涡扇发动机全称为涡轮风扇发动机,是一种先进的空中引擎,由涡轮喷气发动机发展而来。涡扇发动机主要特点是首级压缩机的面积比涡轮喷气发动机大。同时,空气螺旋桨(扇)将部分吸入的空气从喷射引擎喷射出来,并将其向后推动,以达到推进的目的。

涡扇发动机结构是一种特殊的引擎结构,它在涡轮喷气发动机的基础上再增加了 1-2 级低压(低速)涡轮,这些涡轮可以驱动一定数量的风扇,消耗掉一部分涡喷发动机(核心机)的燃气排气动能,从而进一步降低燃气排出速度,提高引擎的性能。从前至后,涡扇发动机由风扇,压气机,燃烧室,导向叶片,高压低压涡轮,加力燃烧室和尾喷管组成。
目前大多数论文的实验中使用的数据集是美国国家航空航天局的 C-MAPSS 数据集。C-MAPSS 数据集是由模拟航空发动机的模拟软件生成。模拟发动机的结构图如下:
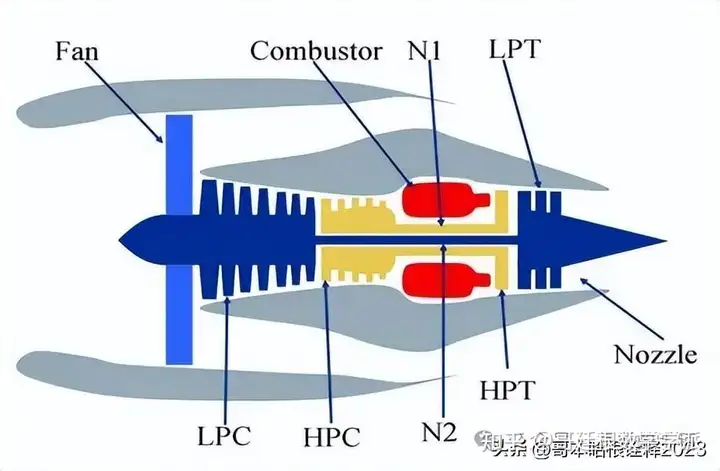
主要部件有低压涡轮(low pressure turbine,LPT)、高压涡轮(high pressure turbine,HPT)、高压压气机(high pressure compressor,HPC)、低压压气机(low pressure compressor,LPC)、风扇(fan)、喷嘴(nozzle)、燃烧室(combustor)、低压转子转速(N1)和高压转子转速(N2)等。风扇在正常飞行条件下工作,将空气分流至内、外涵道。LPC 和 HPC 通过增温增压技术将高温、压力混合气体输送到 combustor。LPT 可以有效减少空气的流速,大大提高飞机煤油的化学能转换效率。而 HPT 则是利用高温、高压气体对涡轮叶片施加做功,从而产生机械能。N1、N2 和 nozzle 的应用大大提升了发动机的燃烧效率。
监控涡扇发动机状况为21个传感器。由于传感器的单位不同,传感器记录的数值的量级也有所差异,位于10的-2次方到10的3次方之间。例如,燃烧室油气比数值的量级是10的-2次方;低压涡轮冷气流量数值的量级是10的1次方。表2-2描述了NASA的C-MAPSS数据集。由于不同的操作条件和故障模式,数据集可以分为四个子数据集,依次是FD001、FD002、FD003和FD004。每个子数据分为训练集和测试集,记录了发动机的3种操作设置和21个传感器数据。每个子数据集通过.txt文件单独保存。在.txt文件中,每一行记录了一个引擎某个时间刻的3种操作设置和21个传感器数据。关于故障模式和操作条件方面,FD001和FD002子数据集包含一种故障模式(高压压气机退化),FD003和FD004包含两种故障模式(高压压气机退化和风扇退化);FD001和FD003只有一种操作条件,FD002和FD004有六种操作条件。由于FD002和FD004子数据集引擎的操作环境复杂多变,FD002和FD004子数据集中RUL的预测更加困难。
可见,涡扇发动机数据集包含大量的按时间顺序采集的传感器数据,这些数据包括发动机温度、压力、振动等多个方面的指标。并且涡扇发动机可能会出现多种故障模式。这适合用时间序列模型去对涡扇发动机的剩余使用寿命做预测。
鉴于此,采用机器学习和深度学习对C-MAPSS涡扇发动机进行剩余使用寿命RUL预测,Python代码,Jupyter Notebook环境,方法如下:
(1)VAR with LSTM
(2)VAR with Logistic Regression
(3)LSTM (Lookback=20,10,5,1)
LSTM Lookback=10的结果如下:
final_pred = []
count = 0
for i in range(100):
j = max_cycles[i]
temp = pred[count+j-1]
count=count+j
final_pred.append(int(temp))
print(final_pred)
fig = plt.figure(figsize=(18,10))
plt.plot(final_pred,color='red', label='prediction')
plt.plot(y_test,color='blue', label='y_test')
plt.legend(loc='upper left')
plt.grid()
plt.show()
print("mean_squared_error >> ", mean_squared_error(y_test,final_pred))
print("root_mean_squared_error >> ", math.sqrt(mean_squared_error(y_test,final_pred)))
print("mean_absolute_error >>",mean_absolute_error(y_test,final_pred))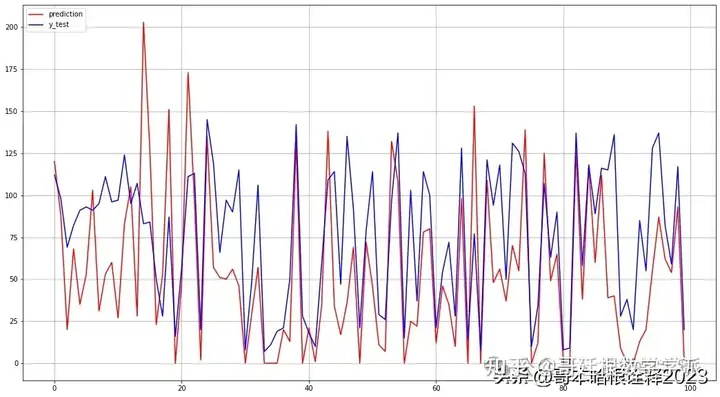
VAR with Logistic Regression结果:
fig = plt.figure(figsize=(18,10))
plt.plot(logistic_pred,color='red', label='prediction')
plt.plot(y_test,color='blue', label='y_test')
plt.legend(loc='upper left')
plt.grid()
plt.show()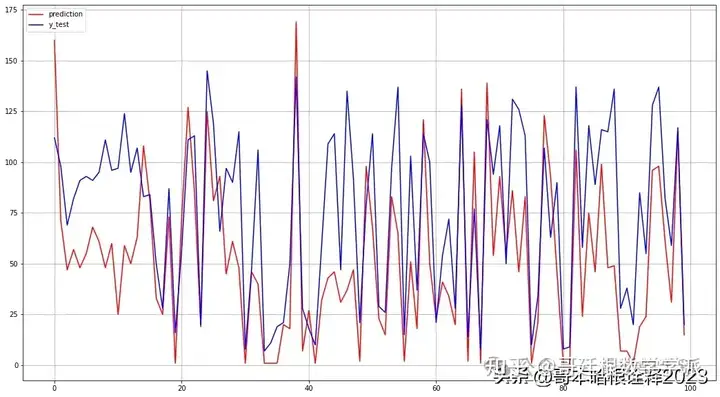
VAR with LSTM结果:
fig = plt.figure(figsize=(18,10))
plt.plot(lstm_pred,color='red', label='prediction')
plt.plot(y_test,color='blue', label='y_test')
plt.legend(loc='upper left')
plt.grid()
完整代码可通过知乎学术咨询获得:
https://www.zhihu.com/consult/people/792359672131756032?isMe=1
plt.show()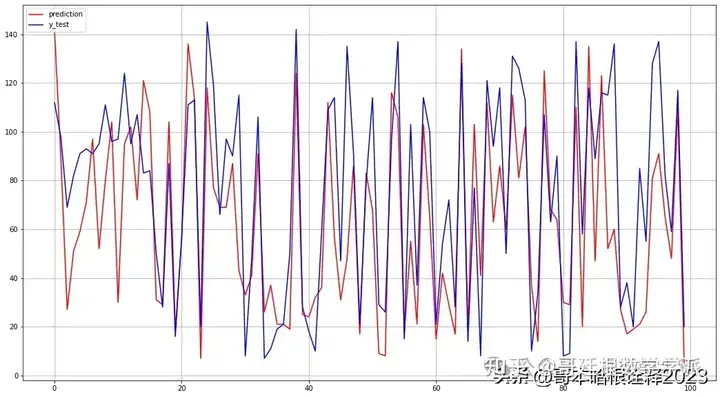
担任《Mechanical System and Signal Processing》《中国电机工程学报》《控制与决策》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。