基于Python/flask的微博舆情数据分析可视化系统
python爬虫数据分析可视化项目
编程语言:python
涉及技术:flask mysql echarts SnowNlP情感分析 文本分类
系统设计的功能:
①用户注册登录
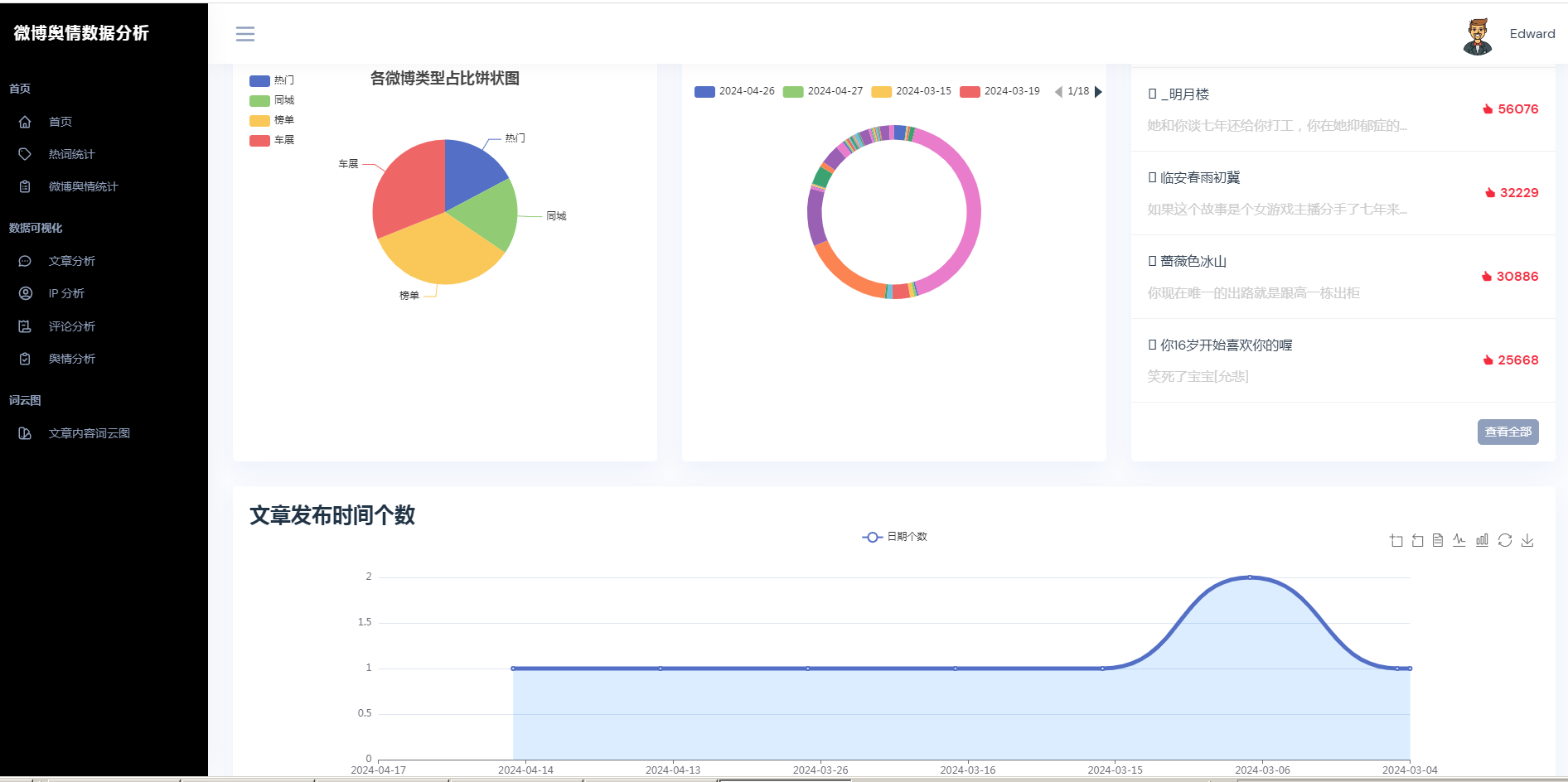
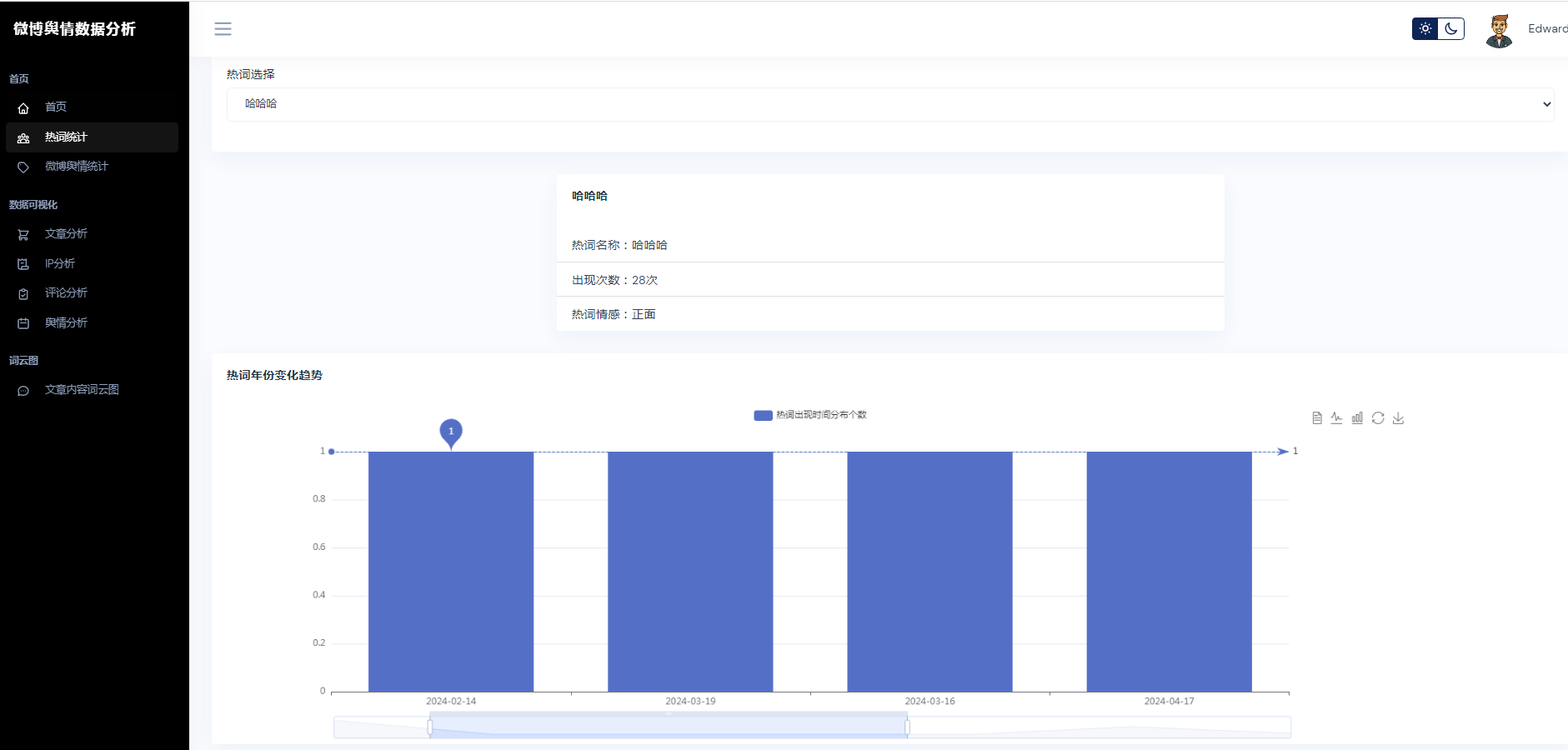
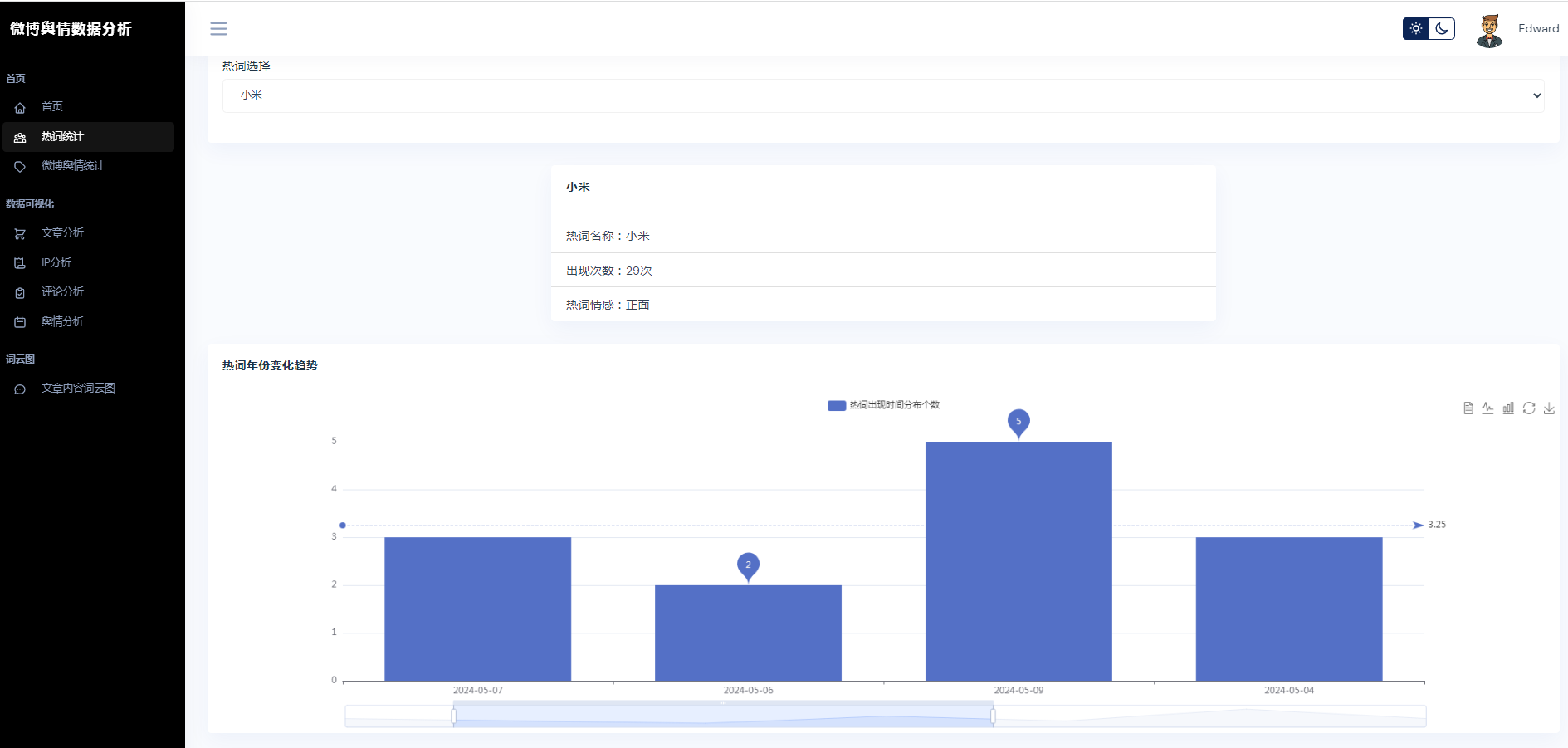
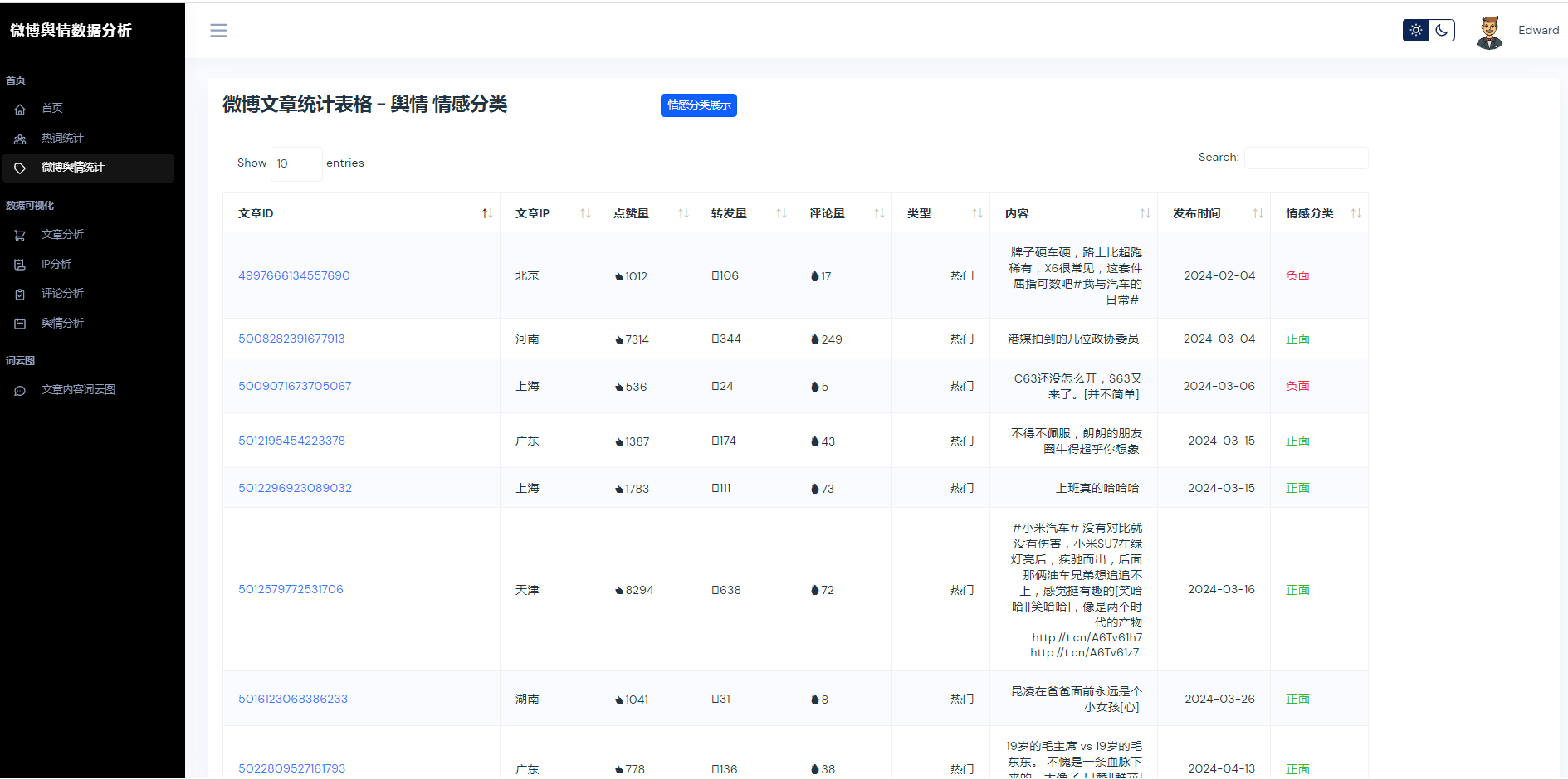
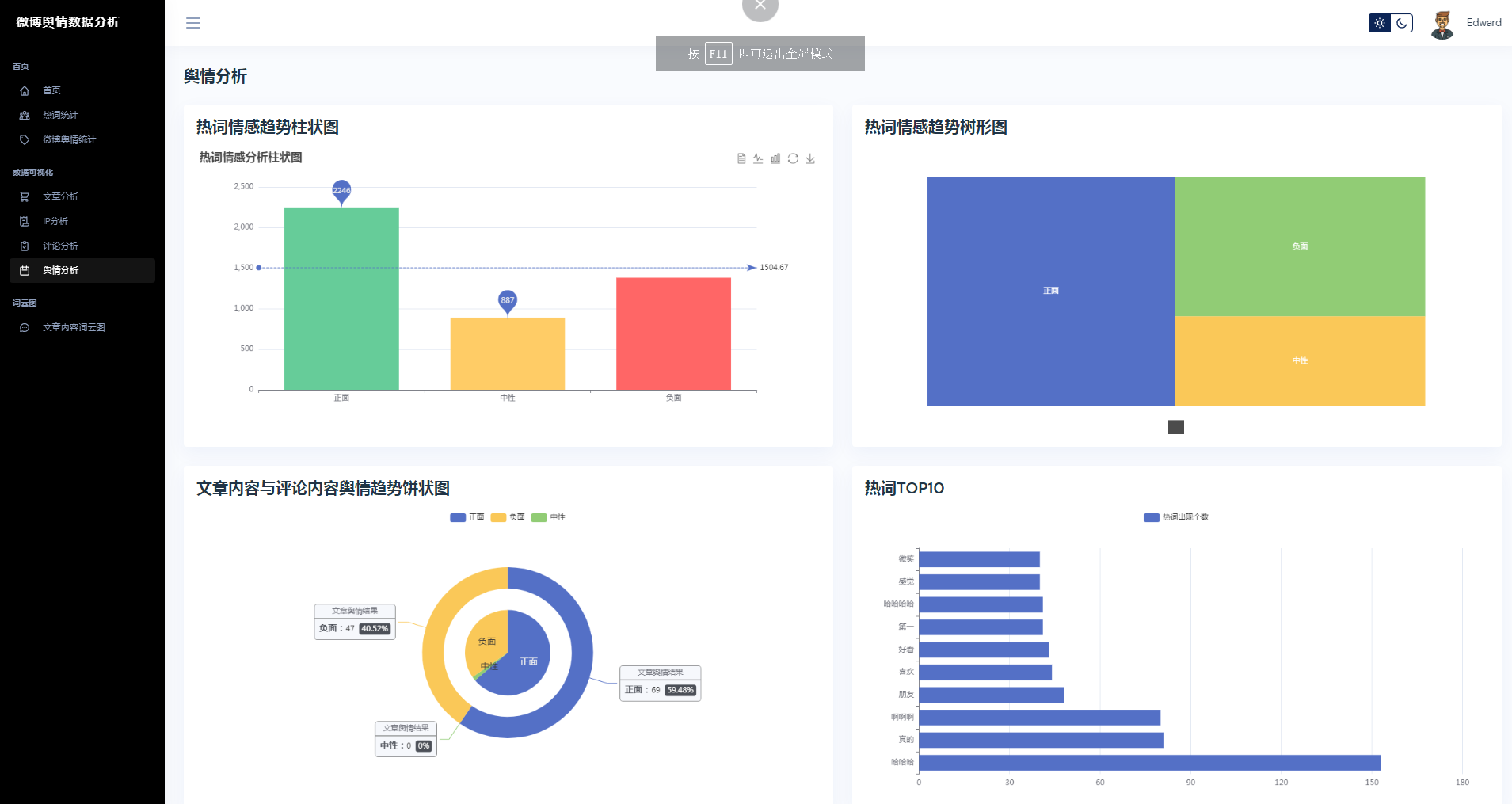
②微博数据描述性统计、热词统计、舆情统计
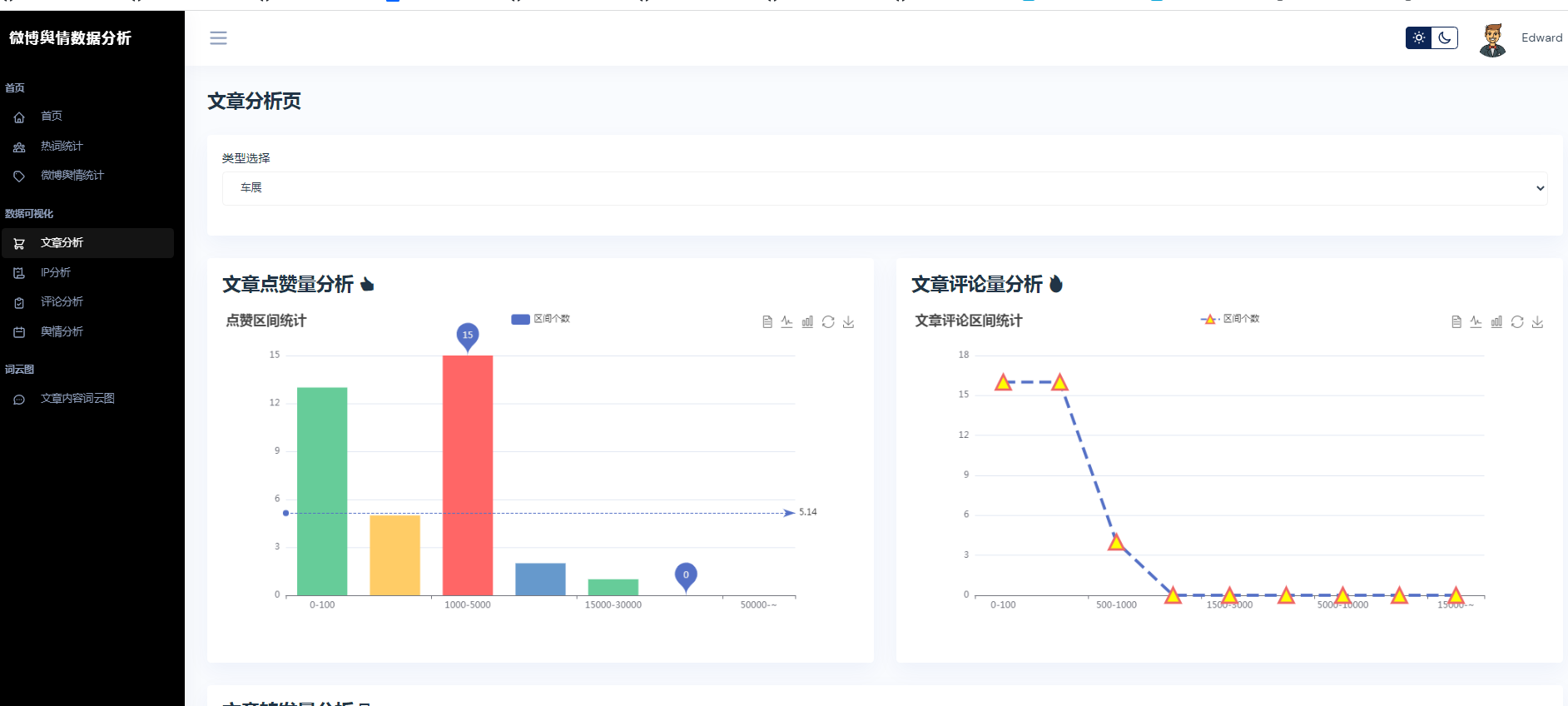
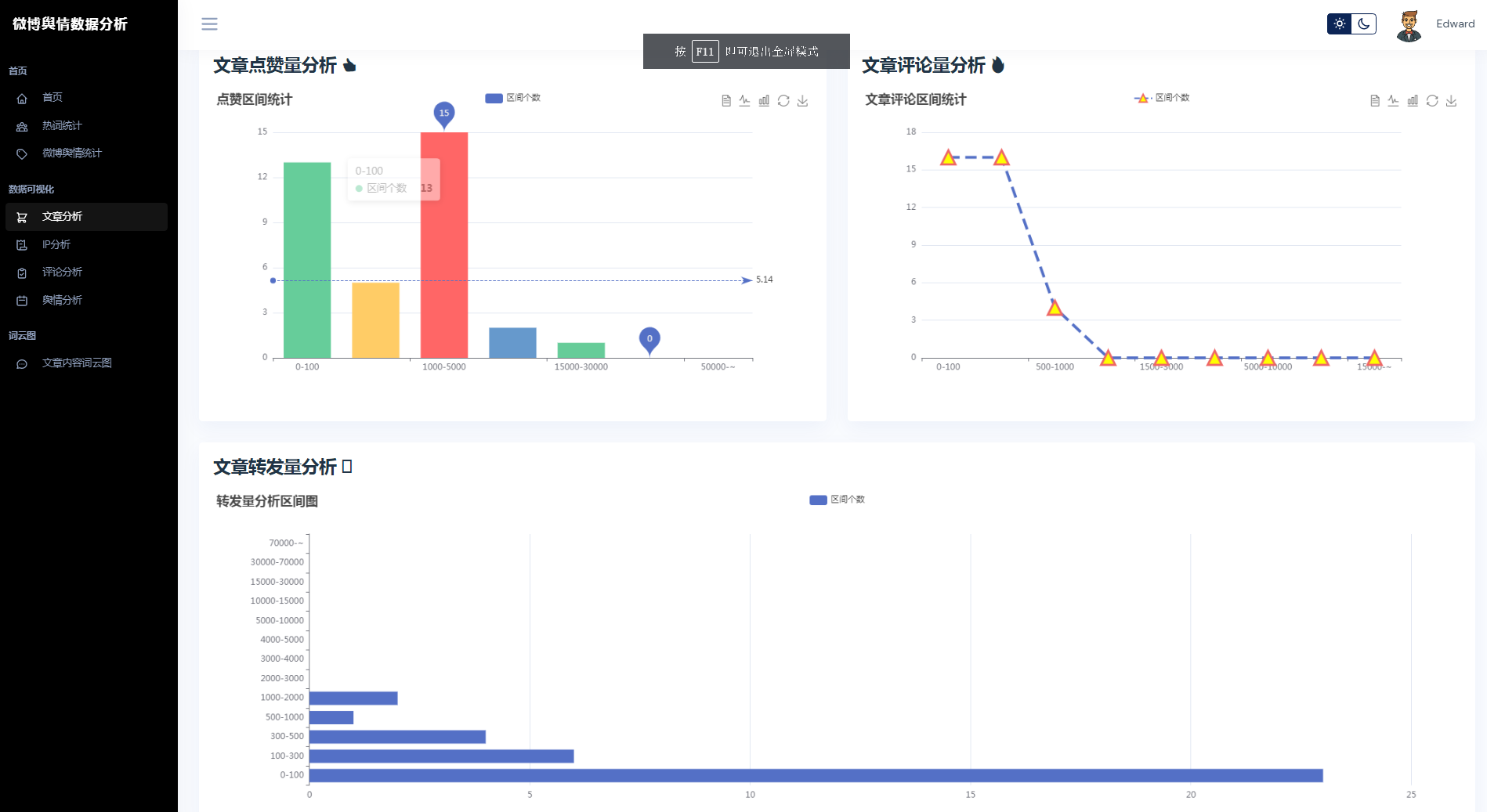
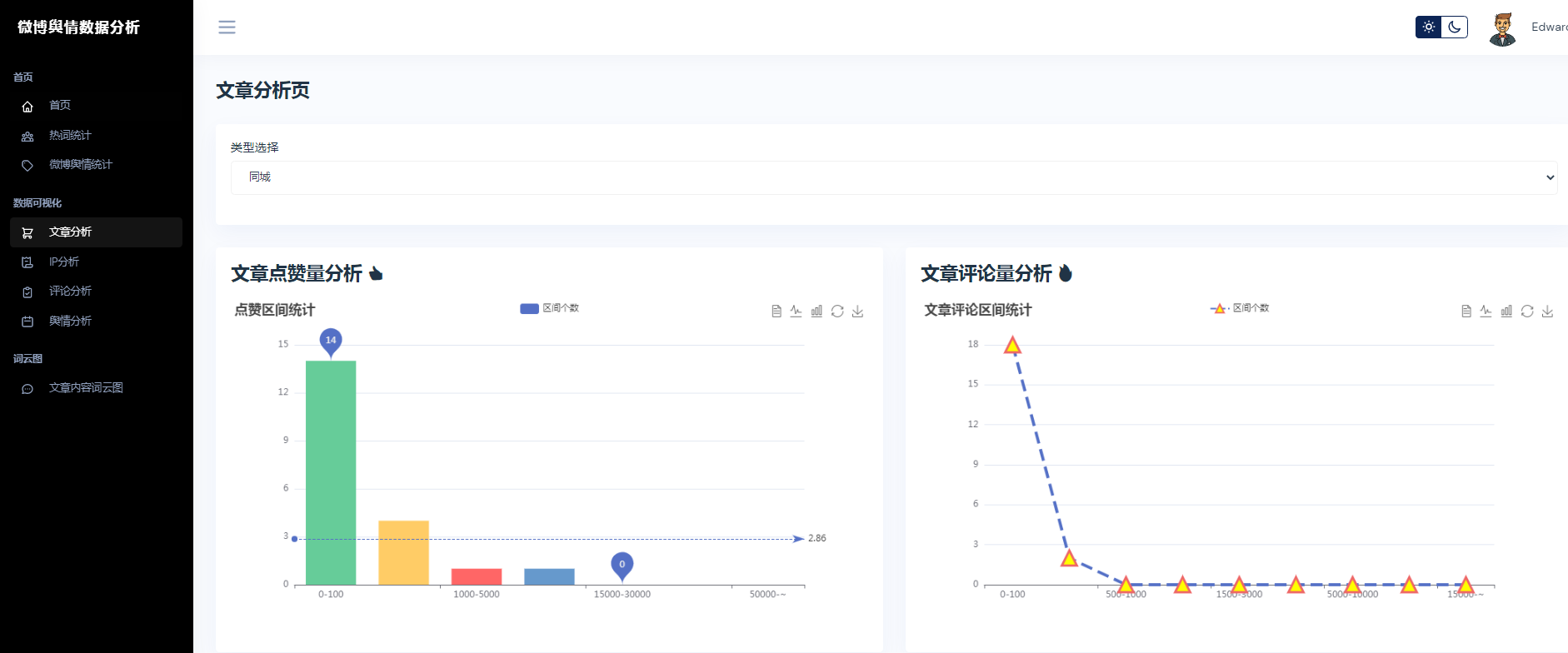
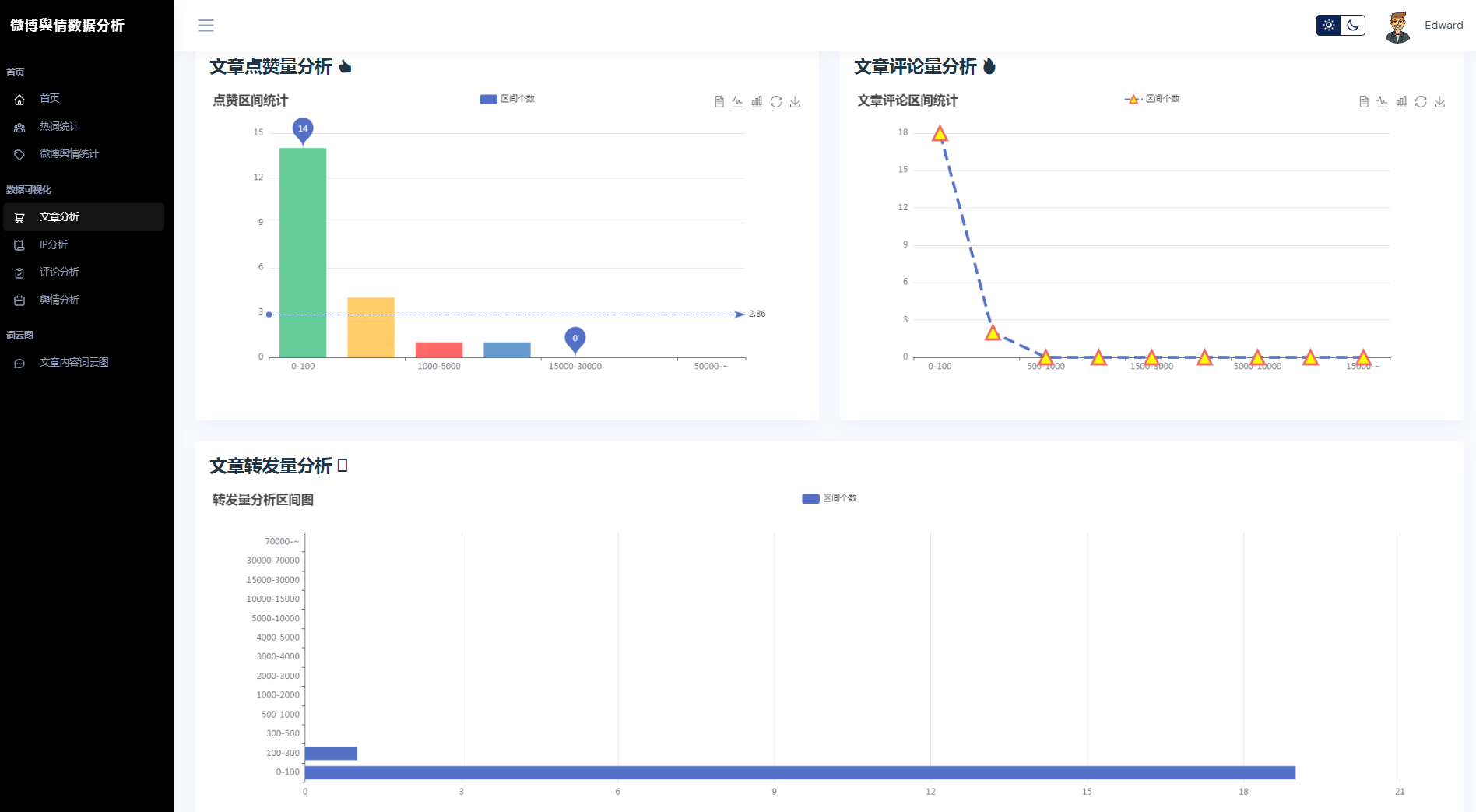
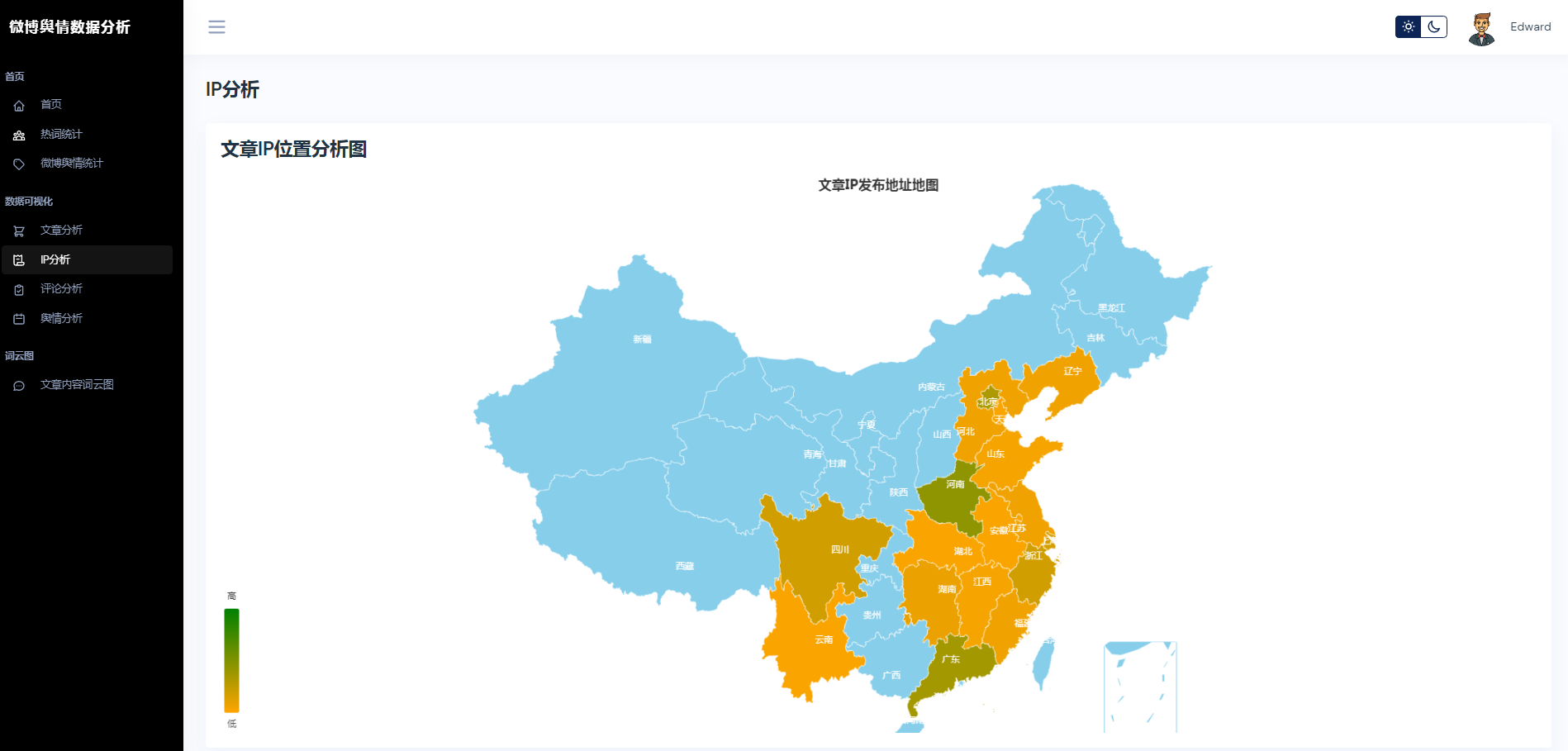
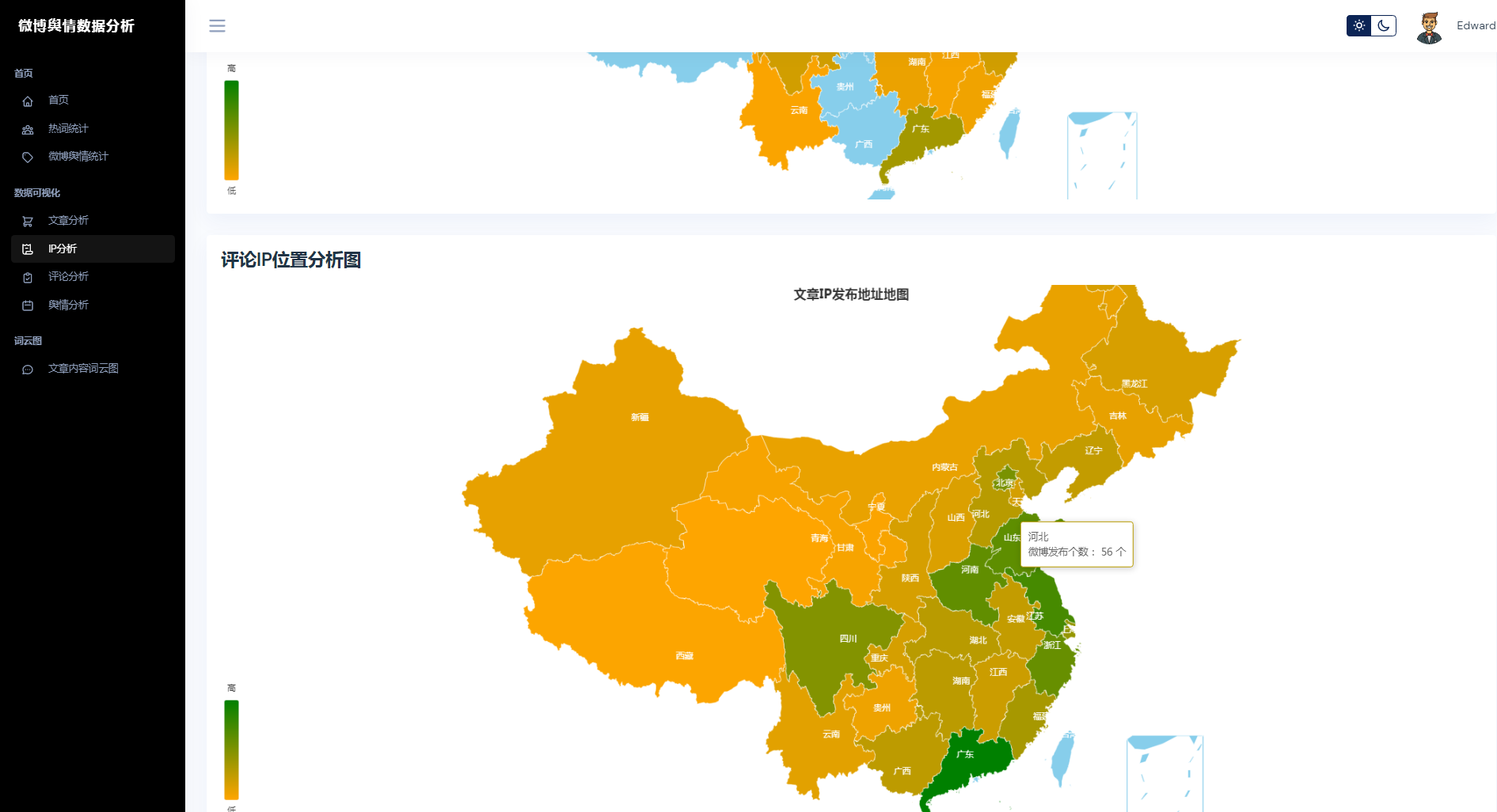
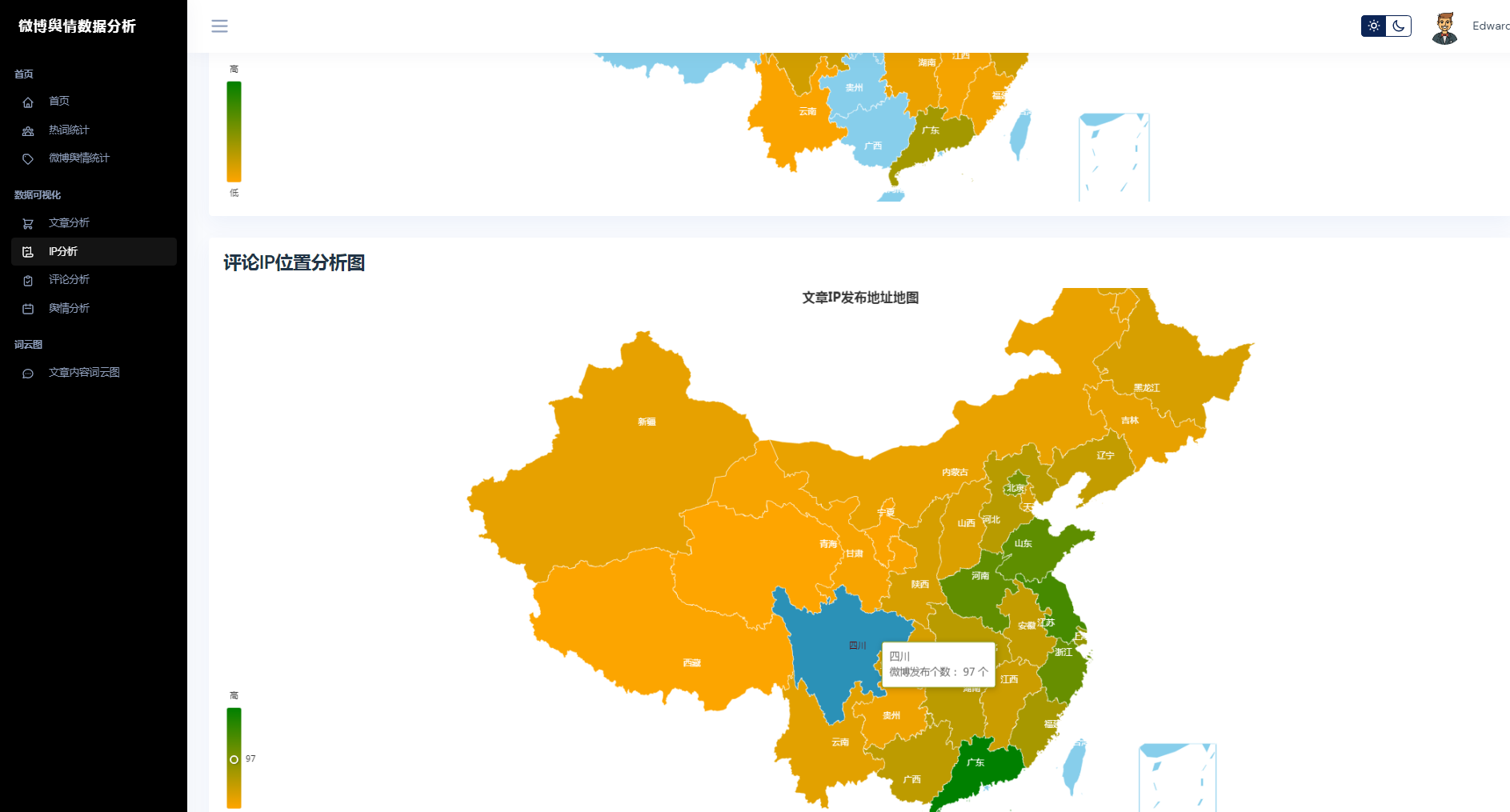
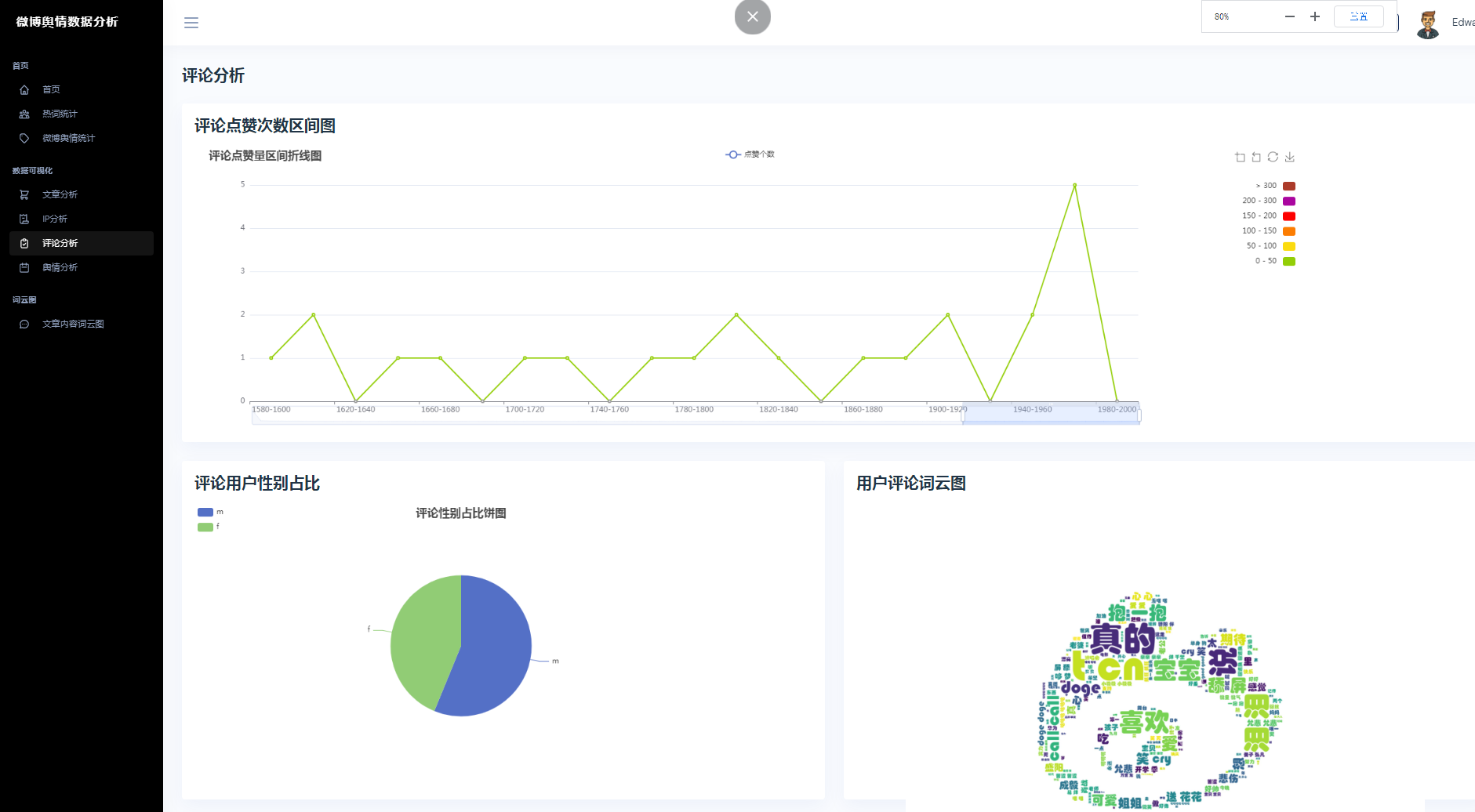
③微博数据分析可视化,文章分析、IP分析、评论分析、舆情分析
④文章内容词云图

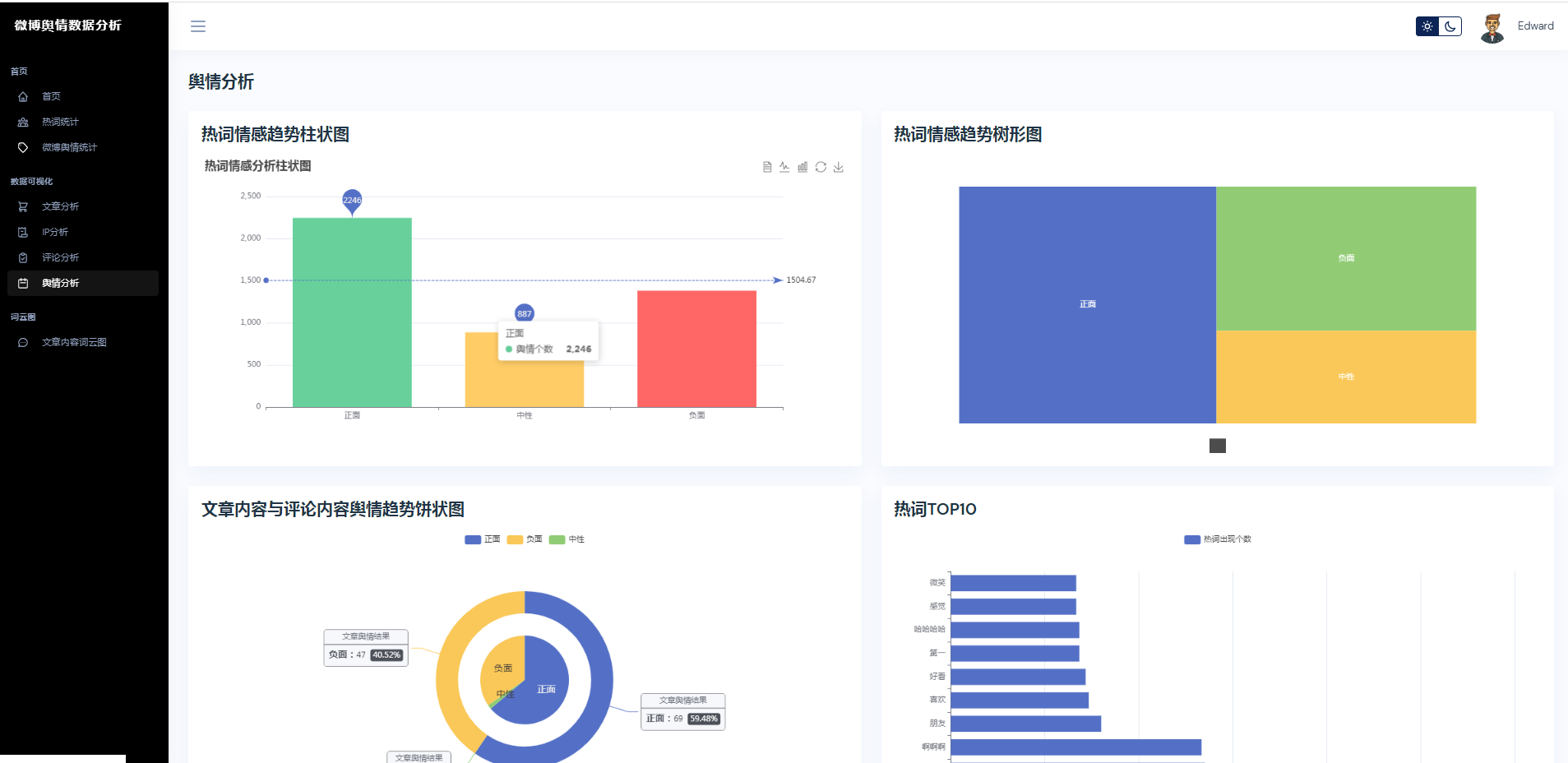
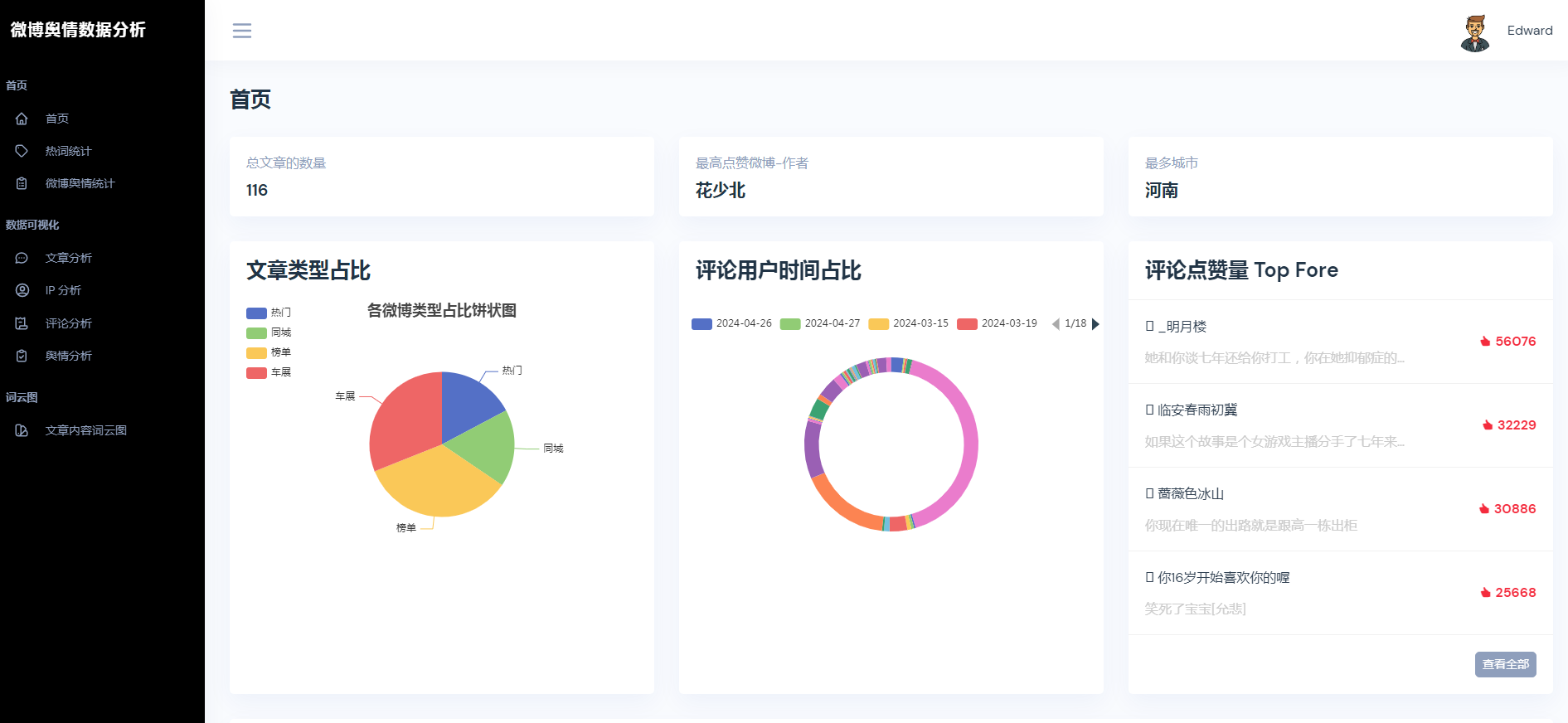



核心算法代码分享如下:
python
from utils.getPublicData import getAllCommentsData
import jieba
import jieba.analyse as analyse
targetTxt = 'cutComments.txt'
# stopWords 停用词
def stopWordList():
stopWords = [line.strip() for line in open('./stopWords.txt',encoding='utf8').readlines()]
return stopWords
def seg_depart(sentence):
sentence_depart = jieba.cut(" ".join([x[4] for x in sentence]).strip())
print(sentence_depart)
stopWords = stopWordList()
outStr = ''
for word in sentence_depart:
if word not in stopWords:
if word != '\t':
outStr += word
return outStr
def writer_comments_cuts():
with open(targetTxt,'a+',encoding='utf-8') as targetFile:
seg = jieba.cut(seg_depart(getAllCommentsData()),cut_all=True)
output = ' '.join(seg)
targetFile.write(output)
targetFile.write('\n')
print('写入成功')
if __name__ == '__main__':
# print(stopWordList())
writer_comments_cuts()