题目:Parameter-Effificient Transfer Learning for NLP
阅读
文章目录
- 0.摘要
- 1.引言
- [2 Adapter tuning for NLP](#2 Adapter tuning for NLP)
- [3 实验](#3 实验)
-
- [3.1 参数/性能平衡](#3.1 参数/性能平衡)
- [3.2 讨论](#3.2 讨论)
- 4.相关工作
0.摘要
克服微调训练不高效的问题,增加一些adapter模块,思想就是固定原始的网络中的参数,针对任务增加一些可以训练的参数,新任务无需重新访问以前的任务,产生高度的参数共享。与完全微调相比,仅仅增加了3.6%的参数,就接近了SOTA的结果。
1.引言
紧凑模型是那些在每个任务中使用少量附加参数来解决许多任务的模型。可以逐步训练可扩展模型来解决新任务,而不会忘记以前的任务。我们的方法在不牺牲性能的情况下产生了这样的模型。
在NLP中最常用的迁移学习技术有两种,分别是feature-based transfer 和 fine-tuning。前一种是将训练好的embedding移植到别的任务中,后一种方法是对已训练好的网络的权重进行复制,然后在下游任务进行调整。已经证明微调比基于特征的迁移效果要更好。

基于Adapter的调优与多任务和持续学习有关。多任务学习也会产生紧凑的模型。然而,多任务学习需要同时访问所有任务,而基于Adapter的调优则不需要。持续学习系统旨在从无穷无尽的任务中学习。这种范式具有挑战性,因为网络在重新训练后会忘记以前的任务。适配器的不同之处在于任务不交互并且共享参数被冻结。这意味着该模型使用少量特定于任务的参数对先前的任务具有完美的记忆。
2 Adapter tuning for NLP
提出了一种在多个下游任务上调整大型文本模型的策略,包含三个属性:
- 保持良好的性能
- 它允许按顺序对任务进行训练,也就是说,它不需要同时访问所有数据集
- 它只为每个任务添加少量额外参数
之所以微调的时候要在神经网络的最顶层添加一个新层,是因为label space和loss space对于上游任务和下游任务是不同的。
**adaper将一些新的层注入到原始的网络,原始网络的权重保持不变,而新的适配器层是随机初始化的。**在标准微调中,新的顶层和原始权重是共同训练的。相反,在 adaptertuning 中,原始网络的参数被冻结,因此可能被许多任务共享。
Adapter模块有两个关键特征:
- 小规模的参数
- 近似一致的初始化。我们还观察到,如果初始化偏离恒等函数太远,模型可能无法训练。
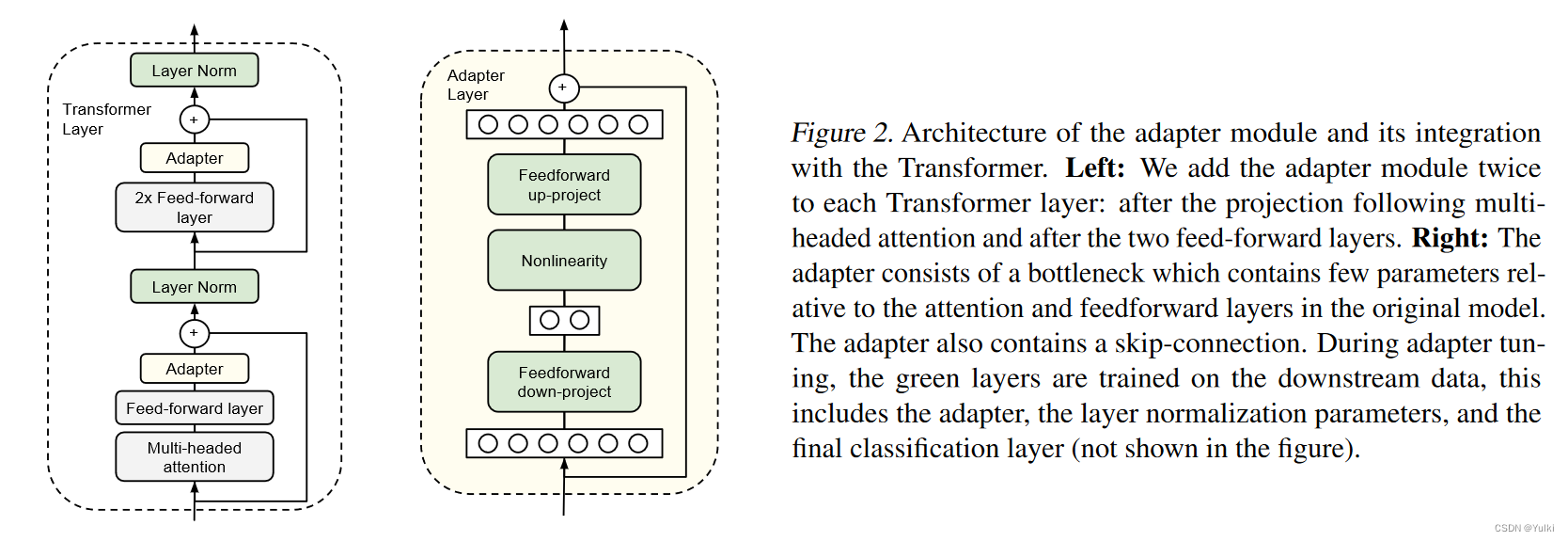
图中绿色的部分是在下游任务中进行训练的,包括layernorm,adapter模块,已经最终的分类头(图中未标出)。
在多头注意力投影层后,在FFN后添加了Adapter模块。
为了限制参数的数量,提出了bottleneck结构。adapter首先将原始的d维特征投影到一个小的维度m,应用一个非线性层,然后在投影回d维度,
对于每个增加的层,增加的参数包括bias时,参数量为2md+d+m。m远小于d
因此对每个任务限制了模型的规模。
bottleneck维度m提供了一种权衡性能与参数效率的简单方法。
🧐适配器模块本身在内部有一个残差连接。使用残差连接,如果投影层的参数被初始化为接近零,则模块被初始化为近似恒等函数
3 实验
训练设置,batch size=32、4块TPU
对于GLUE来说,使用 B e r t l a r g e Bert_{large} Bertlarge:24层,330M参数。
bottleneck维度范围:{8, 64, 256}
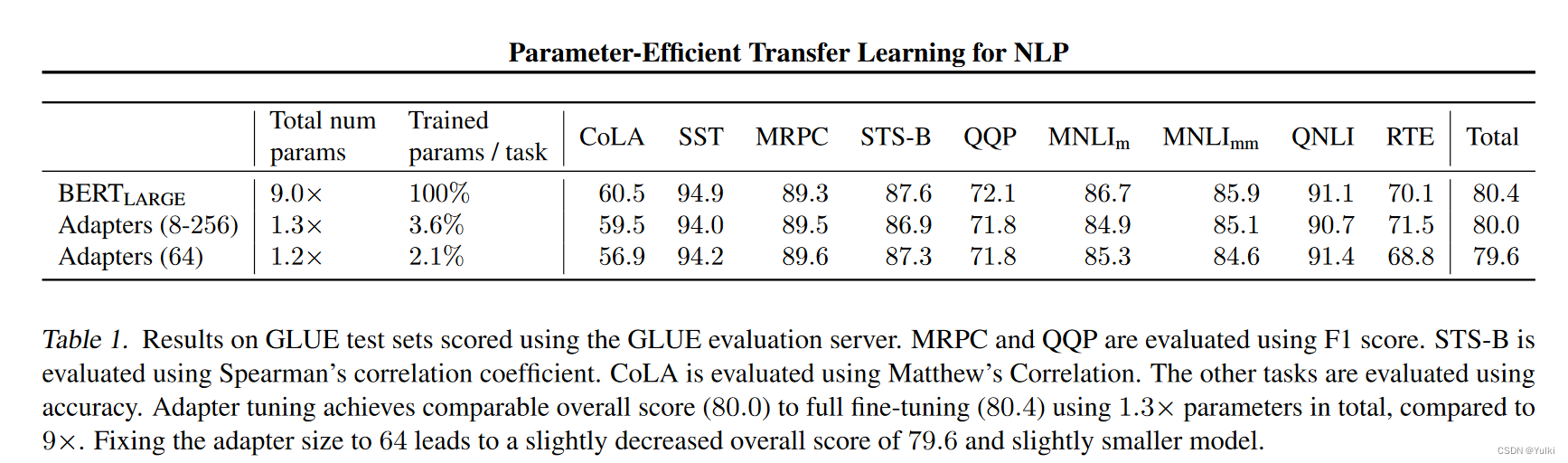
🧐那个Total数值是如何计算出啦的?不是取平均吧,平均的结果是82.02,81.54,81.1
😀那个Total是平均GLUE分数,
3.1 参数/性能平衡
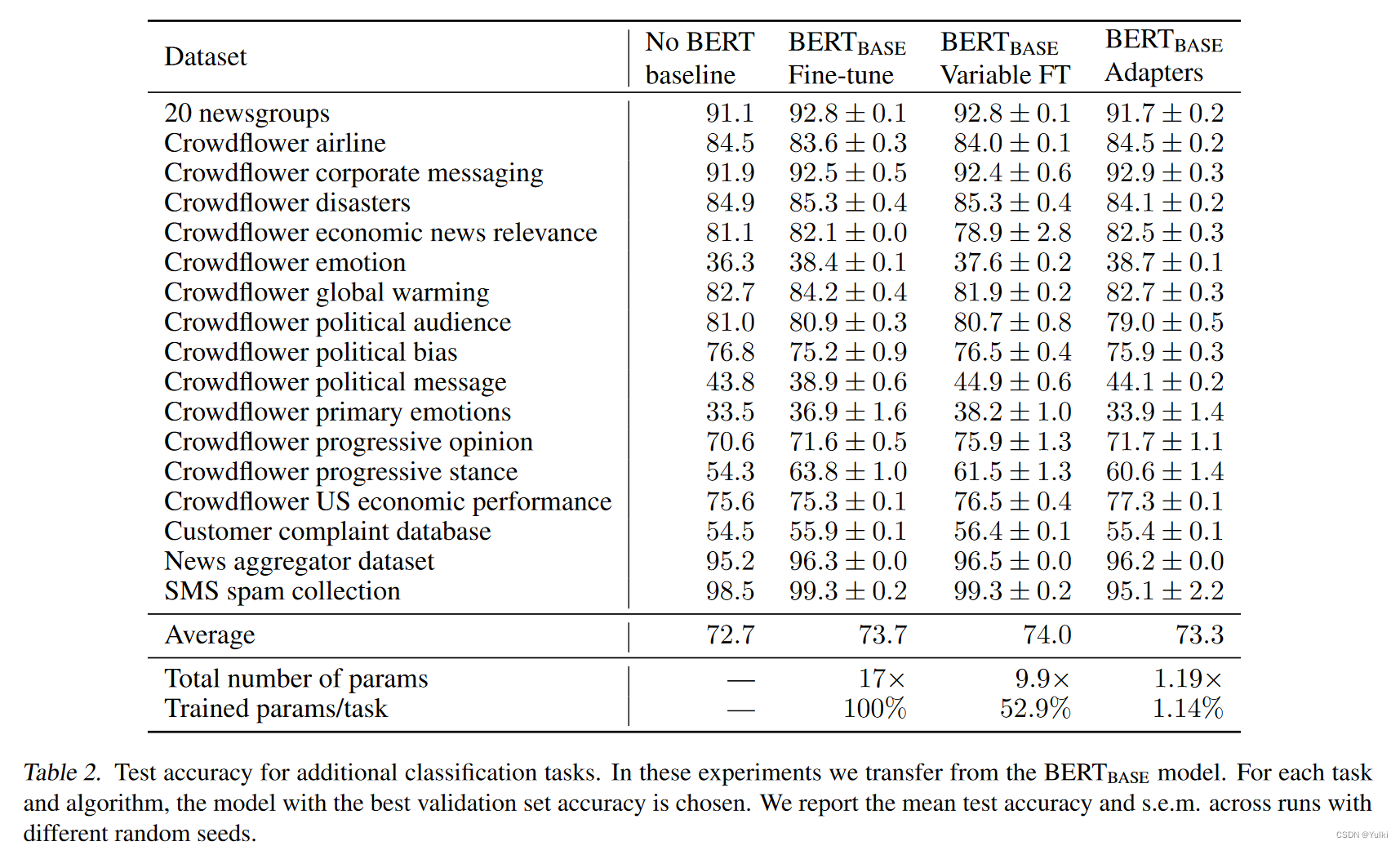
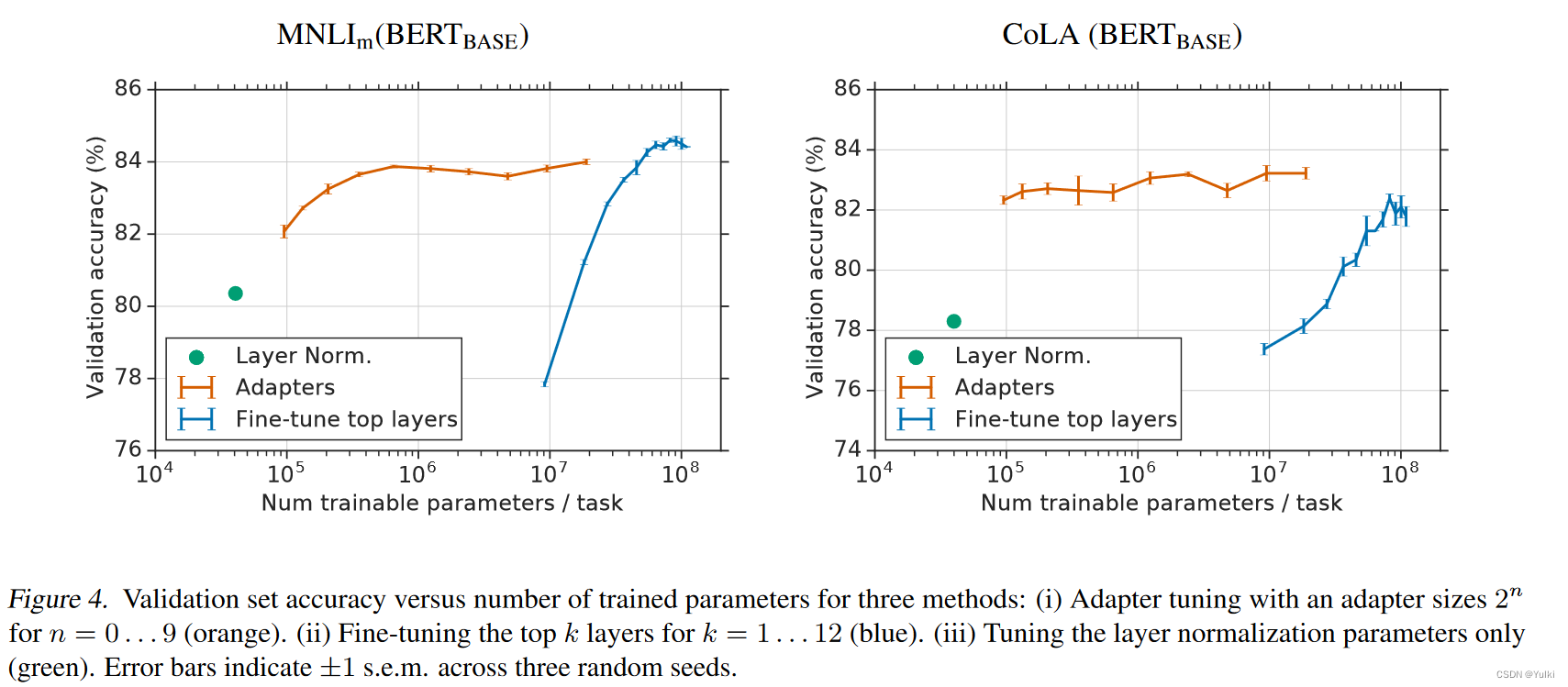
适配器大小控制参数效率,较小的适配器引入较少的参数,可能会降低性能。为了探索这种权衡,我们考虑不同的适配器大小,并与两个基线进行比较:(i)仅微调 B E R T B A S E BERT_{BASE} BERTBASE}的前 k 层。 (ii) 仅调整layer normalization参数。
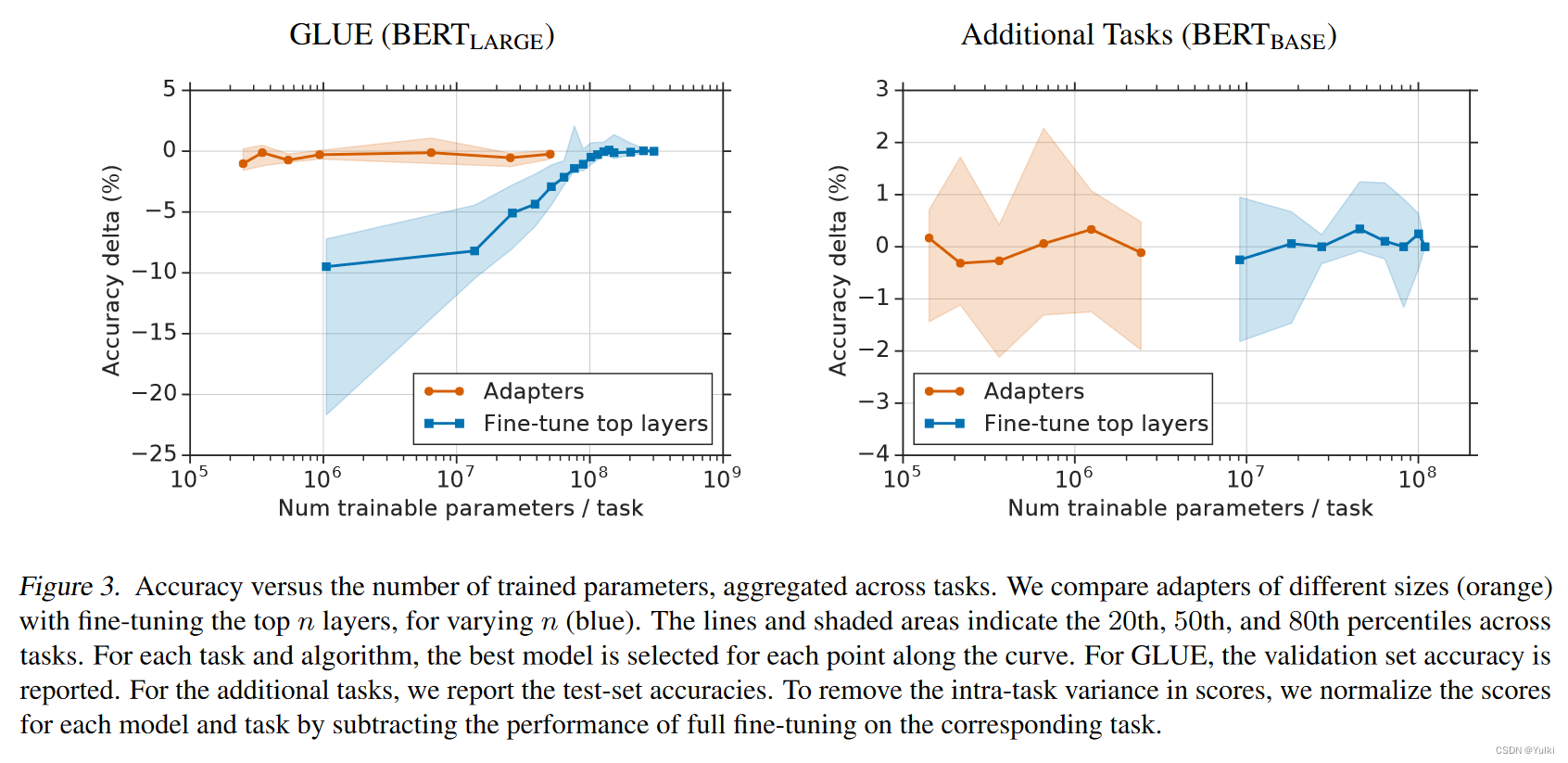
3.2 讨论
移除某一个单层的adapter对性能有很小的影响。热力图的对角线绿色部分表明只移除某一层的adapter,性能最多只有2%的降低。要是全部移除的话对于MNLI是37%,对于CoLa是69%。这表明虽然每个适配器对整个网络的影响很小,但整体影响很大。
右图表明,低层相对于高层只有很小的影响。从 MNLI 上的第 0 层到第 4 层移除适配器几乎不会影响性能。
本文研究了适配器模块对神经元数量和初始化规模的鲁棒性。在我们的主要实验中,适配器模块中的权值从一个标准差为 1 0 − 2 10^{−2} 10−2的零均值高斯分布中提取,并被截断为两个标准差。为了分析初始化规模对性能的影响,我们测试了区间内的标准偏差 1 0 − 7 , 1 10\^{−7},1 10−7,1。在两个数据集上,适配器的性能在 1 0 − 2 10^{−2} 10−2以下的标准差下都是稳健的。然而,在CoLA上当初始化太大时,性能会下降。
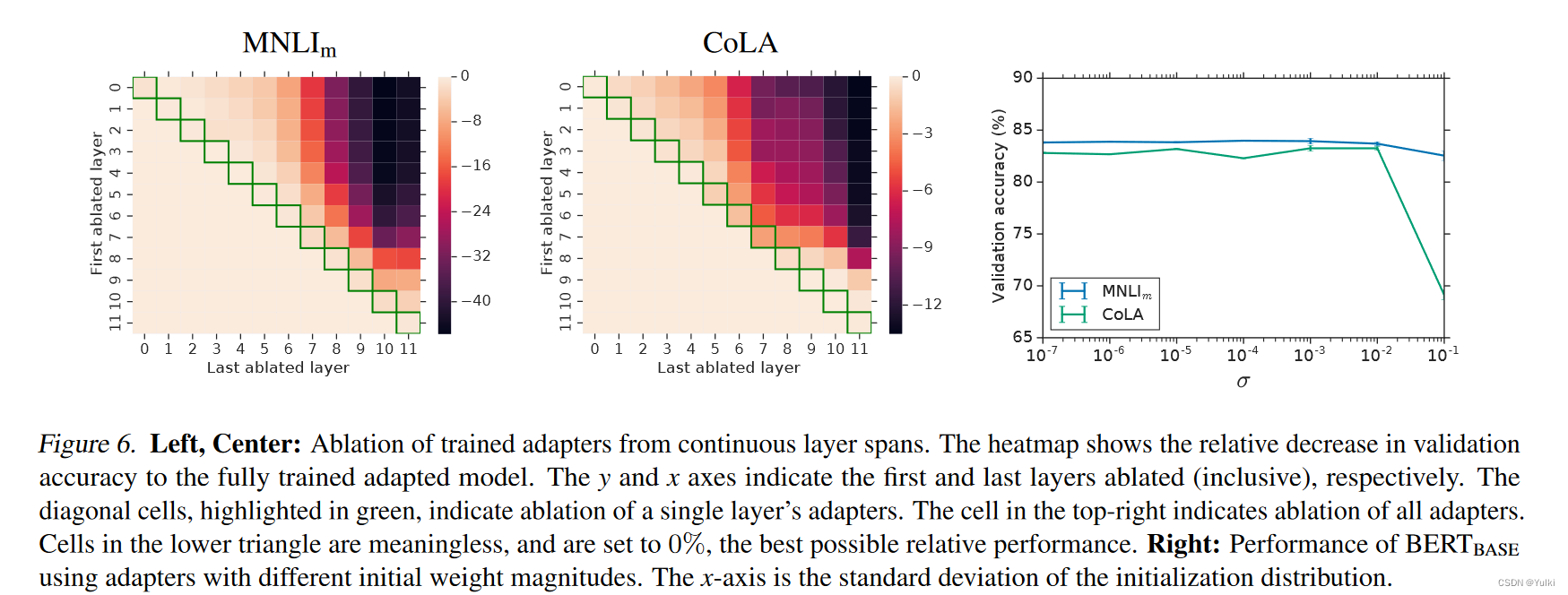
(这个图的最右上角代表着所有adapter都被移除了)
4.相关工作
多任务学习。与adapter不同的是,MTL(multi-task learing)需要在训练阶段同时访问任务。
继续学习。容易发生灾难性遗忘的问题。
视觉领域迁移学习。在视觉领域,卷积adapter模块已经被提出了,为ResNet或VGG增加一些1*1的卷积。(Rebuffi et al., 2017; 2018; Rosenfeld & Tsotsos, 2018).