可解释性人脸识别(XFR)?
人脸识别有一个任务叫1:N(识别)。这个任务将一个人的照片与N张注册照片进行比较,找出相似度最高的人。
这项任务用于刑事调查和出入境点。在犯罪调查中,任务从监控摄像头中检测出人脸,并与罪犯数据库进行比对,以便更有效地识别罪犯。此外,进出大楼时,在入口大门处拍摄人脸,并与员工数据库进行核对,实现员工签到与记录。
近年来,深度学习的突破大大提高人脸识别的准确率了,使其具有实用性。但是,另一方面,由于模型变得更加复杂,决策的标准是一个黑箱,因此,相信模型的识别结果存在一定的风险。
算法会面对一个问题是,人脸识别模型决定该图像与其他图像最相似 ?其依据是什么?
可解释的人脸识别(XFR)是将这一原理可视化的模型。模型的可视化决策依据是人脸识别技术安全使用的重要因素之一。
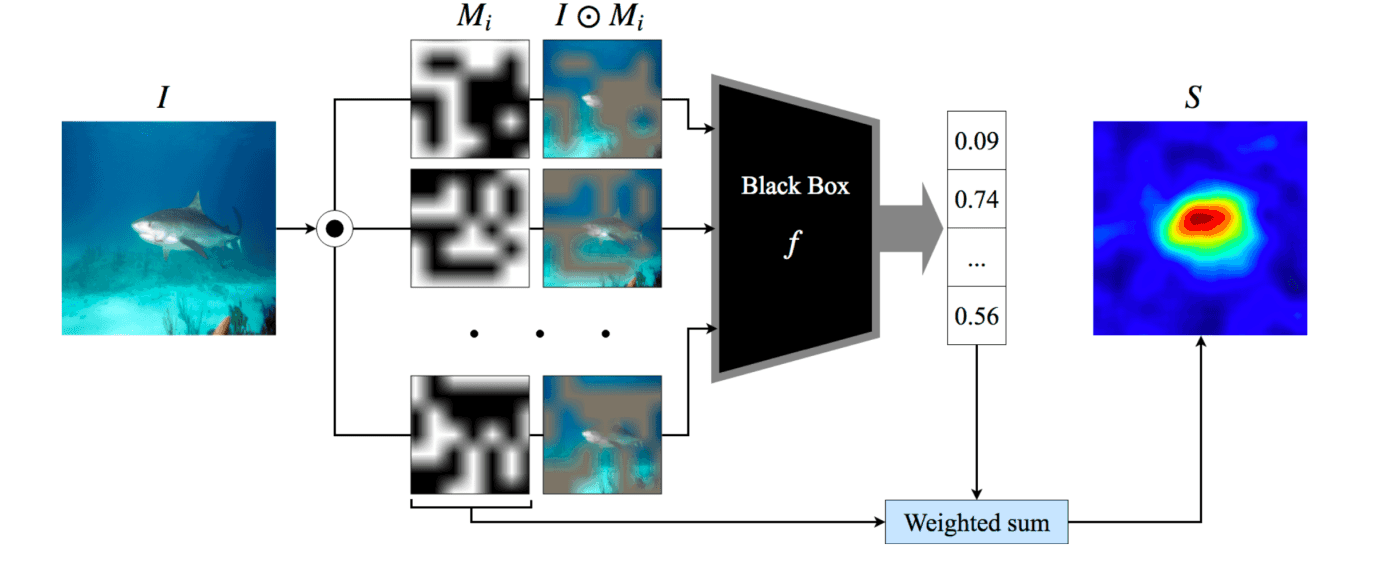
本文提出了一种更准确的检测和评价这种判断依据的方法。下图是本文的概述。首先,把(Mate #1、Probe、Non-mate(Inpainted))作为一对,输入到XFR中。接下来,XFR计算{Probe、Mate #1}和{Probe、Non-mate(Inpainted)}之间概率差异最大的像素,创建XFR Saliency Map。最后,计算XFR Saliency Map和非伴侣(Inpainted)(Mate #2)之间的匹配度,单位为像素。如果符合,则标为True Positive (Green),如果不符合,则标为False Positive(Red)。红色的数值越小,绿色的数值越大,绿色的数值越高,XFR Saliency Map就能更准确地识别出两者之间的细微差异,模型也就越可靠。
本文将介绍XFR算法(Subtree EBP、DISE)、定量评估其性能的方法(Inpainting Game),以及这些评估的结果。
源码地址:https://github.com/stresearch/xfr
XFR的新算法(Subtree EBP、DISE)
本文将五种XFR算法(DISE、Subtree EBP、Mean EBP、Contrastive EBP、Truncated cEBP)应用于三种CNN(LightCNN、VGGFace2 ResNet-50和ResNet-101)。在算法中,Mean EBP、Contrastive EBP和Truncated cEBP是目前报告性能较高的算法的代表。而Subtree EBP,是本文中DISE提出的新算法。在这里我们将介绍Subtree EBP和DISE。
Subtree EBP
SubtreeEBP探索CNN中各个节点的激活性,最大化其与Mate的相似性,最小化Triplet Loss,同时最小化其与Non-mate的相似性。将每个节点的Excitory Regions独立可视化,并按损失降序排序,组合成一个最能描述如何识别Probe的Saliency Map。
SubtreeEBP是本文EBP(Excitation Backprop)中使用的Triplet Loss(见下文)的扩展算法。其中p代表Probe,m代表Mate,n代表Non-mate Embedding。

公式1
输入{Probe, Mate, Non-Mate}计算网络上每个节点xi的三联损失斜率(∂L/∂xi)。然后我们计算Probe的梯度,假设Mate和Non-Mate的Embedding不变。然后我们将每个节点xj的梯度按降序排列,并选择梯度最大的前k个节点的正梯度。这些节点是对Triplet Loss影响最大的前k个节点,与Mate相似度较高,与Non-mate相似度较低。最后,从所选节点中创建k个EBP Saliency Map(Si),并将Si与权重wi(=∂L/∂xi)进行加权凸合,如下式所示,产生最终的SubtreeEBP Saliency Map(S)。在下面的公式中,权重由损失梯度(wi)给出,并进行归一化处理,使之和为1。
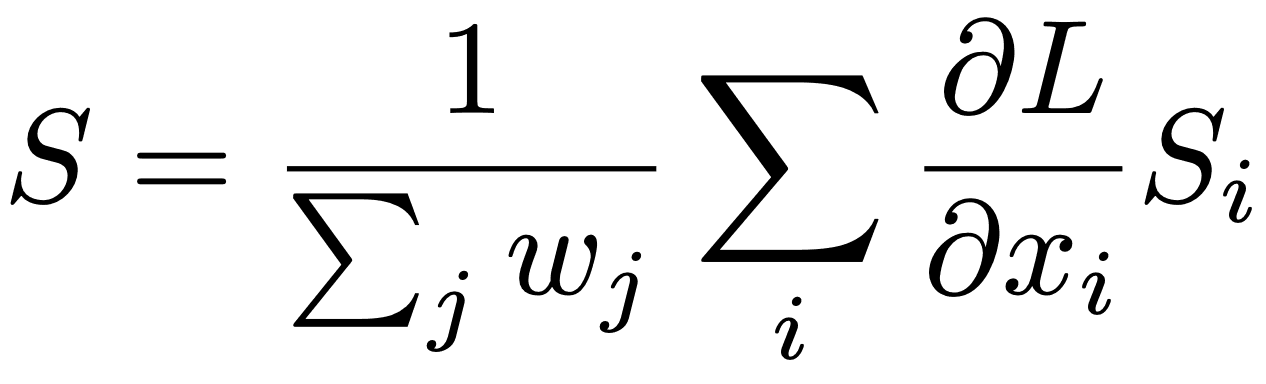
公式2
下图是一个SubtreeEBP的例子。它们显示了损失斜率(WI)最高的27个节点。它们是逐行排序的,因此右下角的节点比左上角的节点对损失的影响更大。每个Saliency Map(Si)都会被凸连接起来,形成最终的Saliency Map(S),创建一个最清晰地说明与Probe相似性的Saliency Map。在这种情况下,说明鼻子里的Mate和Nonmate有很大的区别。换句话说,我们可以看到,我们通过关注鼻子来区分Mate和Nonmate。
DISE(Density-based Input Sampling for Explanation)
本文提出了另一种XFR算法DISE(Density-based Input Sampling for Explanation),它是RISE(Randomized Input Sampling for Explanation)的扩展。DISE是RISE(Randomized Input Sampling for Explanation)的扩展。
V.Petsiuk, A. Das, and K. Saenko.Rise: Randomized input sampling for explanation of black-box models.British Machine Vision Conference(BMVC),2018。(Fig.3)
RISE将随机采样的噪声掩码与输入图像进行匹配,并评估黑盒模型的输出变化,创建一个Saliency Map,将对类目分类有重大影响的像素可视化。DISE为这个RISE提供了三个扩展。
- 定义一个先验分布,使噪声抽样更有效。
- 定义一个具有有限数量遮蔽元素的稀疏遮蔽。
- 定义三倍损失的数值斜率,以加权每个掩模。
关于第一种,RISE为输入图像创建了一个均匀随机的掩码,这使得采样过程效率低下。因此,在DISE中,我们设置了一个先验分布来有效地对噪声进行采样。此外,先验概率被限制在均值-EBP的前50%,以避免掩盖不重要的背景。
2(如:眼睛)因为,RISE使用随机的二进制掩码,覆盖整个输入图像,而DISE限制了被掩码的元素数量,并使其变得稀疏,以明确界定局部区域的效果。此外,用于评估XFR性能的Impainte Game(见下文)表明,使用模糊图像掩模比使用灰色掩模在数量上有更好的效果。
,对于第三种,给定掩码-掩码的Probe根据先验分布进行采样,我们可以计算Triplet Loss的数值斜率如下:P为Probe,m为Mate,而非在伴侣为n,掩蔽的Probe为p^的情况下,Eq.1的数值斜率可近似为: Eq.3
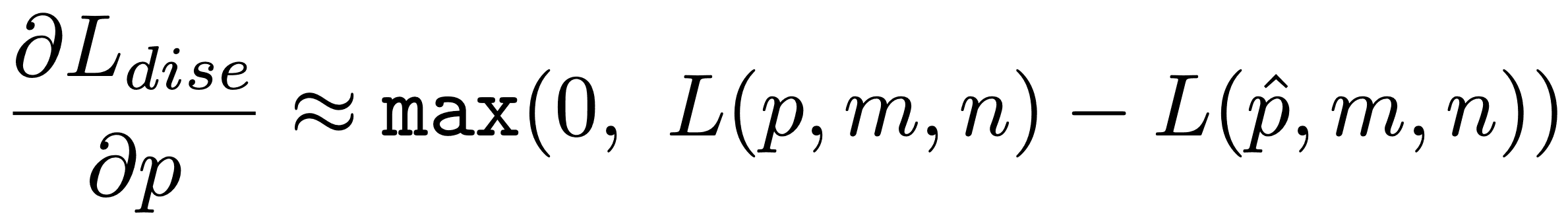
Eq. 3.
当我们掩盖了Probe和Mate之间的相似性增加而与Non-Mate的相似性降低的区域,即对识别有显著贡献的区域时,数值梯度会增加。这使得这些掩码的损失加权累积可以变成一个Saliency Map。最终的Saliency Map是根据公式2计算的。其中Si是配对的二元掩码,并且具有非负的斜率权重(式3)。
综合安全分遣队概述如下:在这种方法中,探针的局部区域被掩盖在灰色中,并根据从激励回传(EBP)获得的先验分布进行采样。给定一个已经被采样和屏蔽的Probe,我们计算{Probe, Mate, Non-mate}的Toriplet Loss的数值斜率。最后,数值斜率较高的掩码在Saliency Map中的权重较高。
什么是评价XFR的Inpainting Game?
XFR算法的目标是可视化,为什么人脸识别模型确定该人脸,而不是其他人脸是最相似的。一种方法是突出并可视化与判断为最相似的ID相匹配的区域,而不是其他ID。创建Saliency Map)。为了评估XFR算法的性能,重要的是要将该区域以高分辨率可视化。
评价这种XFR算法的性能的一个重要问题是Ground Truth的生成。在XFR中,Ground Truth不仅取决于Probe、Mate和Non-Mate的选择,还取决于要评估的网络。我们通过合成Inpainted Nonmate和Doppelganger与从Original修改的人脸选定区域来解决这个问题。
在本实验中,两幅图像之间只有Inpainted区域不同,所以只能用Inpainted区域来区分两幅图像。此外,我们还根据Doppelganger降低目标网络相似度的能力,对其进行综合。我们把这种定量评价的综合方法称为Inpaiting Game。
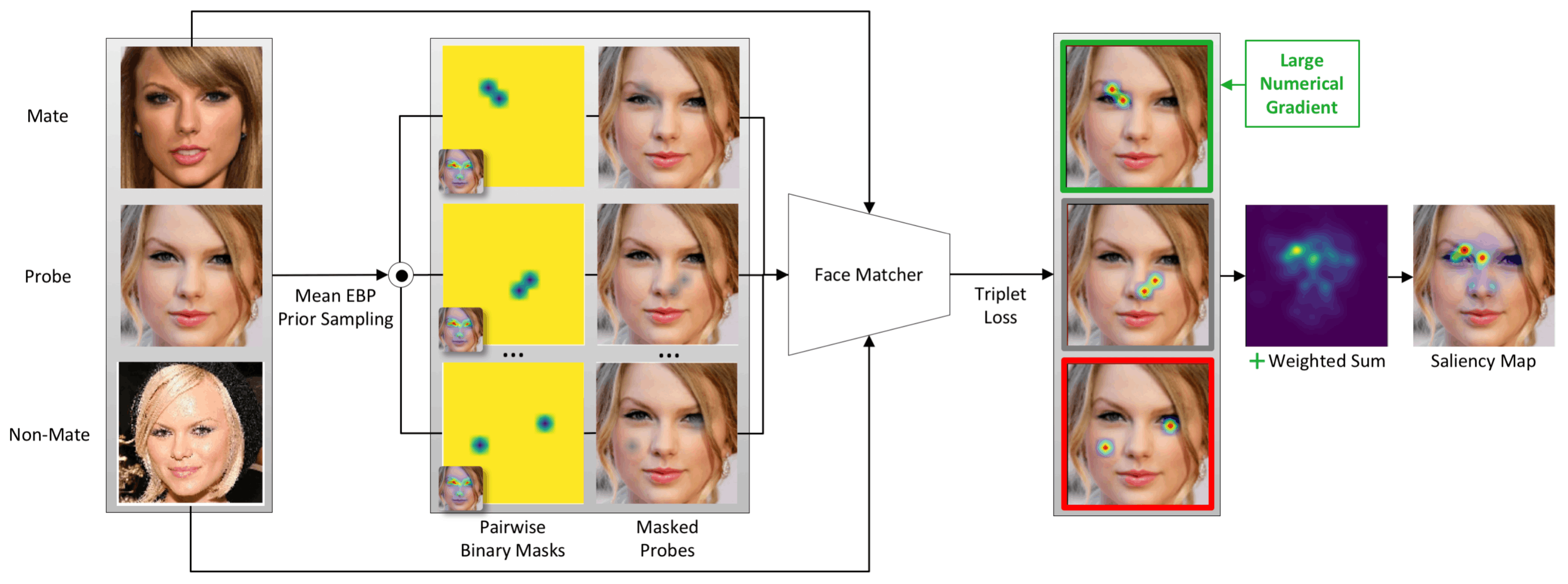
下图是Inpainting Game的概况,每次评价至少使用四张图片:Probe、Mate、Inpainted Probe和Inpainted Nonmate。内画探针和探针分身在脸部的某些部位,如眼睛、鼻子、嘴巴等,与探针有所不同。同样,Inpainted Nonmate或Mate Doppelganger与Mate略有不同。漆质探针和漆质非伴侣是为了成为新的身份而产生的。
XFR算法,给定Probe、Mate和Nonmate的组合,标记为{Mated Probe、Mated Reference、Inpainted Nonmate}。对于每一个组合,我们估计Probe属于可判别区域(像素)的可能性,其中Probe与Mated比Nonmated/Inpainted更相似,并从这些可判别区域(像素)估计形成Saliency Map。
每个像素通过应用一个阈值被分类为一个Salient,从而得到一个二进制Saliency Map。对于每个二进制Saliency Map,探头像素被替换为Inpainted Probe的像素,以创建一个Blended Probe。Inpainted Probe是由Inpainted Nonmates相同的脸部区域生成的,并不提供给用于评估的XFR算法。显著性地图的评估方法是通过平淡探针从Mate到Non-Mate的翻转速度,同时最大限度地提高地面真理(灰色)的显著性(绿色)和最小化误报(红色)。
数据集
Inpainting Game包含从IJB-C数据集中选取的95个主题的561张图片,平均每个主题有5.9张图片。以下面部区域(8)被定义为评估区域。
- 脸颊和下巴
- 喉舌
- 鼻子
- 左眼
- 右眼
- 眉毛
- 脸的左手边
- 脸颊右侧
每张图片都是针对这8个区域分别进行编辑,共形成4488个Inpainted Doppelgangers。然后,我们从这个集合中创建一组3648个三联体,每个组合都是{探针、伴侣和Inpainted Nonmate)。在无法区分Original和Inpaint的网络中,XFR算法无法正确评估。因此,只采用包含可识别ID的组合。
二重身的生成方式如下为了系统地遮挡区域,使用pix2face算法对每张人脸图像进行三维网格拟合,然后将人脸区域的遮挡投影到图像上。然后,我们在蒙版区域上使用多个Inpaints来完成图像。下图是一个编辑过的二重身的例子。前7列是7个主体的原始图像,底部有4个相同的图像。中间一列是一个二进制掩码,定义了要涂抹的区域。而最后7列则逐行显示了使用原图面具Inpaint的二重身。也就是说,Inpainted图像与Original图像仅在遮挡区域有所不同。
前七栏是七个被摄对象的原始图像,最下面是四个相同的图像。中间一列是二进制掩码,定义了要编辑的区域。而最后七列则是用蒙版对照原图编辑的多普勒,一行一行的。即编辑后的图像与原图像仅在遮挡区域有差异。
构建内画数据集的一个重要挑战是将内画ID与其他ID区分开来,在一个给定的网络中,大多数内画图像与原图的相似度没有足够的差异。只有当网络能够区分Mate和Mate二重身以及Probe和Probe二重身时,才会采用创建的组合{Probe,Mate,Inpainted Nonmate}作为数据集。
具体来说,我们对每个组合作为网络的数据集有以下标准。
- 原始探针满足的条件
- 与相应的Inpainted/Nonmated相比,与Original/Mated更为相似。
- 按调整后的阈值正确确定为原件/已定稿
- 喷漆探头所满足的条件
- 与Inpainted/Nonmated ID比Original更相似。
- 按调整后的阈值正确地确定为Inpainted/Nonmated。
根据上述这些标准对每个网络的内画数据集进行过滤,得到的数据集对被检查的网络是唯一的。例如,如果网络是ResNet-101,最终过滤后的数据集将采用84个ID和543个组合。一般来说,识别性能较差的网络比性能较高的网络符合标准的组合会少一些。
评价方法
XFR算法估计,对于每个像素,可分辨区域的可能性,以匹配Probe到Mated而不是Nonmate/Inpainted。这些对可辨别区域可能性的估计,通过估计最亮的区域最有可能属于可辨别区域,形成了一个Saliency Map。
考虑到作为一种典型的ROC曲线评价方法,可以通过扫除估计像素存在的阈值来生成ROC曲线,并且油漆阳性/阳性区域,油漆我们可以通过将非敏感区域设为负值/非敏感区域来计算真接受率和误报率。然而,并不是所有非敏感区域的像素都对该身分有同等贡献。因此,在本文中,我们采用平均非伴侣分类率代替真阳性率进行Saliency分类。
在本文中,我们已经测试了使用一个Blend Probe,通过扫描Saliency阈值,用Saliency算法中没有提供的未涂抹的探针的像素来替换被分类为高Saliency的像素。根据被测试的网络,该混合探头可分为原厂或未上漆的非伴侣。高性能的XFR算法正确地将更多的Saliency分配给Inpainted区域,并在不增加像素Saliency分类的误报率的情况下修改Blend Probe。
假阳性率是由Saliency分类计算出来的,对所有组合使用混合探头的Ground Truth。平均非伴侣分类率由过滤后的数据集的每个面区域内的组合数量加权,以避免更多样本的子协议偏差。该指标的输出曲线示例见下节。
实验结果
利用三种CNN(LightCNN、VGGFace2 ResNet-50、ResNet-101)和五种XFR算法(DISE、Subtree EBP、Mean EBP、Contrastive EBP、Truncated cEBP),Inpainting这是游戏公司的业绩评价。在CNN中,我们通过应用不同深度的CNN来考察网络深度的影响。在XFR算法中,DISE和Subtree EBP是本文提出的新算法,而Mean EBP、Contrastive EBP和Truncated cEBP是最新的算法,已被报道为高精度算法。我们将Impainting Game应用于这些模型,结果如下图所示。这里我们特别展示两个网络。

总的来说,可以看出,当应用较深的CNN(ResNet-50)时,DISE的性能较高;当应用较浅的CNN(LightCNN)时,Subtree EBP的性能较高。两种算法的性能明显优于传统算法(EBP、cEBP和tcEBP)。
我们还在ResNet-101中单独评估每个面部区域。这里我们展示了编辑了眉毛的Doppelganger的DISE和SubtreeEBP结果。更少的红色像素意味着最多的结果。可以看出,DISE对于XFR算法识别眉毛的细微差异比较好。
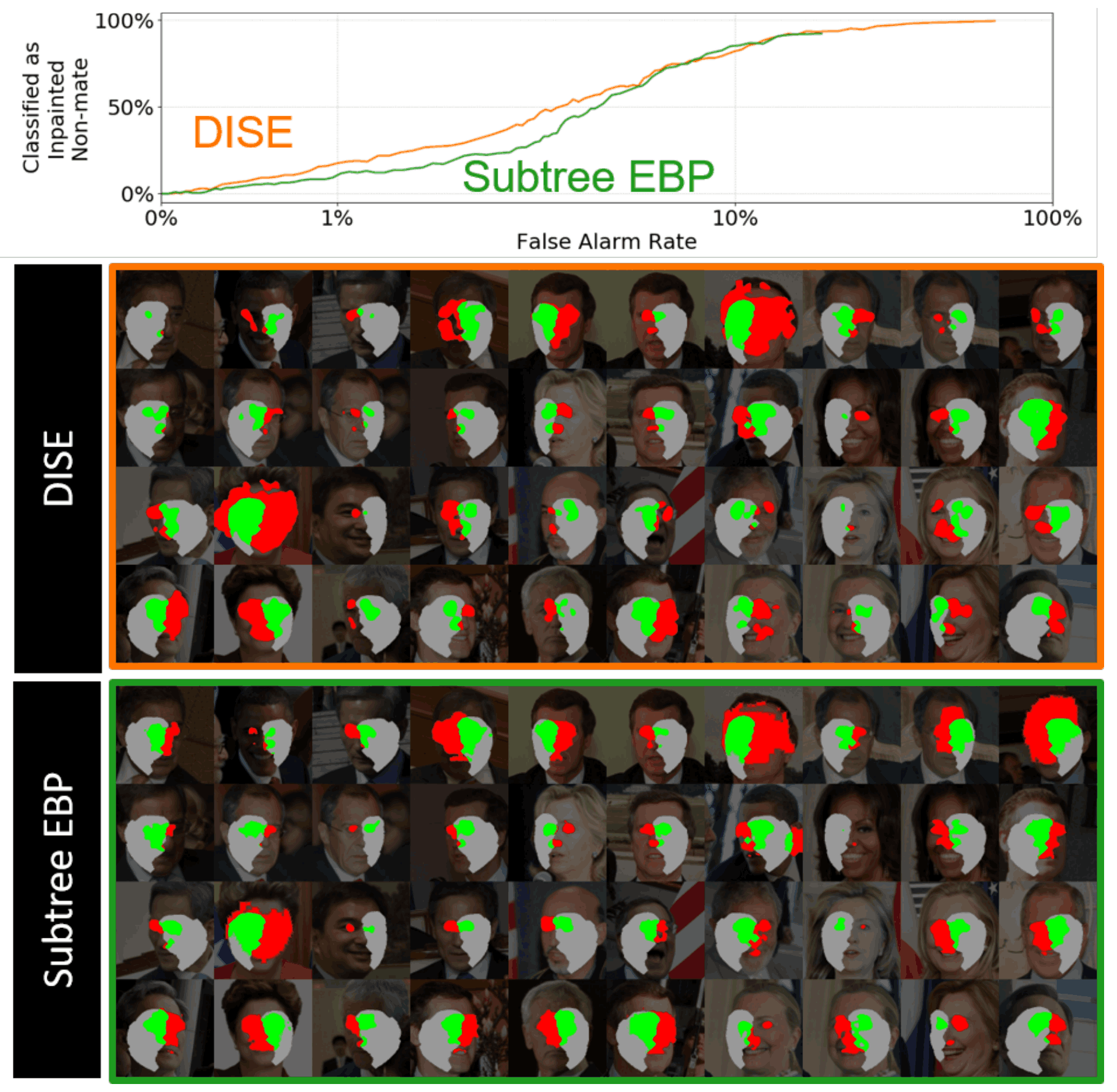
眉毛以外的其他部位被编辑后,差别就没有那么大了。例如,下图显示了左、右面被编辑后运行XFR算法的结果。两种XFR算法都将难以检测出修正后的不对称变化。
总结
论文引入了一种名为Inpainting Game的新的定量方法来比较XFR算法,并提供了第一个可解释人脸识别(XFR)的综合基准。他们还提出了一种新的XFR算法(Subtree EBP,DISE),发现它比现有的算法在性能上有明显的提高。
另一方面,本文的补充验证(详见补充材料)也表明,目前的XFR算法在相似度较高的情况下,可能无法准确地可视化识别原因(精度有限)。
然而,由于现在可以进行这种定量评估,这项研究可能会导致未来进一步研究和开发更准确的XFR,从而使面部识别能够在更广泛的情况下支持人们做出重要决定。在需要可解释的人工智能的背景下,这可能会继续成为一个重点领域。