目录
[1. 主数据管理系统:管的是 "不变的核心数据"](#1. 主数据管理系统:管的是 “不变的核心数据”)
[2. 数据中台:管的是 "流动中的价值"](#2. 数据中台:管的是 “流动中的价值”)
[二、为什么企业更该先建 MDM?](#二、为什么企业更该先建 MDM?)
[1. 数据中台解决不了数据本身问题](#1. 数据中台解决不了数据本身问题)
[2. MDM 可以解决常见的基础问题](#2. MDM 可以解决常见的基础问题)
[3. 数字化转型初期的 "最可行路径"](#3. 数字化转型初期的 “最可行路径”)
[三、数据中台能代替 MDM 吗?](#三、数据中台能代替 MDM 吗?)
[1. 架构不匹配](#1. 架构不匹配)
[2. 成本增加](#2. 成本增加)
[3. 厂商支持不到位](#3. 厂商支持不到位)
"我们把数据中台产品线砍了,全力搞主数据管理!"
最近和一位做大数据的老朋友聊天,他这句话让我大吃一惊。要知道,前几年"数据中台"可是ToB圈子里最火的概念,怎么现在就有公司主动"退场"了?
带着这个问题,我翻了翻行业数据:
- 2020年前后国内宣称做数据中台的厂商超过80家,如今还在稳定运营的只剩不到20家;
- 曾经融资过亿的头部玩家如数澜科技、袋鼠云等,这两年也陆续传出裁员调整的消息。
**为啥突然"凉了"?**原因很简单:
很多企业花大价钱上了数据中台,结果发现连最基本的"客户信息在系统里都对不上号"这种问题都解决不了!
当企业从追概念回归到实际需求 ,一个更"实在"的工具------主数据管理系统(MDM),开始重新被重视起来。
所以问题来了:
- MDM 和 数据中台,到底有啥不一样?
- 企业真该放弃中台,只搞 MDM 吗? 还是说必须硬着头皮上中台?
今天我们就来把这两个问题彻底聊清楚。
一、主数据管理系统≠数据中台
要回答 "能不能代替" 这个问题,首先得弄明白两者的边界在哪。
很多人误以为 "数据中台啥都能管",但实际上, 主数据管理系统(MDM)和数据中台是数据治理体系 里的"地基 "和"桥梁 ",分工完全不同。
1. 主数据管理系统:管的是 "不变的核心数据"
主数据(Master Data)是企业里 "最稳定、最核心、最需要重复使用" 的基础数据。
比如:
客户、供应商、商品、员工这些实体信息都属于主数据。
它们有这些特点:
- 核心性:直接关系到业务能不能正常开展;
- 稳定性:变化的频率很低,一个客户的姓名、ID 很少会天天变;
- 高复用性:会被 ERP、CRM、财务系统等多个业务系统反复调用。
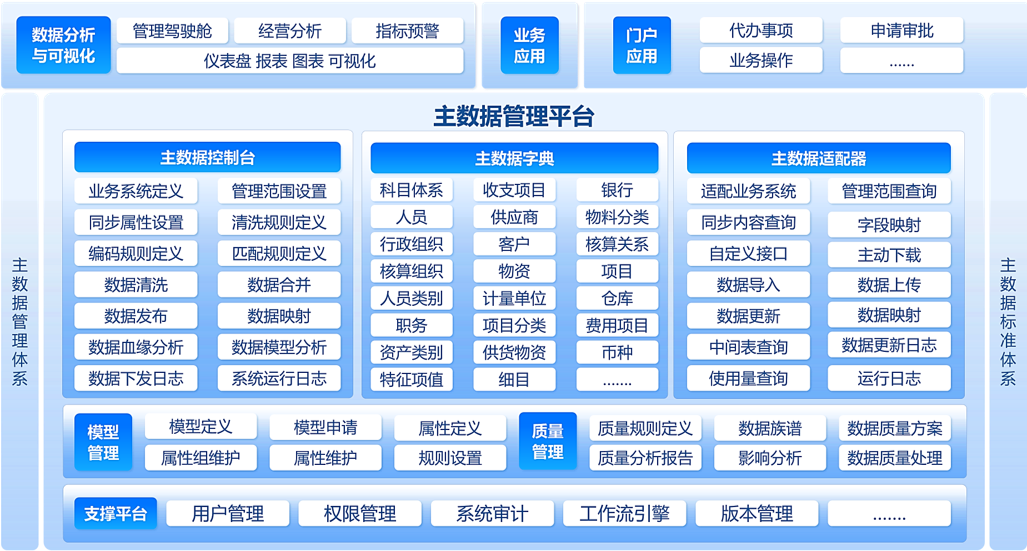
说白了,MDM 的核心工作,就是把这些 "核心数据" 管理得明明白白:
从定义标准→清理重复数据→同步最新的状态,它能确保大家说的 "客户" 都是同一个 "客户"。
2. 数据中台:管的是 "流动中的价值"
数据中台的定位更像是一个 "数据加工厂 ",它处理的是企业里动态的、大量的、来自多个源头的数据。
比如:
- 电商平台的订单流水
- 物流轨迹
- 用户行为日志(点击、加购、收藏等)
这些数据有几个共同点:
- 高频变化:交易数据会随着业务实时变动;
- 场景单一:订单流水主要用在财务对账或者运营复盘上;
- 需要加工:原始数据得通过 ETL、建模变成 "用户画像""销售预测" 这样的内容才有价值。
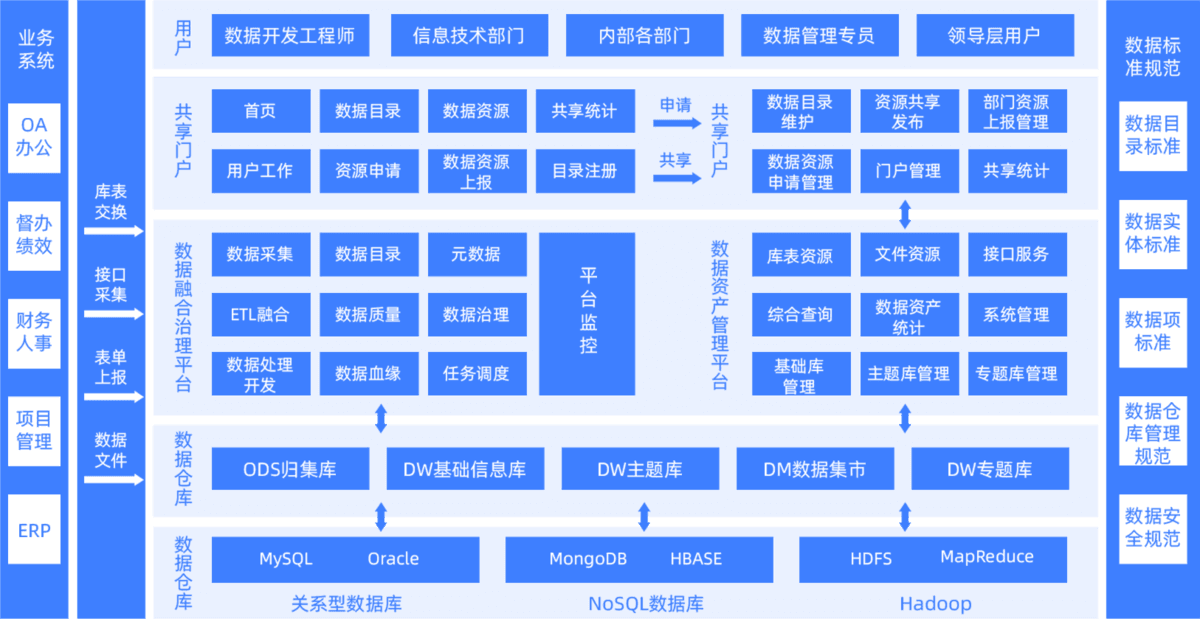
简单来说,数据中台的核心能力,就是:
- 把分散在各个系统里的 "杂乱数据" 进行清洗、整合、加工,
- 变成 "标准化的服务",比如用户标签 API、商品销售看板等,
- 然后提供给业务部门直接使用。
也就是说:
它能让数据从 "静态的资产" 变成 "动态的价值"。
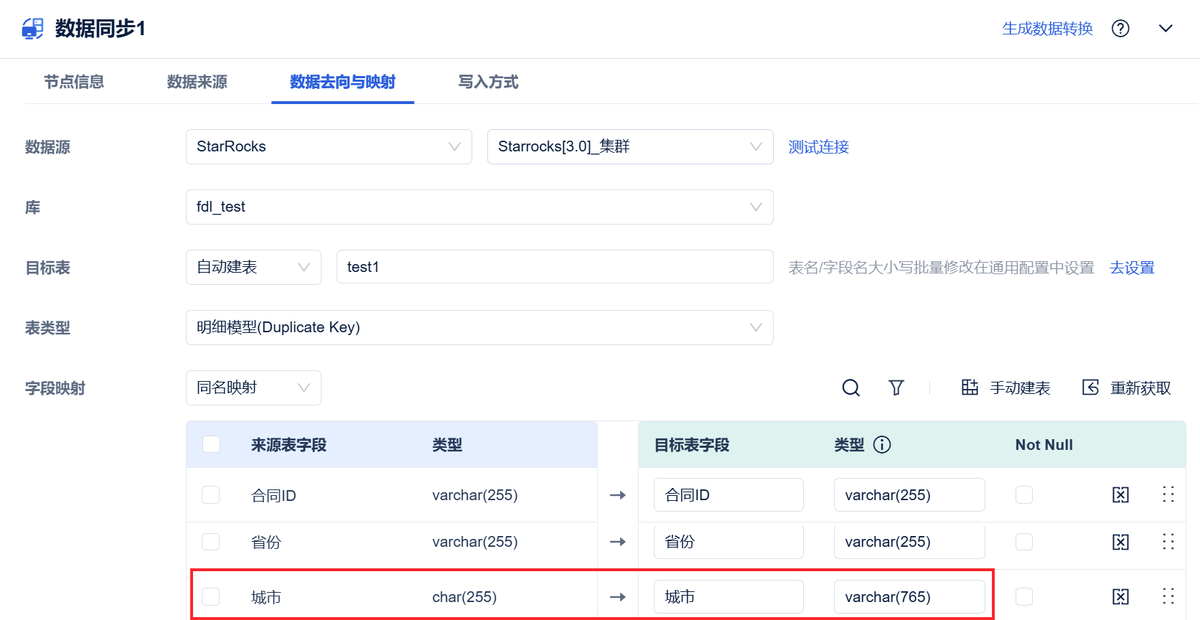
具体怎么开发和部署?
借助工具可以让数据中台的开发和利用更快速,比如数据集成工具 FineDataLink,它可以自定义字段类型映射规则,配置生效的数据连接,适应不同的数据源和目标系统,通过ETL计算,确保数据治理规则的同步和执行。 FineDataLink体验地址→免费FDL激活(复制到浏览器打开)
这样看来:
- MDM 解决的是 "数据从哪来、准不准确 " 的问题,是数据治理的起点;
- 数据中台 解决的是 "数据怎么用、怎么用好 " 的问题,是放大数据价值的工具。
它们是什么关系呢?
两者是上下游的关系 ------MDM 给数据中台提供 "干净的原材料",数据中台基于这些原材料生产出 "高附加值的产品"。
要是强行让数据中台代替 MDM,既不专业,还容易出岔子。
二、为什么企业更该先建 MDM?
回到开头那位同行的选择:为什么放弃数据中台,专注做 MDM 呢? 其实本质上是市场需求和企业所处阶段发生了变化。
1. 数据中台解决不了数据本身问题
前几年数据中台火的时候,很多企业都跟风上了项目,但实际效果却不一样。
有一家零售企业花 300 万买了头部厂商的数据中台,结果上线后发现:
- "跨系统数据同步" 总是延迟,财务部门月底对账还得人工核对;
- 维护成本还特别高,每年光接口调用费就得额外花 50 万。
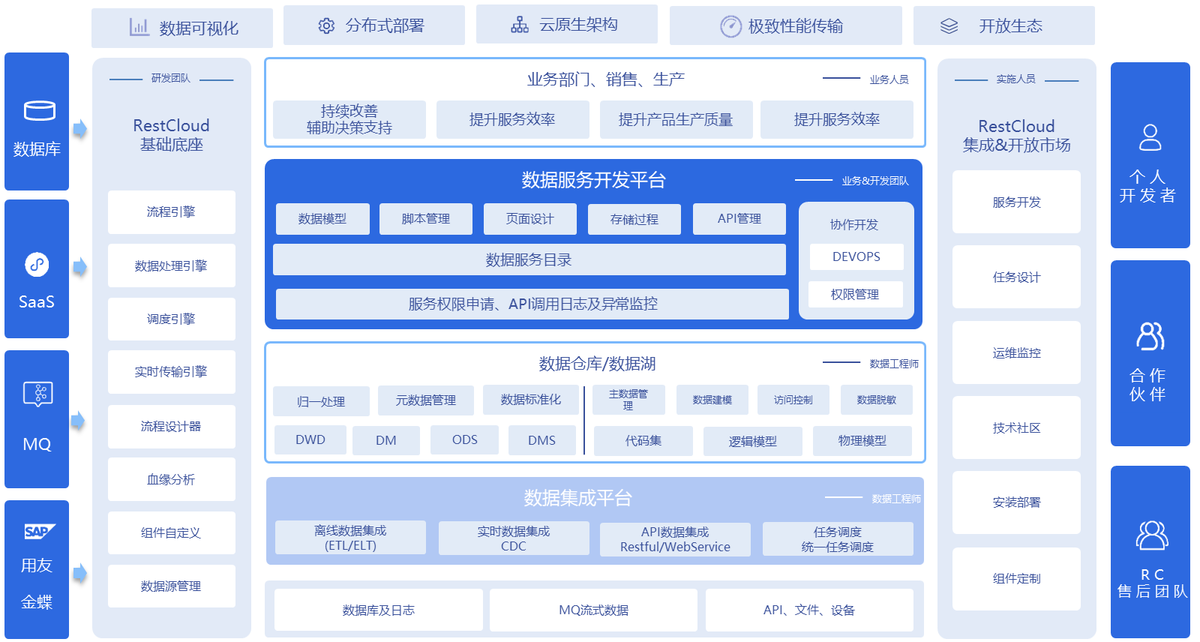
问题的根源在于:
数据中台的优势是 "整合和加工数据",但解决不了 "数据本身的质量问题"。
所以:
数据质量不过关,数据中台再厉害也发挥不出作用。
2. MDM 可以解决常见的基础问题
比起数据中台那些听起来很宏大的功能,MDM 解决的是企业每天都要面对的 "小麻烦":
- 跨系统数据不一致
- 业务决策受影响
- 合规风险
这些问题不解决,企业花再多钱买数据中台也没用。
而MDM 就能直接解决这些问题:
- 通过统一客户、供应商的唯一标识,
- 清理重复数据,
- 建立跨系统的同步机制,
让业务部门明显感觉到 "数据准了,效率也提高了"。
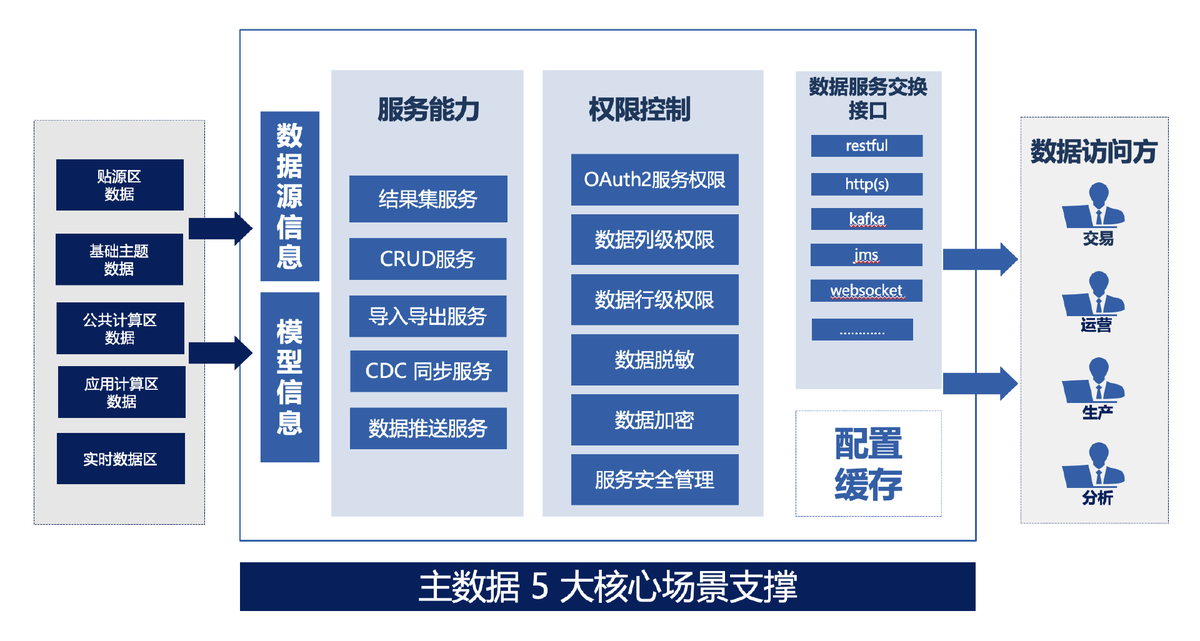
这样一来:
这种能快速看到效果的价值,比数据中台那种 "长期价值" 更能让企业决策层动心,你说对不?
3. 数字化转型初期的 "最可行路径"
对大部分企业来说,数字化转型不是一步就能到位的,得 "先把基础打牢,再谋求发展 "。MDM 的部署成本和复杂程度比数据中台低多了:
- 需求明确:不用纠结 "未来 3 年怎么用数据",只需要解决 "现在客户数据混乱" 的问题就行;
- 见效快:一般 3-6 个月就能完成核心主数据的治理,业务部门很快就能看到效果;
- 风险低:就算以后想扩展数据中台,MDM 积累的主数据质量也能为数据中台打下坚实的基础。
三、数据中台能代替 MDM 吗?
有人可能会问:"既然数据中台能整合数据,那能不能顺便把主数据也管起来?" 理论上是可以的,但真不建议。
因为实际操作中会遇到三个大问题:
1. 架构不匹配
数据中台的底层架构(比如 HDFS 存储、Spark 计算框架)是为了 "处理海量动态数据" 设计的,而主数据需要的是 "高一致性的静态数据管理"。
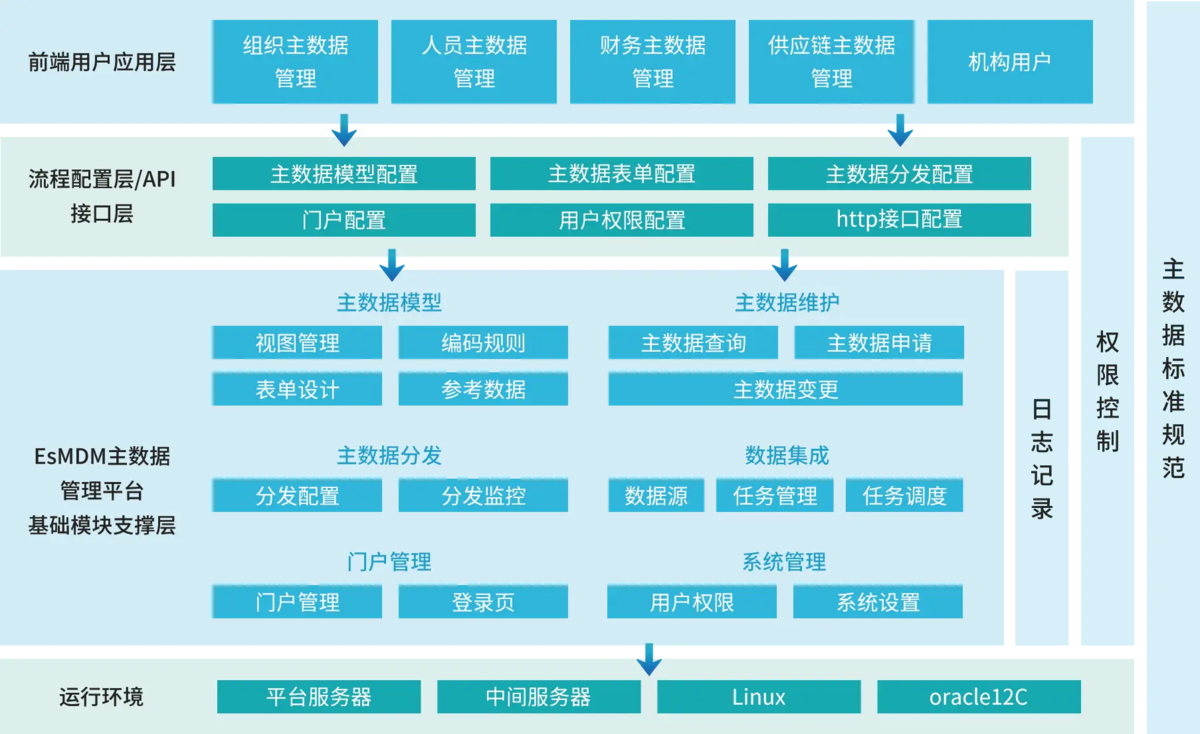
举个例子:
- 主数据 需要支持 "版本回溯",比如客户地址修改后,能查到之前的 3 个版本,
- 但数据中台 通常用 "覆盖写入" 的方式存储历史数据,要实现版本控制就得额外开发脚本,不仅麻烦,还会影响中台的处理性能。
2. 成本增加
数据中台的一些功能模块,比如数据资产目录、算法模型等,对于主数据管理来说大多是用不上的。
有家企业曾经尝试用数据中台管主数据,结果发现:
- 为了满足主数据的 "唯一性校验" 需求,得额外开发一套规则引擎;
- 为了实现 "跨系统同步",得对接 10 多个接口。
但是:
这些功能 MDM 本来就能直接提供,现在却要花双倍的成本在数据中台上做额外开发,你说这划算吗?
3. 厂商支持不到位
数据中台厂商的主要收入来自 "数据加工、分析服务",主数据管理属于 "基础治理",利润低、需求又杂。
所以:
很多厂商嘴上说 "可以管主数据",但实际支持时却很敷衍。
比如:
客户信息校验规则要企业自己定义,主数据同步出了问题,处理优先级还排在 "大屏开发" 后面。这种情况下,企业其实成了厂商练手的对象。
结语
回到最开始的问题:主数据管理系统能代替数据中台吗 ?答案很明确 ------ 不能。
MDM 和数据中台,不是谁代替谁,而是相互配合。
它们在数据治理体系中都是不可或缺的:
- MDM 是基础,解决数据**从 "混乱" 到 "准确"**的问题;
- 数据中台 是桥梁,解决数据从 "准确" 到 "有效使用" 的问题。
对企业来说,正确的做法应该是:
- 数字化转型初期:先建 MDM,解决核心数据的质量问题,让大家相信数据是可靠的;
- 数据基础打好之后:再上数据中台,基于高质量的主数据进行深度加工和分析,让数据发挥出更大的价值。
毕竟,没有准确的数据,再花哨的使用方式也只是空谈;而数据要是不能被有效使用,再准确也没多大意义。两者相互配合,才是企业数据治理的好办法。