首先我们定义出一个点赞系统需要对外提供哪些接口:
1.用户对特定的消息进行点赞;
2.用户查看自己发布的某条消息点赞数量以及被哪些人赞过;
3.用户查看自己给哪些消息点赞过;
这里假设每条消息都有一个message_id, 每一个用户都有一个user_id, 从以上三个接口我们可以大概想到需要在存储层保存哪些数据:
1.消息点赞表, 形式如{message_id, user_id, timestamp ... }, 需要具备根据指定message_id 查找所有点赞人及点赞数量的能力;
2.用户点赞表,形式如{user_id, message_id, timestamp ... },需要具备根据user_id查找其所有点赞过的消息列表;
3.点赞计数表,形式如{message_id, count}
从以上几点来看,如果系统的用户规模不大比如用户小于1w人,如果用mysql来存储好像一张表就能搞定,用message_id做主键,然后在user_id上建立索引就可以很方便实现上面要求的三个接口:
cpp
select * from table where message_id=xxxx
select * from table where user_id=xxxxx
select count(*) from table where message_id=xxxx但是如果用户数量很大比如向抖音这种过亿量级,单表行数量迅速膨胀,并且可能存在某些消息热门,短时间内大量用户点赞导致mysql挂掉(一般而言mysql能够支持的tps为10的三次级别,具体数值依赖与cpu 磁盘 内存性能)。
很自然我们想到分库分表,但是选择哪一个字段做分表列?如果选message_id 进行分库分表,那么如果要查询单个用户所有点赞的message, 就需要查询所有的库;反之用user_id进行分,那么查询指定message_id 查找所有点赞人就需要查询所有库;
从另一个方面来讲,上述方式构建表存在带量冗余信息(一条message 被1000人点赞, 那么就需要1000行来存储),这主要是收到mysql中关系型数据库模式的限制。
方案二:
上述方案在用户规模较大的情况下难以满足我们的需求,这里在提供一种以mogondb作为核心存储的可能方案。
mogondb与mysql不同,它天然支持分布式扩展并且他是无模式的,下面给出存储方案:
消息点赞表:
cpp
{
"message_id":12345,
"count": 3
"user_List": [5555, 8888,9999 ....]
}用户点赞表:
cpp
{
"user_id":5555,
"message_List": [12345...]
}上面只列出核心字段,其他业务字段如时间戳等可以自行扩展;mogondb 可以对message_id 或者 user_id 进行索引查询,很方便的满足上面提出的三个接口。
这里还可以做一些特定的限制,如果一条消息被超过5000以上人点赞,那么我们是否有必要记录所有点赞过的用户呢?我个人觉得没有必要,不会有用户会去查询全量用户列表,因为假设客户端一屏幕展示20个点赞用户,那么5000/20=250,用户需要250此滑屏幕才能看完,不会有人这么干。
因此可以考虑,当点赞用户超过5000后,消息点赞表就只需要更新点赞数量,而不用将用户加到user_List列表里了。
但是如果某条消息上瞬间请求量大还是可能冲垮mogondb特定分片,从而导致服务不可用,如何解决呢?
这里我想到的是使用消息队列来削峰,具体的架构如下图所示:
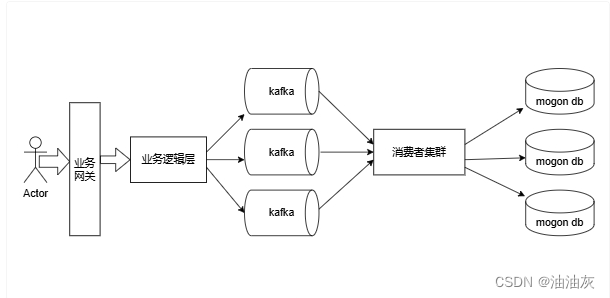
https://docs.qq.com/flowchart-addon
用户点赞的流程:
1.首先业务网关层,这里提供身份校验、限流等通用能力;
2.业务逻辑层根据message id 进行哈希写入kafka分区;
3.消费者集群从kafka消费数据,写入mogondb;
如果是数据查询,那么业务逻辑层直接请求db拿到结果就可以返回;
以上就是我点赞系统的设计的一些思考。