
概述
前三期文章中已经介绍到了 Selenium 与 Playwright 、Pyppeteer 的使用方法,它们的功能都非常强大。而本期要讲的 DrissionPage 更为独特,强大,而且使用更为方便,目前检测少,强烈推荐!!!
这里推荐观看十一姐 B 站 DrissionPage 系列视频,很详细:
合集·爬虫自动化 DrissionPage 实战案例:
https://space.bilibili.com/308704191/channel/collectiondetail?sid=1947582
DrissionPage 相关资料:
官方文档:https://www.drissionpage.cn
Drissionpage "姊妹库":https://gitee.com/haiyang0726/SaossionPage
DrissionPage 的使用
介绍
DrissionPage 是一个基于 python 的网页自动化工具。它既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和 requests 的高效率。它功能强大,内置无数人性化设计和便捷功能。它的语法简洁而优雅,代码量少,对新手友好。
-
支持系统:Windows、Linux、Mac;
-
python 版本:3.6 及以上;
-
支持应用:Chromium 内核浏览器(如 Chrome、Edge),electron 应用;
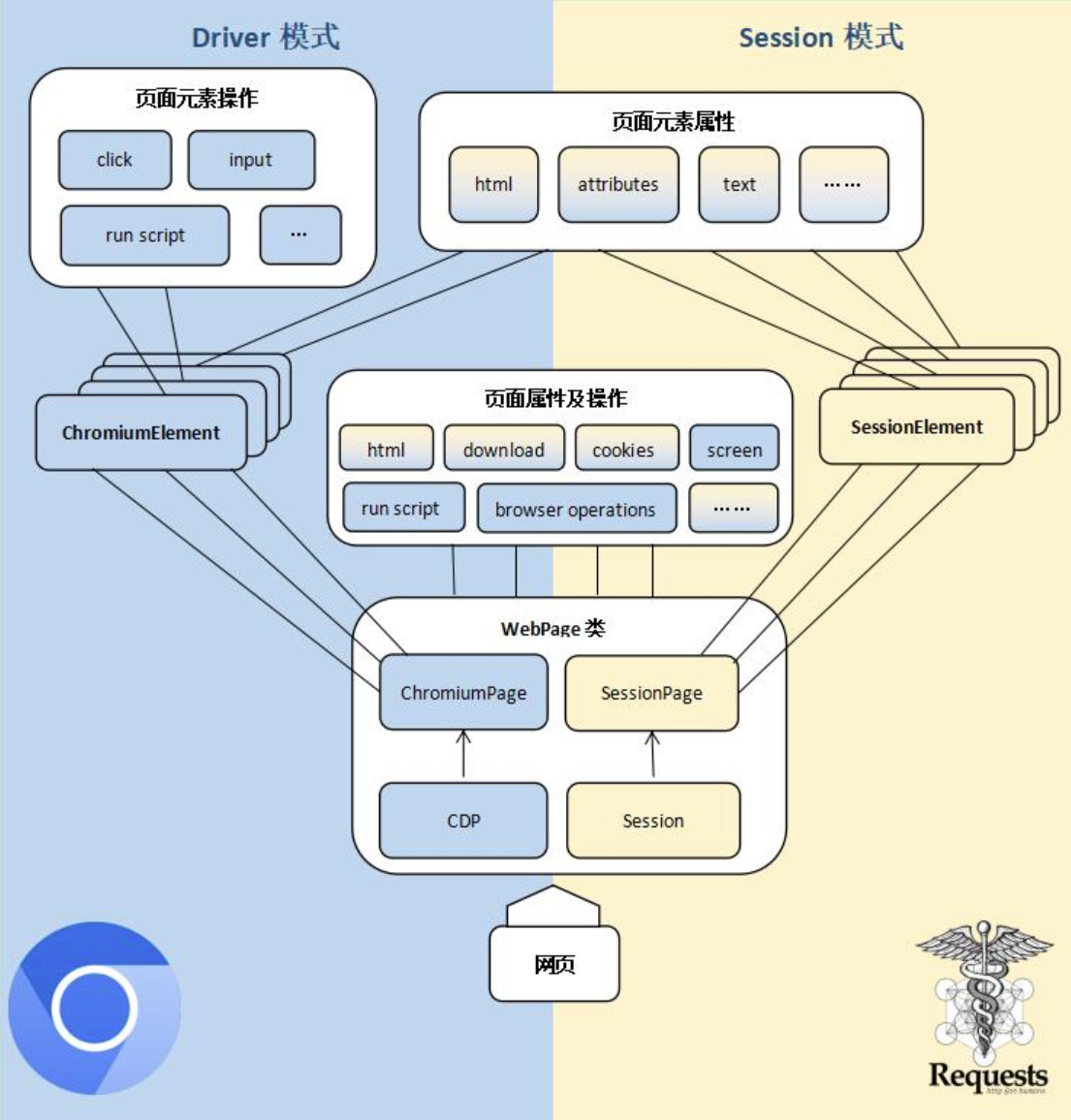
特性
强大的自研内核
本库采用全自研的内核,内置了无数实用功能,对常用功能作了整合和优化,对比 selenium,有以下优点:
- 无 webdriver 特征;
- 无需为不同版本的浏览器下载不同的驱动;
- 运行速度更快;
- 可以跨 iframe 查找元素,无需切入切出;
- 把 iframe 看作普通元素,获取后可直接在其中查找元素,逻辑更清晰;
- 可以同时操作浏览器中的多个标签页,即使标签页为非激活状态,无需切换;
- 可以直接读取浏览器缓存来保存图片,无需用 GUI 点击另存;
- 可以对整个网页截图,包括视口外的部分(90 以上版本浏览器支持);
- 可处理非
open状态的 shadow-root。
亮点功能
除了以上优点,本库还内置了无数人性化设计。
- 极简的语法规则,集成大量常用功能,代码更优雅;
- 定位元素更加容易,功能更强大稳定;
- 无处不在的等待和自动重试功能。使不稳定的网络变得易于控制,程序更稳定,编写更省心;
- 提供强大的下载工具。操作浏览器时也能享受快捷可靠的下载功能;
- 允许反复使用已经打开的浏览器。无需每次运行从头启动浏览器,调试超方便;
- 使用 ini 文件保存常用配置,自动调用,提供便捷的设置,远离繁杂的配置项;
- 内置 lxml 作为解析引擎,解析速度成几个数量级提升;
- 使用 POM 模式封装,可直接用于测试,便于扩展;
- 高度集成的便利功能,从每个细节中体现;
- 还有很多细节,这里不一一列举,欢迎实际使用中体验。
安装升级
javascript
# 安装
pip install DrissionPage
# 升级最新稳定版
pip install DrissionPage --upgrade
# 指定版本升级
pip install DrissionPage==4.0.0b17- 如何在无界面 Linux 使用:
CentOS 请参考这篇文章:
linux 部署说明:https://blog.csdn.net/sinat_39327967/article/details/132181129
Ubuntu 请参考这篇文章:
DrissionPage 在 Ubuntu Linux 的使用:https://zhuanlan.zhihu.com/p/674687748
使用
访问网页
python
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions().set_paths(browser_path=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe")
# 1、设置无头模式:co.headless(True)
# 2、设置无痕模式:co.incognito(True)
# 3、设置访客模式:co.set_argument('--guest')
# 4、设置请求头user-agent:co.set_user_agent()
# 5、设置指定端口号:co.set_local_port(7890)
# 6、设置代理:co.set_proxy('http://localhost:1080')
page = ChromiumPage(co)
page.get('https://gitee.com/login', retry=3, timeout=15, interval=2)
# 定位到账号文本框,获取文本框元素
ele = page.ele('#user_login')
# 输入对文本框输入账号
ele.input('您的账号')
# 定位到密码文本框并输入密码
page.ele('#user_password').input('您的密码')
# 点击登录按钮
page.ele('@value=登 录').click()获取浏览器路径的方法:
- 这里的浏览器路径不一定是 Chrome,Edge 等 Chromium 内核的浏览器都可以;
- 打开浏览器,在地址栏输入
chrome://version(Edge 输入edge://version),回车
如图所示,红框中就是要获取的路径:
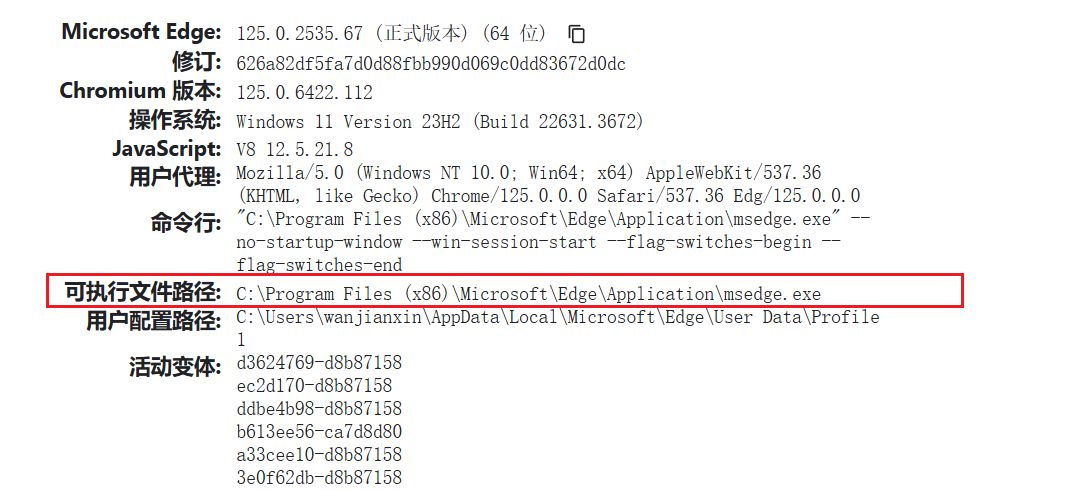
- 此法不限于 Windows,有界面的 Linux 也是这样取路径。
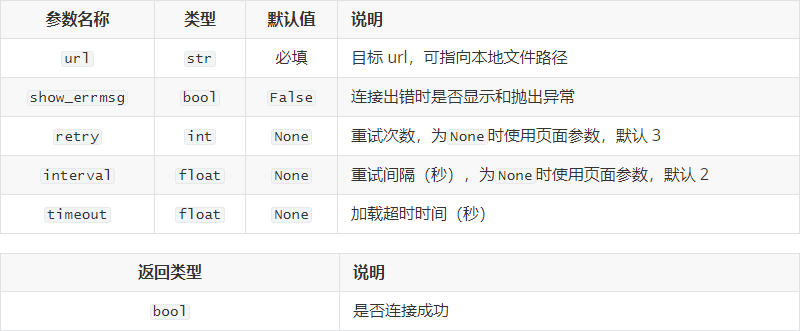
- get()
该方法用于跳转到一个网址。当连接失败时,程序会进行重试:
获取查找元素
本库提供一套简洁易用的语法,用于快速定位元素,并且内置等待功能、支持链式查找,减少了代码的复杂性。
同时也兼容 css selector、xpath、selenium 原生的 loc 元组。
定位元素大致分为三种方法:
- 在页面或元素内查找子元素;
- 根据 DOM 结构相对定位;
- 根据页面布局位置相对定位;
- xpath 方式:
python
# 输入
page.ele('xpath://input[@id="bindMobileFree"]').input("123456789")
# 点击
page.ele('x://span[@class="getYZM_btn"]').click()- 其他方式:
python
from DrissionPage import SessionPage
page = SessionPage()
page.get('https://gitee.com/explore')
# 获取包含"全部推荐项目"文本的 ul 元素
ul_ele = page.ele('tag:ul@@text():全部推荐项目')
# 获取该 ul 元素下所有 a 元素
titles = ul_ele.eles('tag:a')
# 遍历列表,打印每个 a 元素的文本
for i in titles:
print(i.text)
python
foot = page.ele('#footer-left') # 用 id 查找元素
first_col = foot.ele('css:>div') # 使用 css selector 在元素的下级中查找元素(第一个)
lnk = first_col.ele('text:命令学') # 使用文本内容查找元素
text = lnk.text # 获取元素文本
href = lnk.attr('href') # 获取元素属性值
print(text, href, '\n')
# 简洁模式串联查找
text = page('@id:footer-left')('css:>div')('text:命令学').text
print(text)等待
-
✅️️ 页面对象的等待方法:
-
📌
wait.load_start():此方法用于等待页面进入加载状态;-
注意
get()已内置等待加载开始,后无须跟wait.load_start();
-
-
📌
wait.doc_loaded():此方法用于等待页面文档加载完成;- 注意
- 此功能仅用于等待页面主 document 加载,不能用于等待 js 加载的变化;
- 除非
load_mode为None,get()方法已内置等待加载完成,后面无须添加等待;
- 注意
-
📌
wait.eles_loaded():此方法用于等待元素被加载到 DOM; -
📌
wait.ele_displayed():此方法用于等待一个元素变成显示状态; -
📌
wait.ele_hidden():此方法用于等待一个元素变成隐藏状态; -
📌
wait.ele_deleted():此方法用于等待一个元素被从 DOM 中删除; -
📌
wait.download_begin():此方法用于等待下载开始; -
📌
wait.upload_paths_inputted():此方法用于等待自动填写上传文件路径; -
📌
wait.new_tab():此方法用于等待新标签页出现; -
📌
wait.title_change():此方法用于等待 title 变成包含或不包含指定文本; -
📌
wait.url_change():此方法用于等待 url 变成包含或不包含指定文本。 比如有些网站登录时会进行多重跳转,url 发生多次变化,可用此功能等待到达最终需要的页面; -
📌
wait.alert_closed():此方法用于等待弹出框被关闭; -
📌
wait():此方法用于等待若干秒;
-
-
✅️️ 元素对象的等待方法
-
📌
wait.displayed():此方法用于等待元素从隐藏状态变成显示状态; -
📌
wait.hidden():此方法用于等待元素从显示状态变成隐藏状态; -
📌
wait.deleted():此方法用于等待元素被从 DOM 删除; -
📌
wait.covered():此方法用于等待元素被其它元素覆盖; -
📌
wait.not_covered():此方法用于等待元素不被其它元素覆盖; -
📌
wait.enabled():此方法用于等待元素变为可用状态; -
📌
wait.disabled():此方法用于等待元素变为不可用状态; -
📌
wait.stop_moving():此方法用于等待元素运动结束; -
📌
wait.clickable():此方法用于等待元素可被点击; -
📌
wait.disabled_or_deleted():此方法用于等待元素变为不可用或被删除; -
📌
wait():此方法用于等待若干秒。
-
监听网络数据
- 注意:要先启动监听,再执行动作,
listen.start()之前的数据包是获取不到的; - 等待并获取:
- 等待并获取:
python
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get('https://gitee.com/explore/all') # 访问网址,这行产生的数据包不监听
page.listen.start('gitee.com/explore') # 开始监听,指定获取包含该文本的数据包(部分url)
for _ in range(5):
page('@rel=next').click() # 点击下一页
res = page.listen.wait() # 等待并获取一个数据包
print(res.url) # 输出数据包url
print(res.response.headers) # 输出响应头
print(res.response.statusText) # 输出响应状态码
print(res.response.body) # 输出响应内容- 实时获取:
python
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.listen.start('gitee.com/explore') # 开始监听,指定获取包含该文本的数据包
page.get('https://gitee.com/explore/all') # 访问网址
i = 0
for packet in page.listen.steps():
print(packet.url) # 打印数据包url
page('@rel=next').click() # 点击下一页
i += 1
if i == 5:
break动作链
-
✅️ 使用方法
* 📌 使用内置actions属性pythonfrom DrissionPage import ChromiumPage page = ChromiumPage() page.get('https://www.baidu.com') page.actions.move_to('#kw').click().type('DrissionPage') page.actions.move_to('#su').click()- 📌 使用新对象
pythonfrom DrissionPage import ChromiumPage from DrissionPage.common import Actions page = ChromiumPage() ac = Actions(page) page.get('https://www.baidu.com') ac.move_to('#kw').click().type('DrissionPage') ac.move_to('#su').click()- 📌 操作方式
pythonac.move_to(ele).click().type('some text') -
✅️ 移动鼠标
- 📌
move_to():此方法用于移动鼠标到元素中点,或页面上的某个绝对坐标; - 📌
move():此方法用于使鼠标相对当前位置移动若干距离; - 📌
up():此方法用于使鼠标相对当前位置向上移动若干距离; - 📌
down():此方法用于使鼠标相对当前位置向下移动若干距离; - 📌
left():此方法用于使鼠标相对当前位置向左移动若干距离; - 📌
right():此方法用于使鼠标相对当前位置向右移动若干距离。
- 📌
-
✅️ 鼠标按键
- 📌
click():此方法用于单击鼠标左键,单击前可先移动到元素上; - 📌
r_click():此方法用于单击鼠标右键,单击前可先移动到元素上; - 📌
m_click():此方法用于单击鼠标中键,单击前可先移动到元素上; - 📌
db_click():此方法用于双击鼠标左键,双击前可先移动到元素上; - 📌
hold():此方法用于按住鼠标左键不放,按住前可先移动到元素上; - 📌
release():此方法用于释放鼠标左键,释放前可先移动到元素上; - 📌
r_hold():此方法用于按住鼠标右键不放,按住前可先移动到元素上; - 📌
r_release():此方法用于释放鼠标右键,释放前可先移动到元素上; - 📌
m_hold():此方法用于按住鼠标中键不放,按住前可先移动到元素上; - 📌
m_release():此方法用于释放鼠标中键,释放前可先移动到元素上。
- 📌
-
✅️ 滚动滚轮
- 📌
scroll():此方法用于滚动鼠标滚轮,滚动前可先移动到元素上;
- 📌
-
✅️ 键盘按键和文本输入
- 📌
key_down():此方法用于按下键盘按键。非字符串按键(如 ENTER)可输入其名称,也可以用 Keys 类获取; - 📌
key_up():此方法用于提起键盘按键。非字符串按键(如 ENTER)可输入其名称,也可以用 Keys 类获取; - 📌
input():此方法用于输入一段文本或多段文本,也可输入组合键。多段文本或组合键用列表传入; - 📌
type():此方法用于以按键盘的方式输入一段或多段文本。也可输入组合键。type()与input()区别在于前者模拟按键输入,逐个字符按下和提起,后者直接输入一整段文本。
- 📌
-
✅️ 等待
- 📌
wait():此方法用于等待若干秒;
- 📌
-
✅️ 属性
- 📌
owner:此属性返回使用此动作链的页面对象; - 📌
curr_x:此属性返回当前光标位置的 x 坐标; - 📌
curr_y:此属性返回当前光标位置的 y 坐标。
- 📌
-
✅️ 示例
- 📌 模拟输入 ctrl+a
pythonfrom DrissionPage import ChromiumPage from DrissionPage.common import Keys, Actions # 创建页面 page = ChromiumPage() # 创建动作链对象 ac = Actions(page) # 鼠标移动到<input>元素上 ac.move_to('tag:input') # 点击鼠标,使光标落到元素中 ac.click() # 按下 ctrl 键 ac.key_down(Keys.CTRL) # 输入 a ac.type('a') # 提起 ctrl 键 ac.key_up(Keys.CTRL)链式写法:
pythonac.click('tag:input').key_down(Keys.CTRL).type('a').key_up(Keys.CTRL)更简单的写法:
pythonac.click('tag:input').type(Keys.CTRL_A)- 📌 拖拽元素
把一个元素向右拖拽 300 像素:
pythonfrom DrissionPage import ChromiumPage from DrissionPage.common import Actions # 创建页面 page = ChromiumPage() # 创建动作链对象 ac = Actions(page) # 左键按住元素 ac.hold('#div1') # 向右移动鼠标300像素 ac.right(300) # 释放左键 ac.release()把一个元素拖拽到另一个元素上:
pythonac.hold('#div1').release('#div2') -
✅️ 页面对象内置动作链
python
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.actions.move_to((300, 500)).hold().move(300).release()标签页操作
📌 注意:可以对多标签页操作, 即可实现并发自动化。
-
✅️️ 标签页总览
- 📌
tabs_count:此属性返回标签页数量。 - 📌
tab_ids:此属性以list方式返回所有标签页 id。
- 📌
-
✅️️ 新建标签页
- 📌
new_tab():该方法用于新建一个标签页,该标签页在最后面。只有 Page 对象拥有此方法。
- 📌
-
✅️️ 获取标签页对象
- 📌
get_tab():此方法用于获取一个标签页对象。可指定标签页序号、id、标题、url、类型等条件用于检索。当id_or_num不为None时,其它参数无效。当所有参数都为None时,获取 Page 对象控制的标签页的 Tab 对象。title、url和tab_type三个参数是与关系。只有 Page 对象拥有此方法。 - 📌
get_tabs():此方法用于查找符合条件的 tab 对象
- 📌
-
✅️️ 使用多例
pythonfrom DrissionPage import ChromiumPage from DrissionPage.common import Settings page = ChromiumPage() page.new_tab() page.new_tab() # 未启用多例: tab1 = page.get_tab(1) tab2 = page.get_tab(1) print(id(tab1), id(tab2)) # 启用多例: Settings.singleton_tab_obj = False tab1 = page.get_tab(1) tab2 = page.get_tab(1) print(id(tab1), id(tab2))
-
✅️️ 关闭和重连
- 📌
close() - 📌
disconnect() - 📌
reconnect() - 📌
close_tabs()
- 📌
-
✅️️ 激活标签页
- 📌
set.tab_to_front() - 📌
set.activate()
- 📌
-
✅️️ 多标签页协同
截图和录像
✅️️ 页面截图
python
# 对整页截图并保存
page.get_screenshot(path='tmp', name='pic.jpg', full_page=True)✅️️ 元素截图
python
img = page('tag:img')
img.get_screenshot()
bytes_str = img.get_screenshot(as_bytes='png') # 返回截图二进制文本✅️️ 页面录像
python
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.screencast.set_save_path('video') # 设置视频存放路径
page.screencast.set_mode.video_mode() # 设置录制
page.screencast.start() # 开始录制
page.wait(3)
page.screencast.stop() # 停止录制执行 JS 语句
python
page.run_js(f'localStorage.setItem("__user_token.v3",`{token}`)')
page.run_js(f'localStorage.setItem("__user_info",`{token}`)')
cookies_set = ""
cookies_set += f'document.cookie=`__user_token.v3={token}; path=/;domain=i.shengcaiyoushu.com;`;'
page.run_js(cookies_set)反检测
在 Selenium、Playwright 、Playwright 的使用中,我们讲到了自动化工具容易被网站检测,也提供了一些绕过检测的方案。这里我们介绍一下 DrissionPage 的反检测方案。
以 https://bot.sannysoft.com 为例,我们分别测试正常模式与无头模式下的检测结果:
- 正常模式:

- 无头模式:
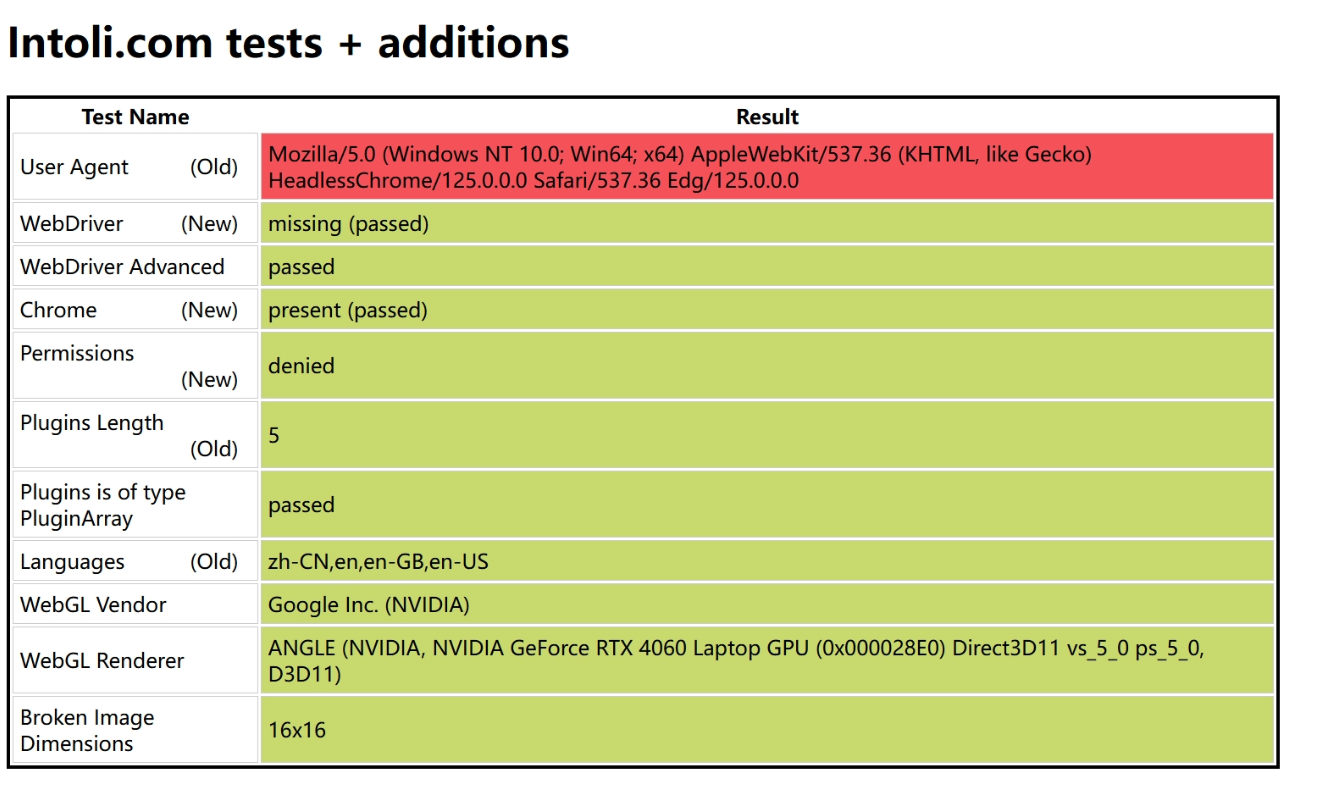
可以发现,我们没有做任何反检测的操作,都不会被检测到,就连使用无头模式也只有 userAgent 有问题,不过我们 co.set_user_agent() 设置一下就可以了,虽然这些只是最基本的检测机制,但也够用了。
总结
DrissionPage 语法简洁,使用方便,底层基于 CDP 协议,拥有较强的反检测机制,目前不需要做任何反检测的操作就可以绕过国内外绝大多数的网站自动化检测,包含但不限于 (xx 验证码、某数、5s)。 还有很多强大的功能这里没法一一展示,强烈推荐!