引言
本文将论述如何将Windows本地的excel表数据,导入到虚拟机Linux系统中的Hadoop生态中的Hive数据仓库中。
实验准备
DBeaver
Hive3.1(Hadoop3.1)
excel数据表
实验步骤
一、首先打开虚拟机,启动Hadoop,启动hive,启动hiveserver2,连接DBeaver,成功连接展示如下:

二、将清洗后的excel表的数据另存为txt格式,并将文本转换为UTF-8:
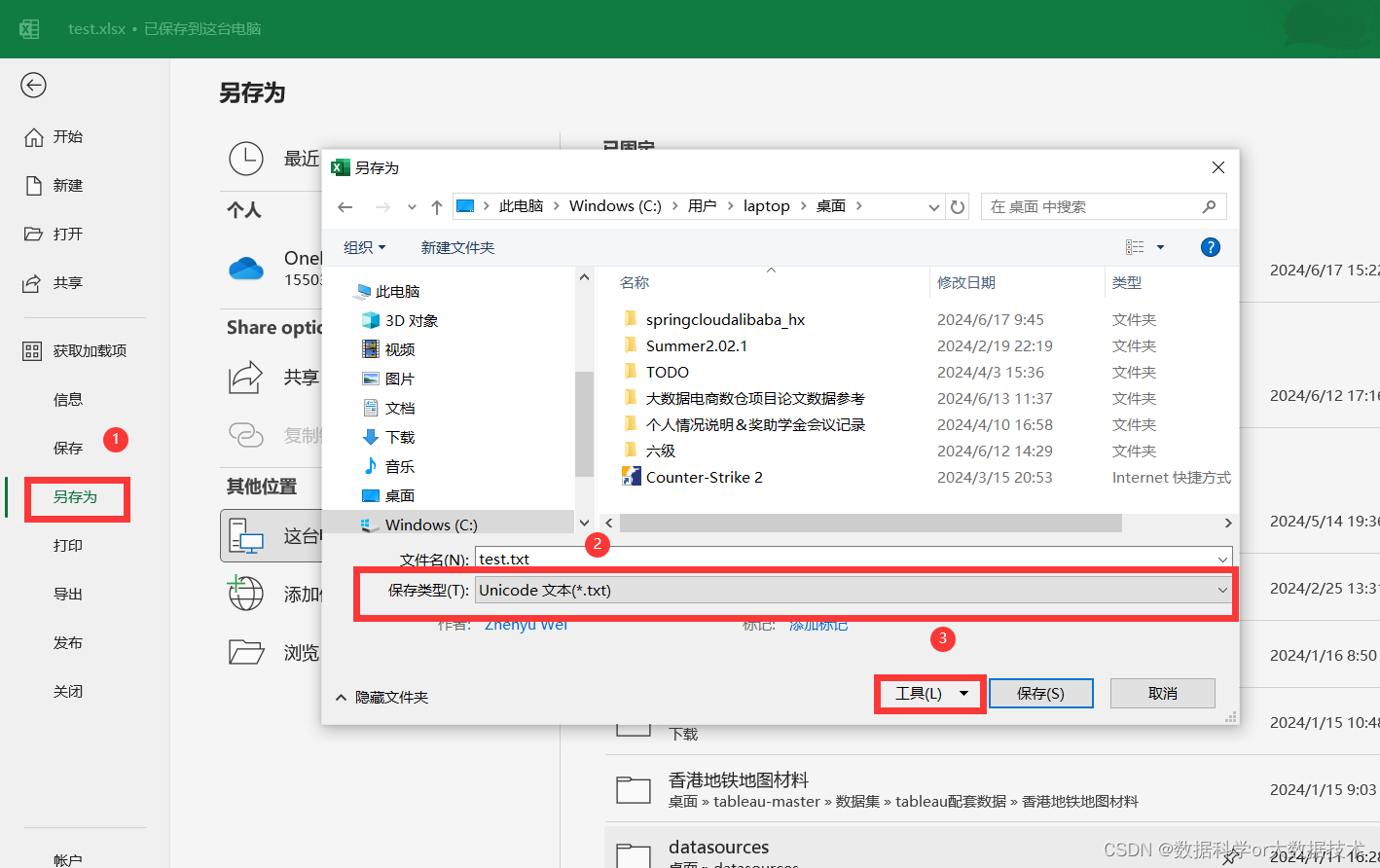
首先点击文件:

点击另存为,转换保存格式为txt,同时在工具中的Web选项中选择编码UTF-8:


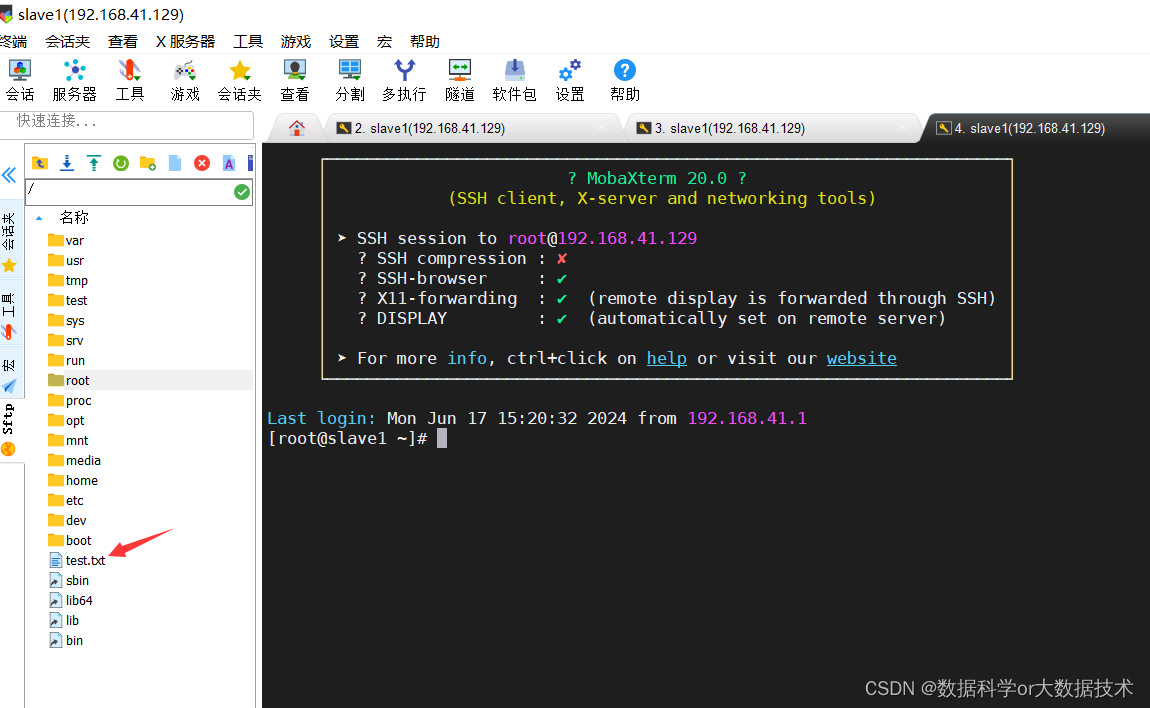
三、源excel表数据文件成功转换为test.txt文本文件,并删除第一行的字段(建表时已经建立英文名称字段了)截图如下:

四、将test.txt文件上传至虚拟机的Linux环境中,同时在hive里新建Test数据表(已经建库),输入建表语句的时候务必注意对应字段的类型必须相同。
建立test数据表的语句如下(后面row...部分是以\t为分隔符,必须加上,否则会将整个数据全放在第一列中):
create table test(Name String,Age String,ID String) row format delimited fields terminated by '\t' STORED AS TEXTFILE;成功建表如下截图如下:

在DBeaver中查看截图如下:

五、接着输入HQL语句:
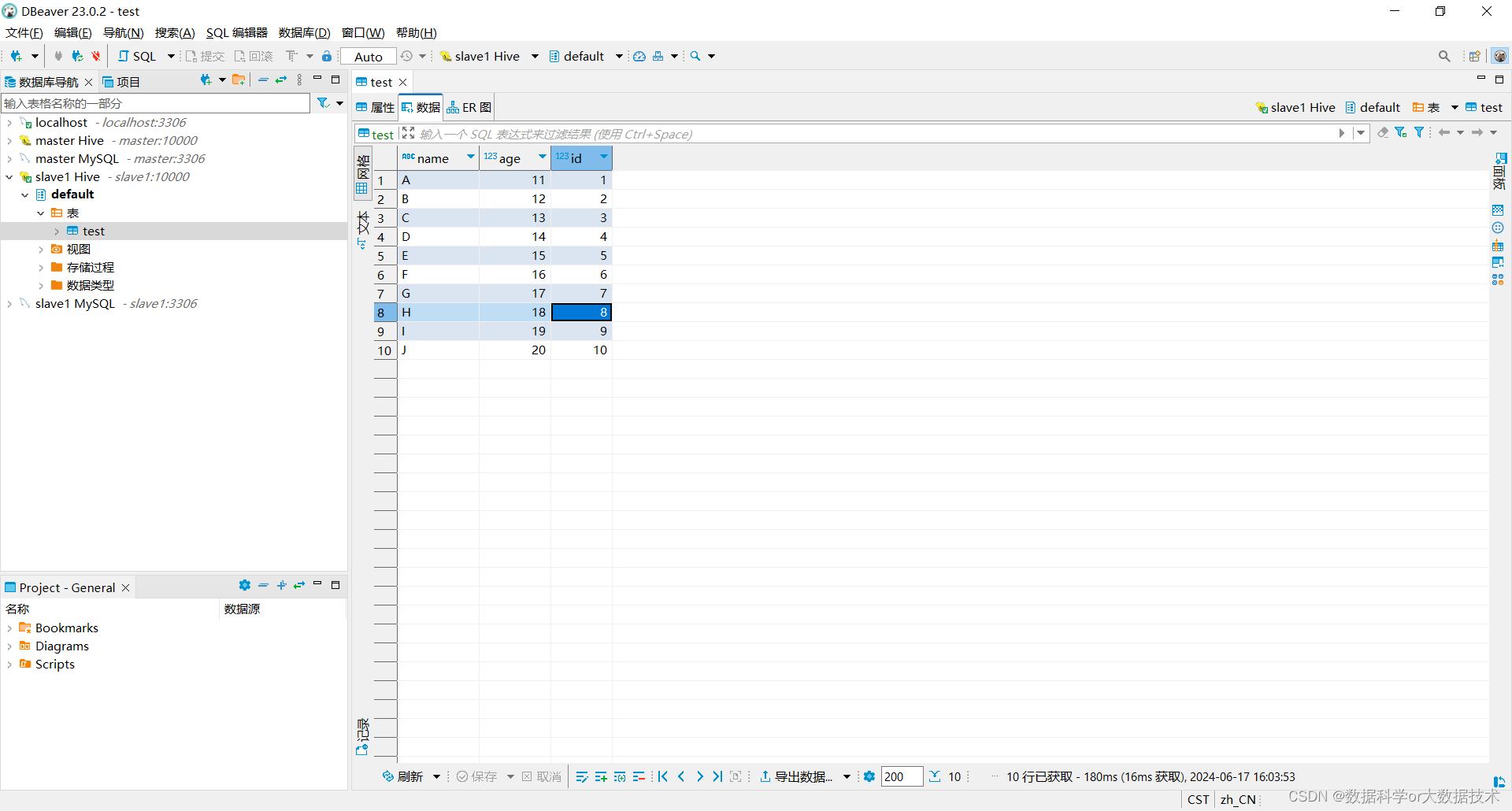
load data local inpath '/test.txt' into table test;成功上传test.txt的文件截图如下:

在DBeaver中查看截图如下:
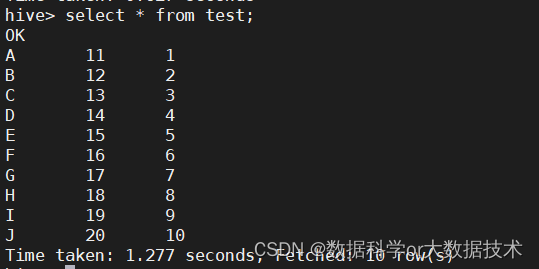
也可以在hive中输入HQL语句查看
select * from test;截图如下:
至此,完成excel表数据传入Hive的所有操作。