在计算机视觉领域,点云配准是一项核心任务,其目标是估计两组点云之间的刚性变换(包括 3D 旋转和 3D 平移),在 3D 重建、目标定位、激光雷达 SLAM 等众多实际应用中发挥着不可或缺的作用。传统的点云配准方法大多基于迭代最近点(ICP)框架,而近年来深度学习驱动的方法也取得了显著进展。然而,这些方法都存在明显的局限性:传统方法在低重叠、噪声点多的真实场景中易陷入次优解,而基于学习的深度方法则受限于训练数据分布,在未见过的场景中泛化能力不稳定。
为此,CVPR 2025 的一篇论文提出了一种创新的零样本 RGB-D 点云配准框架 ------ZeroMatch,该框架无需任何特定任务的训练,就能在多样化的未见过数据上实现可靠的配准。
原文链接:Zero-shot RGB-D Point Cloud Registration with Pre-trained Large Vision Model
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与问题定义
1.1 点云配准的研究现状
点云配准方法大致可分为两类:
- 传统方法:以 ICP 及其变体为代表,通常通过融合颜色信息来增强对应点估计或姿态优化。例如,Park 等人将光度目标融入几何目标进行联合优化,Korn 等人将 3D 颜色元素引入空间坐标以估计对应关系。但这类方法依赖于局部几何特征,在重复模式、低重叠场景中易出现特征歧义,导致配准失败。
- 深度学习方法:设计了多种语义和几何特征融合机制,如多尺度线性变换、双向融合等,显著提升了特征区分度。代表性方法包括 UR&R、PointMBF、NeRF-UR 等,但这些模型严重依赖训练数据,当测试场景与训练数据分布差异较大时,性能会急剧下降。
1.2 零样本 RGB-D 点云配准任务
本文聚焦于一个较少被探索的任务 ------ 零样本 RGB-D 点云配准,其核心要求是:无需任何特定任务的训练,就能在真实世界中多样化的未见过场景(如光照不足、低重叠、重复模式等)中实现可靠的点云配准。该任务具有极高的实际应用价值,但也面临着巨大挑战:如何在缺乏训练数据的情况下,同时保证特征的局部几何辨识度和全局上下文一致性,以应对复杂场景的配准需求。
1.3 核心动机
Stable Diffusion 作为一种预训练大视觉模型,在大规模数据上进行了充分训练,具备强大的零样本图像表征能力,能够有效编码全局上下文信息。本文的核心动机正是:利用 Stable Diffusion 的零样本全局特征,增强手工设计几何描述符的区分能力,同时解决跨视角特征一致性问题,从而实现零样本 RGB-D 点云配准。
二、相关工作
2.1 传统 RGB-D 配准方法
传统方法多基于 ICP 框架扩展,通过整合颜色、语义等信息提升性能。例如:
- Semantic-ICP 将点云语义信息作为隐变量融入 EM-ICP 优化;
- GICPRKHS 引入再生核希尔伯特空间中的正则化器,保证强度表面的对应一致性;
- 众多方法(如 30,31,33 等)通过融合颜色、强度等多模态信息优化配准,但均未摆脱局部特征歧义的问题,在复杂场景中稳定性不足。
2.2 深度 RGB-D 配准方法
深度学习方法通过端到端训练学习特征融合策略,代表性工作包括:
- UR&R:利用可微对齐和渲染隐式引导变换预测;
- PointMBF:提出多尺度双向融合机制,充分利用 RGB-D 数据的互补信息;
- NeRF-UR:以 NeRF 为全局模型进行无监督帧到模型训练;
- ZeroReg:通过级联 Florence-2、SAMv2、CLIP 等 2D 基础模型实现零样本配准,但模型结构复杂,依赖多模型协作。
与现有方法相比,ZeroMatch 的创新点在于:无需模型级联,直接融合手工几何特征与 Stable Diffusion 全局特征,通过设计耦合图像输入模式解决跨视角一致性问题,实现更简洁高效的零样本配准。
2.3 Stable Diffusion 在计算机视觉中的应用
Stable Diffusion 是一种基于潜变量扩散模型的文本到图像生成模型,其预训练过程使其具备强大的全局上下文编码能力。近年来,它被广泛应用于下游视觉任务,如语义分割(SegDiff)、深度估计(DiffusionDepth)、语义匹配(SD4match)等。本文首次将其适配到 RGB-D 点云配准任务,充分挖掘其零样本全局特征提取潜力。
三、ZeroMatch 框架详解
ZeroMatch 的整体 pipeline 如图 2 所示,主要包含三个核心模块:手工局部几何描述符提取、零样本全局 Stable Diffusion 描述符提取(含耦合图像输入模式)、特征融合与姿态估计。
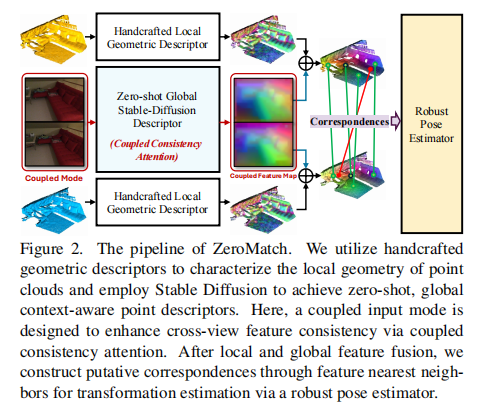
注:框架通过手工几何描述符捕捉局部特征,Stable Diffusion 描述符提供全局上下文,耦合输入模式增强跨视角一致性,最终通过特征融合与鲁棒姿态估计实现配准。
3.1 手工局部几何描述符(FPFH)
为保证零样本能力(无需训练),本文选择经典的手工设计几何描述符 ------ 快速点特征直方图(FPFH)来捕捉点云的局部几何特征。
3.1.1 FPFH 原理
FPFH 通过建模点与其邻域点之间的关系,高效编码局部表面几何:
- 首先计算每个点的简单点特征直方图(SPFH),基于法向量之间的角度等几何特征;
- 通过基于距离的权重聚合邻域点的 SPFH,得到最终的 FPFH 描述符:其中,
为邻域点数量,
3.1.2 FPFH 的局限性
FPFH 仅关注局部几何信息,缺乏全局上下文感知能力,在重复模式、对称场景中易出现特征歧义(如图 3 中间所示),导致不同位置的非对应点具有相似的描述符,进而产生错误的对应关系。

注:(左)重复模式场景;(中)FPFH 特征存在严重歧义;(右)Stable Diffusion 特征能有效区分不同区域,缓解歧义。
3.2 零样本全局 Stable Diffusion 描述符
为缓解 FPFH 的特征歧义,本文引入 Stable Diffusion 提取全局上下文感知特征,并设计了耦合图像输入模式解决跨视角特征一致性问题。
3.2.1 Stable Diffusion 基础回顾
Stable Diffusion 的训练分为两个阶段:
- 训练自编码器:学习编码器 E 将图像映射到潜空间,解码器将潜特征重建为图像;
- 训练 UNet-like 去噪器
UNet 结构包含下采样、瓶颈和上采样阶段,每个阶段包含三个子层:
- 自注意力层(SA):实现图像内特征交互;
- 交叉注意力层(CA):实现提示词到图像的信息传递(依赖 CLIP 文本编码器将提示词嵌入为 token 序列);
- 全连接前馈网络。
3.2.2 Stable Diffusion 特征编码
与标准生成流程不同,本文直接利用 UNet 在特定时间步 t 提取的特征作为 Stable Diffusion 描述符,具体步骤:
- 图像编码:将源图像
- 添加噪声:生成带噪声的潜特征
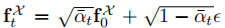 ,其中
,其中 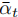 为扩散系数;
为扩散系数; - UNet 特征提取:将
3.2.3 全局上下文感知能力
如图 3 右侧所示,通过 t-SNE 可视化的 Stable Diffusion 特征,在不同场景区域呈现出明显的区分性,表明其能够有效编码空间结构和关系上下文等全局信息,可有效缓解 FPFH 的特征歧义问题。
3.2.4 跨视角特征一致性增强
问题分析
Stable Diffusion 默认采用单图像输入模式,仅包含图像内自注意力,缺乏图像间交叉注意力机制,导致在视角变化较大时,源图像和目标图像的对应区域特征一致性差(如图 4 左所示),进而影响配准性能。
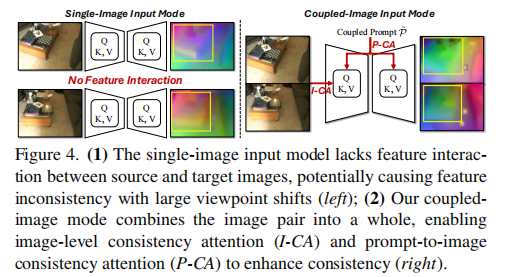
注:(左)单图像模式缺乏图像间特征交互,视角变化大时特征不一致;(右)耦合图像模式通过图像级一致性注意力(I-CA)和提示词到图像一致性注意力(P-CA)增强跨视角一致性。
耦合图像输入模式
为在不修改 Stable Diffusion 模型结构、不额外训练的前提下实现图像间特征交互,本文提出耦合图像输入模式:将源图像和目标图像垂直拼接为一张耦合图像,作为 Stable Diffusion 的输入。该设计使得原本的图像内自注意力能够自然扩展到两张图像,实现低成本的跨视角特征交互。
耦合一致性注意力机制
基于耦合图像输入,本文设计了两种一致性注意力机制,进一步增强跨视角特征一致性:
-
图像级耦合一致性注意力(I-CA)将耦合图像映射为潜特征后,通过掩码控制注意力范围,同时实现图像内自注意力和图像间交叉注意力:其中,SA (X,Y) 为图像内自注意力,CA (X,Y) 为图像间交叉注意力,
-
提示词到图像耦合一致性注意力(P-CA)设计耦合提示词(如图 5 所示):"生成两张垂直拼接的图像,来自同一场景的不同视角,场景环境(室内 / 室外)相同,布局和关键元素保持一致,仅存在细微差异"。

注:耦合提示词能引导 Stable Diffusion 生成布局一致的跨视角拼接图像,为特征一致性提供约束。
将耦合提示词嵌入后输入 UNet 的交叉注意力层,引导模型提取跨视角一致的特征,其计算公式为:其中, 为耦合图像特征投影的查询向量,
和
为耦合提示词嵌入的键和值向量。
特征投影与对齐
- 将 UNet 输出的耦合 Stable Diffusion 特征(
- 通过双线性插值将特征图上采样到输入图像的空间分辨率;
- 利用已知的相机内参矩阵,将图像特征投影到点云空间,得到每个点的 Stable Diffusion 描述符
3.3 特征融合与姿态估计
3.3.1 融合零样本点描述符
将手工几何描述符(FPFH)与 Stable Diffusion 全局描述符进行拼接,形成兼具局部几何细节和全局上下文的融合描述符:其中,PCA (・) 用于将 Stable Diffusion 特征的维度 压缩到与几何描述符匹配的维度
,确保特征融合的有效性。
3.3.2 鲁棒姿态估计
采用 "对应点构建 - 假设验证" 的配准流程,具体步骤:
- 构建候选对应点:通过特征最近邻匹配和随机下采样,得到候选对应点集合
- 二阶空间兼容性筛选:定义对应点
- 内点种子选择:通过谱匹配选择潜在的内点种子集合 C̃;
- 变换估计:对每个种子
- 最优变换选择:选择使重叠对应点数量最大化的变换参数(R,t)作为最终结果。
四、实验设计与结果分析
4.1 实验设置
4.1.1 数据集
- ScanNet:大规模室内 RGB-D 数据集,按 20 帧间隔采样,生成 159.4k/12.6k/26k 的训练 / 验证 / 测试集;
- ScanLoNet:ScanNet 的低重叠变体,按 50 帧间隔采样,场景重叠率更低,配准难度更大;
- 3DMatch:按 40 帧间隔采样生成 RGB-D 对,增加配准难度,与现有方法保持数据处理一致性。
4.1.2 实现细节
- FPFH 邻域半径设置为 0.15m;
- Stable Diffusion 去噪时间步 t=150,选择第 6 个上采样层特征;
- PCA 压缩后 Stable Diffusion 特征维度 d̃_sd=128;
- 姿态估计中,种子比例 = 0.2,一致性大小 = 6;
- 实验环境:Intel i5 2.2GHz CPU + TITAN RTX GPU,PyTorch 实现。
4.1.3 评价指标
采用点云配准领域标准指标:
- 旋转误差(Rotation Error):均值、中位数,以及误差≤5°/10°/45° 的准确率;
- 平移误差(Translation Error):均值、中位数,以及误差≤5cm/10cm/25cm 的准确率;
- 香农距离(Chamfer Distance):均值、中位数,以及误差≤1mm/5mm/10mm 的准确率。
4.2 与现有方法的对比实验
4.2.1 ScanNet 数据集结果
表 1 展示了 ZeroMatch 与 14 种主流方法的对比,包括 3 种传统方法(ICP、SIFT、SuperPoint)、6 种深度几何方法(FCGF、DGR 等)和 5 种深度 RGB-D 方法(UR&R、PointMBF 等)。
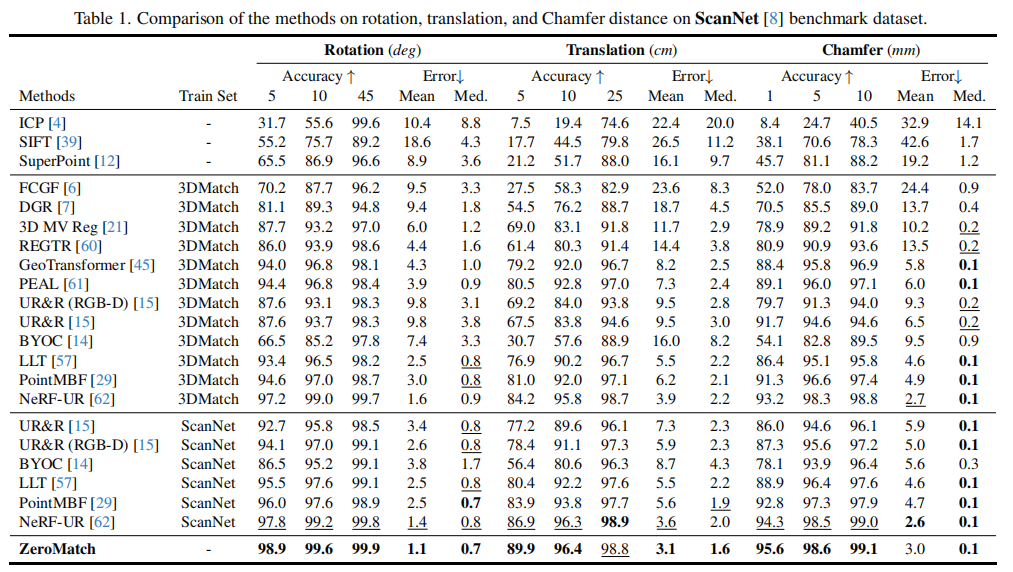
关键结论:
- 传统方法性能显著落后,验证了局部特征在复杂场景中的局限性;
- 深度方法受训练集限制,在未训练过的场景中性能下降(如 3DMatch 训练的模型在 ScanNet 上表现不如 ScanNet 训练的模型);
- ZeroMatch 无需训练,在所有指标上均超越现有 SOTA 方法,旋转误差≤5° 的准确率达 98.9%,平移误差≤5cm 的准确率达 89.9%,充分证明了零样本配准的有效性。
4.2.2 ScanLoNet 数据集结果
表 2 展示了低重叠场景下的对比结果,ZeroMatch 与 4 种 SOTA 深度 RGB-D 方法(UR&R、LLT、PointMBF、NeRF-UR)进行比较。
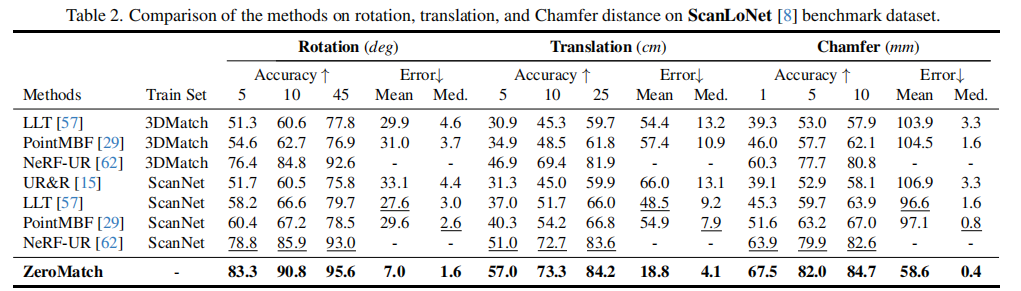
关键结论:
- 低重叠场景下,所有方法性能均有下降,但 ZeroMatch 的下降幅度最小,依然保持领先;
- 相比最优的 NeRF-UR,ZeroMatch 在旋转误差≤5° 的准确率上提升 4.5%,平移误差≤5cm 的准确率上提升 6%,证明其在低重叠场景中的强鲁棒性;
- 图 7 展示了定性结果,ZeroMatch 在重叠率仅 11.9%-18.1% 的场景中,仍能实现精准配准。
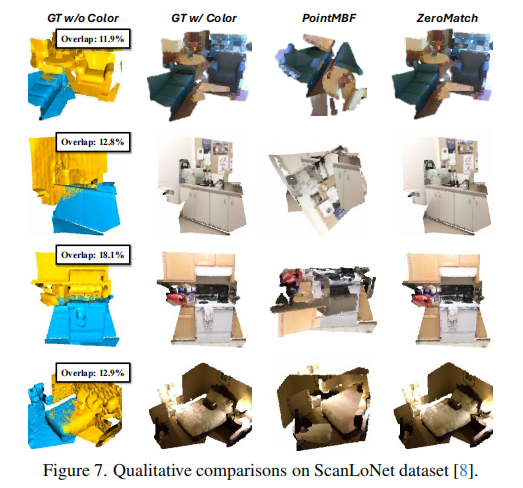
注:ZeroMatch 在低重叠场景中配准效果明显优于对比方法。
4.2.3 3DMatch 数据集结果
表 3 展示了 3DMatch 数据集的对比结果,ZeroMatch 与 UR&R、LLT、PointMBF 三种方法进行比较。
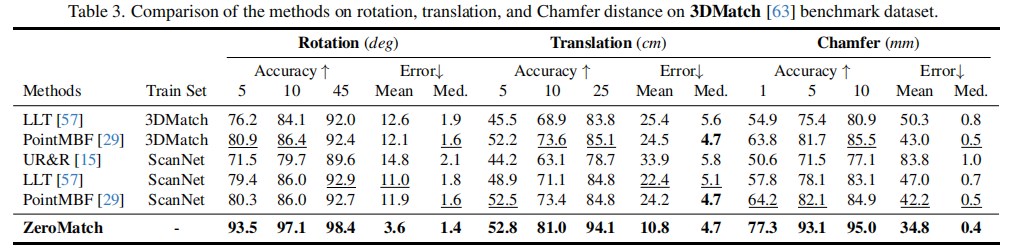
关键结论:
- 即使在 40 帧间隔的高难度配准任务中,ZeroMatch 仍在所有指标上领先,旋转误差≤5° 的准确率达 93.5%,平移误差≤25cm 的准确率达 94.1%;
- 相比 PointMBF,ZeroMatch 的旋转误差均值从 12.1° 降至 3.6°,香农距离均值从 43.0mm 降至 34.8mm,验证了其在不同数据集上的泛化能力。
4.3 消融实验与分析
为验证各模块的有效性,本文设计了多组消融实验,所有实验均在 ScanLoNet 数据集上进行。
4.3.1 耦合图像输入模式的有效性
表 4 第一组对比了单图像输入模式(Single)和耦合图像输入模式(Coupled)的性能:
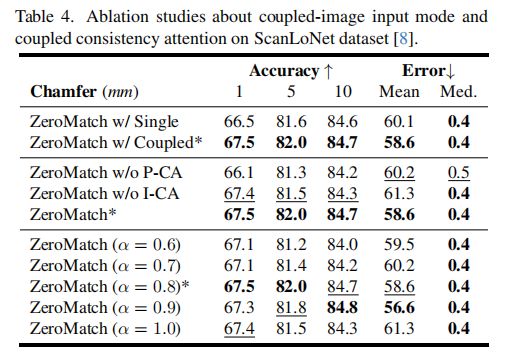
结论:耦合图像输入模式相比单图像模式,在所有指标上均有提升,证明其能有效增强跨视角特征一致性。图 6 的 t-SNE 可视化进一步验证了这一点 ------ 耦合模式下源图像和目标图像的对应区域特征更集中、更对齐。
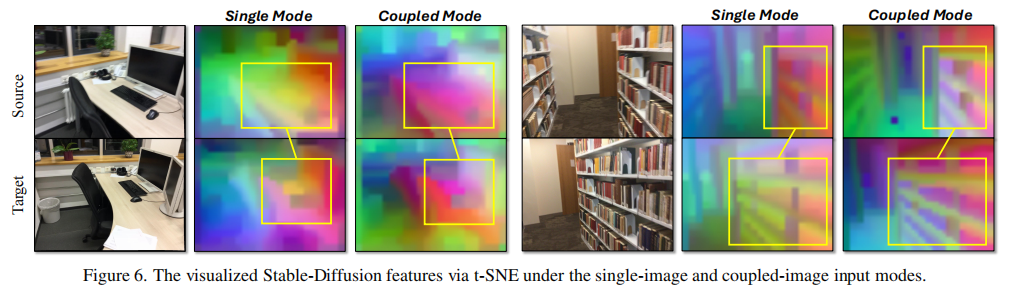
注:耦合模式下(右)对应区域特征更一致,单图像模式(左)特征分散。
4.3.2 耦合一致性注意力的有效性
表 4 第二组对比了移除 P-CA(ZeroMatch w/o P-CA)和移除 I-CA(ZeroMatch w/o I-CA)的性能:
- 移除 P-CA 后,旋转准确率和香农距离均下降,证明耦合提示词能有效引导特征一致性;
- 移除 I-CA 后(仅保留自注意力,α=1.0),性能同样下降,验证了图像间交叉注意力的必要性;
- 表 4 第三组显示,当 α=0.8 时性能最优,表明平衡图像内和图像间特征聚合能获得最佳效果。
4.3.3 特征融合的有效性
表 5 对比了仅使用几何特征(Geo)、仅使用 Stable Diffusion 特征(SD)和融合特征(Geo+SD)的性能:

结论:融合特征的性能显著优于单一特征,证明几何特征(局部细节)和 Stable Diffusion 特征(全局上下文)具有互补性,二者结合能有效提升特征区分度。
4.3.4 Stable Diffusion 特征维度的影响
表 6 对比了不同压缩维度(64/128/256)的性能:
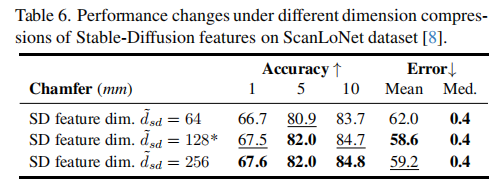
结论:维度为 128 时性能最优,维度过小会导致上下文信息丢失,维度过大则不会带来显著性能提升,反而增加计算成本。
五、结论与展望
5.1 主要贡献
本文的核心贡献可总结为三点:
- 提出了一种新颖的零样本 RGB-D 点云配准框架 ZeroMatch,无需任何特定任务训练,通过融合手工几何特征与 Stable Diffusion 的零样本全局特征,实现了未见过场景的可靠配准;
- 设计了耦合图像输入模式及对应的图像级和提示词到图像耦合一致性注意力机制,有效解决了跨视角特征一致性问题,低成本实现了图像间特征交互;
- 在 ScanNet、ScanLoNet、3DMatch 三个数据集上的大量实验表明,ZeroMatch 显著优于现有 SOTA 方法,验证了其在常规场景和低重叠、重复模式等复杂场景中的强鲁棒性。
5.2 未来展望
尽管 ZeroMatch 取得了显著突破,但仍有进一步优化的空间:
- 特征融合策略可进一步优化,例如采用自适应权重融合而非简单拼接,以更好地平衡局部几何和全局上下文;
- 可探索 Stable Diffusion 不同层、不同时间步特征的差异,进一步提升特征的判别能力;
- 扩展到更具挑战性的场景,如动态场景、室外大规模场景的点云配准;
- 优化计算效率,降低 Stable Diffusion 特征提取的时间成本,实现实时配准。
总结
ZeroMatch 创新性地将预训练大视觉模型 Stable Diffusion 引入 RGB-D 点云配准任务,通过 "手工几何特征 + 全局上下文特征" 的融合模式,结合耦合图像输入设计,成功解决了零样本场景下的特征歧义与跨视角一致性问题。其无需训练、泛化能力强、鲁棒性高的特点,为实际应用中的点云配准提供了一种全新的解决方案,也为预训练大模型在 3D 视觉任务中的应用提供了重要借鉴。