目录
[2.数据 "断点多",打通成本高](#2.数据 “断点多”,打通成本高)
[3.数据 "用不起来",价值难落地](#3.数据 “用不起来”,价值难落地)
[第一步:明确 "集成为了谁"--- 用业务目标倒推数据需求](#第一步:明确 “集成为了谁”— 用业务目标倒推数据需求)
[第二步:盘点 "数据资产"------ 搞清楚 "有什么""缺什么"](#第二步:盘点 “数据资产”—— 搞清楚 “有什么”“缺什么”)
[第三步:清楚"数据质量"------用 "四性" 来判断](#第三步:清楚”数据质量“——用 “四性” 来判断)
[方案 1:轻量级 ETL(适合中小企业 / 离散制造)](#方案 1:轻量级 ETL(适合中小企业 / 离散制造))
[方案 2:实时流集成(适合大型制造 / 流程制造)](#方案 2:实时流集成(适合大型制造 / 流程制造))
[方案 3:数据中台(适合集团化 / 多基地制造)](#方案 3:数据中台(适合集团化 / 多基地制造))
数据集成,听着高大上,但制造业做过的都知道------坑多、失败率高!
- 设备数据在PLC里,
- 生产数据在MES里,
- 质量数据在另一台机器上...
想搞个分析?东拼西凑、手动核对,折腾半天数据不准,效率还低!
为什么花了钱、费了劲,数据集成还是做不成?
问题往往不在技术本身,而是你根本没搞清楚这三个根本性问题。
今天就跟大家好好聊聊这三个问题:
- 为啥你的数据集成总失败?
- 想成功,到底该避开哪些坑,抓住哪些关键?
- 数据集成的路径到底该怎么选?
一、为什么你的数据集成总失败?
在说 "怎么做" 之前,得先说说 "为啥难"。
国内制造企业搞数据集成费劲,根本上是:
- 业务太复杂
- 技术又跟不上
具体来说,有三个常见的让人头疼的地方:
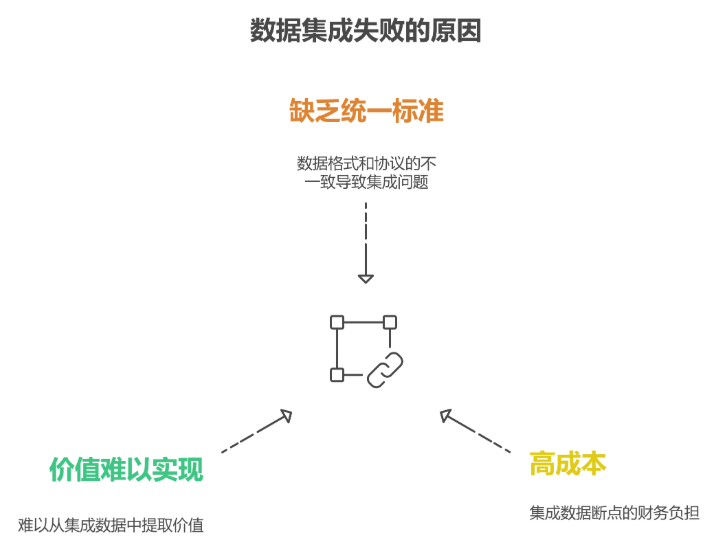
1.数据没有统一标准
制造业涉及工艺、设备、质量、供应链等好多环节,每个环节的数据说法都不一样。
比如:
- 设备部门用 "OEE(设备综合效率)" 看产能,但不同产线对 "停机" 的说法就可能不一样;
- 质量部门用 "CPK(过程能力指数)" 看良率,可供应商给的原材料数据可能用 "批次合格率";
- 老设备的传感器数据是按分钟采的,新上的智能设备是按秒采的,时间记录的精度不一样。
简单来说,就是数据标准不统一,整合起来处处是阻碍。
2.数据 "断点多",打通成本高
制造业的数据链很容易断,具体来说就是:
(1)纵向断:
从研发(PLM)→生产(MES)→售后(CRM),数据基本不怎么互通。
比如:
研发的设计 BOM(物料清单)和生产的制造 BOM,版本经常乱套,排产的时候材料用错是常事儿。
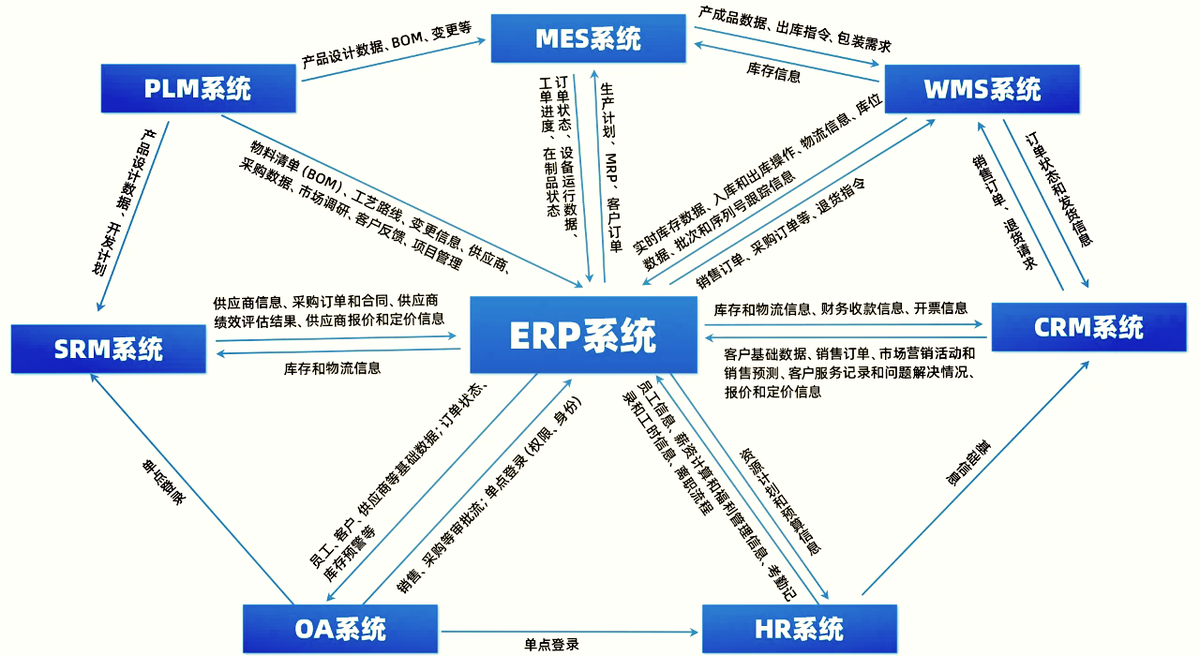
(2)横向断:
同一个工厂的不同产线,用的 ERP 模块可能都不一样:
- 有的用 SAP,
- 有的用金蝶,
- 甚至还有用 Excel 手写记录的。
(3)内外断:
供应商的交货数据、客户的订单变更,想实时传到企业内部系统里,难着呢。
这些断点,每打通一个都得花不少钱,你说难不难?
3.数据 "用不起来",价值难落地
很多企业觉得把数据放一块儿就是集成了。
结果呢?
- 数据不少,但能用到的维度太少:只采了设备运行的数据,没把工艺参数和质量结果关联起来,想分析啥参数组合容易出不良品,根本没法弄;
- 分析就停在看个表面:能看到实时产量、设备状态,可要说根据历史停机数据,预测下一周设备可能出啥故障,做不到;
- 业务部门不认可:生产工人觉得多了一堆填表的活儿,管理层觉得这些数据跟做决策没啥关系,你说这集成了有啥用?
说到底,就是数据没真正用起来,价值根本落不了地。
二、数据集成的正确做法是什么?
解决数据集成的难题,关键是别光想着技术,得盯着业务价值来做。
结合行业里做得好的例子,我总结了 "四步走" 的法子,从需求到落地,一步一步来,准没错。
第一步:明确 "集成为了谁"--- 用业务目标倒推数据需求
数据集成说到底是为了解决业务问题,不是为了炫技术。
开始之前,这三个问题必须想清楚:
首先是业务场景:
- 是想提高生产效率,比如减少停机时间;
- 还是想提升产品质量,少出点不良品;
- 或者是想让决策快点,排产能灵活调整。
其次是用户角色:
集成完了,谁用这些数据?
- 一线工人可能需要实时知道咋操作;
- 车间主任得盯着生产过程;
- 管理层要能看到全局情况。
不同的人需求不一样,工人要操作方便,管理层要看得全面,你说对吗?
这时就可以:
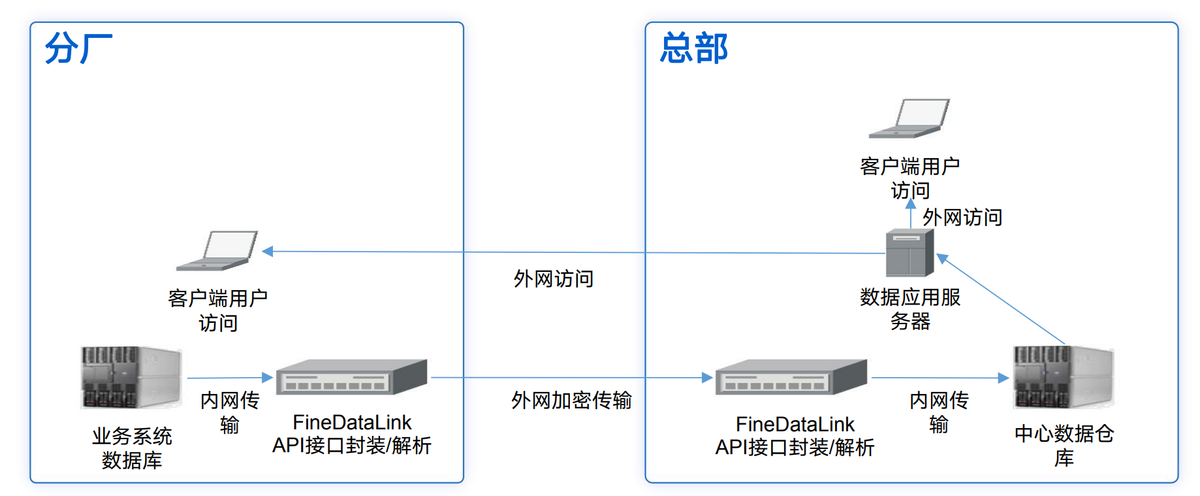
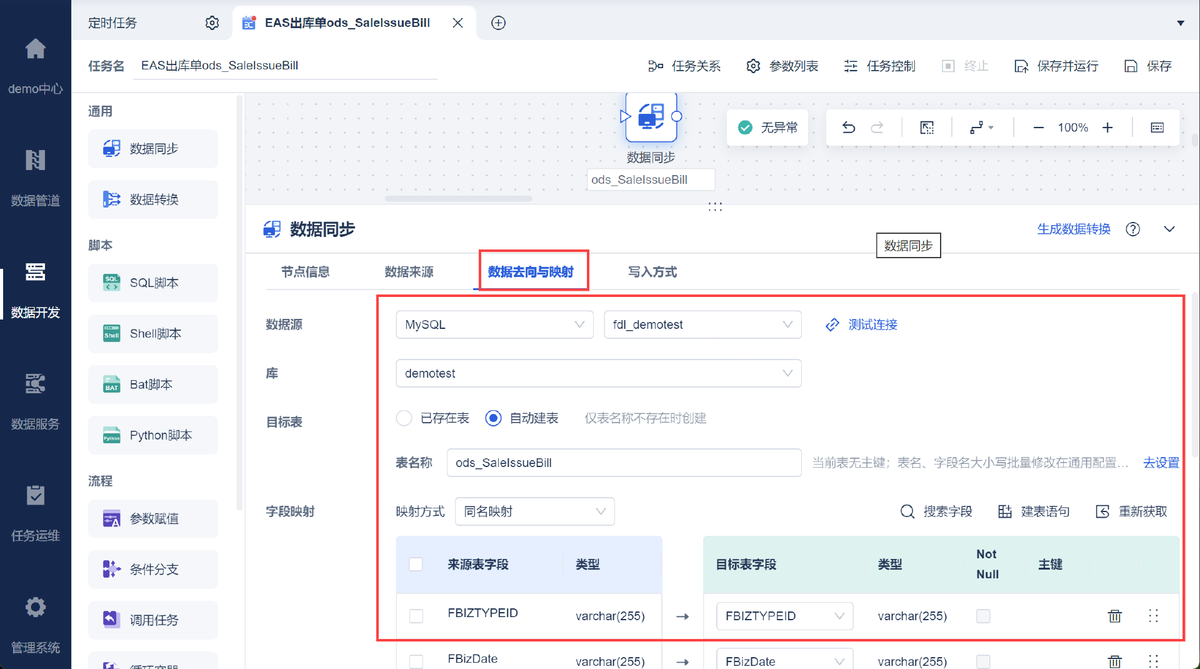
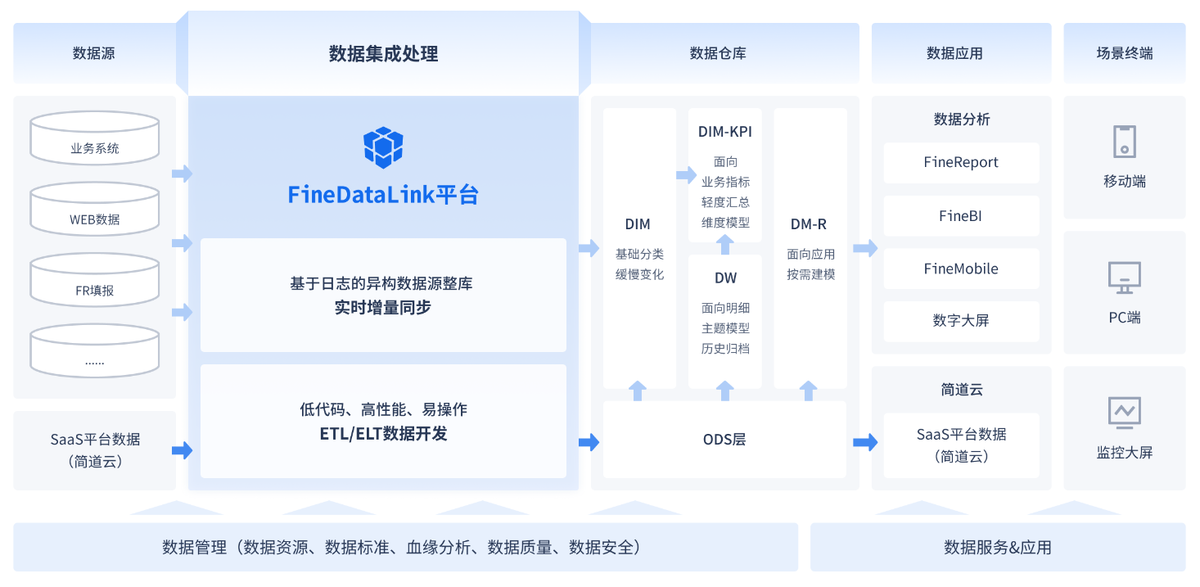
借助数据集成平台 FineDataLink,将 EAS 系统和OA 系统存储的数据,通过数据开发-定时任务将数据同步至同一数据库,形成数据分析架构线上化,实现数据口径的统一 。还能实时监控生产数据,提供及时的决策支持。FineDataLink体验地址→免费FDL激活(复制到浏览器打开)
最后看价值指标:
怎么才算集成成功了?
- 是设备综合效率(OEE)提高 5%,
- 还是不良品追溯时间从 3 天缩到 30 分钟,
- 或者订单交付准时率涨了 10%。
没有这些能衡量的指标,很容易瞎忙活。
一句话总结:明确谁用、解决啥问题、怎么算成功,集成才有方向。
第二步:盘点 "数据资产"------ 搞清楚 "有什么""缺什么"
数据集成不是简单挪数据,得先把手里的数据好好查查。
具体来说,要清楚数据在哪儿?
制造业的数据存的地方五花八门,得分类理清楚:
- 结构化数据:就是存在数据库里的,像 MES 里的生产订单、ERP 里的采购记录;
- 半结构化数据:有固定格式,但不是正经数据库里的,比如设备传感器的 JSON 日志、质检照片的元数据;
- 非结构化数据:没固定格式的,像工人的操作日志 Word 文档、会议纪要 PDF。
这些地方都得查到,漏一个都可能影响后续分析。
第三步:清楚"数据质量"------用 "四性" 来判断
"四性"简单来说就是:
- 完整性:关键的字段有没有漏的;
- 准确性:数据符不符合实际情况;
- 一致性:同一个指标在不同系统里的说法是不是一样;
- 及时性:数据采集和传输有没有耽误。
数据质量不行,集成了也白搭。
还要看缺啥数据:
比如想分析 "供应商来料质量对生产线效率的影响",得有:
- 供应商交货批次
- 来料检验结果(IQC 数据)
- 生产线因为来料问题停机的时间(MES 数据)。
要是其中某类数据没记录,比如 IQC 的详细情况没记,那得先补上,不然分析没法做。
三、数据集成路径怎么选?
数据集成的技术方法不少,关键是要为业务场景服务 ,所以要选适合自己的,别盲目追新。
根据数据要不要实时用、系统复不复杂,我总结了三种常用方案:
方案 1:轻量级 ETL(适合中小企业 / 离散制造)
如果企业:
- 数据量不大,一天下来不到 1GB,
- 系统也比较稳定,就只有 ERP 和 MES,
那用 ETL 工具,定时把数据抽出来、洗洗干净、转成能用的格式就行。
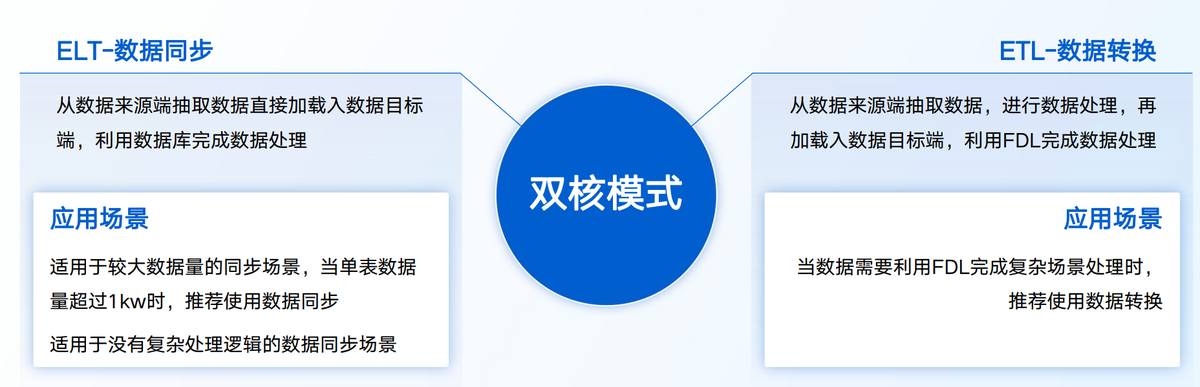
具体操作方法:
- 先把 "主数据" 定下来,像物料编码、设备编号,让各系统说法一致;
- 记清楚数据从哪儿来、经过啥处理,方便以后找问题;
- 定期检查数据质量,比如用 Python 写个小程序,看看关键指标有没有大的波动。
优势很多:
- 花钱少,工具要么免费,要么不贵;
- 容易学,技术团队学一两周就能上手。
但局限也很明显:
实时性差,一般按小时或者按天同步数据。
比如像:
设备要提前预测故障这种需要秒级响应的情况,就不适合。
简单说,就是小投入解决大问题,适合中小企业起步用。
方案 2:实时流集成(适合大型制造 / 流程制造)
像汽车、化工这些行业,需要实时盯着生产线,比如 OEE 随时算、设备一停机就报警,那必须用流处理技术。

可以进行技术组合:
- 用 Kafka 做消息队列,接收设备、传感器、PLC 的实时数据;
- 用 Flink 或者 Spark Streaming 实时计算;
- 用 ClickHouse 或者 HBase 存数据,能做到毫秒级查询。
- 用FineDataLink一键发布 API 接口,解决数据传输最后一公里问题。
具体操作方法:
- 先做 "数据降维",比如设备传感器的原始数据是每秒 1 条,而分析只需要每分钟的平均值,可先进行聚合处理;
- 设置 "流控机制",防止数据突发洪峰压垮系统;
- 做好 "断点续传",在网络中断时能从上次位置继续采集数据。
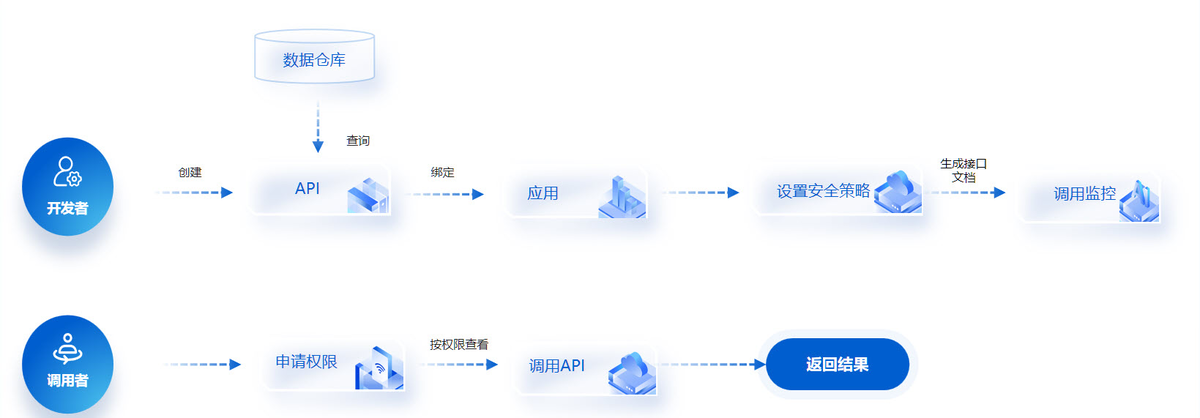
优势是:
实时性强,延迟能控制在几秒内,能马上做决策。
局限性也很明显:
- 技术比较复杂,运维团队得熟悉这些流处理工具;
- 花钱也多,服务器和人工成本都不低。
所以说:
这种方案,适合对实时性要求高的大企业。
方案 3:数据中台(适合集团化 / 多基地制造)
如果企业有好几个工厂,还不在一个地方,像家电、钢铁行业,要把不同基地、不同系统的数据连起来,建议建个数据中台。
这样就能:
- 统一数据标准,通过 MDM 主数据管理,让物料、设备、供应商的编码在全集团都一样;
- 把 ERP、MES、PLM、SCADA 等系统的数据都接到中台里;
- 业务部门想用数据,通过 API 调用就行,不用直接去碰底层系统;
- 业务人员自己用低代码工具,拖拖拽拽就能生成报表,很方便。
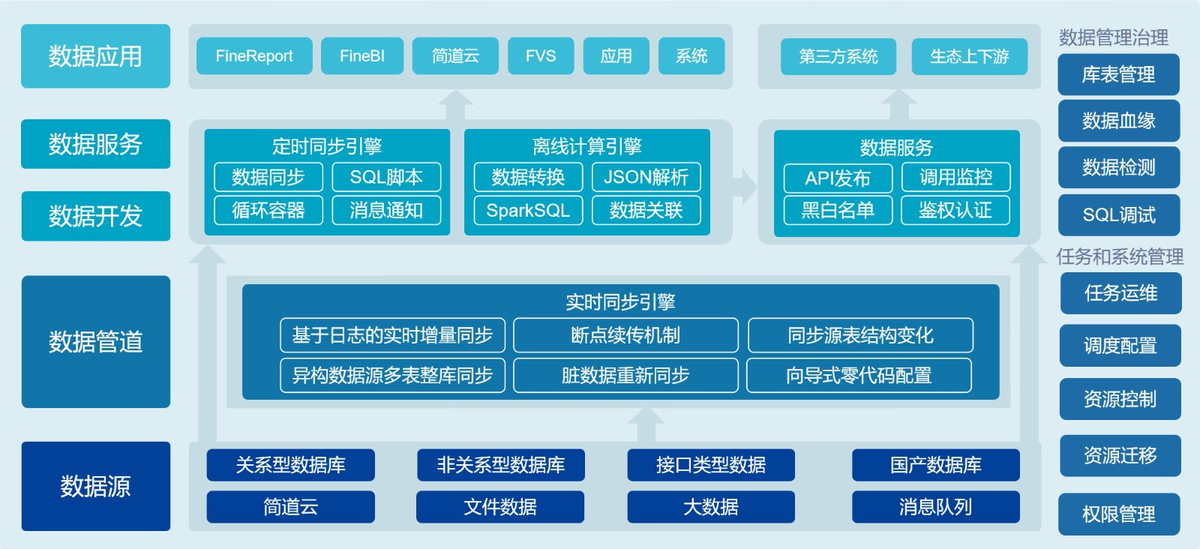
但要注意:
中台不是大仓库,别什么数据都往里塞,只整合生产、质量、供应链这些核心业务的数据就行。
还要:
成立个 "数据治理委员会",IT、生产、质量部门的负责人都参与进来,别弄成 IT 自己建,业务部门不用的情况。
一句话总结:
这种方案,适合跨地域、多工厂的大企业统一管理数据。
结语
国内制造业现在正从 "拼规模" 转向 "拼效率""拼质量" ,数据集成就是这场转型的基础。说到底,制造业数据集成能不能成,关键就看你有没有搞定这三件事:
- 让数据"说同一种话" (统一标准),
- 把断掉的"数据链"接起来 (打通断点),
- 让数据真正"发挥价值" (提升业务)。
它不是简单地挪数据,**成功的集成,是让对的数据,在对的时间,顺畅地流到需要它的人手里。**做到这些,制造业的数字化转型才算真正开始。