个范围可以提供足够的内存来支持更复杂的操作和数据存储。
- 大型项目:对于大型项目,可能需要处理大量的数据和高并发的请求。在这种情况下,建议将maxmemory设置在2GB以上,甚至可以达到数十GB或更多。这样可以确保Redis能够有足够的内存来处理大量的数据和请求。
另外,如果开启了Redis的快照功能(RDB或AOF),maxmemory的设置还需要考虑快照文件的大小和频率。为了确保系统的稳定性和性能,建议将maxmemory设置为物理内存的45%(如果开启了快照功能)或系统可用内存的95%(如果没有开启快照功能)
新的问题
redis中这样不停的写,那么redis 中的数据就会越来越多,达到 redis 配置的容量上限之后怎么办?------内存淘汰策略
内存淘汰策略
-
FIFO (First In First Out) :先进先出。把缓存中存在时间最久的 (也就是先来的数据) 淘汰掉.
-
LRU (Least Recently Used) :淘汰最久未使⽤的。记录每个 key 的最近访问时间. 把最近访问时间最⽼的 key 淘汰掉.
-
LFU (Least Frequently Used) :淘汰访问次数最少的。记录每个 key 最近⼀段时间的访问次数. 把访问次数最少的淘汰掉
-
Random 随机淘汰:从所有的 key 中抽取幸运儿被随机淘汰掉
Redis淘汰策略
| 策略 | 说明 |
|---|---|
| volatile-ttl | 相当于 FIFO, 只不过是局限于过期的 key,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰. |
| volatile-lru | 就是 LRU,只不过局限于过期的 key ,当内存不足以容纳新写⼊数据时,从设置了过期时间的key中使⽤LRU(最近最少使用)算法进行淘汰. |
| allkeys-lru | 就是 LRU,针对所有 key ,当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LRU(最近最少使用)算法进行淘汰 |
| volatile-lfu | 就是 LFU,只不过局限于过期的 key, 4.0版本新增,当内存不⾜以容纳新写⼊数据时,在过期的key中,使⽤LFU算法 进行删除key. |
| allkeys-lfu | 就是 LFU,针对所有 key, 4.0版本新增,当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LFU算法进行淘汰. |
| volatile-random | 当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中,随机淘汰数据. |
| allkeys-random | 当内存不⾜以容纳新写⼊数据时,从所有key中随机淘汰数据. |
| noeviction | 默认策略,当内存不⾜以容纳新写⼊数据时,新写⼊操作会报错. |
为什么redis要内存淘汰
Redis需要缓存更新或内存淘汰的原因如下:
-
提高读取性能:Redis将数据存储在内存中,读取速度非常快。通过缓存更新,Redis可以将经常访问的数据保存在内存中,减少读取数据库的次数,从而提高读取性能。
-
减少数据库负载:缓存更新可以减轻数据库的读写压力。当缓存中存在请求的数据时,Redis可以直接从内存中读取,而不需要访问数据库。这样可以减少数据库的读取请求,减轻数据库的负载。
-
解决高并发问题:缓存更新可以有效解决高并发访问数据库的问题。当多个用户同时访问数据库时,通过缓存更新,可以减少对数据库的访问,提高系统的并发性能。
-
空间限制:Redis将数据存储在内存中,而内存是有限的资源。当数据量超过Redis的内存限制时,需要进行内存淘汰操作,即删除一部分数据,以腾出空间存储新的数据。
-
数据过期:Redis中的数据可以设置过期时间,当数据过期时,需要进行内存淘汰操作,将过期的数据从内存中删除,以释放空间。
一句话总结:内存的淘汰机制的初衷是为了更好地使用内存,用一定的缓存miss来换取内存的使用效率。
内存淘汰过程
- 客户端发起了需要申请更多内存的命令(如set)。
- Redis检查内存使用情况,如果已使用的内存大于maxmemory则开始根据用户配置的不同淘汰策略来淘汰内存(key),从而换取一定的内存。
- 如果上面都没问题,则这个命令执行成功。
缓存预热
- 缓存预热是指在系统正式启动运行之前,提前将需要频繁使用的数据加载到缓存中的过程。
- 在系统启动后,缓存中已经有了预先加载的数据,可以提高系统的响应速度和性能。
原因
- 使用缓存预热的主要目的是减少系统的响应时间。
- 当系统启动后,如果没有进行缓存预热,那么用户首次访问某个数据时,系统需要从数据库或其他数据源中获取数据,并将其放入缓存中。
- 这个过程需要时间,因此会导致用户在首次访问时面临较长的等待时间。
- 而通过缓存预热,系统可以在启动之前将热门数据提前加载到缓存中,当用户首次访问时,可以直接从缓存中获取数据,避免了从数据源中获取数据的开销,从而提高了系统的响应速度。
- 此外,缓存预热还可以减轻数据库的压力。通过将热门数据提前加载到缓存中,系统可以减少对数据库的频繁查询,从而减轻数据库的负载,提高系统的稳定性和可靠性。
缓存和数据库数据同步问题
- 引入缓存就会引入和数据库中数据的一致性问题。
- 由于缓存的读写速度远高于数据库,所以在数据库中的数据更新后,缓存中的数据可能会出现不一致的情况
- 例如缓存和数据库中都保存了商品信息,但是数据库中的商品数据被修改了,那么缓存上的数据也应该被更新,否则就会导致用户下次访问的时候还是读取的缓存上的旧数据
解决方案
-
主动更新:在数据库中进行数据更新的同时,主动更新缓存中对应的数据。这可以通过在数据更新操作后,直接调用缓存系统的接口,将数据更新到缓存中。这种方式可以保证数据一致性,但也会增加数据库操作的时间。
-
超时失效:在数据更新之后,可以设置缓存的失效时间,在缓存失效之后,再从数据库中获取最新的数据存入缓存。这样可以避免频繁的数据更新操作,但是会增加读取时的查询延迟。
-
读写穿透处理:在读取缓存数据之前,先查询缓存中是否存在,如果不存在则查询数据库并将数据存入缓存。这样可以避免缓存中的脏数据,但是会增加一定的数据库查询操作。
-
双写策略:在数据更新的同时,先更新数据库,然后异步或延迟更新缓存,以减少对数据库操作的影响。这种方式可以提高系统的性能,但是会带来一定的数据不一致风险。
-
基于事件的缓存更新:通过使用发布订阅模式,当数据库中的数据发生变化时,发布一个事件通知,缓存作为订阅者接收到通知后进行相应的数据更新操作。这种方式可以保证缓存和数据库的数据同步,但是需要引入事件机制和相应的消息队列等组件。
在选择缓存和数据库的同步方案时,需要根据业务需求和系统性能要求进行权衡。每种方案都有其优缺点,需要根据具体场景来选择最合适的解决方案。
缓存一致性解决方案
- 缓存一致性是指缓存中的数据与数据源中的数据保持一致。
- 在使用缓存的系统中,由于系统的高并发和分布式特性,可能会导致缓存中的数据与数据源中的数据存在不一致的情况
问题
对于缓存数据库数据同步问题,无论是双写模式还是失效模式,都可能存在多个实例并发读写导致缓存不一致的问题
- 双写模式:例如有 实例A 和 实例B 同时对同一数据进行双写操作(数据库 + 缓存),但是由于 实例A 在写数据库的时候花费的时间比较长,而此时 实例B 已经双写完成,之后 实例A 才去更新 缓存. 此时,就相当于 实例B 之前写的数据无效.
- 失效模式:例如有 实例A 对数据进行失效模式,但是在写数据库的时候花费的时间比较长,还没来得及删除缓存,此时有一个 实例B 对同一数据进行读取,发现缓存上有,就把这个 实例A 即将要删除的缓存数据读到了
解决方案
-
读写穿透:在查询缓存之前,先查询数据源,如果数据源中不存在该数据,则将该空数据放入缓存,避免了缓存中的"空数据"。这种方法可以减轻缓存雪崩的风险。
-
更新缓存策略:在数据源中进行数据更新时,即时更新缓存中的数据。可以通过以下几种方式实现更新缓存的策略:
-
Cache-Aside模式:在查询数据时,先从缓存中获取数据,如果缓存中不存在,则从数据源中获取数据,并将数据存入缓存。在更新数据时,先更新数据源,再删除缓存中的旧数据,下次查询时会重新加载最新的数据存入缓存。
-
Write-Through模式:在更新数据时,先更新数据源,再更新缓存中的数据,保持数据源和缓存的一致性。
-
Write-Back模式:在更新数据时,先更新缓存中的数据,然后异步更新数据源中的数据,可以提高写操作的性能。
-
-
缓存失效策略:设置合适的缓存失效时间,确保缓存中的数据与数据源中的数据保持一致。可以根据业务需求和数据更新频率来设置缓存的失效时间,避免数据的过期问题。
-
缓存更新通知:当数据源中的数据更新时,主动通知缓存进行数据更新。可以使用发布订阅模式,当数据发生变更时,发送通知给订阅者,缓存作为订阅者接收到通知后进行数据更新。
-
分布式锁:在进行缓存更新时,使用分布式锁来保证只有一个线程可以更新缓存。通过使用分布式锁,可以避免多个线程同时更新缓存导致的并发问题,保证缓存的一致性。