Pandas是一个强大的数据分析库,它内置了基于matplotlib的数据可视化功能,使得直接在DataFrame和Series上进行绘图变得非常方便。在pandas中,.plot()方法允许用户通过kind参数灵活地选择多种图表类型。
导库
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt基本绘图-画线图(Basic plotting): plot
基础时间序列折线图
python
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()
plt.show()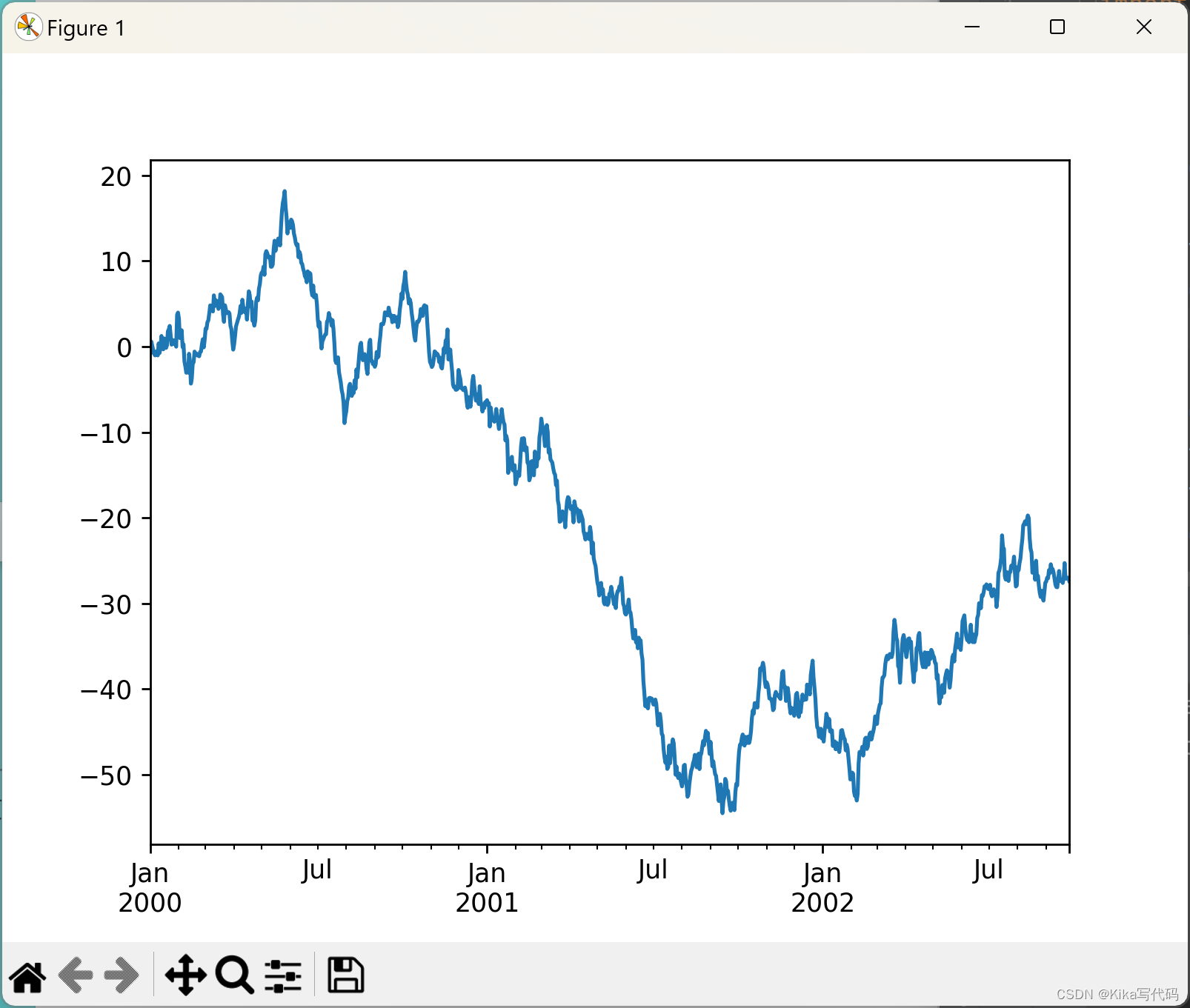
多列
python
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list('ABCD'))
df = df.cumsum()
df.plot()
plt.show()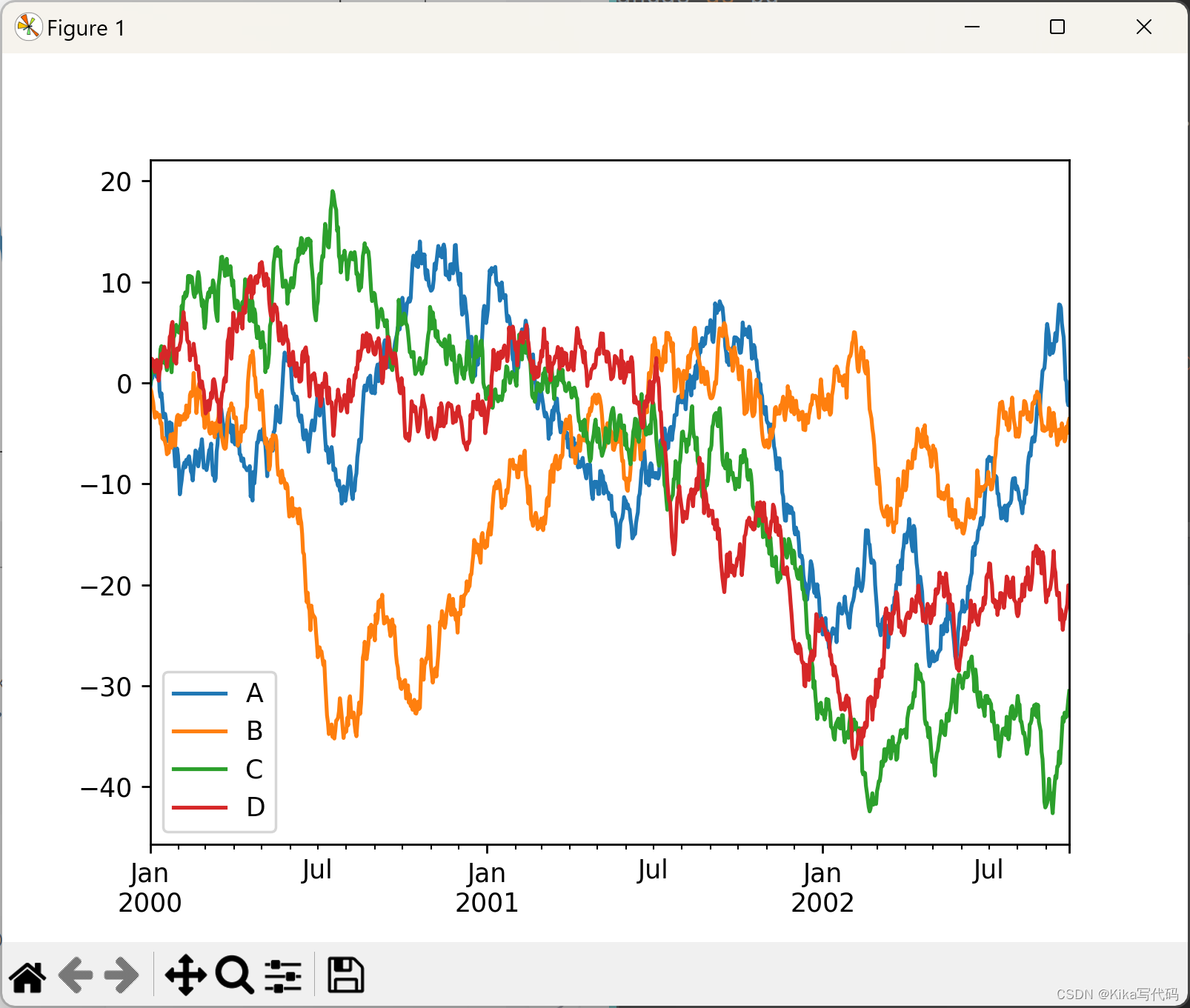
自定义x-y轴绘图
python
df3 = pd.DataFrame(np.random.randn(1000, 2), columns=['B', 'C']).cumsum()
df3['A'] = pd.Series(list(range(len(df))))
df3.plot(x='A', y='B')
plt.show()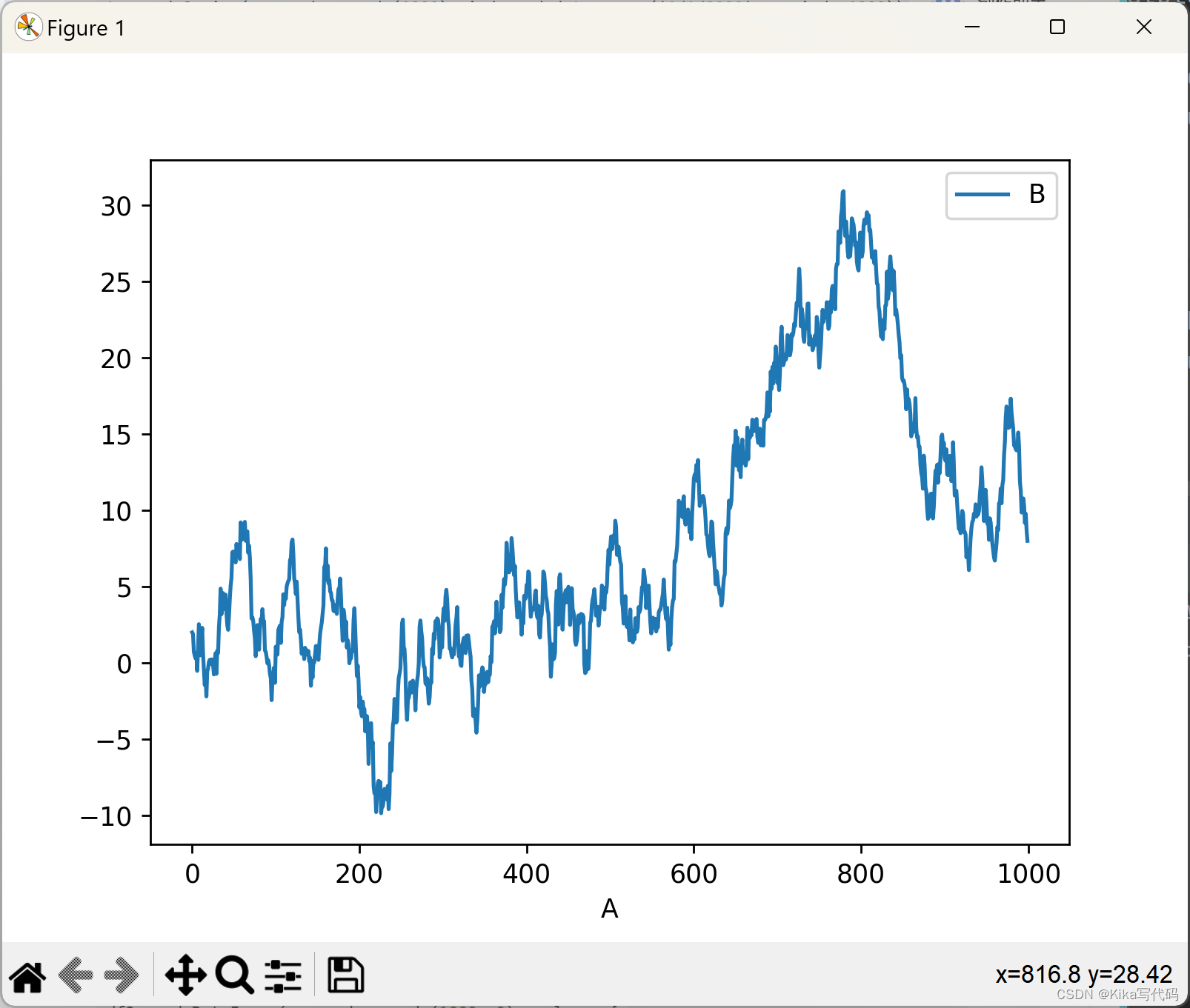
其它图类型(Other plots)
- 条形图 :使用
kind='bar'或kind='barh'创建水平或垂直条形图。 - 直方图 :使用
kind='hist'绘制数据分布的直方图。 - 箱型图 :使用
kind='box'可视化数据分布和异常值。 - 密度图 :使用
kind='kde'或kind='density'绘制。 - 面积图 :使用
kind='area'绘制,类似于折线图,但区域会被填充。 - 散点图 :使用
kind='scatter'展示两个变量之间的关系。 - 六边形分布图 :使用
kind='hexbin'绘制。 - 饼图 :使用
kind='pie'展示各部分占总体的比例。
当然了,您也可以使用DataFrame.plot.方法创建这些其他绘图。而不是提供kind关键字参数。这样可以更容易地发现绘图方法及其使用的特定参数:
pythondf.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
除了这些类型之外,还有使用单独接口的DataFrame.hist()直方图和DataFrame.boxplot()箱线图方法。
最后再扩展一下,pandas.plotting中有几个以Series或DataFrame为参数的绘图函数。其中包括:
- 散点矩阵图 Scatter Matrix:使用
scatter_matrix方法创建。 - Andrews曲线 Andrews Curves:使用
andrews_curves方法展示多变量数据。 - 平行坐标图 Parallel Coordinates:使用
parallel_coordinates方法展示。 - 滞后图 Lag Plot:使用
lag_plot方法检查数据集是否随机。 - 自相关图 Autocorrelation Plot:使用
autocorrelation_plot检查时间序列的随机性。 - Bootstrap图 :使用
bootstrap_plot评估统计量的不确定性。 - RadViz图 :使用
radviz方法可视化多变量数据。
绘图也可以用错误条errorbars或表格tables进行装饰。在创建图表(如线图、柱状图、散点图等)时,除了基本的图表元素(如线条、点、柱子等)外,还可以添加额外的元素来增强图表的信息量和可读性。这里提到的"错误条"和"表格"是两种常见的装饰元素。
bar plots条形图
python
df.iloc[5].plot.bar() # 绘制第5行的条形图
# plt.axhline(0, color='k') # 绘制水平参考线
plt.show()
调用DataFrame的**plot.bar()**方法会生成一个多条形图:
python
df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df2.plot.bar()
plt.show()
想要生成堆叠条形图,可以传参:stacked=True
python
df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df2.plot.bar(stacked=True)
plt.show()
想要获得水平条形图,就改用**barh()**方法:
python
df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df2.plot.barh(stacked=True)
plt.show()
Histograms 直方图
可以使用 DataFrame.plot.hist() 和 Series.plot.hist() 方法绘制直方图。
python
df4 = pd.DataFrame({'a': np.random.randn(1000) + 1, 'b': np.random.randn(1000),
'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df4.plot.hist(alpha=0.5) # 设置alpha=0.5使得直方图半透明,以便于比较重叠部分
plt.show()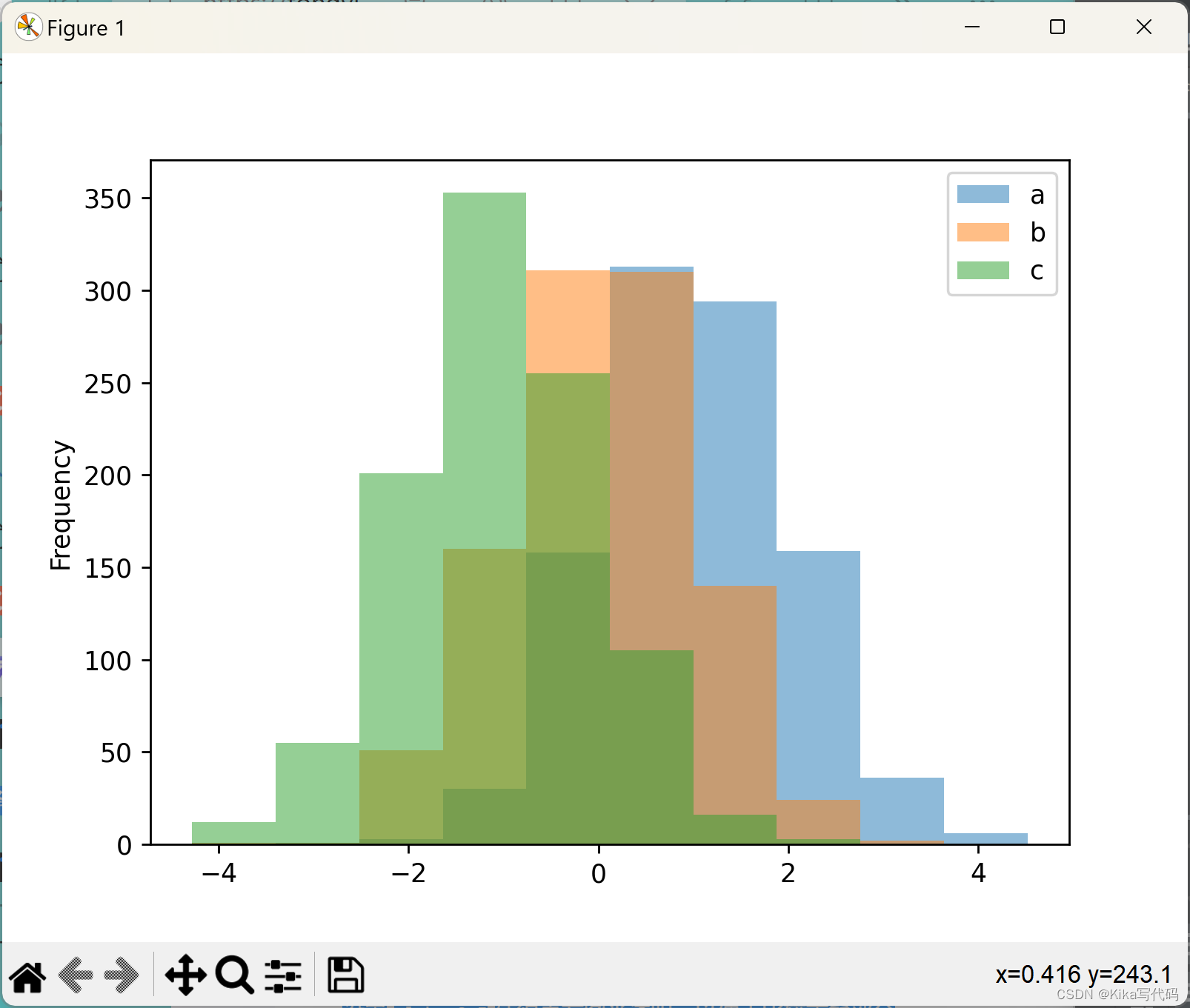
直方图可以使用stacked=True进行堆叠。可以使用bins关键字更改箱大小.
python
df4 = pd.DataFrame({'a': np.random.randn(1000) + 1, 'b': np.random.randn(1000),
'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df4.plot.hist(stacked=True, bins=20)
plt.show()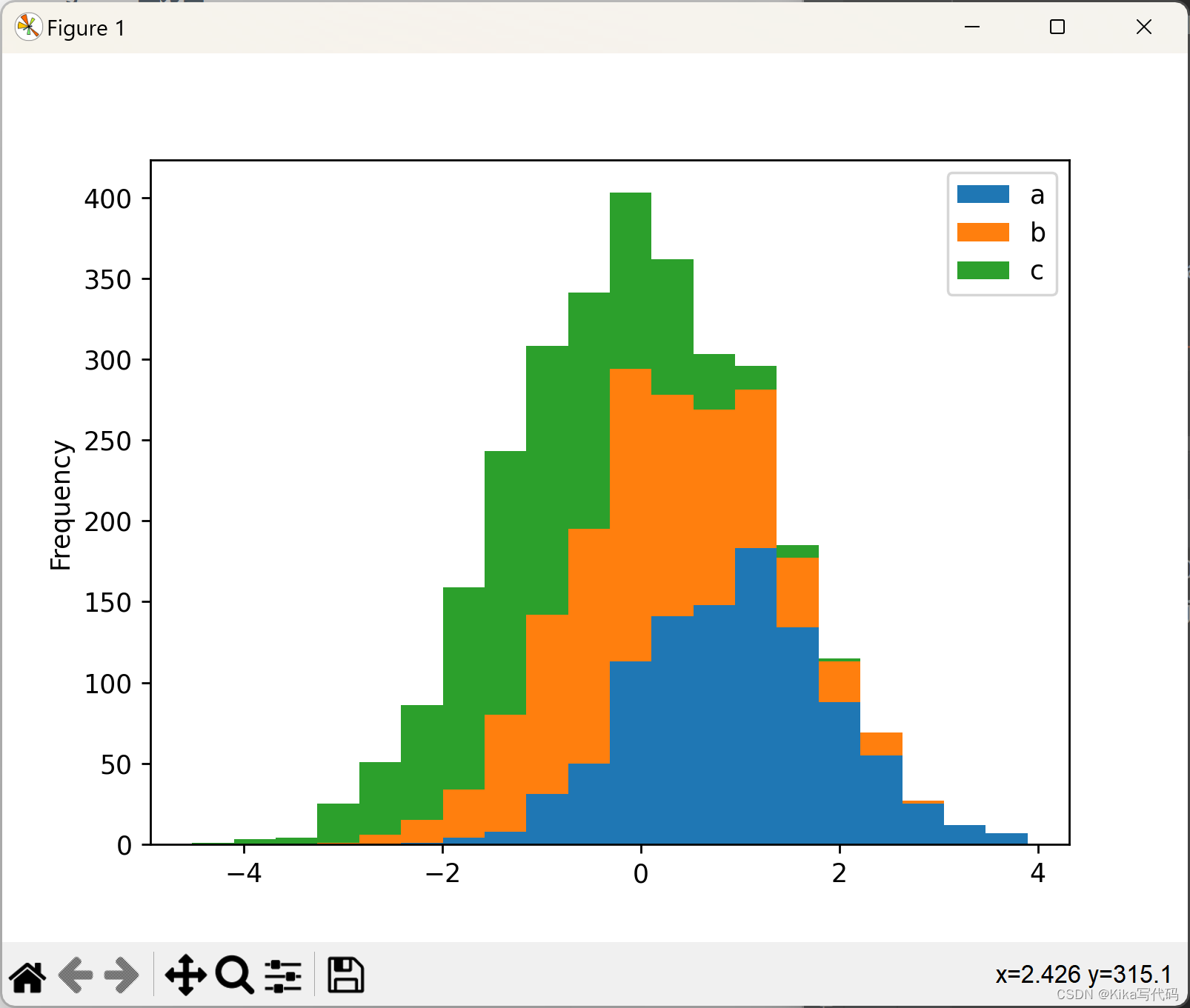
你可以尝试传递matplotlib hist支持的其他关键字。例如,水平直方图和累积直方图可以按orientation='horizontal' 和cumulative=True绘制。
python
df4 = pd.DataFrame({'a': np.random.randn(1000) + 1, 'b': np.random.randn(1000),
'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df4['a'].plot.hist(orientation='horizontal', cumulative=True)
plt.show()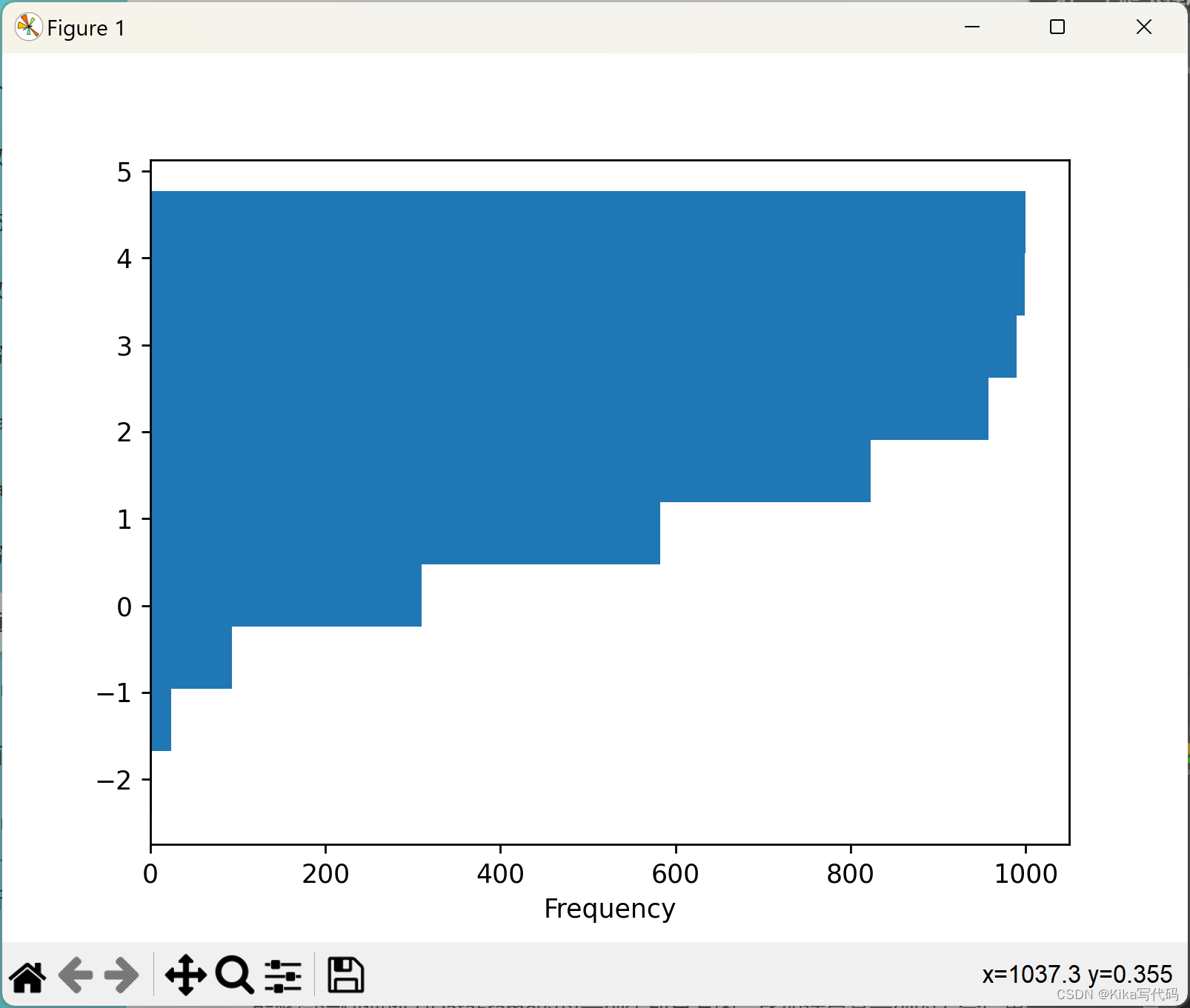
使用传统接口DataFrame.hist:
python
df4 = pd.DataFrame({'a': np.random.randn(1000) + 1, 'b': np.random.randn(1000),
'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df4['a'].diff().hist()
plt.show()
计算数据差异 (
df['A'].diff()) :df['A']表示选择DataFramedf中的名为'A'的列。.diff()方法用于计算该列中每个元素与其前一个元素的差值。默认情况下,.diff()方法计算的是相邻行之间的差异。例如,如果'A'列包含1, 2, 3, 4,那么df['A'].diff()的结果将是NaN, 1, 1, 1,因为第一行没有前一个元素,所以是NaN(表示"不是一个数字"的值)。绘制直方图 (
.hist()) :.hist()是matplotlib库中用于绘制数据直方图的方法。在计算了差异之后,.hist()方法会被调用来显示这些差异的分布情况。
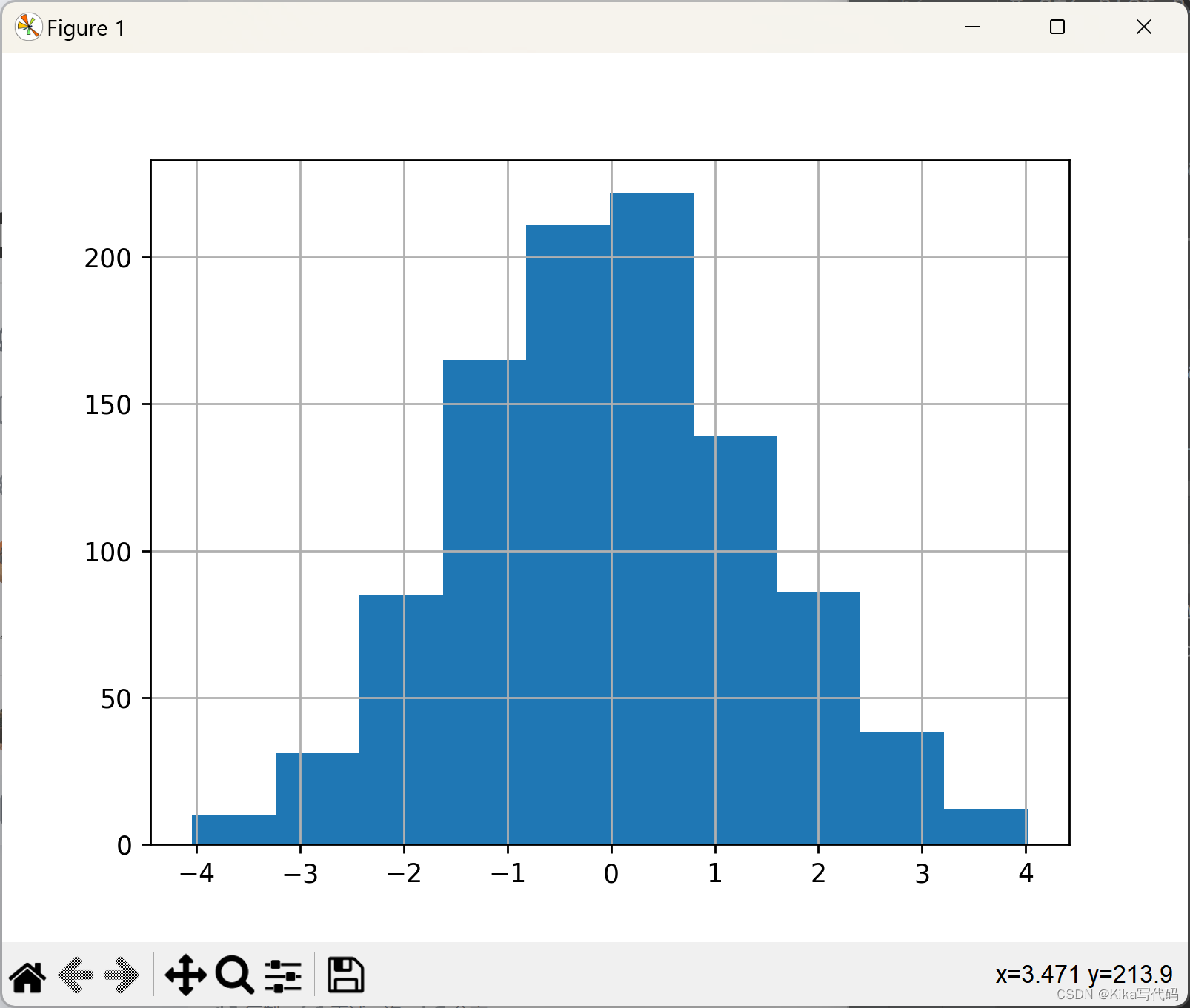
多列直方图与子图布局
对于多列数据,直接调用DataFrame.hist()会自动在子图中为每列生成直方图,这是快速概览整个数据集分布的理想方式。此外,可以通过调整figsize来控制图表的整体尺寸。
python
df4 = pd.DataFrame({'a': np.random.randn(1000) + 1, 'b': np.random.randn(1000),
'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df4.diff().hist(color='k', alpha=0.5, bins=50)
plt.show()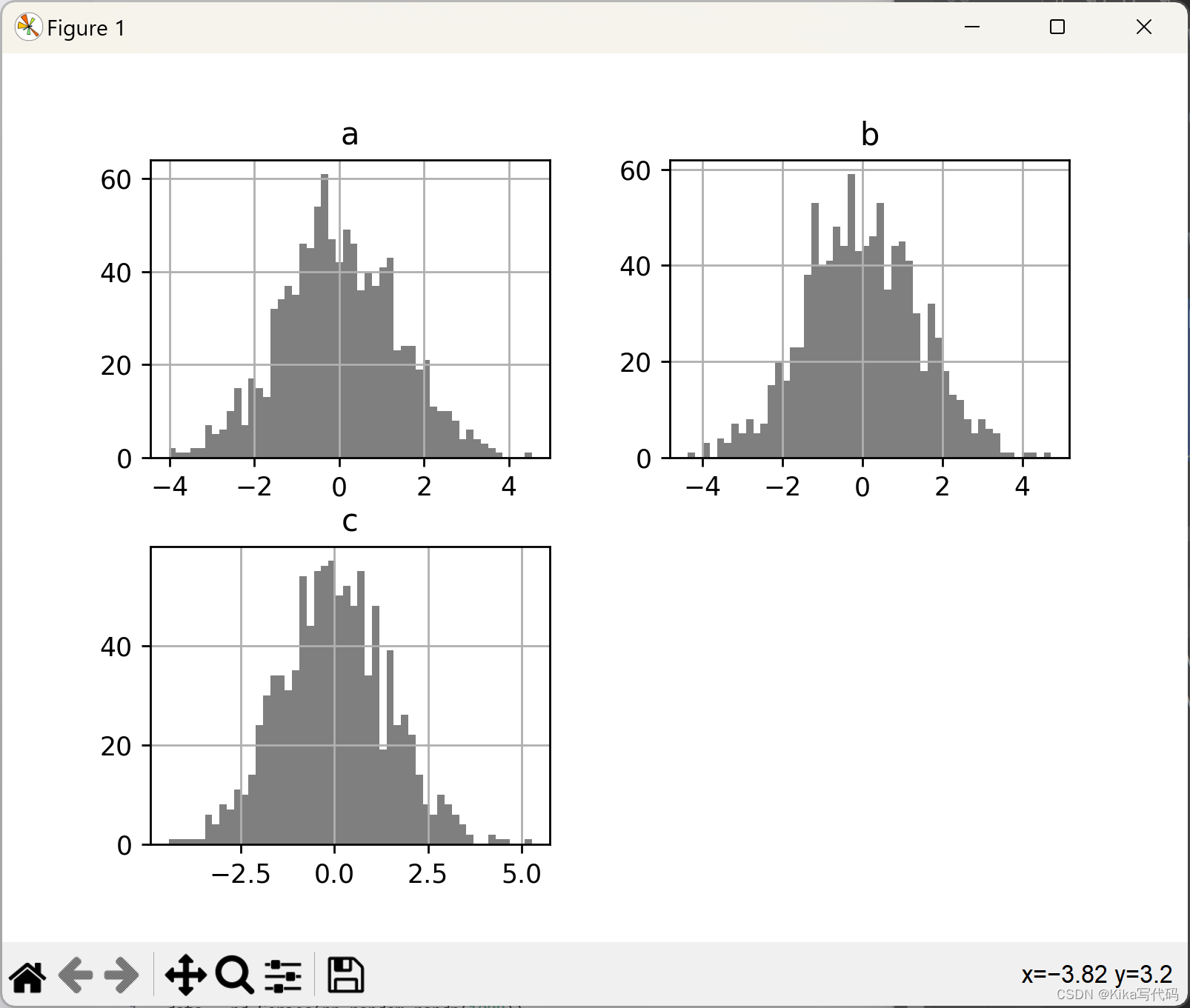
分组直方图:按类别分析
在处理分类数据时,通过by参数,我们可以对数据进行分组并绘制分组直方图,这对于探索不同群体间的差异尤为关键。比如,基于随机分配的整数标签来绘制不同组的数据分布直方图。
python
data = pd.Series(np.random.randn(1000))
data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4))
plt.show()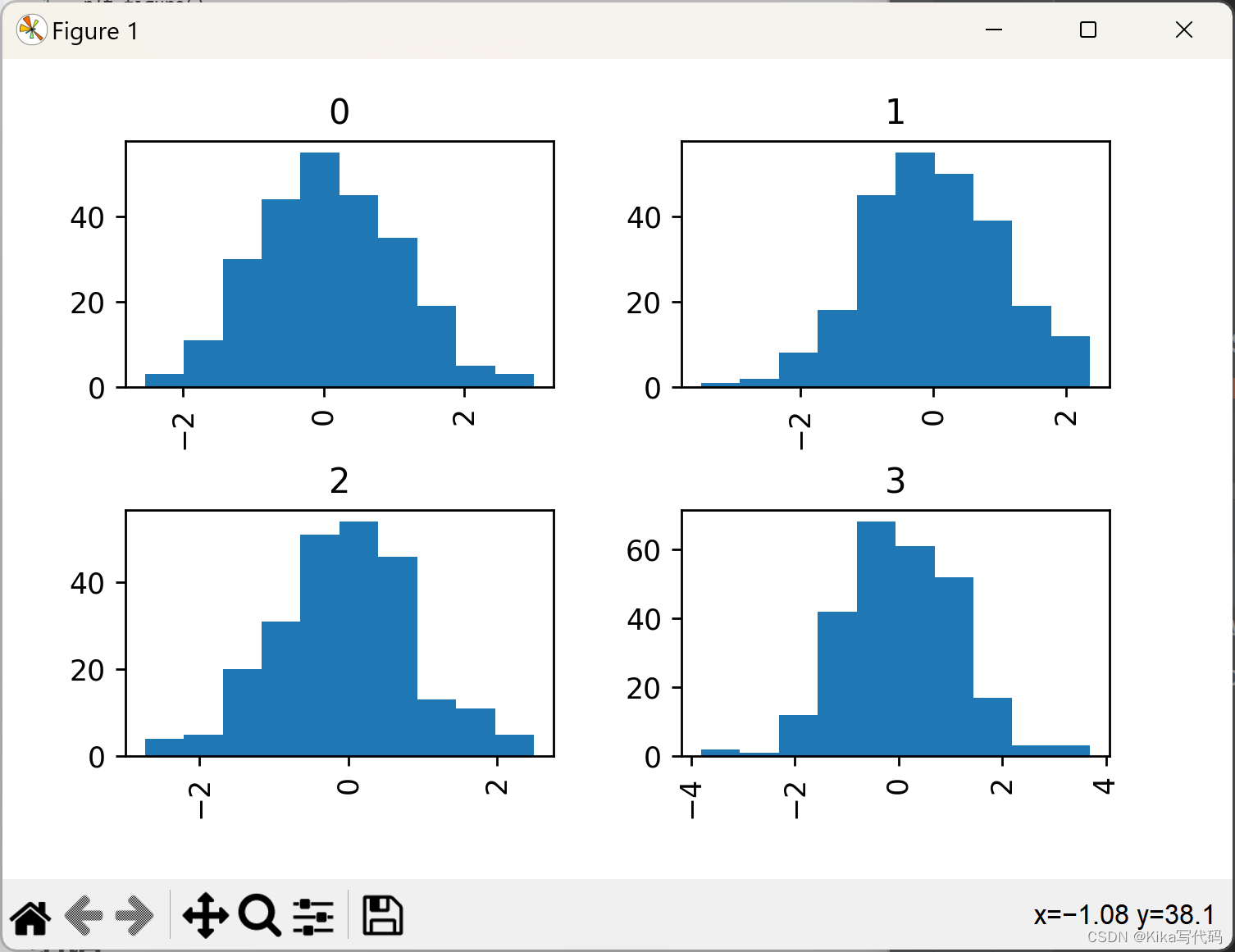
Box plots 箱型图
箱型图可以通过调用 Series.plot.box() 或 DataFrame.plot.box() 方法,或者 DataFrame.boxplot() 方法来绘制,以便可视化每个列中值的分布。
例如,这个箱线图,它表示在[0,1)区间上的均匀随机变量进行的五次试验,每次试验包含10个观测值。
python
df = pd.DataFrame(np.random.rand(10, 5), columns=['A', 'B', 'C', 'D', 'E'])
# df.plot.box()
df.plot(kind='box')
plt.show()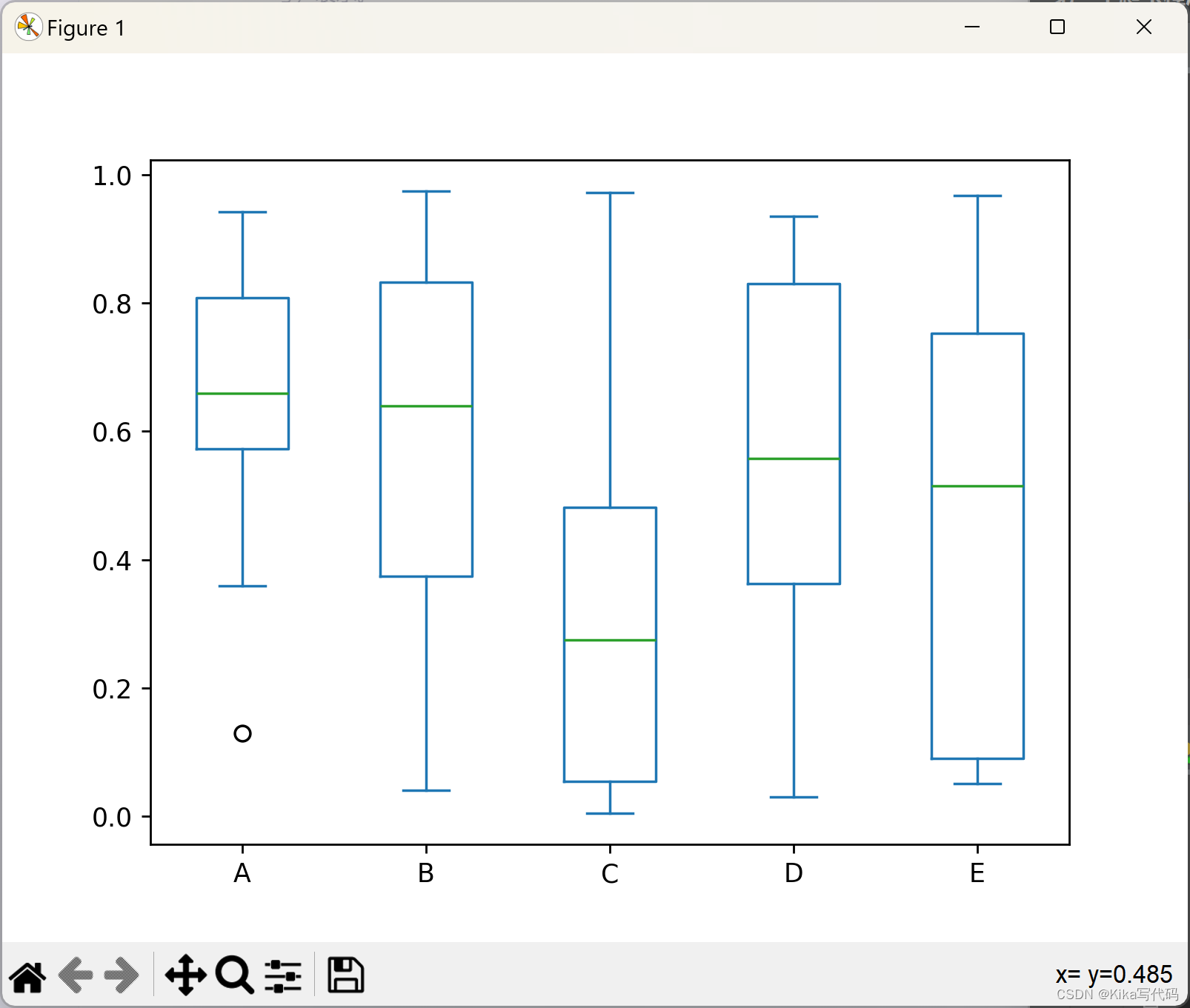
箱线图(Boxplot)的颜色可以通过传递color关键字进行定制。你可以传递一个字典,其键为boxes(箱体)、whiskers(须线)、medians(中位数)和caps(箱盖)。如果字典中缺少某些键,则将使用默认颜色。此外,boxplot还有一个sym关键字用于指定异常值(fliers)的样式。
python
color = {'boxes': 'DarkGreen', 'whiskers': 'DarkOrange',
'medians': 'DarkBlue', 'caps': 'Gray'}
df.plot.box(color=color, sym='r+')
# df.plot(kind='box', color=color, sym='r+')
plt.show()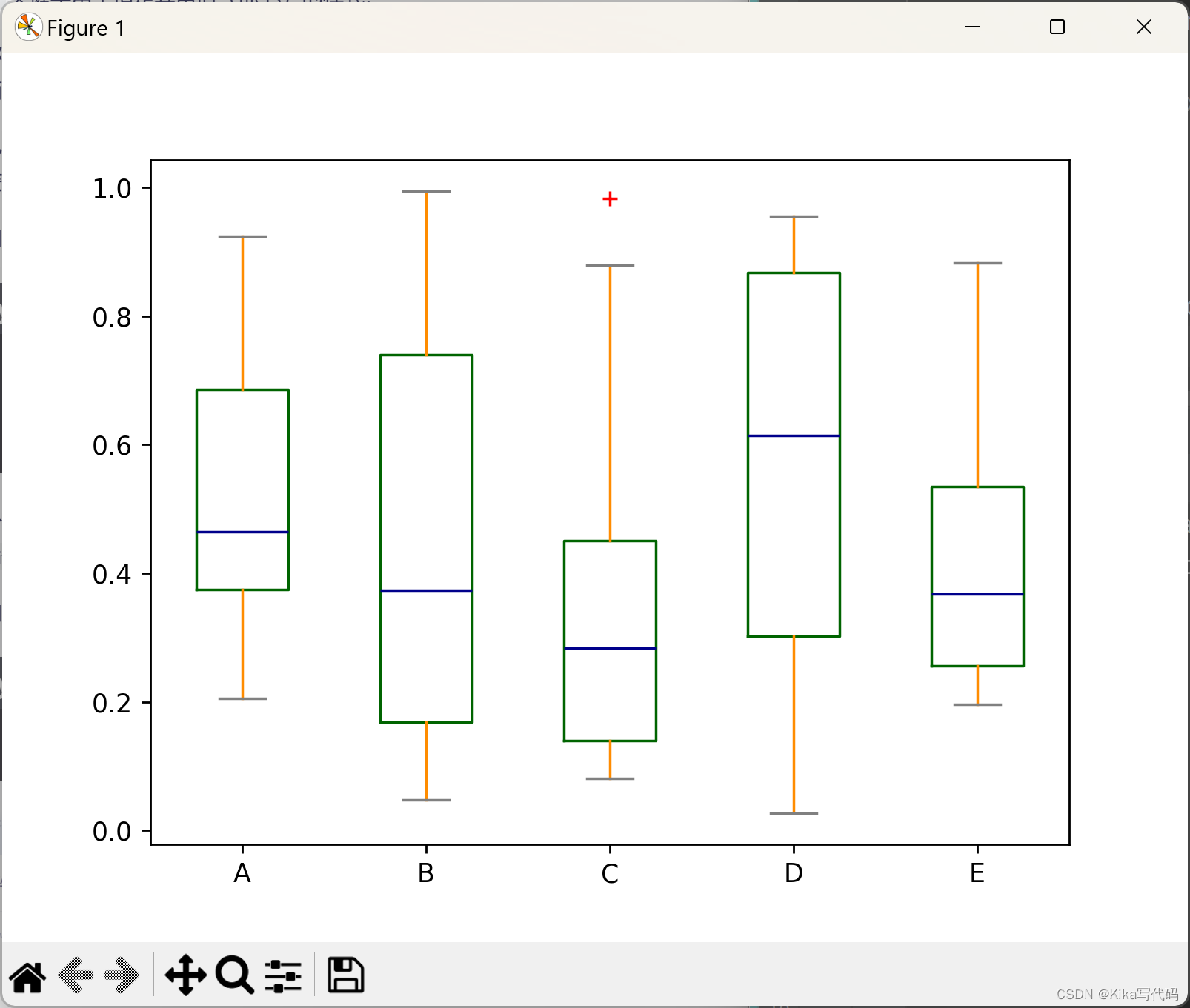
此外,通过vert参数可以控制箱形图的方向,将其设为False可以得到水平箱形图。
同时,positions参数可以用来指定各个箱形图的位置:
python
df.plot.box(vert=False, positions=[1, 4, 5, 6, 8]) # 水平箱形图并自定义位置
plt.show()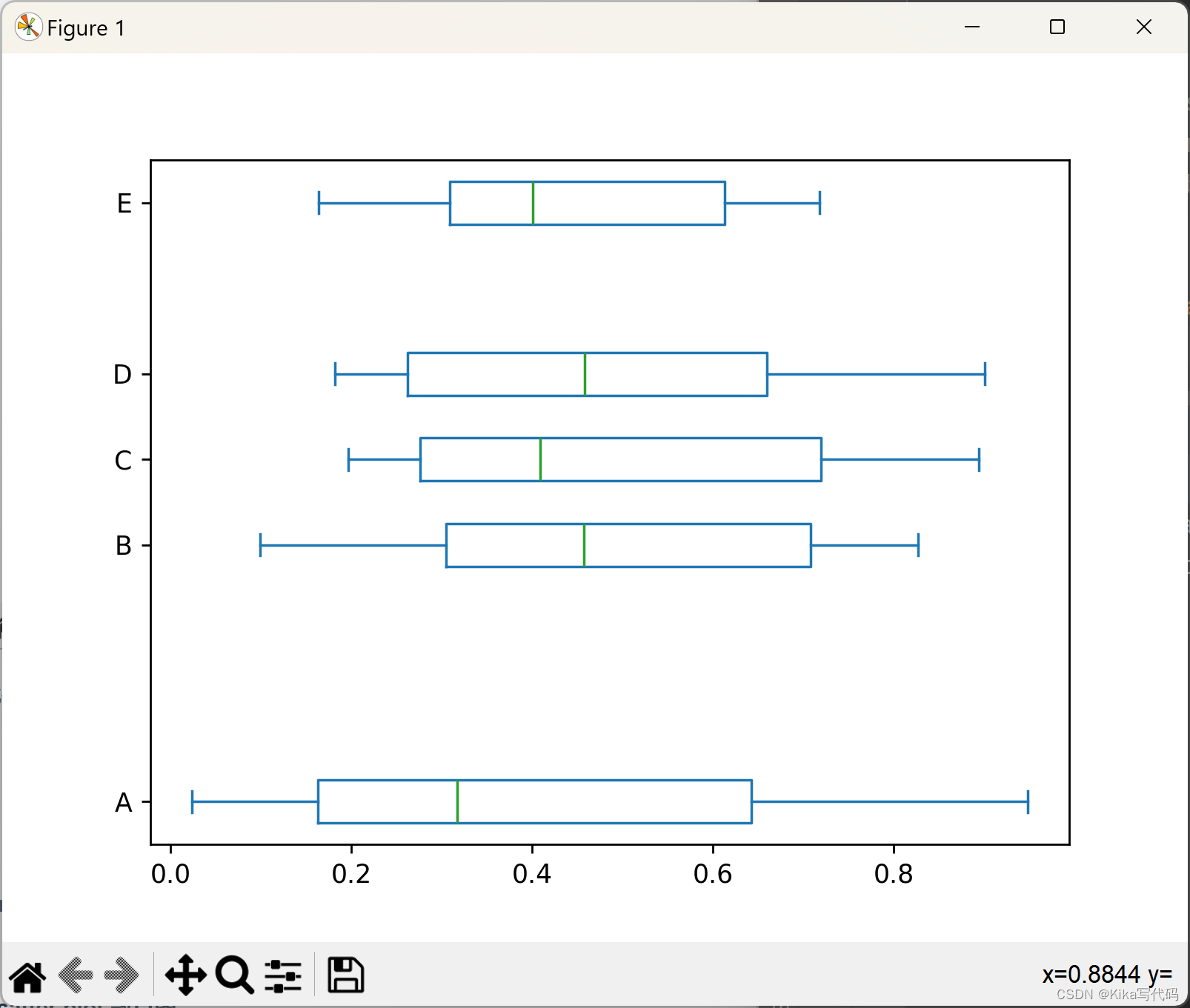
接口 DataFrame.boxplot
python
df.boxplot()
plt.show()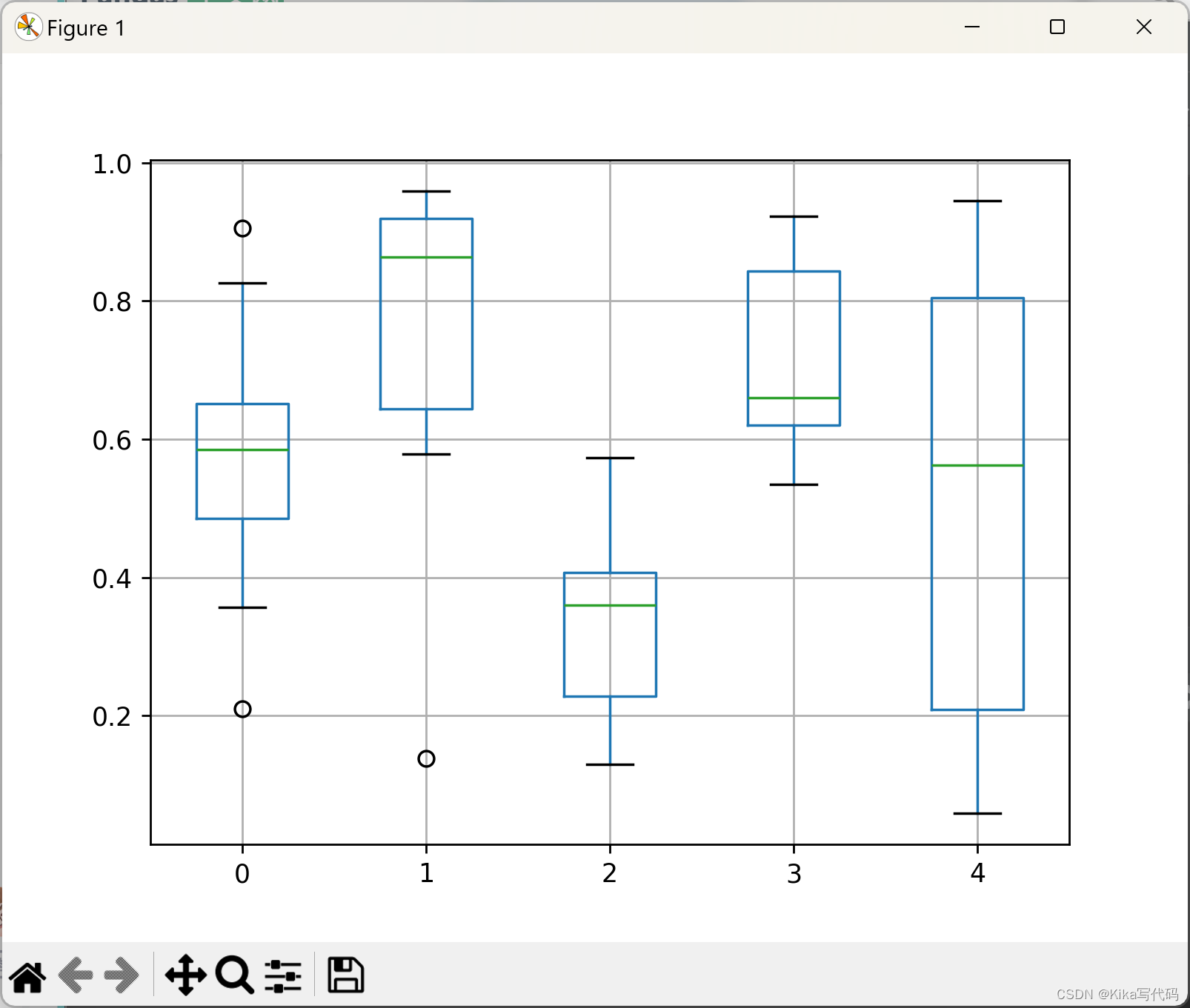
使用by参数可以依据某个或某几个列对数据进行分组,从而绘制分层箱形图。这有助于比较不同组之间的数据分布差异:
python
df['Group'] = ['Group1'] * 5 + ['Group2'] * 5 # 添加分组列
bp = df.boxplot(by='Group') # 按'Group'列分组绘制箱形图
plt.show()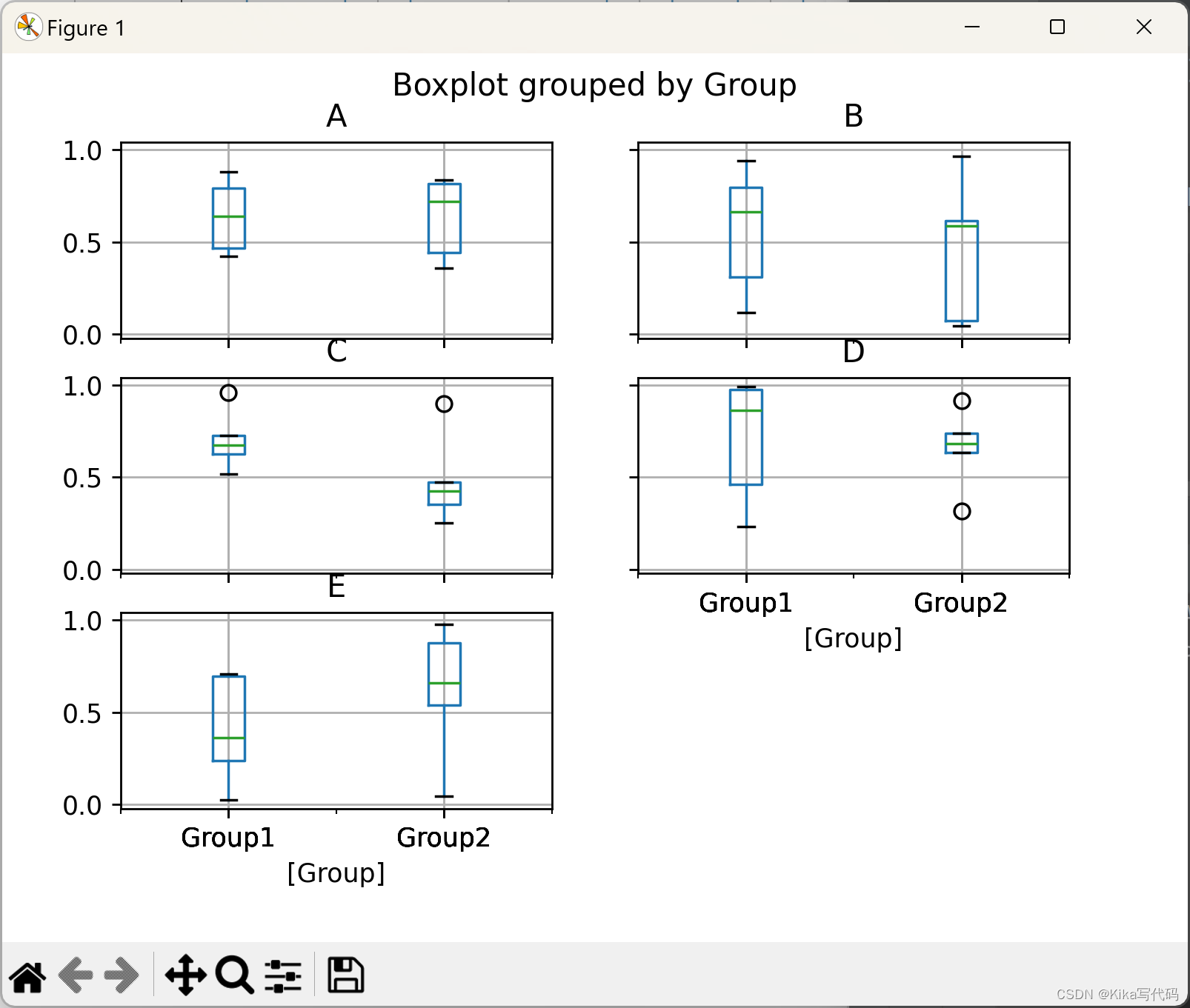
在绘制箱形图时,可以指定只绘制DataFrame中的部分列,并且支持按多个列进行分组,以便进行更细致的比较分析:
python
df['Category'] = ['Cat1', 'Cat2'] * 5 # 添加另一 分组列
bp = df.boxplot(column=['A', 'B'], by=['Group', 'Category'], figsize=(10, 4)) # 按'Group'和'Category'分组,仅绘制'A'和'B'列
plt.tight_layout()
plt.show()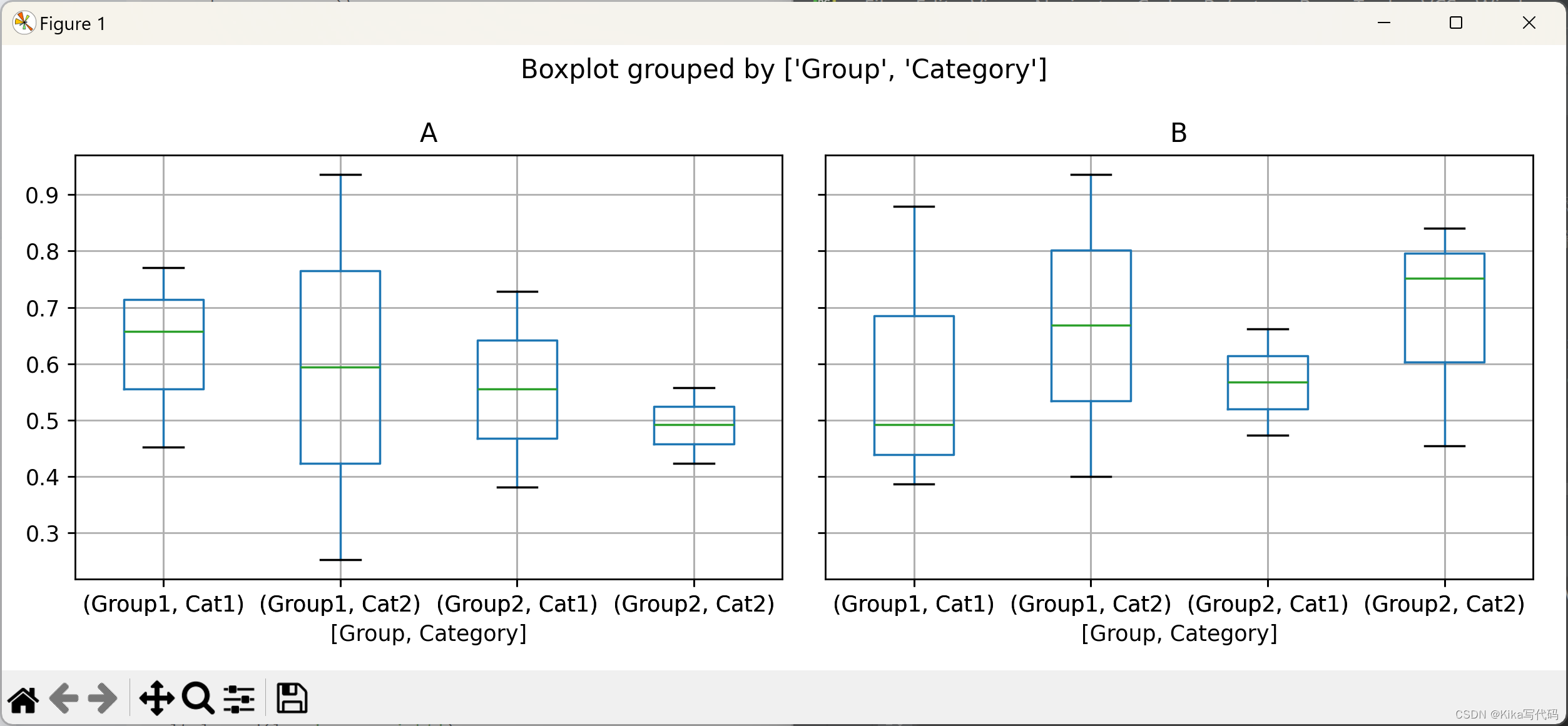
Area plot 面积图
面积图是一种将数据分布随时间或类别变化展现出来的图形方法,特别适合于表现每个部分如何共同构成整体的情况。在Pandas中,可以使用Series.plot.area()和DataFrame.plot.area()方法来创建面积图。默认情况下,面积图是堆叠式的,也就是说,当你绘制的是DataFrame时,每一列的数据会在图上堆叠起来,形成层次分明的区域。
要生成堆叠 面积图,要求DataFrame的每一列要么全是正数,要么全是负数,这样才能保证堆叠的效果清晰且具有意义。
如果输入数据中包含NaN值,Pandas会自动将这些缺失值填充为0来进行绘图。不过,如果你想在绘图前去掉NaN值或者用其他值填充,可以先使用dataframe.dropna()或dataframe.fillna()方法处理数据。
例如,下面的代码演示了如何生成一个默认的堆叠面积图:
python
df = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df.plot.area()
plt.show()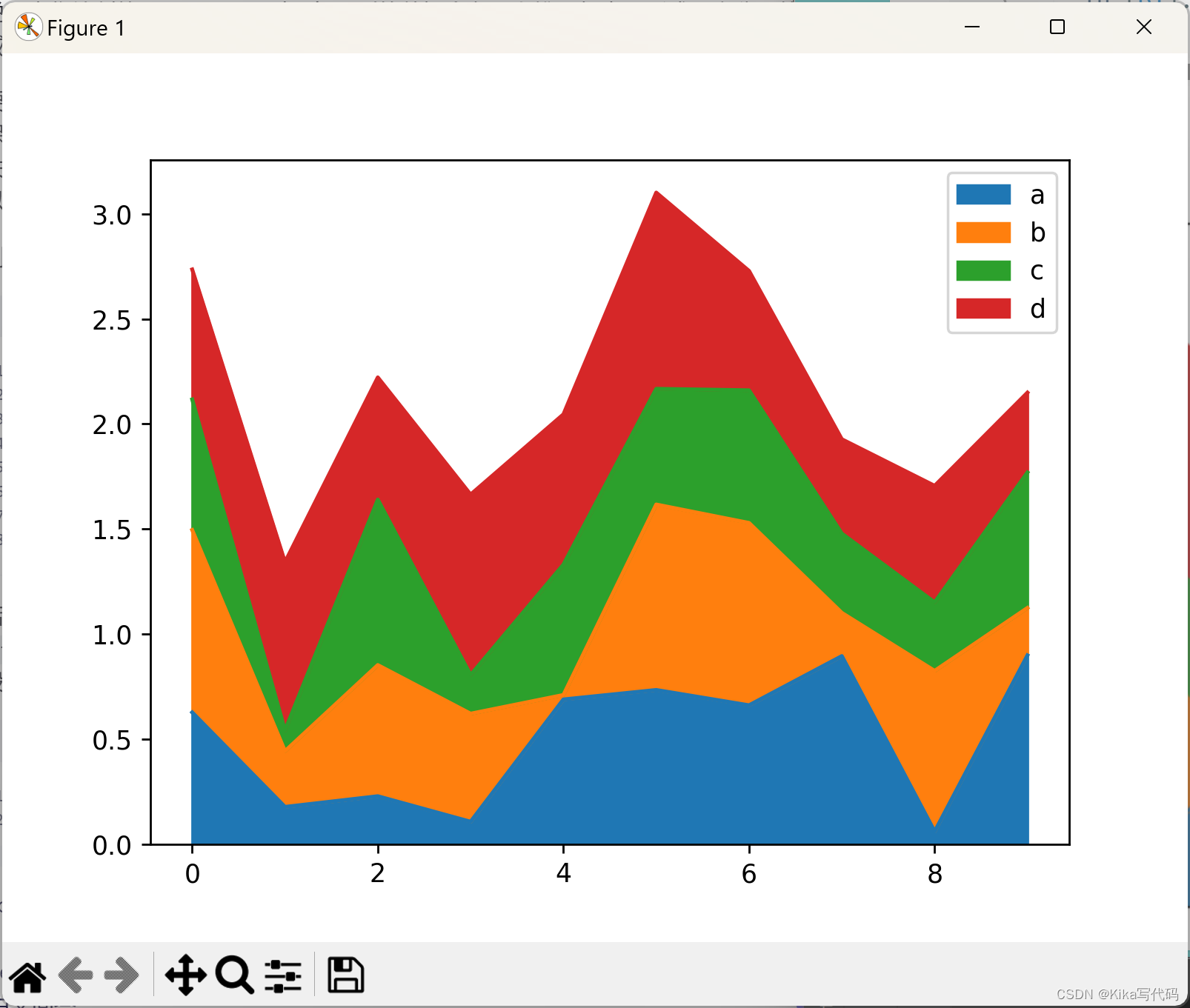
若要绘制非堆叠的面积图,即每一部分不互相覆盖,只需在调用plot.area()时设置stacked=False。
同时,未特别指定的情况下,非堆叠面积图的透明度(alpha值)默认设置为0.5,以便于区分重叠部分:
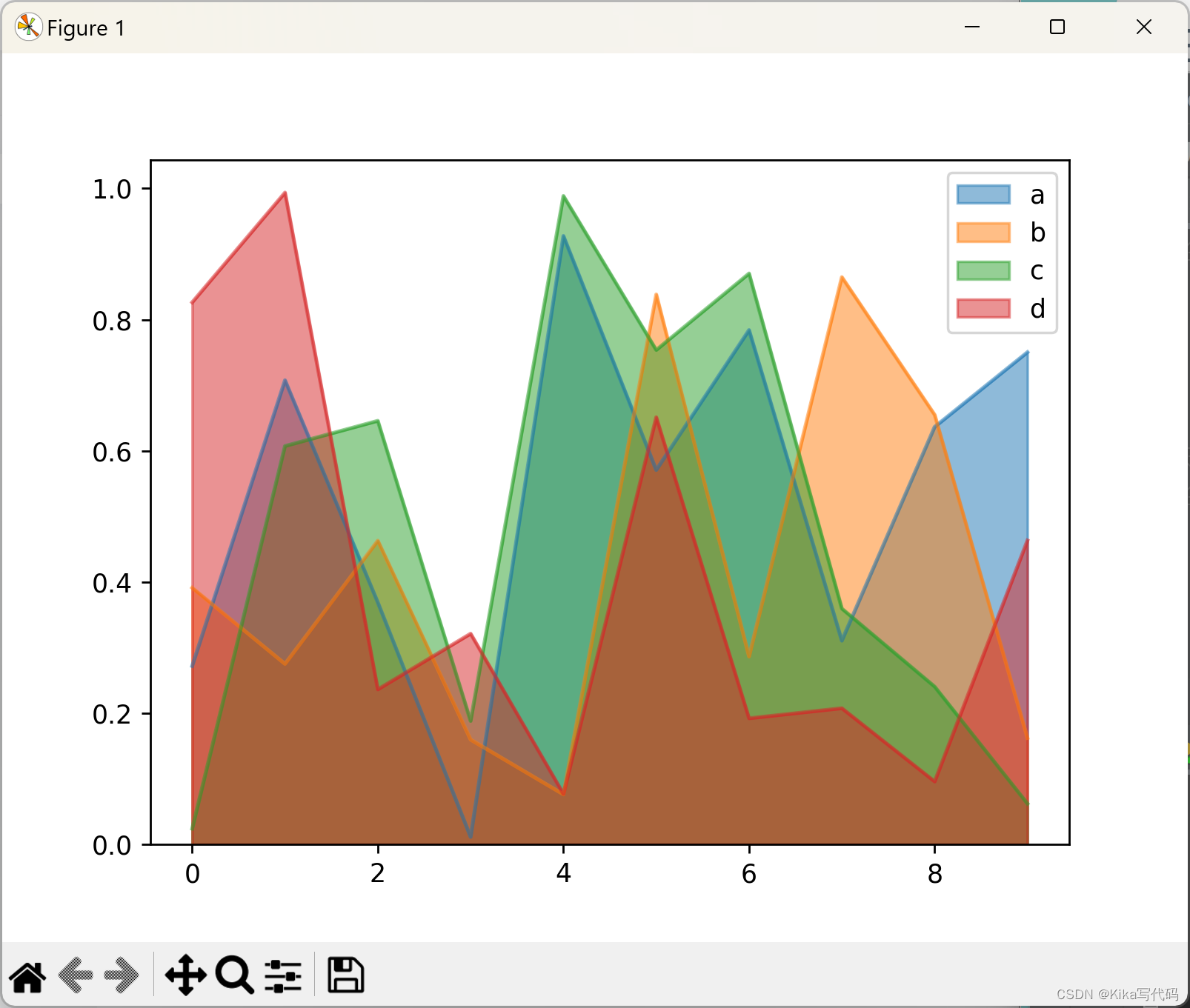
Scatter plot 散点图
散点图需要数值型的列作为x轴和y轴的数据,你可以通过x和y参数来指定这些列。
比如,有如下代码创建了一个包含随机数据的DataFrame,并基于列'a'和'b'绘制了一个基本的散点图:
python
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
df.plot.scatter(x='a', y='b')
plt.show()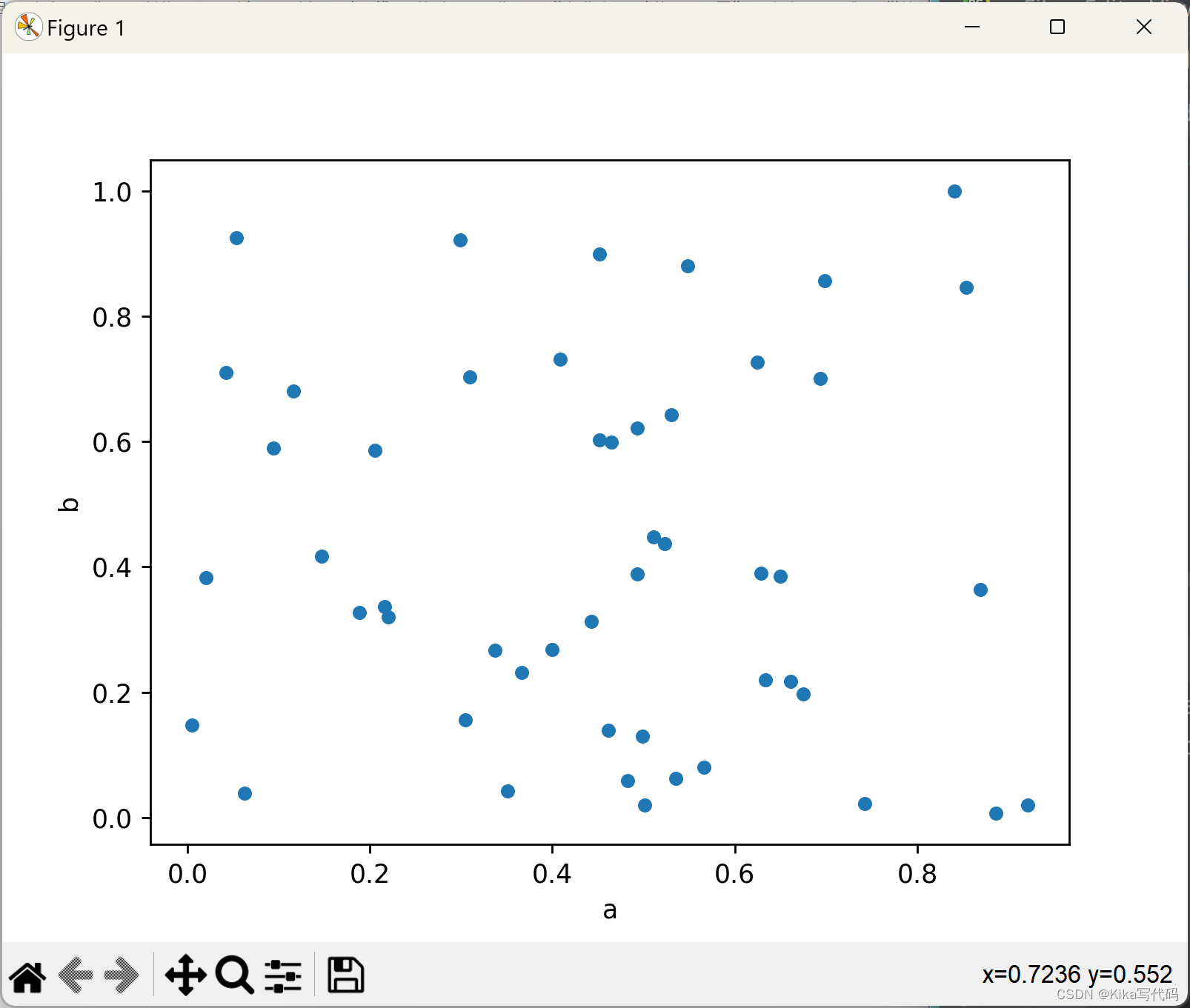
要在同一个坐标轴上绘制多个数据列组,可以重复调用plot.scatter()方法,并指定目标坐标轴(ax)。为了区分不同的组,推荐使用color和label关键字来分别设定颜色和标签:
python
ax = df.plot.scatter(x='a', y='b', color='DarkBlue', label='Group 1')
df.plot.scatter(x='c', y='d', color='DarkGreen', label='Group 2', ax=ax)
plt.show()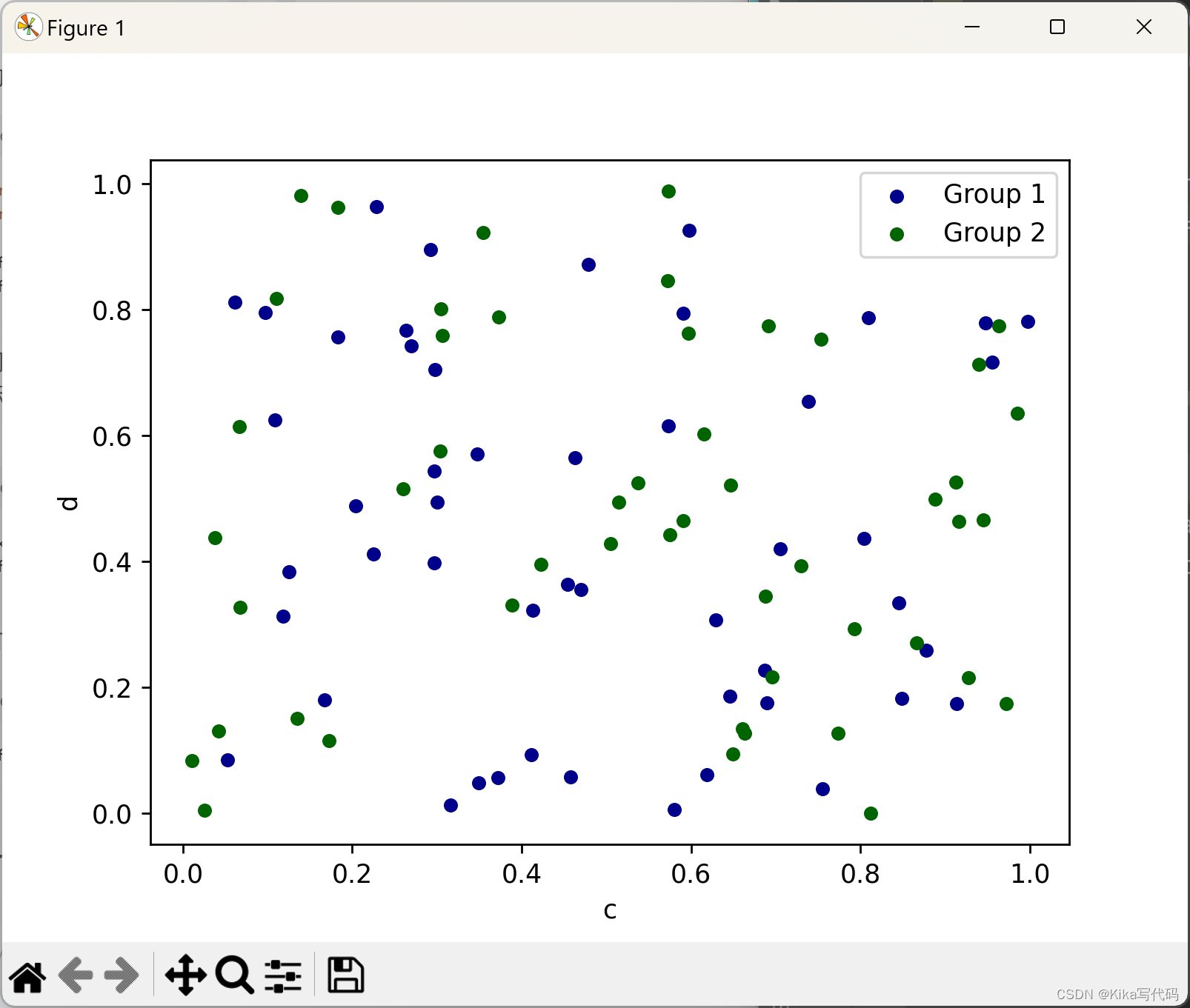
你还可以通过c关键字指定一个列名,用该列的值来为每个点着色:
python
df.plot.scatter(x='a', y='b', c='c', s=50)
plt.show()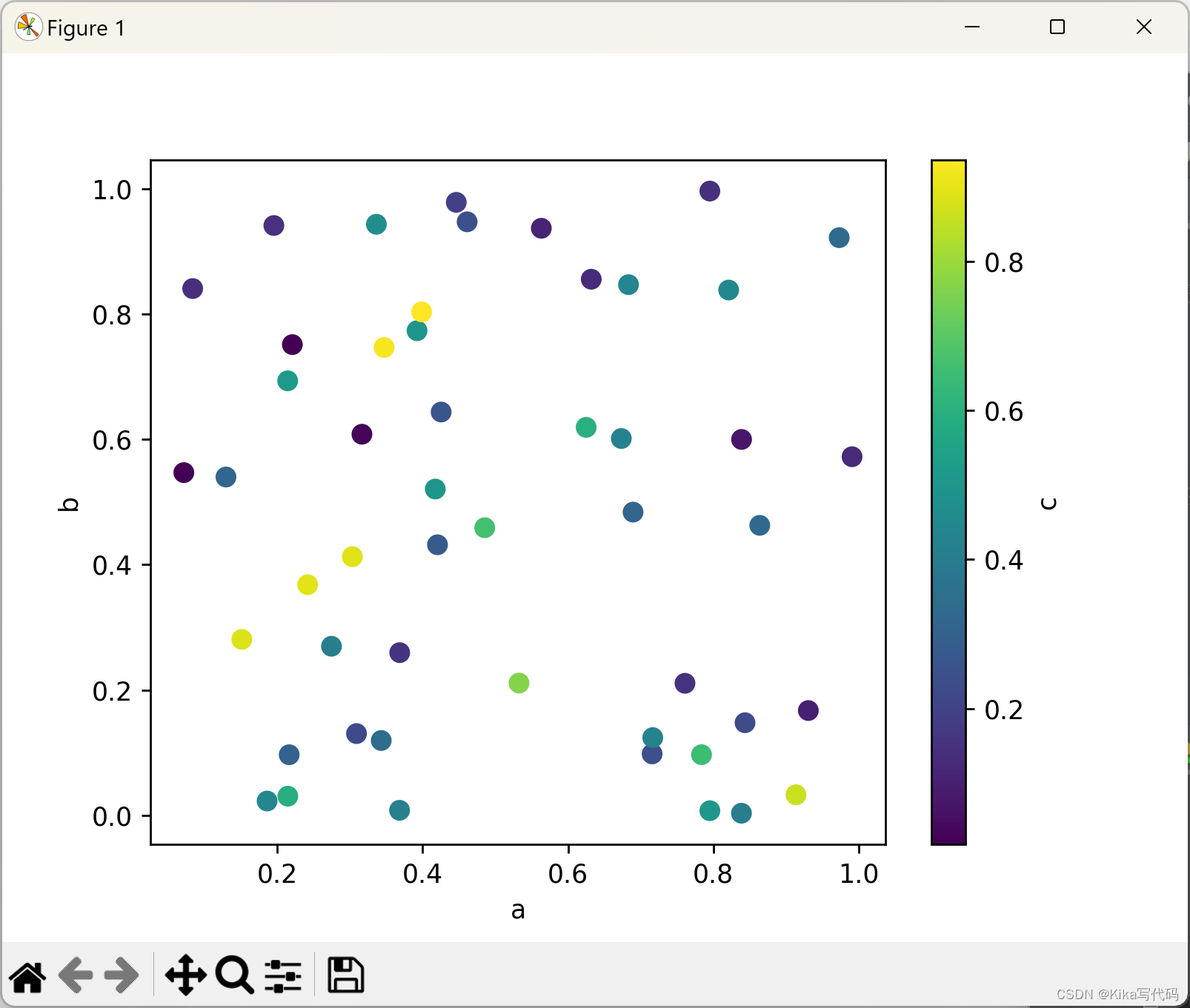
下面的代码展示了如何利用DataFrame的一列数据作为气泡大小,来绘制一个气泡图:
python
df.plot.scatter(x='a', y='b', s=df['c'] * 200)
plt.show()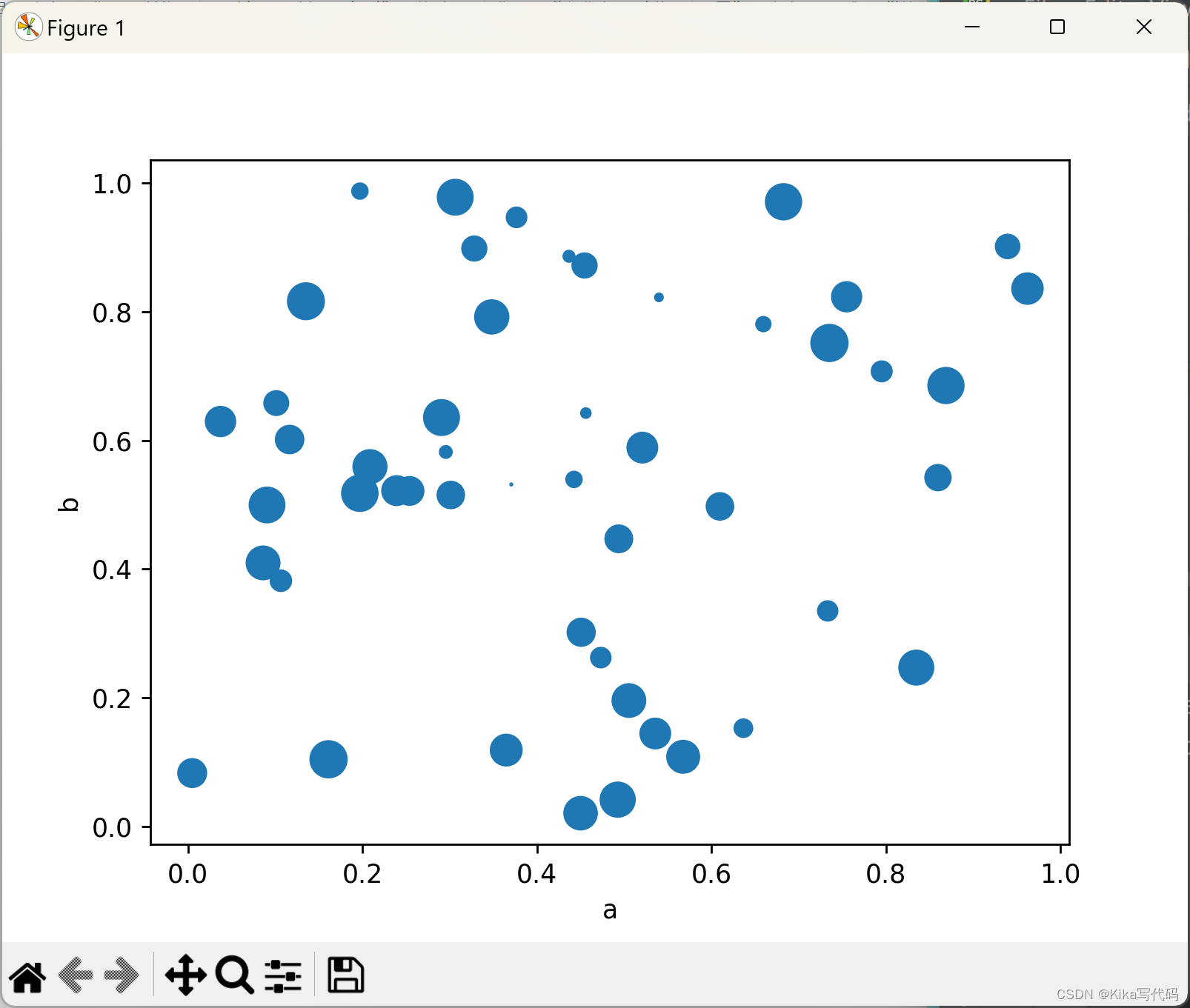
Hexagonal bin plot 六边形分布图
六边形分布图是处理密集数据点的一种有效方式,作为散点图的替代方案 ,特别是在数据点过多以至于无法单独绘制每一个点时。
这种图表通过将数据点分组到六边形的格子中,并根据格子中的数据点数量来调整格子的颜色
在pandas中,你可以使用DataFrame.plot.hexbin()方法来创建六边形分布图。
例如,首先创建一个包含随机数据的DataFrame,并基于列'a'和'b'绘制一个基础的六边形分布图,同时设置gridsize参数来控制x方向上的六边形数量:
python
df = pd.DataFrame(np.random.randn(1000, 2), columns=['a', 'b'])
df['b'] += np.arange(1000)
df.plot.hexbin(x='a', y='b', gridsize=25)
plt.show()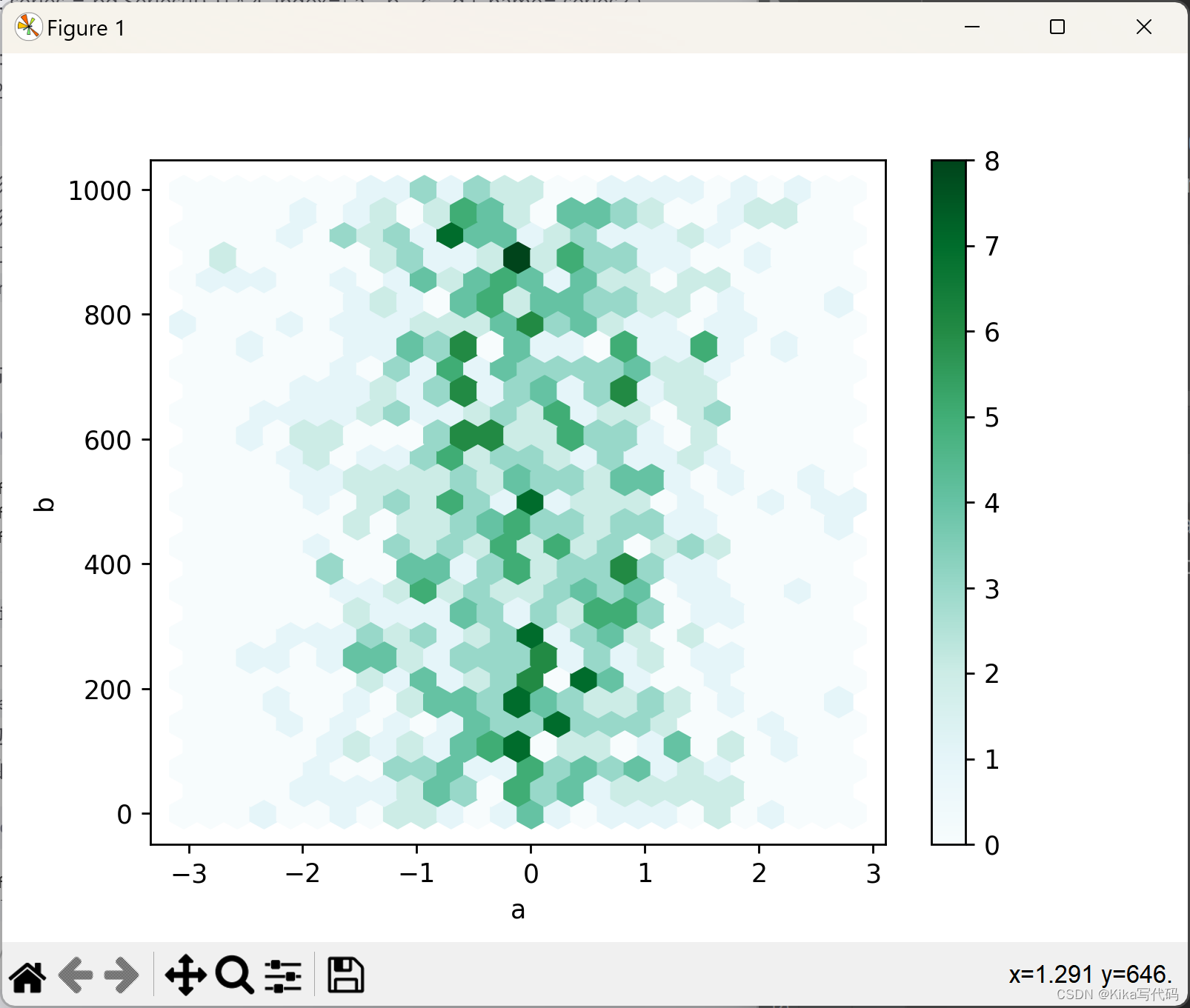
gridsize默认为100,更大的gridsize意味着更多的、更小的六边形单元。
除了计数外,你还可以通过C参数指定每个(x, y)点的值,并通过reduce_C_function参数指定一个聚合函数(如均值、最大值、和、标准差等)来对每个六边形内的值进行汇总。例如,这里我们用列'z'的值,并使用numpy的max函数作为聚合函数:
python
df['z'] = np.random.uniform(0, 3, 1000)
df.plot.hexbin(x='a', y='b', C='z', reduce_C_function=np.max, gridsize=25)
plt.show()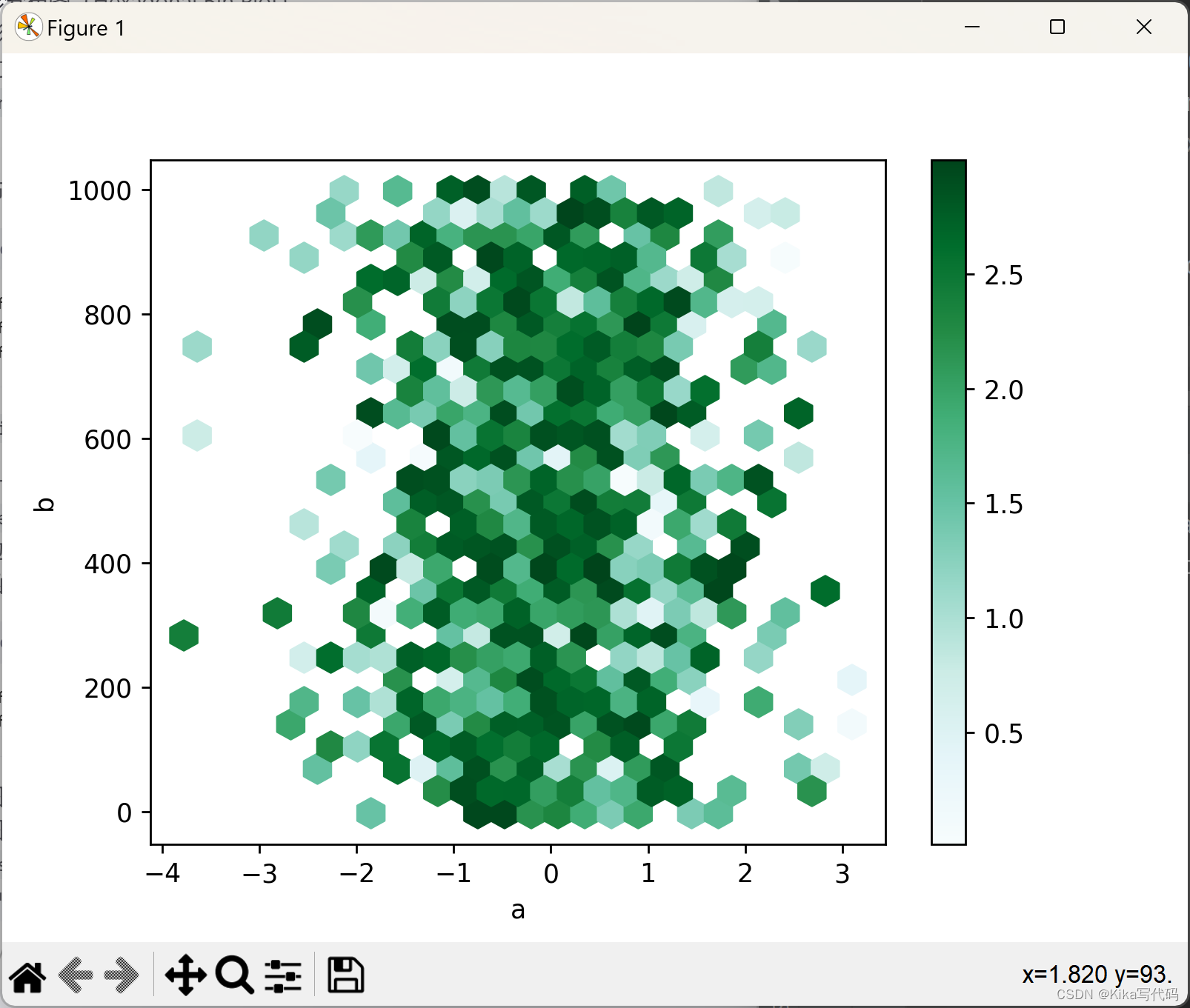
Pie plot 饼图
饼状图用于展示各部分占总体的比例,可以通过DataFrame.plot.pie()或Series.plot.pie()方法创建。如果数据中有NaN值,它们会被自动填充为0,且若数据中有负值,会抛出ValueError。
对于Series,可以直接绘制饼状图:
python
series = pd.Series(3 * np.random.rand(4), index=['a', 'b', 'c', 'd'], name='series')
series.plot.pie(figsize=(6, 6))
plt.show()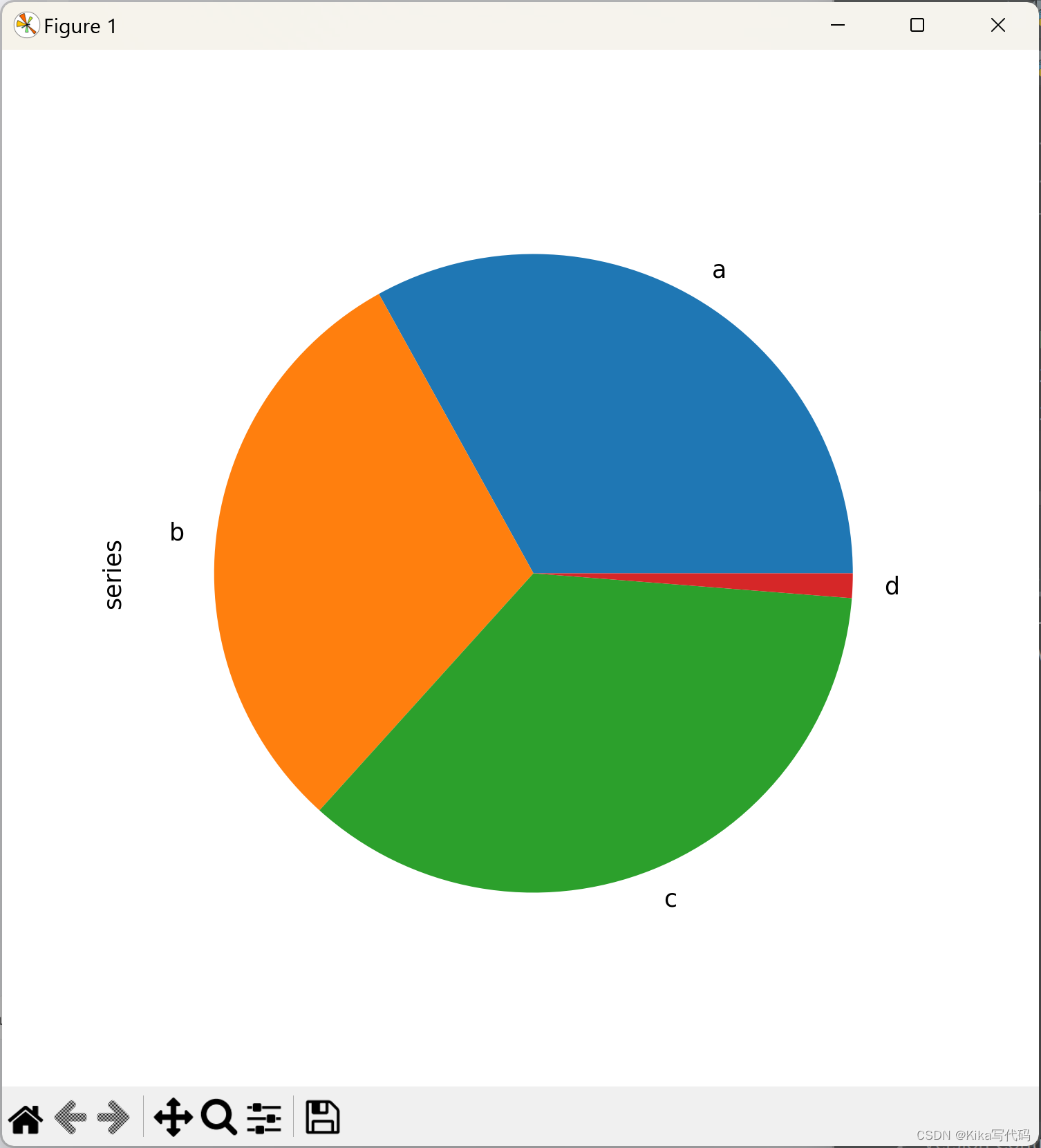
饼状图最好使用正方形的画布,即宽高比为1。可以通过设定画布尺寸或在绘制后调用ax.set_aspect('equal')来强制等比。
当使用DataFrame绘制饼图时,你需要指定一个目标列(通过y参数)或设置subplots=True。
前者仅绘制指定列的饼图,后者则为每列分别绘制子图,并默认带有图例。
可通过legend=False隐藏图例。
python
df = pd.DataFrame(3 * np.random.rand(4, 2), index=['a', 'b', 'c', 'd'], columns=['x', 'y'])
df.plot.pie(subplots=True, figsize=(8, 4))
plt.show()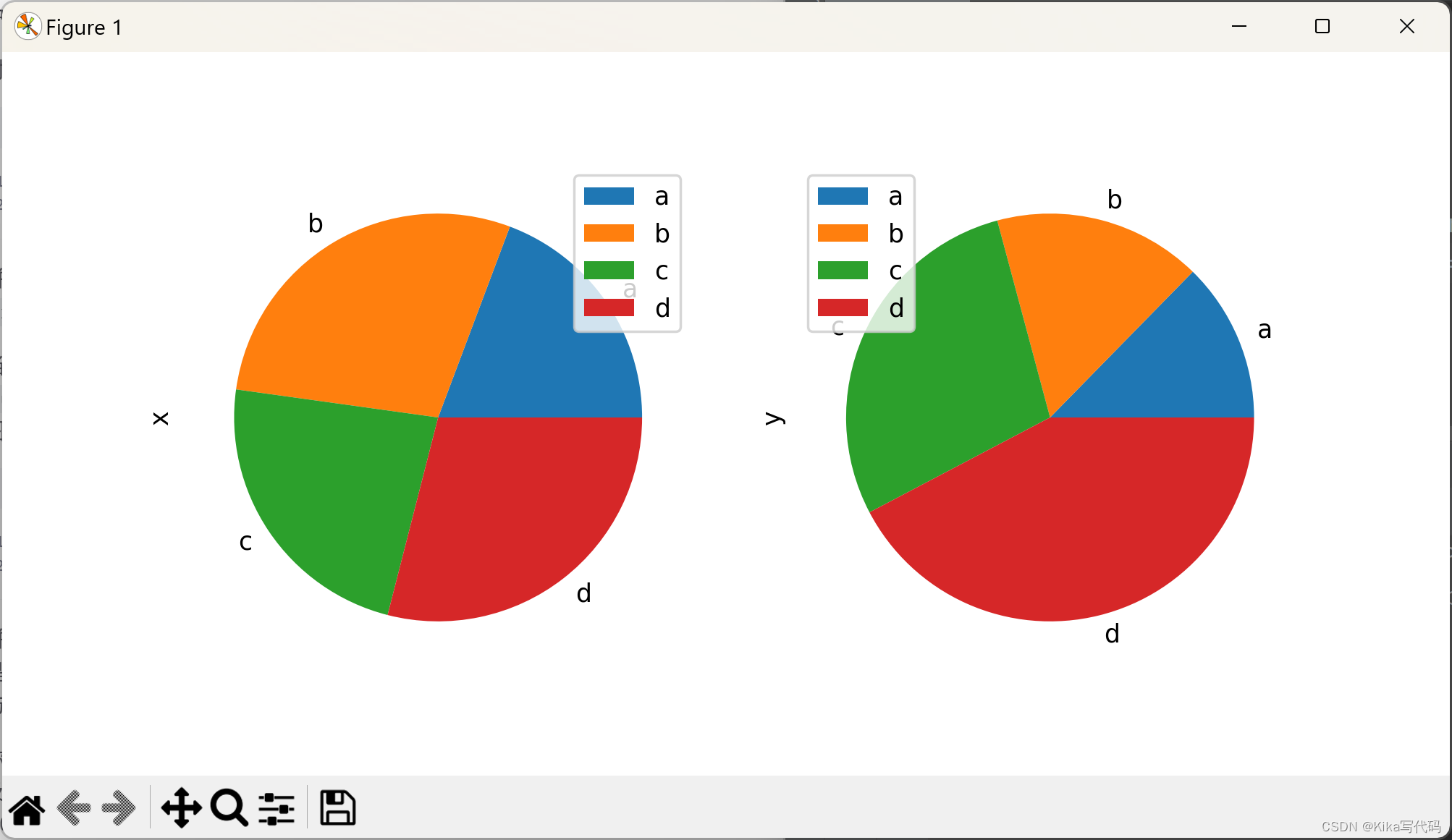
饼图还支持通过labels和colors关键字来自定义每个扇区的标签和颜色。需要注意的是,与大多数pandas绘图函数不同,饼图应使用复数形式的labels和colors,以保持与matplotlib.pyplot.pie()的一致性。
python
series.plot.pie(labels=['AA', 'BB', 'CC', 'DD'], colors=['r', 'g', 'b', 'c'],
autopct='%.2f', fontsize=20, figsize=(6, 6))
plt.show()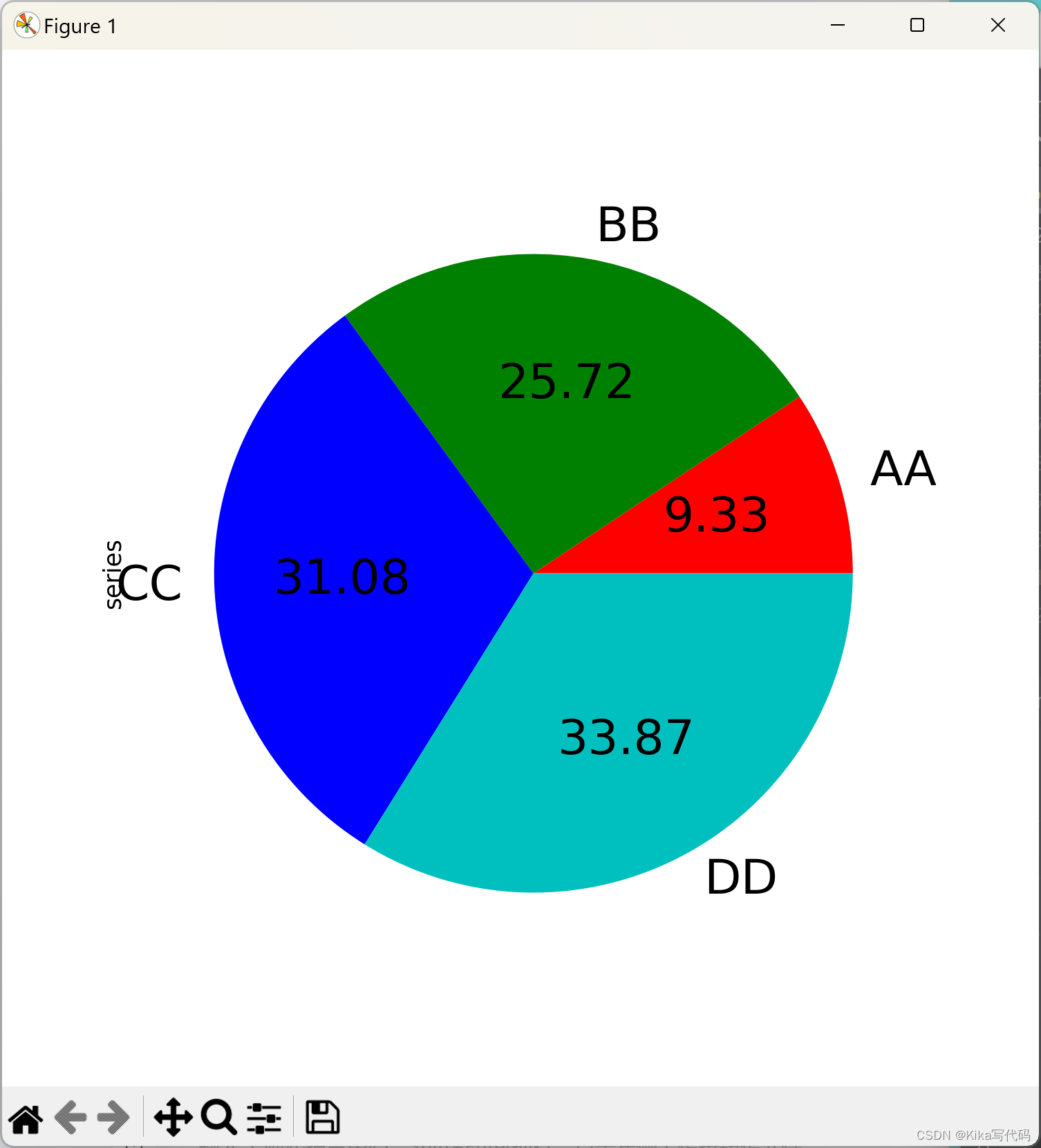
你还可以隐藏扇区标签(通过labels=None),调整字体大小(通过fontsize),以及其他matplotlib.pyplot.pie()支持的参数来进一步定制饼图。
缺失值默认处理
Pandas绘图时对缺失值默认处理:
在使用Pandas进行绘图时,它会根据图表类型对缺失数据进行不同的处理。以下是不同图表类型对NaN(缺失值)的处理方式:
-
折线图(Line) :在NaN处留空隙。如果你不希望出现空隙,可以在绘图前使用
fillna()方法填补数据或进行插值处理。 -
堆积折线图(Line, stacked):用0填充NaN。如果你不想使用0填充,可以提前对数据进行处理。
-
条形图(Bar):用0填充NaN。若需改变这种处理方式,可在绘图前手动调整数据。
-
散点图(Scatter):删除NaN。若希望保留这些点,可以考虑在绘图前对缺失值进行填充或处理。
-
直方图(Histogram):按列删除NaN。如果想以特定方式包含缺失数据的信息,可以先对数据进行预处理。
-
箱线图(Box):按列删除NaN。对于缺失值的特殊处理,应在绘图前进行。
-
面积图(Area) :用0填充NaN。若希望展示缺口,可以先用
fillna()或其他方式处理数据。 -
核密度图(KDE):按列删除NaN。需要考虑缺失值影响时,应预先处理数据。
-
六边形分布图(Hexbin):删除NaN。若需特别处理缺失值,提前处理数据。
-
饼图(Pie):用0填充NaN。若不希望缺失值计入总数,绘图前需进行调整。
如果这些默认的处理方式不符合你的需求,或者你想要明确地指定如何处理缺失值,可以在绘图前 使用fillna()或dropna()方法。fillna()可以用来填充缺失值,dropna()则可以用来删除包含缺失值的行或列。
Pandas.plottingPan模块
在Pandas库中,pandas.plotting模块提供了多种用于数据分析和可视化的便捷函数。以下是一些主要的绘图工具及其用途概述:
散点矩阵图(Scatter Matrix Plot)
散点矩阵图通过scatter_matrix函数实现,它能快速生成数据集中所有数值变量两两之间的散点图矩阵,非常适合探索变量间的关系。每个单元格展示两个变量之间的散点图,而对角线上的图则通常显示相应变量的分布情况,如核密度估计(KDE)。例如:
python
from pandas.plotting import scatter_matrix
df = pd.DataFrame(np.random.randn(1000, 4), columns=['a', 'b', 'c', 'd'])
scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal='kde')
plt.show()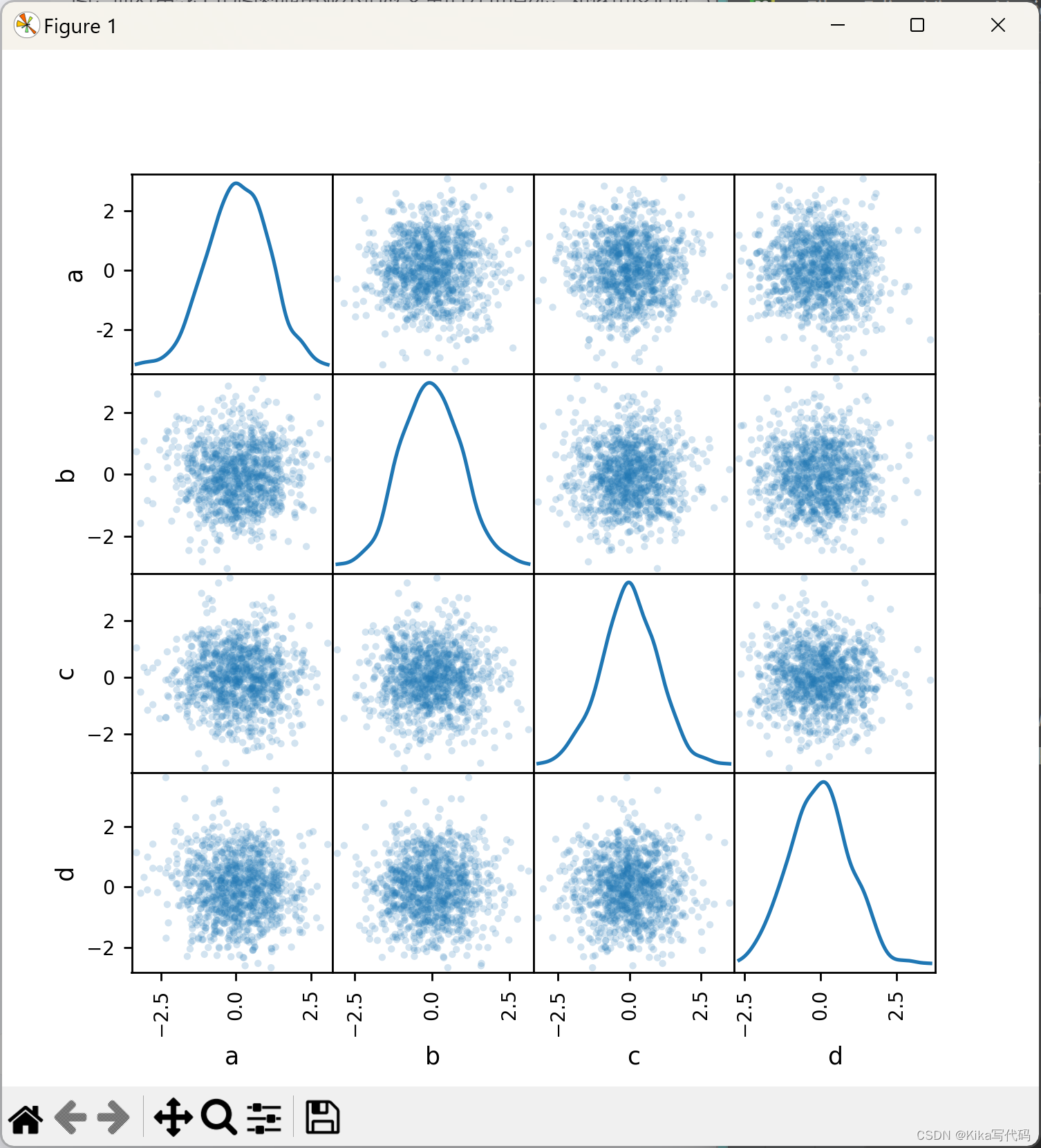
密度图(Density Plot)
密度图通过.plot.kde()方法应用于Series或DataFrame对象,用于可视化数据分布。它通过估计数据的概率密度函数,展示数据值的分布密度。例如:
python
ser = pd.Series(np.random.randn(1000))
ser.plot.kde()
plt.show()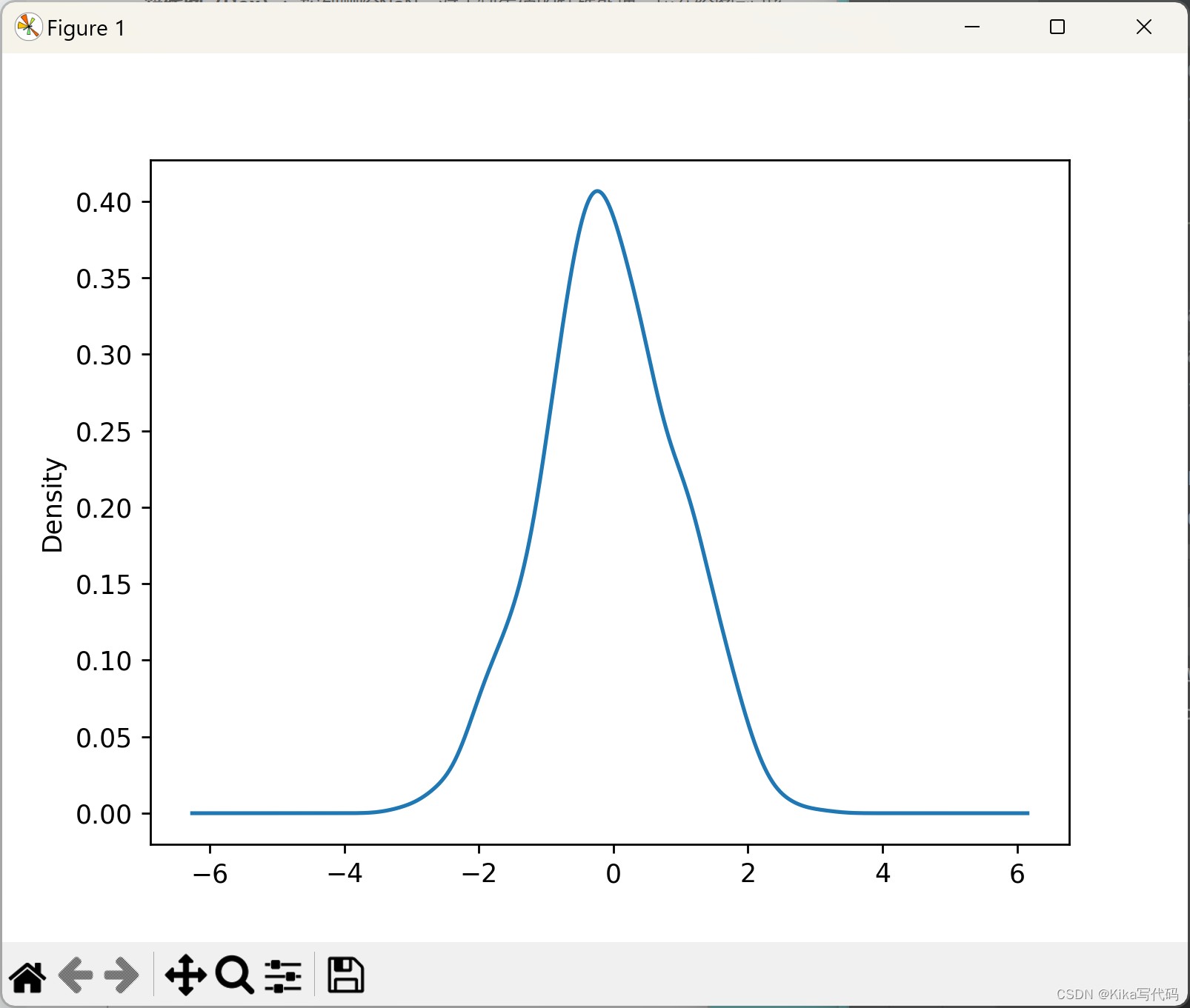
安德鲁斯曲线(Andrews Curves)
安德鲁斯曲线是一种将多维数据转化为一维曲线的方法,利用多变量数据的属性作为正弦函数的系数,从而在二维平面上表现数据点的特征。这有助于识别数据集中的模式和分类。例如:
功能 :通过andrews_curves函数,将多维数据转换成一系列基于傅里叶级数的曲线,不同类别的样本用不同颜色表示,便于观察数据聚类。
示例 :andrews_curves(data, 'Name'),其中data是包含分类标签(如'Iris'数据集中的'Name')的数据集。
python
from pandas.plotting import andrews_curves
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names)
# 将分类标签作为新列添加到DataFrame中
data['Name'] = iris.target
andrews_curves(data, 'Name')
plt.show()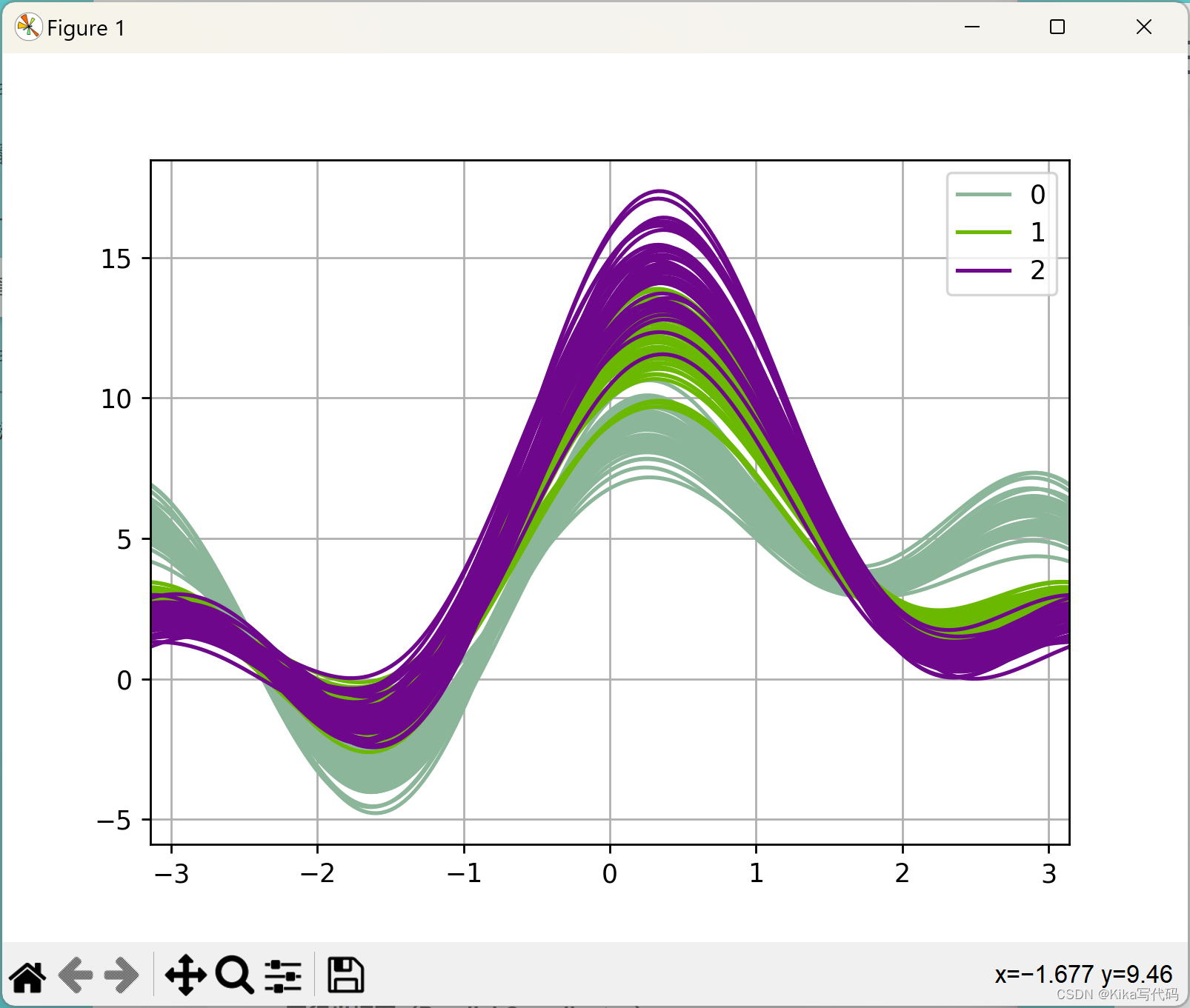
平行坐标图(Parallel Coordinates)
平行坐标图通过parallel_coordinates函数实现,适用于展示高维数据的多变量关系。每个数据点由一系列穿过各坐标轴的平行线段表示,相同类别的点在图中会形成较为密集的带状区域(每一条线代表一个数据点,通过垂直线分割表示不同属性),有利于发现数据的聚类结构。例如:
示例 :parallel_coordinates(data, 'Name'),用于展示基于某一分类变量(如类别名)的数据点分布。
python
from pandas.plotting import parallel_coordinates
from sklearn.datasets import load_iris
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names)
# 将分类标签作为新列添加到DataFrame中
data['Name'] = iris.target
parallel_coordinates(data, 'Name')
plt.show()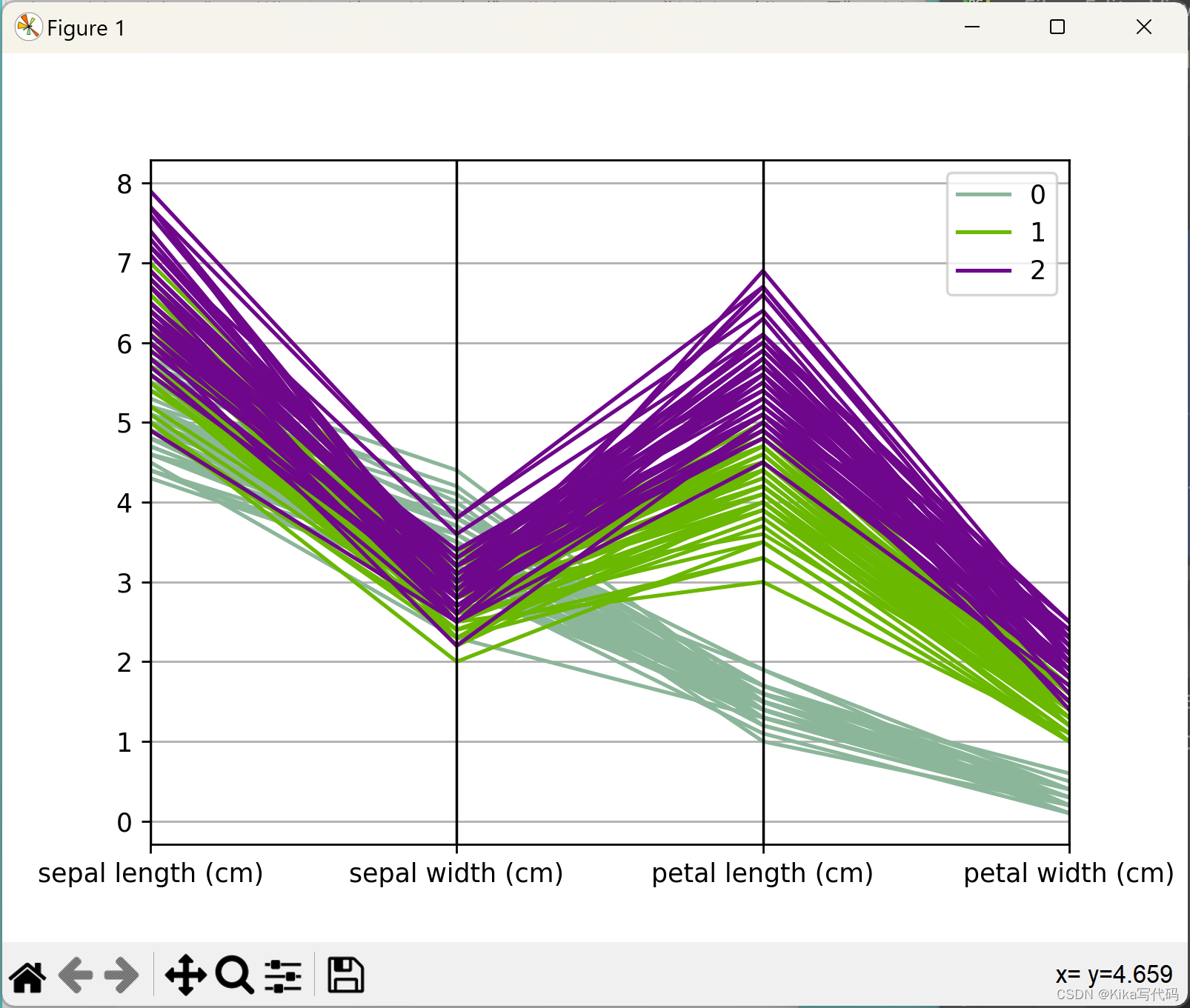
延迟图(Lag Plot)
lag_plot用于检查数据集或时间序列是否随机。通通过比较序列中每个点与其滞后一个或多个周期后的点的位置关系,若数据随机,则图中不应出现明显模式;反之,存在非随机结构。例如:
示例 :lag_plot(data),可以设置lag参数来指定滞后阶数。
python
from pandas.plotting import lag_plot
spacing = np.linspace(-99 * np.pi, 99 * np.pi, num=1000)
data = pd.Series(0.1 * np.random.rand(1000) + 0.9 * np.sin(spacing))
lag_plot(data)
plt.show()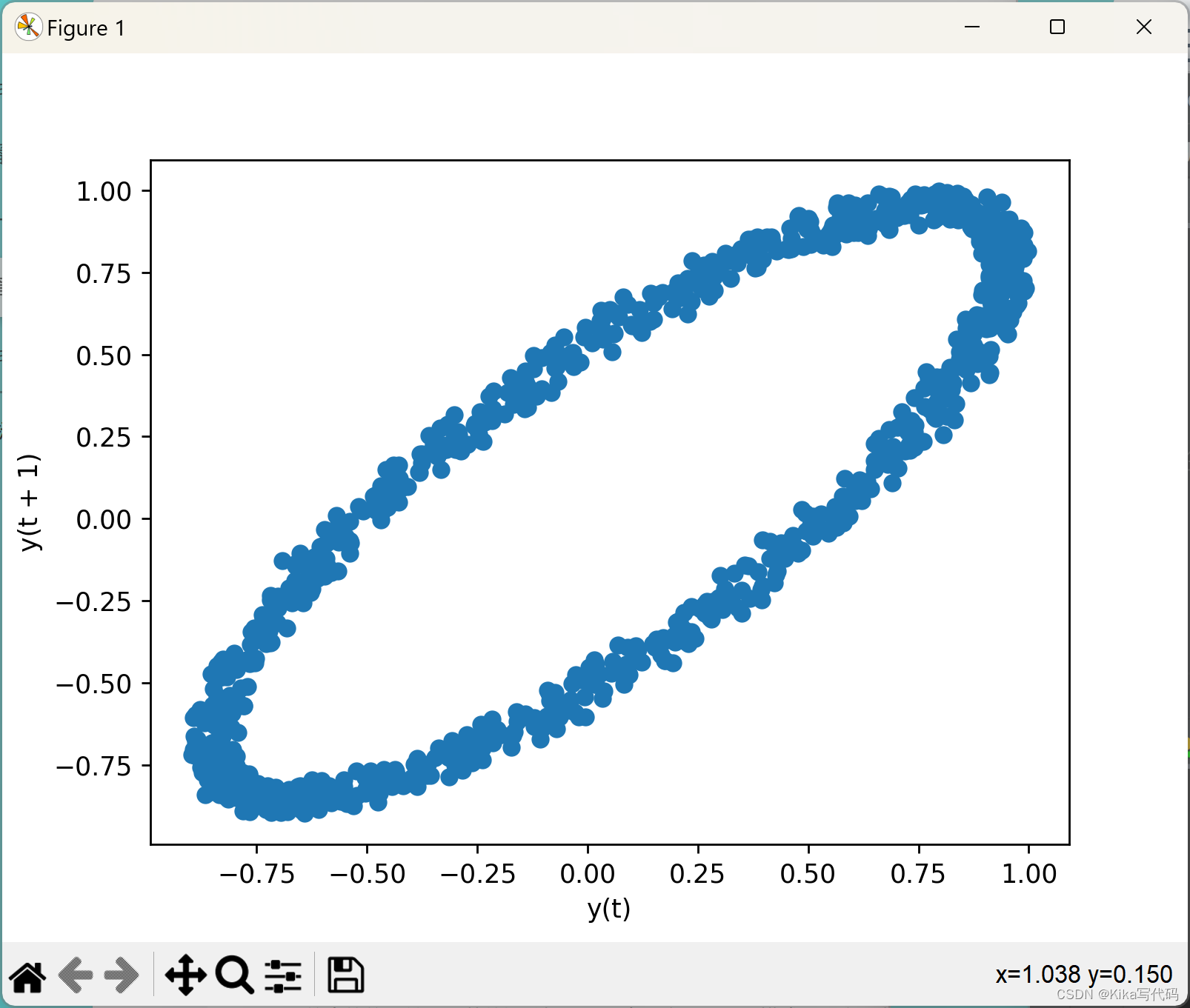
自相关图(Autocorrelation Plot)
自相关图通过autocorrelation_plot函数绘制,用于分析时间序列数据的自相关性,即序列中不同时间点的观测值之间的相关性。这对于识别序列中的趋势、周期性和随机性非常有用。例如:
功能:评估时间序列数据的相关性随时间滞后变化的情况,帮助判断序列是否具有周期性或趋势。
示例 :autocorrelation_plot(data),用于分析数据序列的自相关特性。
python
from pandas.plotting import autocorrelation_plot
spacing = np.linspace(-9 * np.pi, 9 * np.pi, num=1000)
data = pd.Series(0.7 * np.random.rand(1000) + 0.3 * np.sin(spacing))
autocorrelation_plot(data)
plt.show()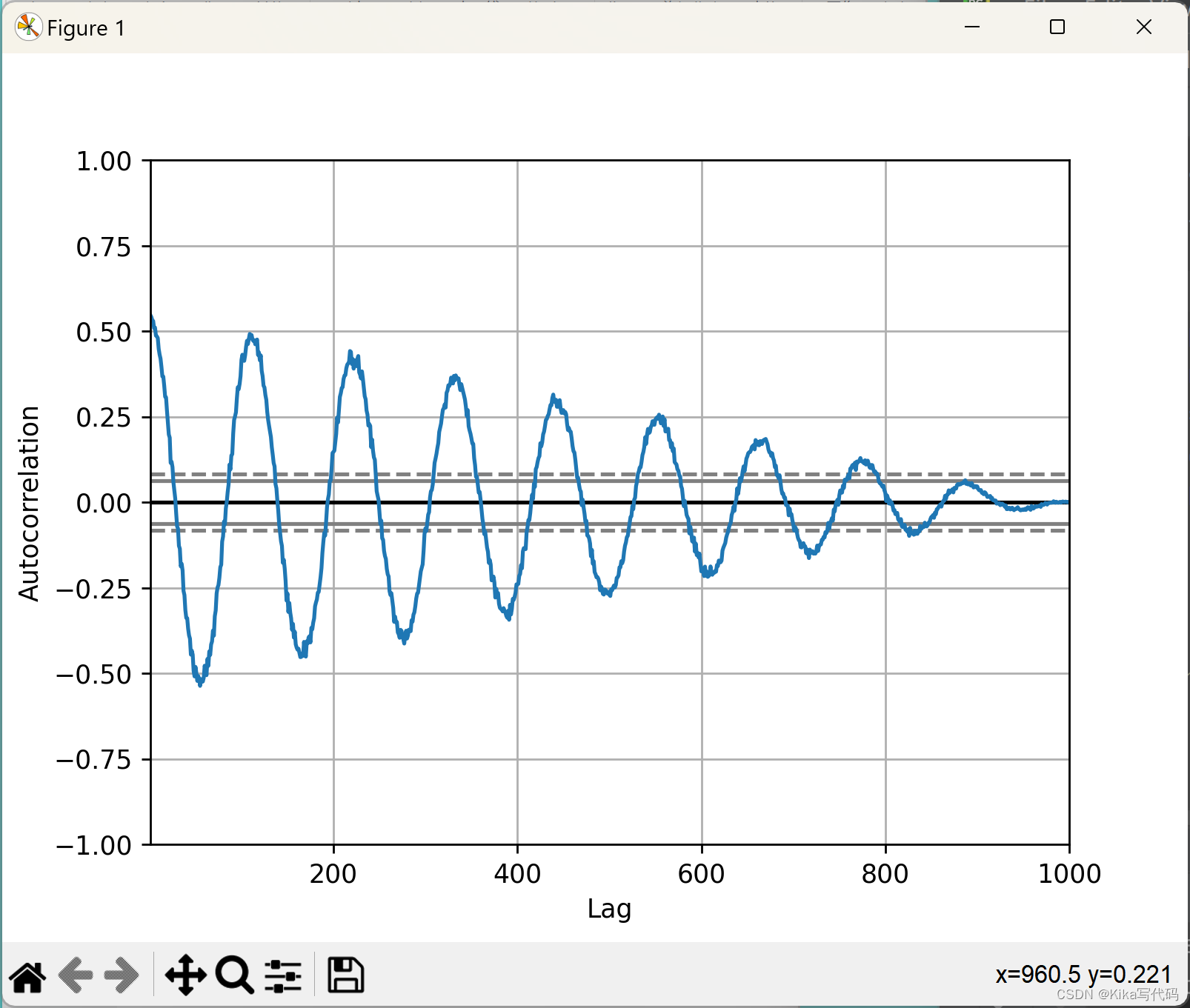
Bootstrap图(Bootstrap Plot)
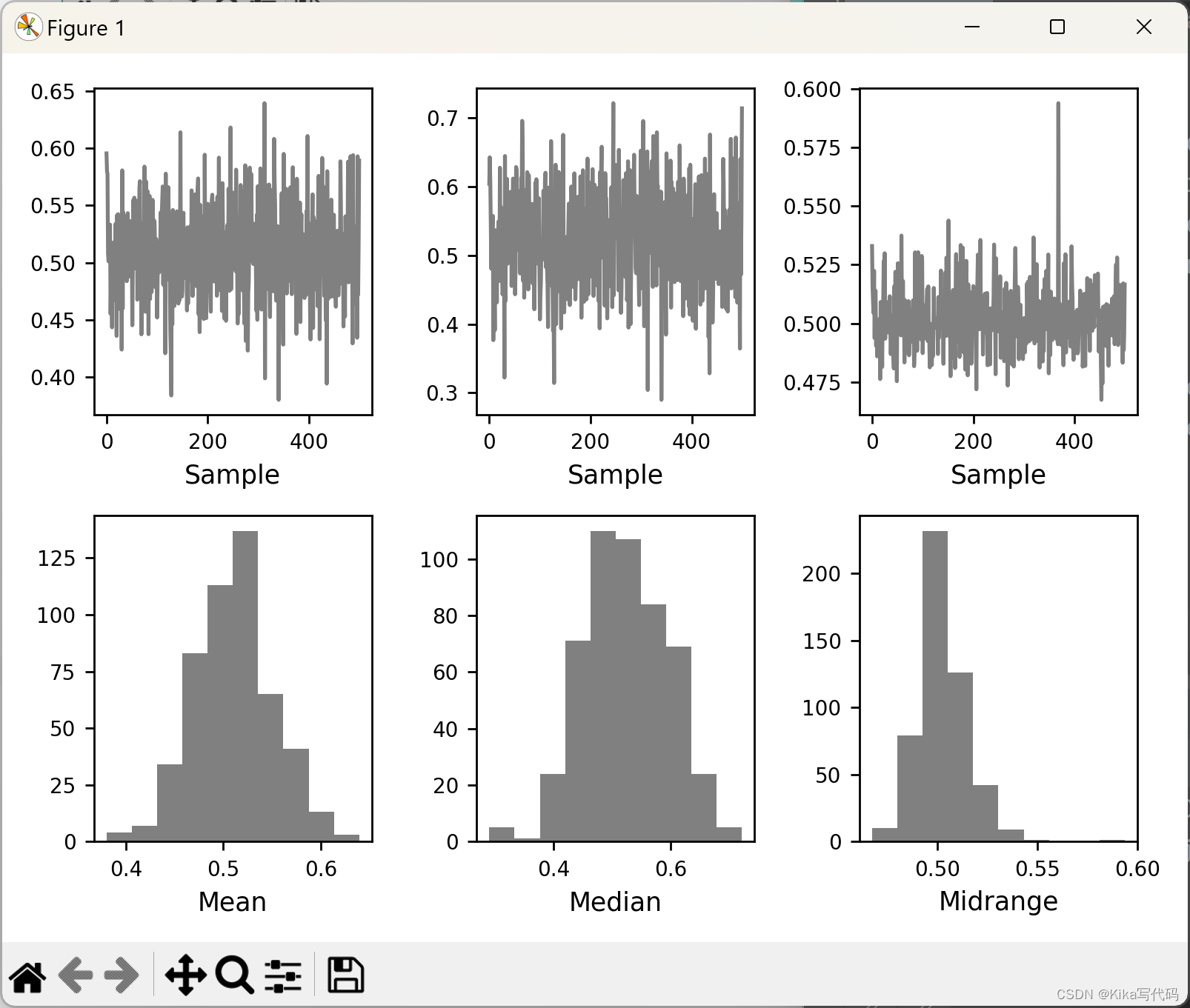
Bootstrap图通过bootstrap_plot函数生成,用于估计统计量(如均值、中位数)的不确定性和置信区间。通过多次从原数据集中抽取样本并计算统计量,最终以直方图的形式展示这些样本统计量的分布。例如:
功能:通过重复抽样来估计统计量的不确定性,生成的直方图和曲线展示了所选统计量(如均值、中位数)的分布情况。
示例 :bootstrap_plot(data, size=50, samples=500, color='grey'),用于可视化数据统计量的变异程度。
python
from pandas.plotting import bootstrap_plot
data = pd.Series(np.random.rand(1000))
bootstrap_plot(data, size=50, samples=500, color='grey')
plt.show()