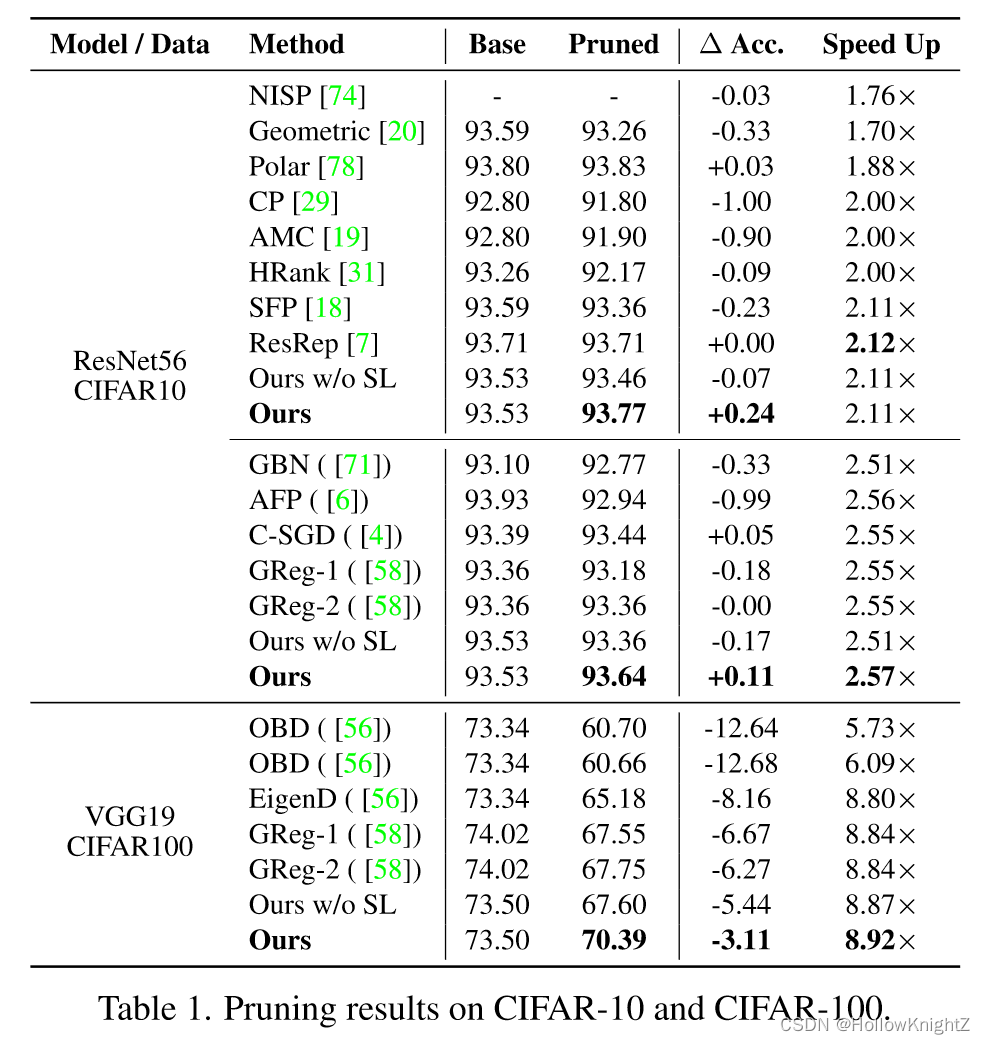
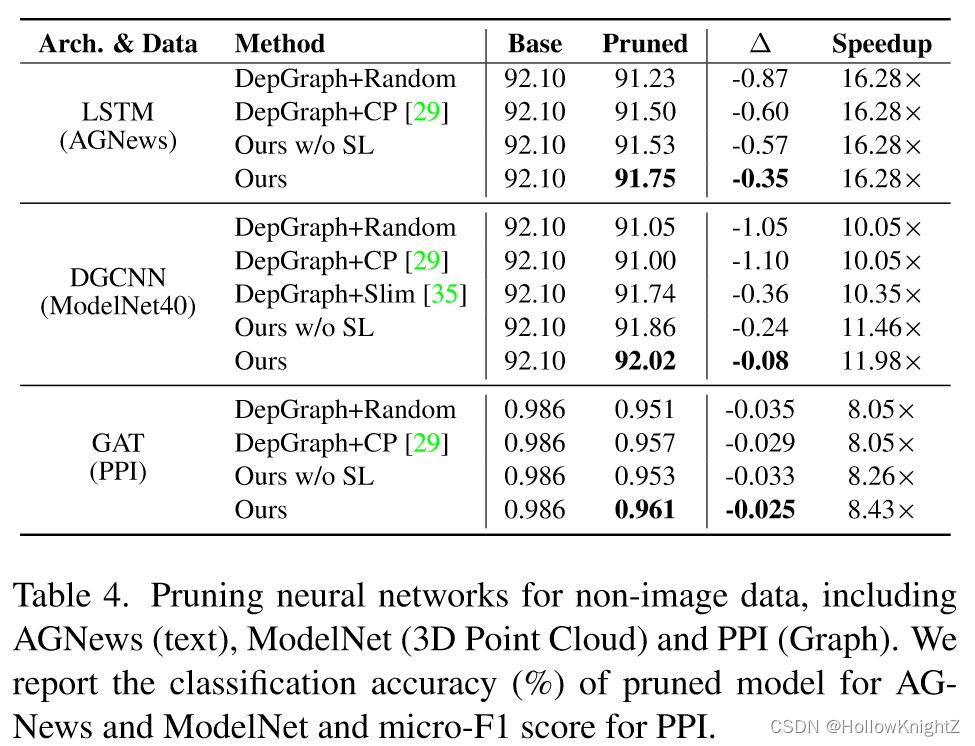
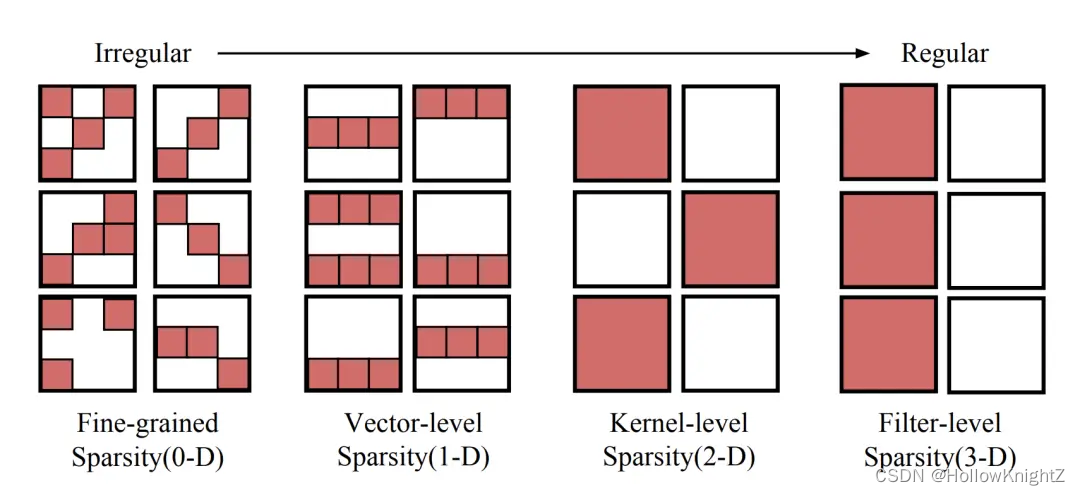
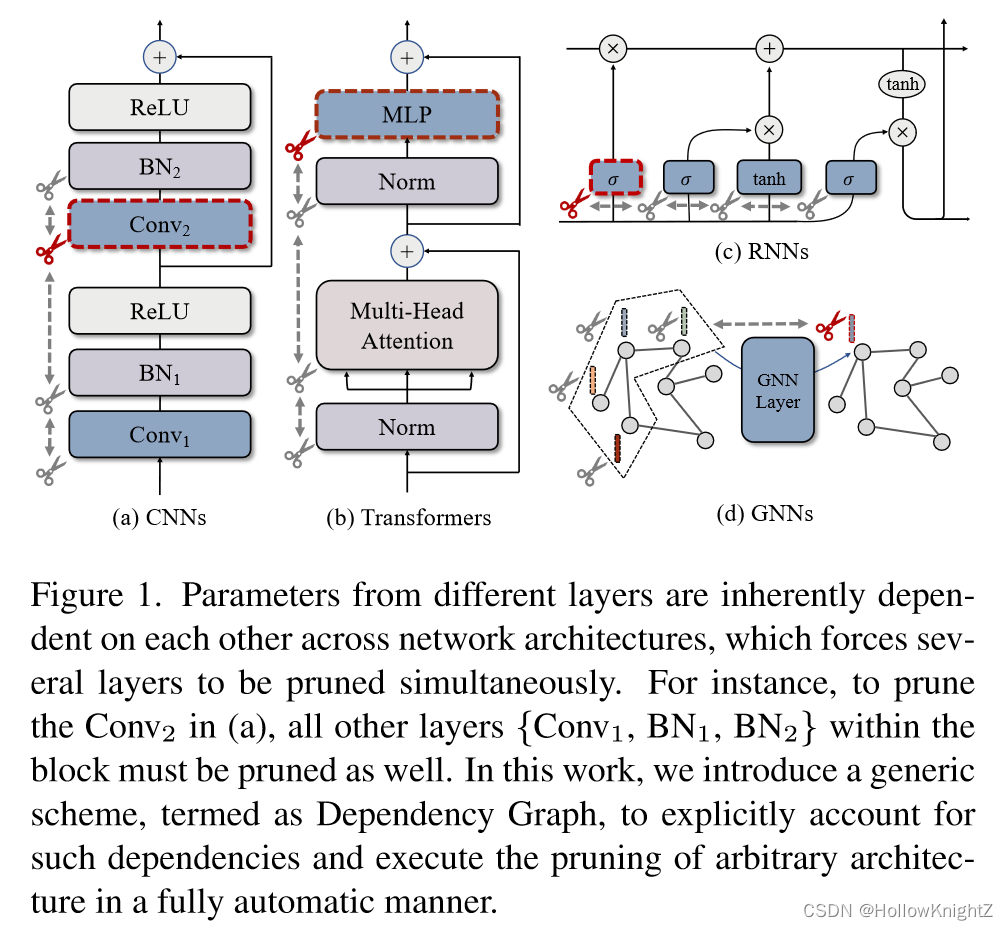
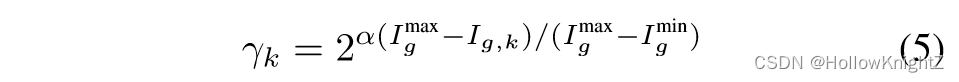在本文中,作者为任意结构化剪枝寻求了一个通用方案,其中任意网络架构上的剪枝都是自动执行的。方法的核心是估计依赖图(Dependency Graph, DepGraph),它显式地建模了神经网络中成对层之间的相互依赖关系。引入DepGraph进行结构化剪枝的动机源于观察到,一层的结构化剪枝有效地"触发"了相邻层的剪枝,这进一步导致了类似{ B N 2 ← C o n v 2 → B N 1 → C o n v 1 BN_2←Conv_2→BN_1→Conv_1 BN2←Conv2→BN1→Conv1 }的链式效应,如图1 ( a )所示。
如图2(a)所示,从3个全连接层组成的神经网络开始,分别用二维权重矩阵 w l w_l wl、 w l + 1 w_{l+1} wl+1 和 w l + 2 w_{l+2} wl+2 进行参数化。这种简单的神经网络可以通过去除神经元进行结构修剪。在这种情况下,很容易发现参数之间存在某种依赖关系,记为 w l ⇔ w l + 1 w_l⇔w_{l+1} wl⇔wl+1,这迫使 w l w_l wl 和 w l + 1 w_{l+1} wl+1 同时被剪枝。具体来说,为了修剪连接 w l w_l wl 和 w l + 1 w_{l+1} wl+1 的第 k k k 个神经元, w l k , : w_lk,: wlk,: 和 w l + 1 : , k w_{l+1}:,k wl+1:,k 都将被移除。
为了实现结构化剪枝,首先需要根据层的相关性对层进行分组。目标是找到一个分组矩阵 G ∈ R L × L G∈R^{L×L} G∈RL×L,其中L表示待剪枝网络的层数, G i j = 1 G_{ij}=1 Gij=1 表示第 i i i 层和第 j j j 层之间存在依赖关系。为了方便起见,令 D i a g ( G ) = 1 1 × L Diag(G) = 1^{1×L} Diag(G)=11×L以实现自依赖。利用分组矩阵,可以很直观地找到相关性到第 i i i 层的所有耦合层,记为 g ( i ) g(i) g(i):
然而,由于现代深度网络可能由数以千计的具有复杂连接的层组成,从而产生了一个庞大而复杂的分组矩阵G。这个矩阵中, G i j G_{ij} Gij 不仅由第 i i i 层和第 j j j 层决定,还受到他们之间的中间层的影响。因此这种非局部和隐式的关系在大多数情况下不能用简单地规则来处理。为了克服这一挑战,作者不直接估计分组矩阵G,而是提出了一种等价但易于估计的依赖建模方法,即依赖图(Dependency graph)。从依赖图中高效的导出G。
4.2 依赖图
首先考虑一个群 g = { w 1 , w 2 , w 3 } g=\{w_1, w_2, w_3\} g={w1,w2,w3},它具有依赖关系 w 1 ⇔ w 2 , w 2 ⇔ w 3 , w 1 ⇔ w 3 w_1⇔w_2, w_2⇔w_3,w_1⇔w_3 w1⇔w2,w2⇔w3,w1⇔w3。在仔细观察这种依赖关系建模后,可以发现存在一些冗余。哟如,从 w 1 ⇔ w 2 , w 2 ⇔ w 3 w_1⇔w_2, w_2⇔w_3 w1⇔w2,w2⇔w3可以通过递归过程导出依赖关系 w 1 ⇔ w 3 w_1⇔w_3 w1⇔w3。首先以 w 1 w_1 w1 为起点,考察它对其它层的依赖性,例如 w 1 ⇔ w 2 w_1⇔w_2 w1⇔w2。然后, w 2 w_2 w2 为递归扩展依赖关系提供了新的起点,依赖关系触发 w 2 ⇔ w 3 w_2⇔w_3 w2⇔w3。这个递归过程最终以一个传递关系 w 1 ⇔ w 2 ⇔ w 3 w_1⇔w_2⇔w_3 w1⇔w2⇔w3结束。在这种情况下,只需要两个依赖关系来描述组g中的关系。同样地,分组矩阵G对于依赖建模也是冗余的,因此可以压缩为具有更少边数的更紧凑的形式,同时保留相同的信息。作者证明了一个新的度量相邻层之间局部相关性的图 D,称为依赖图,可以对分组矩阵G进行有效的约减。依赖图与G的不同之处在于,它只记录了具有直接连接的相邻层之间依赖关系。图D可以看成是图G的可迁约化,它包含了图G相同的顶点但具有尽可能少的边。形式上,构造D使得对所有 G i j = 1 G_{ij}=1 Gij=1 在D中存在一条顶点 i i i 和 j j j 之间的路径。因此 G i j G_{ij} Gij 可以通过检查D中顶点 i i i 和 j j j 之间是否存在一条路径得到。
4.3 网络分解
然而,作者在实际构建依赖图时发现可能存在问题,因为一些基本层(如全连接层)可能由两种不同的剪枝方案,如之前讨论的 w k , : wk,: wk,: 和 w : , k w:,k w:,k ,他们分别压缩了输入和输出的维度。此外,网络还包括跳跃连接等非参数化操作,这也会影响层与层之间的依赖关系。为了解决这些问题,作者将网络 F ( x ; w ) F(x;w) F(x;w) 分解成更精细和更基本的组件,记为 F = { f 1 , f 2 , ... , f L } F=\{f_1, f_2, ..., f_L\} F={f1,f2,...,fL} ,其中每个组件 f f f 指的是参数化的层(如卷积)或非参数化的操作(如残差相加)。取代在层级别上建模关系,作者专注于层的输入和输出之间的依赖关系。具体的,将分量 f i f_i fi 的输入和输出分别记为 f i − f_i^- fi− 和 f i + f_i^+ fi+。对于任意网络,最终的分解可以形式化为 F = f 1 − , f 1 + , ... , f L − , f L + F={f_1^-,f_1^+,...,f_L^-,f_L^+} F=f1−,f1+,...,fL−,fL+。这种表示方法有利于更容易的依赖建模,并且允许对同一层采用不同的剪枝方案。
(1)层间依赖:在连接层 f i − ↔ f j + f_i^-↔f_j^+ fi−↔fj+中一致产生一个依赖 f i − ⇔ f j + f_i^-⇔f_j^+ fi−⇔fj+
(2)层内依赖:如果 f i − f_i^- fi− 和 f i + f_i^+ fi+具有相同的剪枝方案,则存在依赖 f i − ⇔ f i + f_i^-⇔f_i^+ fi−⇔fi+ ,记为 s c h ( f i − ) = s c h ( f i + ) sch(f_i^-)=sch(f_i^+) sch(fi−)=sch(fi+) 。
首先,如果已知网络的拓扑结构,可以很容易地估计层间依赖。对于 f i − ↔ f j + f_i^-↔f_j^+ fi−↔fj+ 的连接层,由于 f i − f_i^- fi− 和 f j + f_j+ fj+ 对应网络相同的中间特征,因此依赖关系是始终存在。
其次,层内依赖要求对单层的输入和和输出同时进行剪枝,许多网络层满足这个条件,例如BN层,其输入和输出共享相同的剪枝方案,记作 s c h ( f i − ) = s c h ( f i + ) sch(f_i^-)=sch(f_i^+) sch(fi−)=sch(fi+) ,将同时进行剪枝,如图3所示。相反,卷积等层对其输入和输出具有不同的剪枝方案,如图3所示, w : , k , : , : ≠ w k , : , : , : w:,k,:,:≠wk,:,:,: w:,k,:,:=wk,:,:,: ,导致 s c h ( f i − ) ≠ s c h ( f i + ) sch(f_i^-)≠sch(f_i^+) sch(fi−)=sch(fi+),在这种情况下,卷积层的输入和输出之间不存在依赖。
给定上述规则,可以形式的建立如下依赖建模:
其中, ∧ ∧ ∧ 和 ∨ ∨ ∨ 表示逻辑与和或, 1 1 1 是一个条件成立则返回True的指示器函数。第一项考察由网络连接引起的层间依赖,而第二项考察由层输入和输出之间的共享剪枝方案引入的层内依赖。值得注意的是,DepGraph 是一个对称矩阵,即 D ( f i − , f j + ) = D ( f j + , f i − ) D(f_i^-,f_j^+)=D(f_j^+,f_i^-) D(fi−,fj+)=D(fj+,fi−)。因此可以检查所有的输入输出对来估计依赖图。图3中可视化了具有残差连接的CNN块的依赖图。
算法1和算法2总结了依赖建模和分组的算法。
4.4 组级剪枝
评估分组参数的重要性对剪枝提出了重大挑战,因为它涉及了多个耦合层。这里,作者利用一个简单的基于范数的准则来建立一个实用的组级剪枝方法。给定一个参数组 g = { w 1 , w 2 , ... w ∣ g ∣ } g=\{w_1,w_2,...w_{|g|}\} g={w1,w2,...w∣g∣},现有的L2范数重要性准则 I ( w ) = ∣ ∣ w ∣ ∣ 2 I(w)=||w||2 I(w)=∣∣w∣∣2可以对每个 w ∈ g w∈g w∈g 产生独立的评分。估计群体重要性的一个自然方法是计算一个综合得分 I ( g ) = ∑ w ∈ g I ( w ) I(g)=\sum{w∈g}I(w) I(g)=∑w∈gI(w) ,不幸的是,不同层独立评估的重要性得分很可能是不可加的,因为分布和量级的差异而因此没有意义。为了使这种简单的聚合方式适用于重要性估计,作者提出了一种稀疏训练方法来稀疏化组级别的参数,如图4(c)所示,以便那些被零化的组可以安全的从网络中移除。
具体来所,对于每一个具有 K K K 个可剪枝维度的参数 w w w,作者引入了一个简单的用于稀疏训练的正则化项,定义为:
其中, I g , k = ∑ w ∈ g ∣ ∣ w k ∣ ∣ 2 2 I_{g,k}=\sum_{w∈g}||wk||_2^2 Ig,k=∑w∈g∣∣wk∣∣22 表示 第 k k k 个可剪枝维度的重要性, γ k \gamma_k γk 指的是应用于这些参数的缩放强度。作者使用一个可控的指数策略来确定 γ k \gamma_k γk 如下:
其中,收缩强度 α k \alpha_k αk 采用归一化分数来控制,其变化范围为 2 0 , 2 α 2\^0,2\^\\alpha20,2α。在实验中 α = 4 \alpha=4 α=4。在稀疏训练之后,作者进一步使用了简单的相对得分 I ^ g , k = N ⋅ I g , k / ∑ { T o p N ( I g ) } \hat{I}{g,k}=N·I{g,k}/\sum\{TopN(I_g)\} I^g,k=N⋅Ig,k/∑{TopN(Ig)},用于识别和去除不重要的参数。
这里正则化的目的就是为了让成对的参数重要性都趋向于0。
稀疏训练过程如下:
复制代码
for epoch in range(epochs):
model.train()
pruner.update_regularizer() # <== initialize regularizer
for i, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
out = model(data)
loss = F.cross_entropy(out, target)
loss.backward() # after loss.backward()
pruner.regularize(model) # <== for sparse training
optimizer.step() # before optimizer.step()


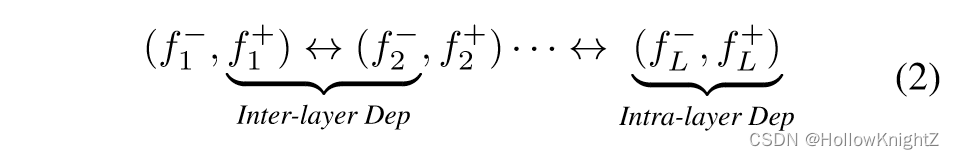 #pic_center
#pic_center