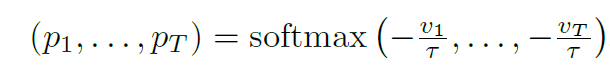- 这是ICLR2023的一篇world model论文,用transformer来做世界模型的sequence prediction。
- 文章贡献是transformer-based world model(不同于以往的如transdreamer的world model,本文的transformer-based world model在inference 的时候可以丢掉)两个损失,一个采样策略。
WM
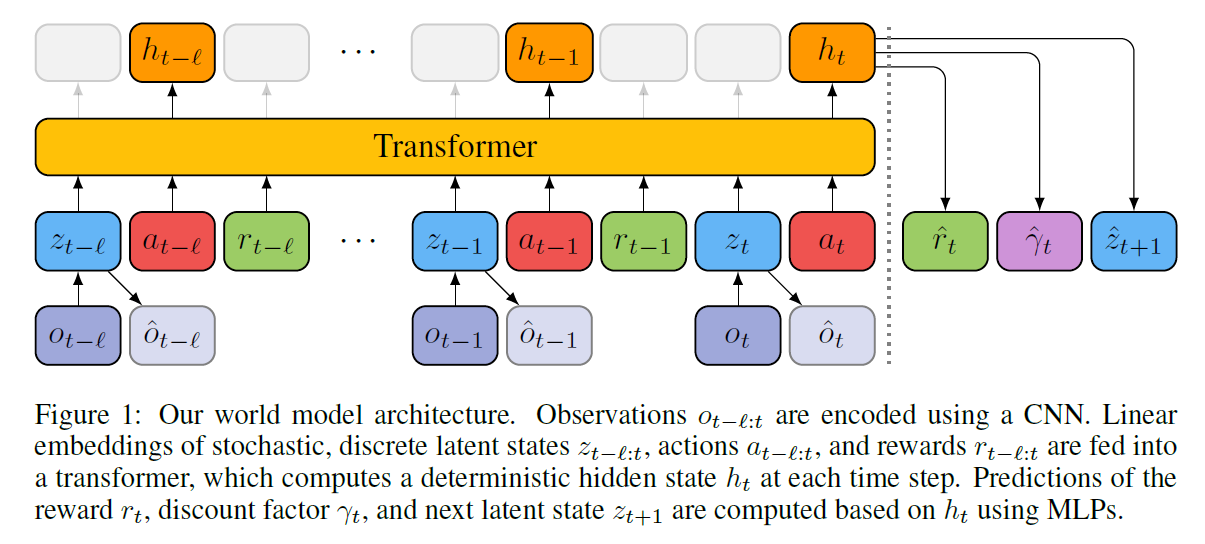
- TWM用的仍然是经典的world model框架:
- encoder-decoder用的是VAE,不过输入是四帧而不是一帧
- dynamic model用过去 l l l 步的 z z z a a a r r r 和当前的 z z z a a a作为输入,用transformer预测 h t h_t ht,再用 h t h_t ht预测 r t r_t rt, γ t \gamma_t γt和 z t + 1 z_{t+1} zt+1,如下:
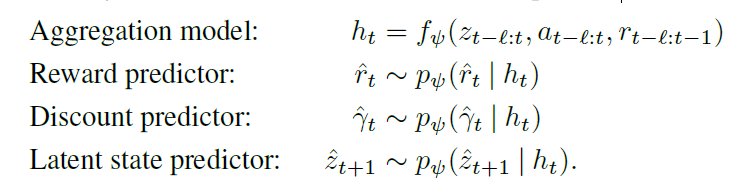
- 上面的三个 p p p都是MLP, f f f是transformerXL, 3 l − 1 3l-1 3l−1个token输入,预测一个token:
- z,r,gamma的MLP的输出分别是:a vector of independent categorical distributions, a normal distribution,
and a Bernoulli distribution
- 提的两个损失,一个是如下的encoder-decoder的损失,由三项组成,第一项是VAE的损失,第二项是对z的熵损失,第三项是与sequence model的一致损失:
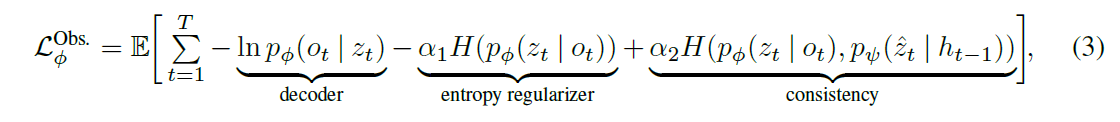
- 第二个损失是用来train sequence model的,第一项其实跟上一个损失的第三项一样,但是上一个损失是train VAE的,这个损失是train sequence model的;第二项第三项不用说,就是正常的reward和discount的损失:
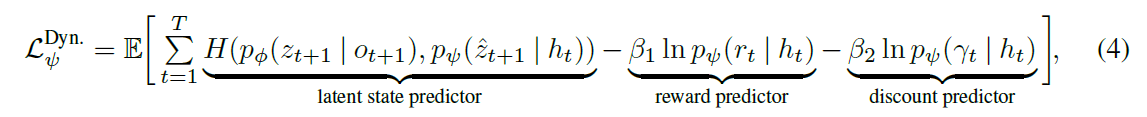
- 相比LSTM GRU之类模型,transformer的好处在于长序列建模,sequence model总是能看到过去 l l l步发生的确切的事情,而非仅能观察到一个压缩的状态 h t h_t ht
RL
- 这里可以看到,dreamerv3等模型预测的是奖励 r t r_t rt 和terminate d t d_t dt,但是TWM预测的是discount factor γ \gamma γ,在这里就可以派上用场了,预测的 γ \gamma γ用来train RL模型(而其他的WM,RL模型的 γ \gamma γ用的是固定值)。那么训练的时候 γ \gamma γ怎么监督呢,文章定义的label是 γ t = 0 \gamma_t=0 γt=0和 γ t = γ \gamma_t=\gamma γt=γ,即当terminate的时候 γ = 0 \gamma=0 γ=0而其他时候 γ \gamma γ是固定值,label是这样,而模型应该会灵活预测?不知道
- 这里有一些新的损失,比如对策略的熵的损失,不能低于一个阈值:
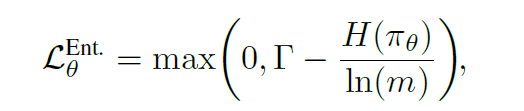
- 这里还要关注的是policy model的输入,一般policy model的输入是 z t z_t zt和 h t h_t ht的concate,如dreamerv3和STORM,文章试了发现decoder的输出也可以(IRIS就这么干的), o t o_t ot也可以,本文用的是 z t z_t zt,比较轻量快速,只需要encoder而不需要sequence model。并且,训练的时候用的是sequence model预测的zt,而测试的时候则用的是encoder编码的zt加上frame stacking操作(这里有点疑问,维度?)
- train的时候还是常规的三步走:用RL model采样,train world model,用world model train RL model。
- training的时候有个sampling的stategy,如下, 是为了让模型更关注后面采样得到的sample,但vt的公式也没给,之说是incremented every time an entry is sampled: