1、在做ETL数据抽取的时候,会用到生成随机数的功能,今天我们一起来学习下如何生成随机数据。如下图所示
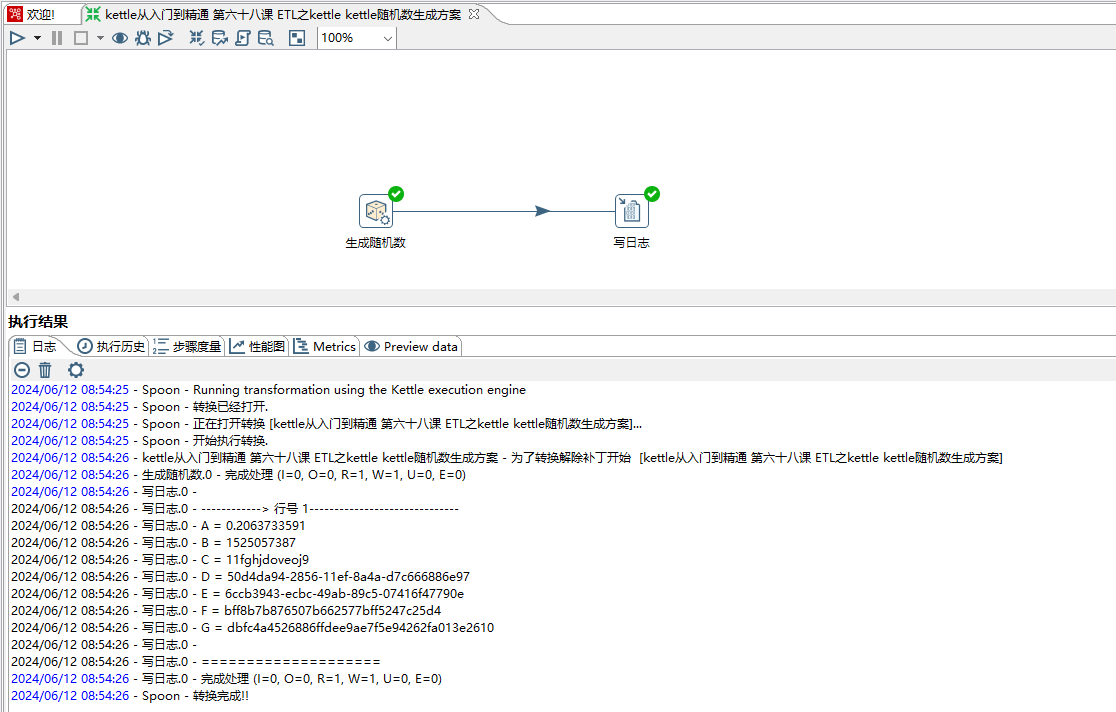
2、将生成随机数拉倒画布即可,然后设置字段名称和选择合适的类型,如下图所示:
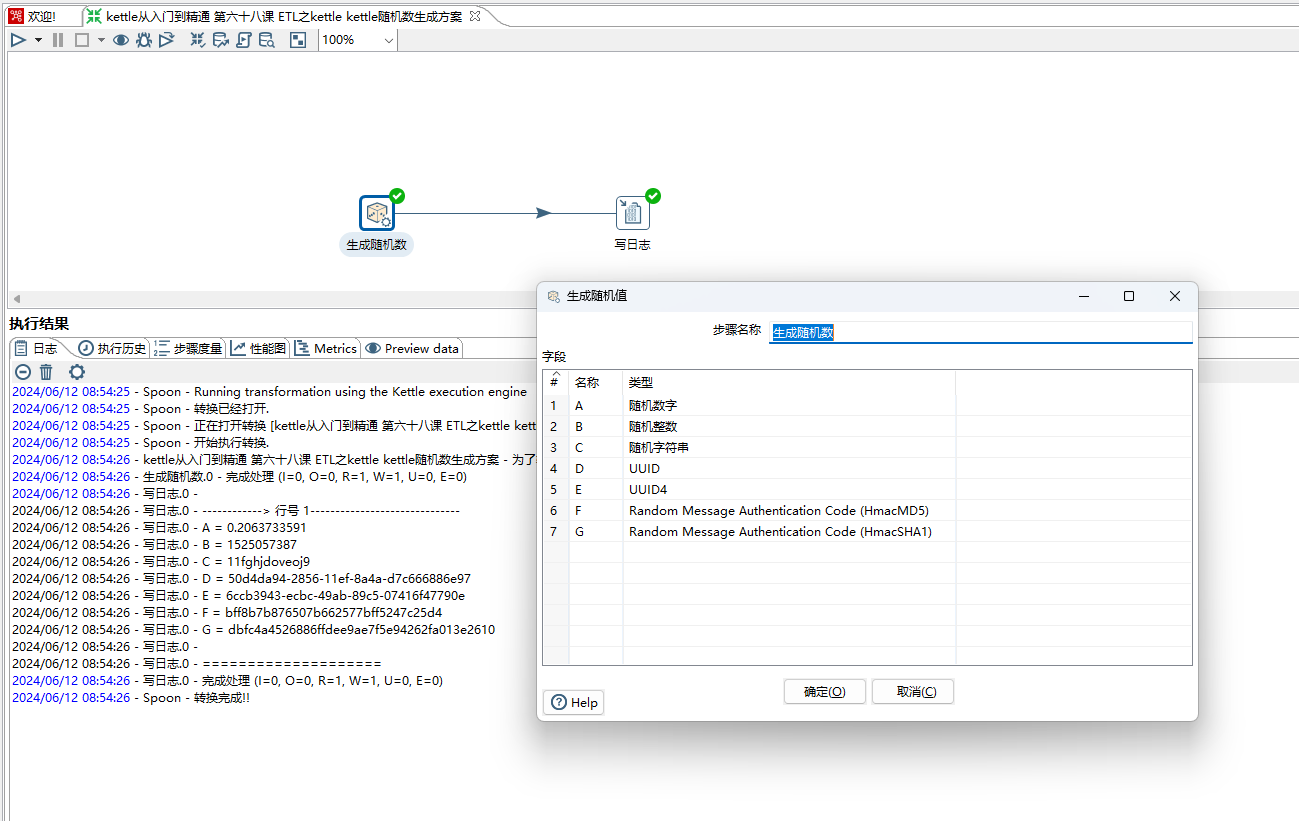
类型:
随机数字:生成一个介于 0 和 1 之间的随机数
随机整数:生成一个随机的 32-bit整数
随机字符串:基于 64-bit 长随机值生成一个随机字符串
UUID:通用唯一标识符(UUID)
UUID4:通用唯一标识符类型 4(UUID4)
随机消息认证码(HmacMD5)
随机消息认证码(HmacSHA1)
3、通过javascript调用jar包工具类进行生成,如下图所示:
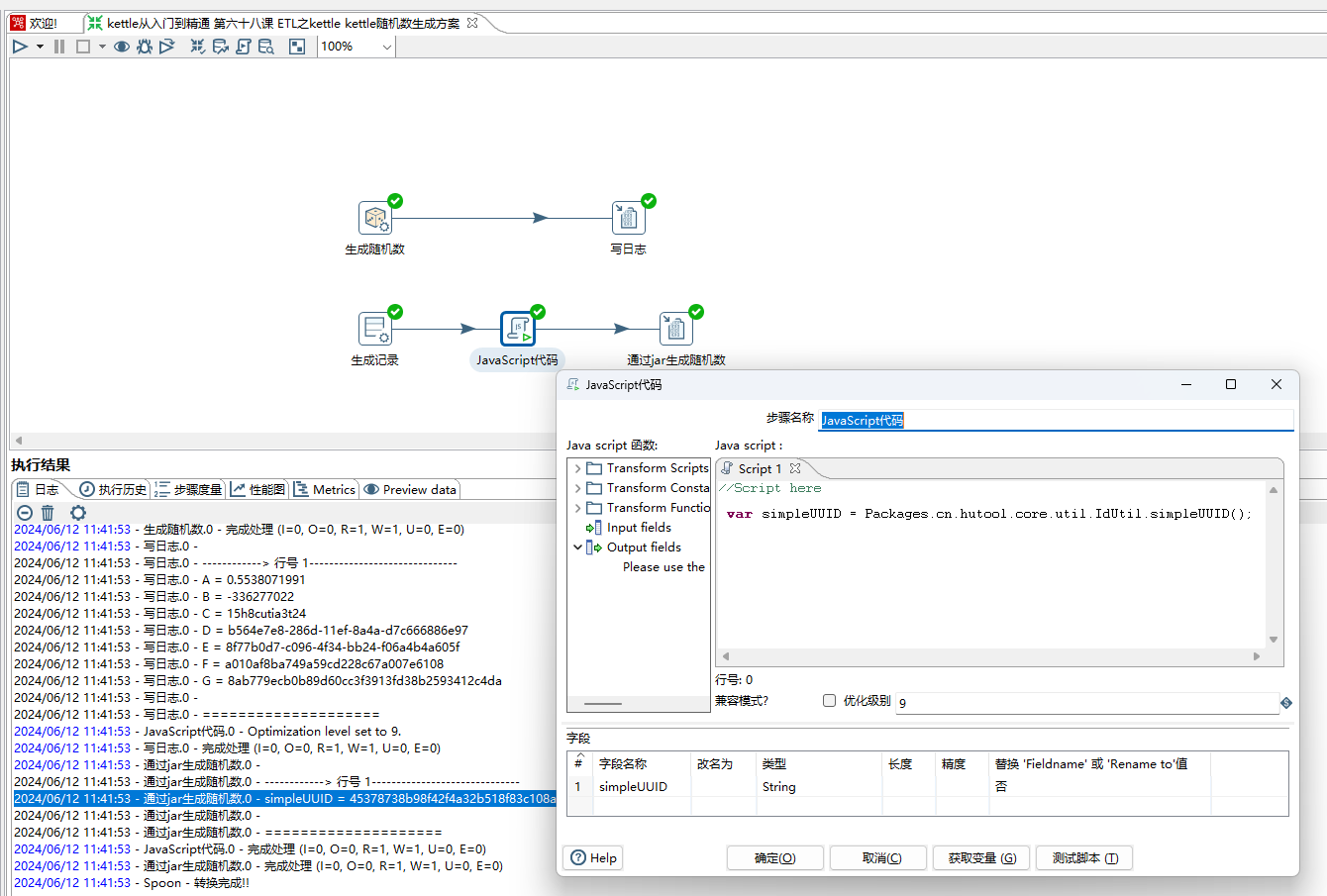
4、通过java脚本进行生成,如调用 java.util.UUID.randomUUID().toString(),这里不做过多介绍。
