Microorganisms infiltrating through brain-machine interfaces --v 6.0

Microorganisms infiltrating through brain-machine interfaces ,redpupil --v 6.0

Microorganisms infiltrating through brain-machine interfaces,billion girls dream --v 6.0

--niji 6
"动漫风"模型,可以生成高质量的二次元图像以及插画。

▎--sref URL
风格一致性,URL 是风格参考图片的网址,通过提供图像URL来指定理想的视觉风格。
下面是示例:图1 作为垫图,另外 选择一张作为视觉风格参考(图2),生成了一组图3

图1

图2
▎--cref URL
角色一致性功能,URL 是角色参考图片的网址。Midjourney会分析参考图片的角色特征,在生成新图片时尽可能保持一致。
下面是示例:图1 作为角色参考图,生成了一组图2,很像了。

图1

图2
▎局部修图
案例:比如下图生成的图片里有文字,需要去掉,而出现的原因是我垫的那张图也有文字
操作:点击vary(region),进入局部修图,方法删除垫图的链接,涂抹有文字的区域,重新生图



Stable Diffusion 基础操作
文生图
如图所示 Stable Diffusion WebUl 的操作界面主要分为: 模型区域、功能区域、参数区域出图区域
txt2img 为文生图功能,重点参数介绍:
正向提示词: 描述图片中希望出现的内容
反向提示词: 描述图片中不希望出现的内容
Sampling method: 采样方法,推荐选择 Euler a 或 DPM++ 系列,采样速度快
Sampling steps: 迭代步数,数值越大图像质量越好,生成时间也越长,一般控制在 30-50就能出效果
Restore faces: 可以优化脸部生成
Width/Height: 生成图片的宽高,越大越消耗显存,生成时间也越长,一般方图 512x512竖图 512x768,需要更大尺寸,可以到 Extras 功能里进行等比高清放大
CFG: 提示词相关性,数值越大越相关,数值越小越不相关,一般建议 7-12 区间
Batch count/Batch size: 生成批次和每批数量,如果需要多图,可以调整下每批数量
Seed: 种子数,-1 表示随机,相同的种子数可以保持图像的一致性,如果觉得一张图的结构不错,但对风格不满意,可以将种子数固定,再调整 prompt 生成

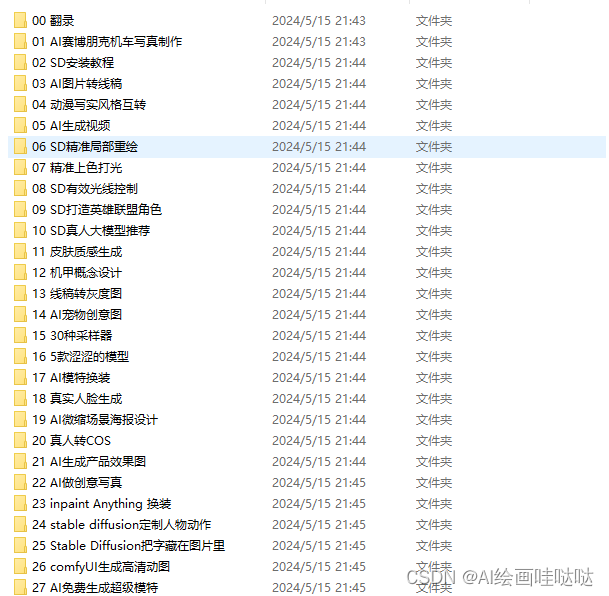
图生图
img2img 功能可以生成与原图相似构图色彩的画像,或者指定一部分内容进行变换。可以重点使用 Inpaint 图像修补这个功能:
Resize mode: 缩放模式,Just resize 只调整图片大小,如果输入与输出长宽比例不同,图片会被拉伸。Crop and resize 裁剪与调整大小,如果输入与输出长宽比例不同,会以图片中心向四周,将比例外的部分进行裁剪。Resize and fill 调整大小与填充,如果输入与输出分辨率不同,会以图片中心向四周,将比例内多余的部分进行填充
Mask blur: 蒙版模糊度,值越大与原图边缘的过度越平滑,越小则边缘越锐利
Mask mode: 蒙版模式,Inpaint masked 只重绘涂色部分,Inpaint not masked 重绘除了涂色的部分
Masked Content: 蒙版内容,fill 用其他内容填充,original 在原来的基础上重绘
Inpaint area: 重绘区域,Whole picture 整个图像区域,Only masked 只在蒙版区域
Denoising strength: 重绘幅度,值越大越自由发挥,越小越和原图接近
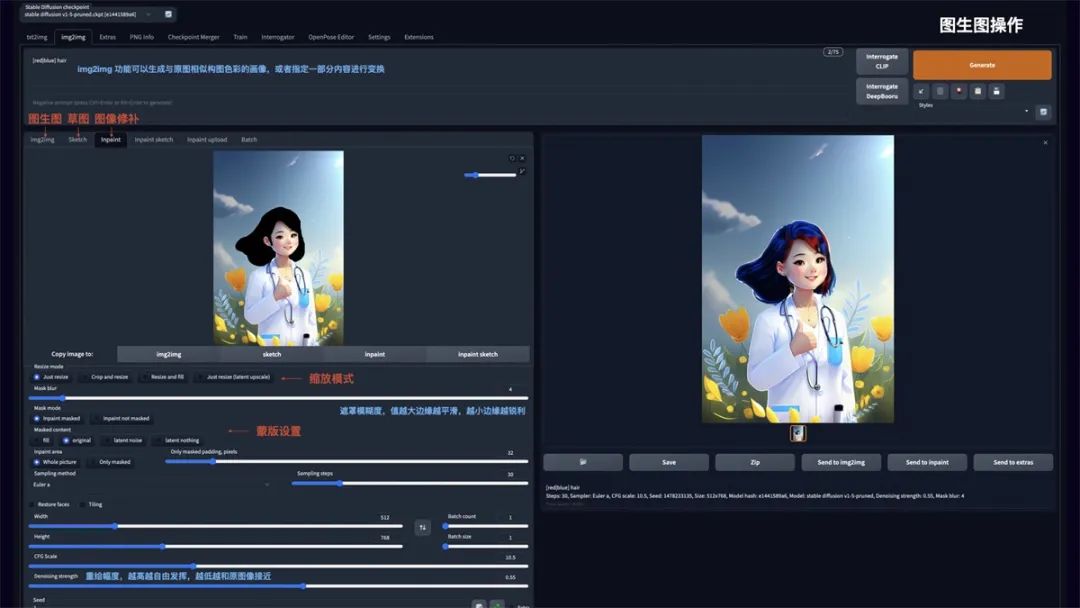
ControlNet
安装完 ControlNet 后,在 txt2img 和 img2img 参数面板中均可以调用 ControlNet。操作说明:
Enable: 启用 ControlNet
Low VRAM: 低显存模式优化,建议 8G 显存以下开启
Guess mode: 猜测模式,可以不设置提示词,自动生成图片
Preprocessor: 选择预处理器主要有 OpenPose、Canny、HED、Scribble、MIsd.Seg、Normal Map、Depth
Model: ControlNet 模型,模型选择要与预处理器对应
Weight: 权重影响,使用 ControlNet 生成图片的权重占比影响
Guidance strength(T): 引导强度,值为 1时,代表每选代 1 步就会被 ControlNet引导1次
Annotator resolution: 数值越高,预处理图像越精细Canny low/high threshold: 控制最低和最高采样深度Resize mode: 图像大小模式,默认选择缩放至合适
Canvas width/height: 画布宽高
Create blank canvas: 创建空白画布
Preview annotator result: 预览注释器结果,得到一张 ControlNet 模型提取的特征图片
Hide annotator result: 隐藏预览图像窗
LORA 模型训练说明
前面提到 LORA 模型具有训练速度快,模型大小适中 (100MB 左右),配置要求低 (8G 显存),能用少量图片训练出风格效果的优势。
以下简要介绍该模型的训练方法:
最后想说
AIGC(AI Generated Content)技术,即人工智能生成内容的技术,具有非常广阔的发展前景。随着技术的不断进步,AIGC的应用范围和影响力都将显著扩大。以下是一些关于AIGC技术发展前景的预测和展望:
1、AIGC技术将使得内容创造过程更加自动化,包括文章、报告、音乐、艺术作品等。这将极大地提高内容生产的效率,降低成本。2、在游戏、电影和虚拟现实等领域,AIGC技术将能够创造更加丰富和沉浸式的体验,推动娱乐产业的创新。3、AIGC技术可以帮助设计师和创意工作者快速生成和迭代设计理念,提高创意过程的效率。
未来,AIGC技术将持续提升,同时也将与人工智能技术深度融合,在更多领域得到广泛应用。感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程。
对于从来没有接触过AI绘画的同学,我已经帮你们准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
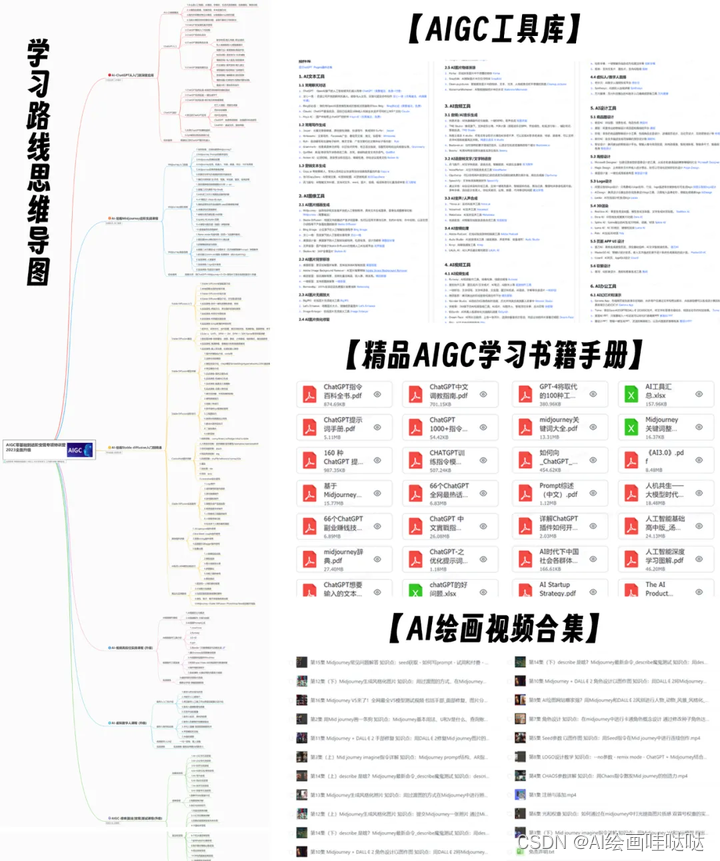
AIGC学习必备工具和学习步骤
工具都帮大家整理好了,安装就可直接上手
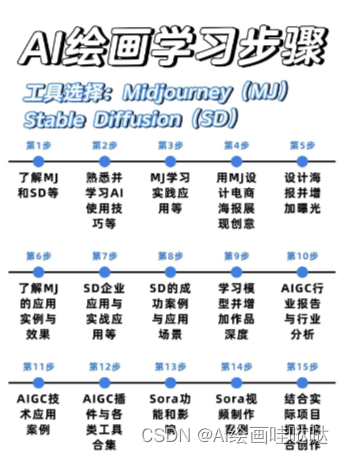
现在AI绘画还是发展初期,大家都在摸索前进。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。
学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图、Stable Diffusion安装包、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册、AI绘画视频教程、AIGC实战等等。
【Stable Diffusion安装包(含常用插件、模型)】
【AI绘画12000+提示词库】
【AI绘画800+骨骼姿势图】

【AI绘画视频合集】
还有一些已经总结好的学习笔记,可以学到不一样的思路。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。