本文将帮助大家实现 RAG (使用 LangChain 和 PostgreSQL )以提高 LLM 输出的准确性和相关性。
得益于强大的机器学习模型(特别是由托管平台/服务通过 API 调用公开的大型语言模型,如 Claude 的 LLama 2等),生成式 AI 开发已经变得普惠化了。这使开发人员免于考虑基础设施问题,从而可以专注于核心业务问题。这也意味着开发人员可以自由选择最适合其解决方案的编程语言。Python 通常是 AI/ML 解决方案的首选语言,但在这一领域有更大的灵活性。
在本文中,您将看到如何利用 Go 编程语言来使用向量数据库和诸如 langchaingo 等技术实现检索增强生成(RAG) 。如果您是想学习如何构建生成式 AI 应用程序的 Go 开发人员,那您就来对地方了!
如果您正在寻找使用 Go 进行 AI/ML 的入门内容,欢迎查阅我在这一领域的前期博客和开源项目。
首先,让我们在深入本文实践部分之前退后一步,了解一些背景。
LLM 的局限性
大型语言模型(LLM)和其他基础模型经过了大量数据的训练,使它们能够在许多自然语言处理(NLP)任务中表现良好。但最重要的限制之一是大多数基础模型和 LLM 使用的是静态数据集,通常具有特定的知识截止时间(例如 2022 年 1 月) 。
知识截止日期
例如,如果您询问了截止日期后发生的事件,它要么无法回答(这是可以的),要么更糟糕的是,自信地给出了错误的回应------通常被称为幻觉。
幻觉
我们需要考虑到 LLM 只是根据它们训练的数据作出回应的事实------这限制了它们准确回答专业主题或专有主题问题的能力。例如,如果我提出了一个关于特定亚马逊云科技服务的问题, LLM 可能(也可能不)能给出准确的回应。如果 LLM 能够使用亚马逊云科技服务的官方文档作为参考,那不是很好吗?
RAG (检索增强生成)有助于缓解这些问题
它通过在响应生成过程中动态检索外部信息来增强 LLM ,从而扩展了模型的知识库超出其原始训练数据。基于 RAG 的解决方案包括一个向量存储,可以对其进行索引和查询以检索最新和相关的信息,从而扩展 LLM 的知识超出其训练截止日期。当需要生成响应时,配备了 RAG 的 LLM 首先会查询向量存储以找到与查询相关的最新信息。这确保了模型的输出不仅基于其现有知识,还增强了最新信息,从而提高了其响应的准确性和相关性。
但 RAG 并非唯一的方式
尽管本文仅关注于 RAG ,但还有其他解决此问题的方式,每种方式都有其优缺点:
- 任务特定调优:在特定任务或数据集上微调大型语言模型,以提高它们在这些领域的性能。
- 提示工程:仔细设计输入提示以引导语言模型产生期望的输出,无需进行重大架构更改。
- 少量样本学习和零样本学习:使语言模型能够在有限或无额外训练数据的情况下适应新任务的技术。
向量存储和嵌入
在上一段中,我多次提到了向量存储。它们只是存储和索引向量嵌入的数据库,向量嵌入是数据(如文本、图像或实体)的数值表示。嵌入使我们能够超越基本搜索,因为它们代表了源数据的语义含义------因此得名"语义搜索",这是一种理解单词的意义和上下文以提高搜索准确性和相关性的技术。向量数据库还可以存储元数据,包括嵌入的原始数据源(例如:Web 文档的 URL )的引用。
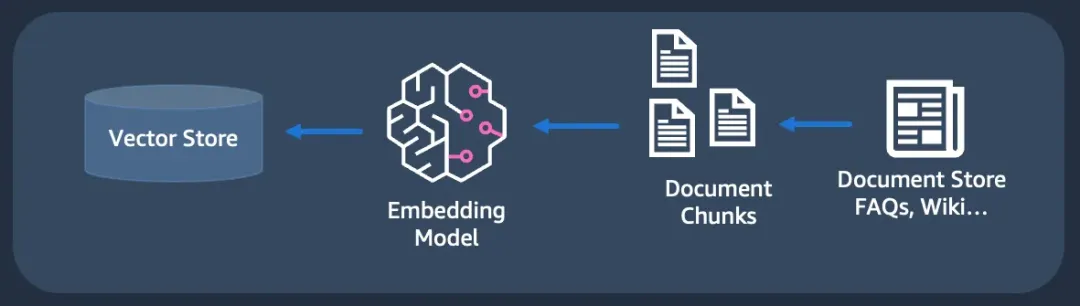
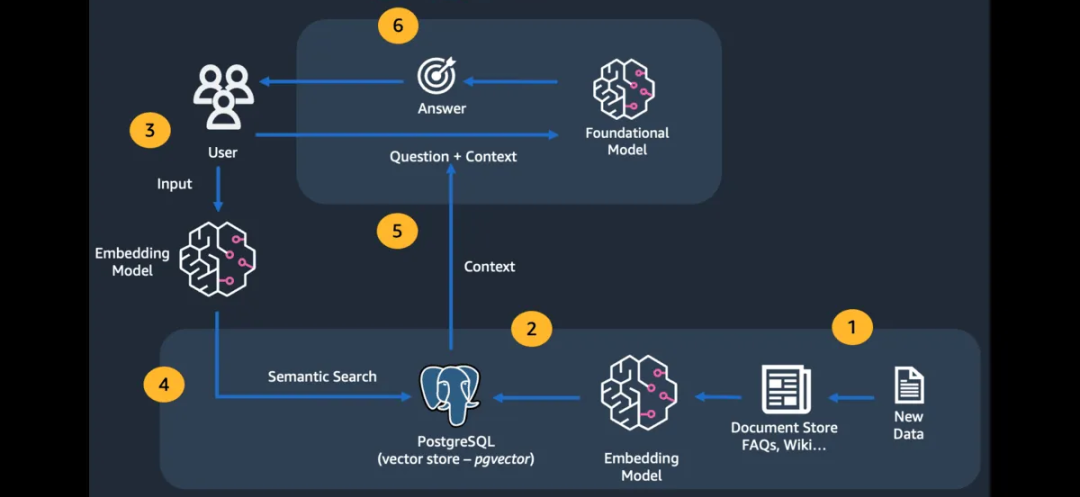
RAG - 数据摄取 由于生成式 AI 技术的爆炸式发展,向量数据库也出现了爆炸式增长。这些包括您可能已经在其他架构部分中使用的成熟 SQL 和 NoSQL 数据库,例如PostgreSQL 、Redis 、MongoDB 和 OpenSearch 。但也有专门为向量存储构建的数据库。其中包括 Pinecone 、Milvus 、Weaviate 等。
好了,让我们回到 RAG ......
典型的 RAG 工作流程是怎样的?
从高层次来看,基于 RAG 的解决方案具有以下工作流程。这些通常作为一个连贯的管道执行:
-
从各种外部来源检索数据 ,如文档、图像、网址、数据库、专有数据源等。这包括分块子步骤,即将大型数据集(例如 100 MB PDF 文件)分割为较小的部分(用于索引)。
-
创建嵌入- 这涉及使用嵌入模型将数据转换为其数值表示。
-
在向量存储中存储/索引嵌入。
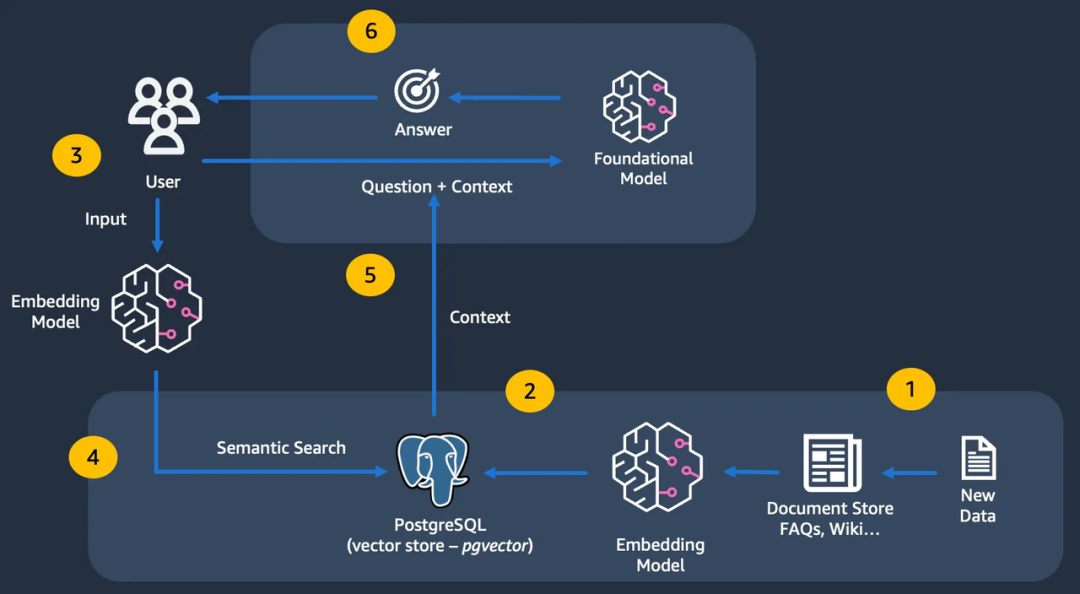
RAG :端到端工作流程
最终,这将作为更大应用程序的一部分进行集成,在该应用程序中,上下文数据(语义搜索结果)将与提示一起提供给 LLM 。
端到端 RAG 工作流程实际运行
工作流程的每个步骤都可以使用不同的组件执行。本博客中使用的组件包括:
- PostgreSQL- 由于 pgvector 扩展,它将用作向量数据库。为简单起见,我们将在 Docker 中运行。
- langchaingo - 这是 langchain 框架的 Go 端口。它为各种组件(包括向量存储)提供插件。我们将使用它从 Web URL 加载数据并将其索引在 PostgreSQL 中。
- 文本和嵌入模型- 我们将使用 Amazon Bedrock Claude and Titan models (用于文本和嵌入)与 langchaingo 。
- 检索和应用集成- langchaingo 向量存储(用于语义搜索)和链(用于 RAG )。
您将了解这些单独部分的工作原理。我们将在后续博客中介绍这种架构的其他变体。
开始之前
请确保您已安装:
- Go、Docker 和 psql (例如,如果您使用的是Mac,可以使用 Homebrew )。
- 从本地机器配置 Amazon Bedrock 访问权限 。
在 Docker 上启动 PostgreSQL
我们可以使用 Docker 镜像!
docker run --name pgvector --rm -it -p 5432:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres ankane/pgvector左右滑动查看完整示意
通过从不同终端登录 PostgreSQL (使用 psql)激活 pgvector 扩展:
# 提示输入密码时输入 postgres psql -h localhost -U postgres -W
CREATE EXTENSION IF NOT EXISTS vector;左右滑动查看完整示意
将数据加载到 PostgreSQL(向量存储)
克隆项目储存库
git clone https://github.com/build-on-aws/rag-golang-postgresql-langchain cd rag-golang-postgresql-langchain左右滑动查看完整示意
在这一步骤中,我假设您的本地机器已配置好可以使用Amazon Bedrock 。
我们将要做的第一件事是将数据加载到 PostgreSQL中。
请随意使用您自己的!确保在后续步骤中相应地更改搜索查询。

export PG_HOST=localhost
export PG_USER=postgres
export PG_PASSWORD=postgres
export PG_DB=postgres
go run *.go -action=load -source=https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-general-nosql-design.html左右滑动查看完整示意
您应该会看到以下输出:
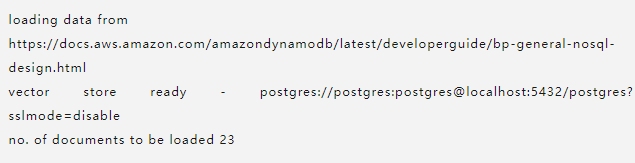
给它一些时间。最后,如果一切顺利,您应该会看到"数据已成功加载到向量存储中"这样的输出。
要验证,请返回 psql 终端并检查表:
应该会看到几个表 - langchain_pg_collection 和 langchain_pg_embedding 。这些是由 langchaingo 创建的,因为我们没有明确指定它们(这没关系,对于入门来说很方便!)。langchain_pg_collection 包含集合名称,而 langchain_pg_embedding 存储实际的嵌入。
| Schema | Name | Type | Owner |
|---|---|---|---|
| public | langchain_pg_collection | table | postgres |
| public | langchain_pg_embedding | table | postgres |
您可以检查表格内容:
select * from langchain_pg_collection; select count(*) from langchain_pg_embedding;
select collection_id, document, uuid from langchain_pg_embedding LIMIT 1;左右滑动查看完整示意
您将在 langchain_pg_embedding 表中看到 23 行,因为那是我们的网页源被分割成的 langchain 文档数(请参阅上面加载数据时的应用程序日志)。
快速了解其工作原理...
数据加载实现在 load.go 中,但让我们看看如何访问向量存储实例(在 common.go 中):
brc := bedrockruntime.NewFromConfig(cfg)
embeddingModel, err := bedrock.NewBedrock(bedrock.WithClient(brc), bedrock.WithModel(bedrock.ModelTitanEmbedG1))
//...
store, err = pgvector.New(
context.Background(),
pgvector.WithConnectionURL(pgConnURL),
pgvector.WithEmbedder(embeddingModel),
)左右滑动查看完整示意
- pgvector.WithConnectionURL 提供 PostgreSQL实例的连接信息
- pgvector.WithEmbedder 是有趣的部分,因为这是我们可以插入所选嵌入模型的地方。langchaingo 支持 Amazon Bedrock 嵌入。在这种情况下,我使用了Amazon Bedrock Titan 嵌入模型。
回到 load.go 中的加载过程。我们首先使用 langchaingo 内置的 HTML 加载器获取数据,形式为schema.Document 的切片(getDocs 函数)。
docs, err := documentloaders.NewHTML(resp.Body).LoadAndSplit(context.Background(), textsplitter.NewRecursiveCharacter())左右滑动查看完整示意
然后,我们将其加载到 PostgreSQL 中。我们不需要自己编写所有代码,可以使用 langchaingo 向量存储抽象并使用高级函数 AddDocuments :
_, err = store.AddDocuments(context.Background(), docs)左右滑动查看完整示意
太好了。我们已经建立了一个简单的管道来获取和摄取数据到 PostgreSQL 。让我们加以利用吧!
语义搜索执行
让我们提出一个问题。我将采用"我可以使用哪些工具来设计 DynamoDB 数据模型?"
我您可以根据您的场景进行调整。
export PG_HOST=localhost
export PG_USER=postgres
export PG_PASSWORD=postgres
export PG_DB=postgres
go run *.go -action=semantic_search -query="what tools can I use to design dynamodb data models?" -maxResults=3左右滑动查看完整示意
您应该会看到类似的输出 - 请注意,我们选择最多输出三个结果(您可以更改):
vector store ready
vector store ready
similarity search results
similarity search info - can build new data models from, or design
models based on, existing data models that satisfyyour application's
data access patterns. You can also import and export the designed
datamodel at the end of the process. For more information, see
Building data models with NoSQL Workbenchsimilarity search score -
0.3141409
similarity search info - NoSQL Workbench for DynamoDB is a cross-platform, client-side GUIapplication that you can use for modern
database development and operations. It's availablefor Windows, macOS,
and Linux. NoSQL Workbench is a visual development tool that
providesdata modeling, data visualization, sample data generation, and
query development features tohelp you design, create, query, and
manage DynamoDB tables. With NoSQL Workbench for DynamoDB,
yousimilarity search score - 0.3186116
similarity search info - key-value pairs or document storage. When you switch from a relational database managementsystem to a NoSQL
database system like DynamoDB, it's important to understand the key
differencesand specific design approaches.
TopicsDifferences between relational datadesign and NoSQLTwo key
concepts for NoSQL designApproaching NoSQL designNoSQL Workbench for
DynamoDBDifferences between relational datadesign and NoSQLsimilarity
search score - 0.3275382
现在您在这里看到的是前三个结果(感谢-maxResults=3) 。
请注意,这不是对我们问题的回答。这些是来自向量存储的语义上接近查询的结果 - 这里的关键词是语义。
多亏了 langchaingo 中的向量存储抽象,我们能够轻松地将源数据摄入到PostgreSQL中,并使用SimilaritySearch 函数获取与我们查询相对应的前 N 个结果(参见 query.go 中的 semanticSearch 函数):
searchResults, err := store.SimilaritySearch(context.Background(), searchQuery, maxResults)请注意, pgvector 在 langchaingo 中的实现使用余弦距离向量运算,但 pgvector 也支持 L2 和内积。
好的,到目前为止我们已经:
- 加载了向量数据
- 执行了语义搜索
这是 RAG (检索增强生成)的基石 - 让我们看看它的实际应用!
智能搜索与 RAG
要执行基于 RAG 的搜索,我们运行与上述相同的命令(几乎相同),只需对动作(rag_search)做一点小改动:
export PG_HOST=localhost
export PG_USER=postgres
export PG_PASSWORD=postgres
export PG_DB=postgres
go run *.go -action=rag_search -query="我可以使用哪些工具来设计DynamoDB数据模型?" -maxResults=3左右滑动查看完整示意
这是我得到的输出(您的情况可能会略有不同):
Based on the context provided, the NoSQL Workbench for DynamoDB is a
tool that can be used to design DynamoDB data models. Some key points
about NoSQL Workbench for DynamoDB:
- It is a cross-platform GUI application available for Windows, macOS, and Linux.
- It provides data modeling capabilities to help design and create DynamoDB tables.
- It allows you to build new data models or design models based on existing data models.
- It provides features like data visualization, sample data generation, and query development to manage DynamoDB tables.
- It helps in understanding the key differences and design approaches when moving from a relational database to a NoSQL database like
DynamoDB.So in summary, NoSQL Workbench for DynamoDB seems to be a useful tool
specifically designed for modeling and working with DynamoDB data
models.
因此,总的来说, NoSQL Workbench for DynamoDB 是专门用于建模和处理 DynamoDB 数据模型的有用工具。
正如您所看到的,结果不仅仅是**"这里是对您查询的前 X个响应"**。相反,它是对该问题的周全阐述。让我们再看看幕后是如何运作的。
与摄入和语义搜索不同,RAG 基于搜索没有直接在 langchaingo 向量存储实现中公开。为此,我们使用langchaingo 链,它负责以下工作:
- 调用语义搜索
- 将语义搜索与提示组合在一起
- 将其发送到大型语言模型( LLM ) ,在本例中就是Amazon Bedrock上的Claude 。
以下是链的样子(参考 query.go 中的 ragSearch 函数):

左右滑动查看完整示意
让我们尝试另一个
这只是一个例子。我提出了一个不同的问题,并将 maxResults 增加到 10 ,这意味着来自向量数据库的前 10 个结果将用于构建答案。
go run *.go -action=rag_search -query="how is NoSQL different from SQL?" -maxResults=10左右滑动查看完整示意
结果(同样,对于您可能会有所不同):
Based on the provided context, there are a few key differences between
NoSQL databases like DynamoDB and relational database management
systems (RDBMS):
- Data Modeling: - In RDBMS, data modeling is focused on flexibility and normalization without worrying much about performance
implications. Query optimization doesn't significantly affect schema
design. - In NoSQL, data modeling is driven by the specific queries
and access patterns required by the application. The data schema is
designed to optimize the most common and important queries for speed
and scalability.- Data Organization: - RDBMS organizes data into tables with rows and columns, allowing flexible querying. - NoSQL databases like DynamoDB
use key-value pairs or document storage, where data is organized in a
way that matches the queried data shape, improving query performance.- Query Patterns: - In RDBMS, data can be queried flexibly, but queries can be relatively expensive and don't scale well for
high-traffic situations. - In NoSQL, data can be queried efficiently
in a limited number of ways defined by the data model, while other
queries may be expensive and slow.- Data Distribution: - NoSQL databases like DynamoDB distribute data across partitions to scale horizontally, and the data keys are
designed to evenly distribute the traffic across partitions, avoiding
hot spots. - The concept of "locality of reference," keeping related
data together, is crucial for improving performance and reducing costs
in NoSQL databases.In summary, NoSQL databases prioritize specific query patterns and
scalability over flexible querying, and the data modeling is tailored
to these requirements, in contrast with RDBMS where data modeling
focuses on normalization and flexibility.
从这里前进到哪里
边做边学是一个好方法。如果您一直跟随并执行了到目前为止的应用程序,那太好了!
我建议您尝试以下操作:
- langchaingo 支持许多不同的模型,包括 Amazon Bedrock 中的模型 (例如 Meta LLama 2、Cohere 等)- 尝试调整模型并查看是否会产生差异?输出是否更好?
- 那么向量数据库呢?我演示了 PostgreSQL ,但 langchaingo 也支持其他数据库(包括 OpenSearch 、Chroma 等)- 尝试切换向量存储并查看搜索结果是否有差异?
- 您可能已经大致了解了,但您也可以尝试不同的嵌入模型。我们使用了 Amazon Titan ,但 langchaingo 也支持许多其他模型,包括:Amazon Bedrock 中的 Cohereembed 模型。
总结
这只是一个简单的示例,旨在让您更好地理解构建基于 RAG 的解决方案中的各个步骤。这些可能会根据实现的不同而略有变化,但高层次的思路保持不变。
我使用了 langchaingo 作为框架。但这并不意味着您一定要使用某个框架。如果您需要在应用程序中进行细粒度控制或框架无法满足您的要求,您也可以移除抽象层并直接调用 LLM 平台的 API 。与大多数生成式 AI 一样,这个领域正在迅速发展,我对 Go 开发人员拥有更多选择来构建生成式 AI 解决方案持乐观态度。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。