目录
三、Hbase

Hbase是基于Hadoop的开源分布式数据库,它以Google的BigTable为原型,设计并实现了具有高可靠性 、高性能 、列存储 、可伸缩 、实时读写的分布式数据库系统。
- HBase适合于存储非结构化数据
- Hbase是基于列的而不是基于行的模式
- Hbase在Hadoop之上提供了类似于BigTable的能力
(一)Hbase简介
1、Hbase数据模型

称用户对数据的组织形式为数据的逻辑模型,称Hbase里数据在HDFS上的具体存储形式为数据的物理模型。
(1)逻辑模型
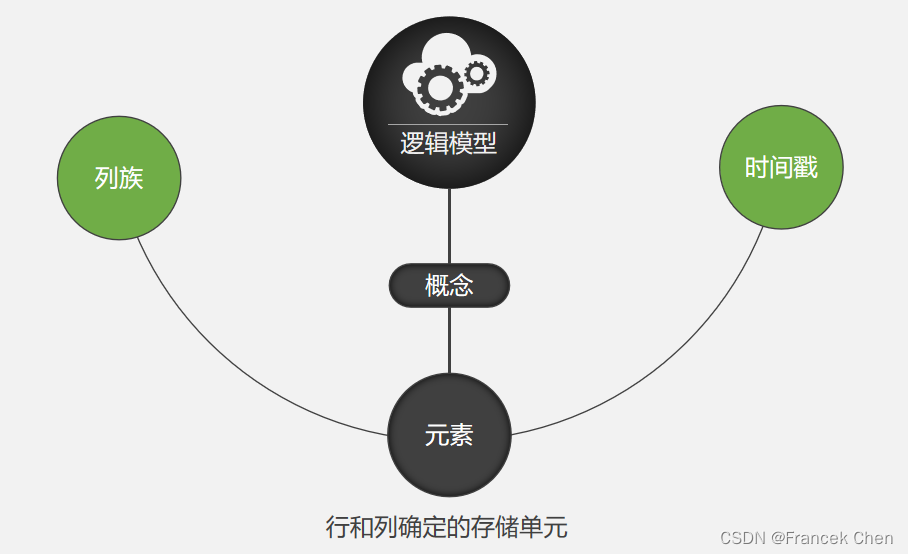
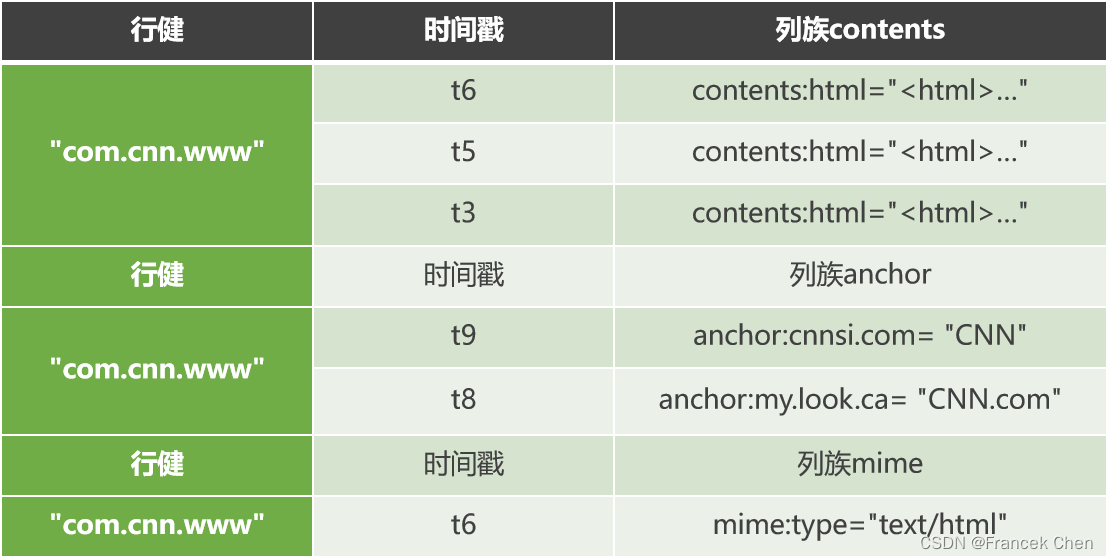
Hbase以表的形式存储。表中仅有一行数据,行的唯一标识为com.cnn.www,对这行数据的每一次逻辑修改都有一个时间戳关联对应。表中共有四列:contents:html,anchor:cnnsi.com,anchor:my.look.ca,mime:type,每一列以前缀的方式给出其所属的列族。
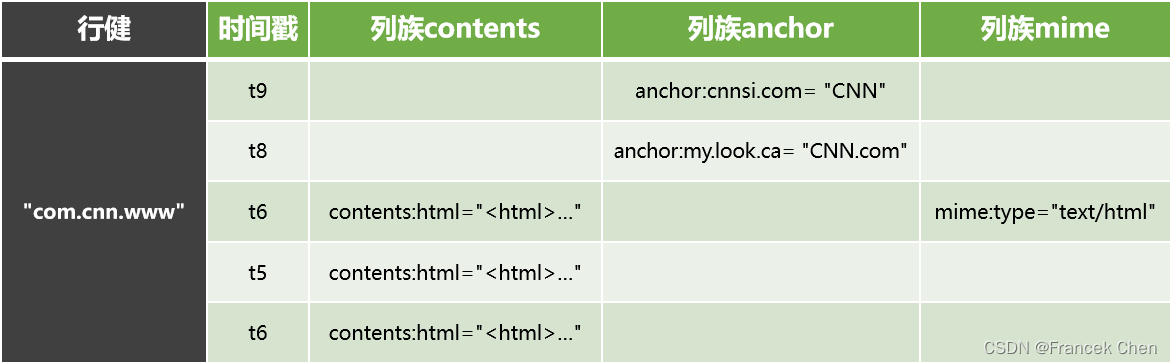
行键是数据行在表中的唯一标识,并作为检索记录的主键。在Hbase中访问表中的行有三种方式:通过单个行健访问、给定行健的范围访问、全表扫描。
Hbase提供了两个版本的回收方式:一是对每个数据单元,只存储指定个数的最新版本;二是保存最近一段时间内的版本(如七天),客户端可以按需查询。
元素由行健、列(<列族>:<限定符>)和时间戳唯一确定,元素中的数据以字节码的形式存储,没有类型之分。
(2)物理模型

Hbase是按照列存储的稀疏行/列矩阵。表中的空值是不被存储的,如果没有指名时间戳,则返回指定列的最新数据值,可以随时向表中的任何一个列添加新列,而不需要事先声明。
2、Hbase架构
Hbase采用master/slave架构,主节点运行的服务称为HMaster,从节点服务称为HRegionServer,底层采用HDFS存储数据。
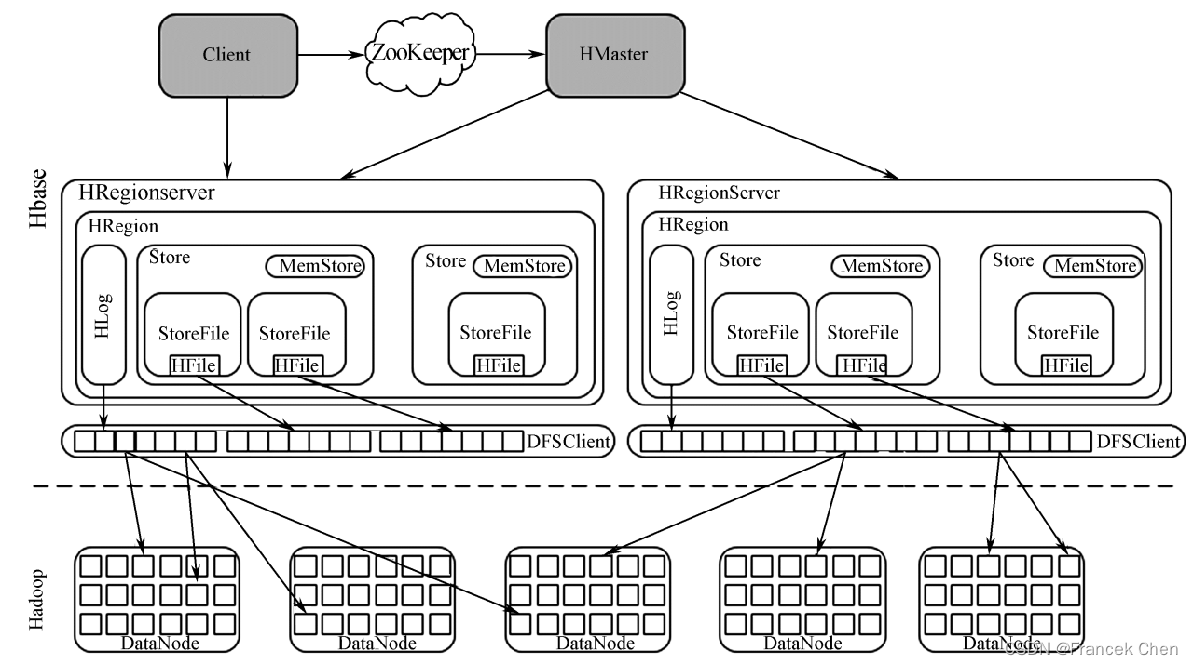
(1)Client
Client端使用Hbase的RPC机制与HMaster和HRegionServer进行通信。
(2)ZooKeeper
存储了ROOT表的地址、HMaster的地址和HRegionServer地址。
(3)HMaster
Hbase主节点,将Region分配给HRegionServer,协调HRegionServer的负载并维护集群状态。
(4)HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据。
(二)Hbase入门
1、Hbase部署
(1)部署前提
除了要求集群已安装cloudera-cdh-5-0.x86_64.rpm外,Hbase 还要求集群已部署好ZooKeeper集群和Hadoop集群。
(2)Hbase部署规划
cMaster为Hbase主节点,cSlave0~2为Hbase从节点,iClient安装Hbase客户端。
(3)部署Hbase
[root@iClient ~]# sudo yum install hbase #iClient安装Hbase客户端
[root@cMaster ~]# sudo yum install hbase-master #cMaster安装主服务HMaster
[root@cSlave0 ~]# sudo yum install hbase-regionserver #cSlave0安装从服务
[root@cSlave1 ~]# sudo yum install hbase-regionserver #cSlave1安装从服务
[root@cSlave2 ~]# sudo yum install hbase-regionserver #cSlave2安装从服务(4)配置Hbase
编辑/etc/hbase/conf/hbase-site.xml将下面内容添加到configuration便笺切记iClient,cMaster,cSlave0~2这五台机器都要进行配置,且要求配置相同。
<property><name>hbase.cluster.distributed</name><value>true</value></property>
<property><name>hbase.rootdir</name><value>hdfs://CMaster:8020/hbase</value></property>
<property>
<name>hbase.zookeeper.quorum</name><value>cSlave0,cSlave1,cSlave2</value>
</property>(5)HDFS里新建Hbase存储目录
[root@iClient ~]# sudo -u hdfs hdfs dfs -mkdir /hbase
[root@iClient ~]# sudo -u hdfs hdfs dfs chown -R hbase /hbase(6)启动Hbase集群
共分三步,即启动ZooKeeper集群(参考ZooKeeper部署),启动主服务HMaster和启动从服务HRegionServer。
[root@cMaster ~]# sudo service hbase-master start #cMaster开启主服务命令
$ sudo service hbase-regionserver start #cSlave0,cSlave1,cSlave2开启regionserverHbase启动好后,在iClient上浏览器打开"cMaster:60010",即可以看到Hbase的Web页面。
2、Hbase接口
Hbase提供了诸多访问接口,下面简单罗列各种访问接口。
(1)Native Java API:最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理Hbase表数据。
(2)Hbase Shell:Hbase的命令行工具,最简单的接口,适合管理、测试时使用。
(3)Thrift Gateway:利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问Hbase表数据。
(4)REST Gateway:支持REST 风格的HTTP API访问Hbase,解除了语言限制。
(5)Pig:可以使用Pig Latin流式编程语言操作Hbase中的数据,和Hive类似,本质上最终也是编译成MR Job来处理Hbase表数据,适合做数据统计。
(6)Hive:同Pig类似,用户可以使用类SQL的HiveQL语言处理Hbase表中数据,当然最终本质依旧是HDFS与MR操作。
【例2】 按要求完成问题:
① 假定MySQL里有member表,要求使用Hbase的Shell接口,在Hbase中新建并存储此表。
② 简述Hbase是否适合存储问题①中的结构化数据,并简单叙述Hbase与关系型数据库的区别。
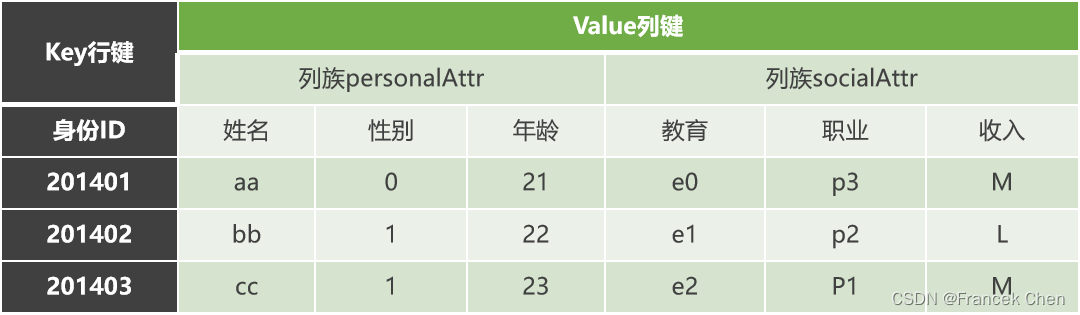
| 身份ID | 姓名 | 性别 | 年龄 | 教育 | 职业 | 收入 |
|---|---|---|---|---|---|---|
| 201401 | aa | 0 | 21 | e0 | p3 | m |
| 201402 | bb | 1 | 22 | e1 | p2 | 1 |
| 201403 | cc | 1 | 23 | e2 | p1 | m |
解:
下面将姓名、性别、年龄这三个字段抽象为个人属性(personalAttr),教育、职业、收入抽象为社会属性(socialAttr),personalAttr列族包含name、gender和age三个限定符;同理socialAttr下包含edu、prof、inco三个限定符。
按上述思路,iClient上依次执行如下命令:
[root@iClient ~]# hbase shell #进入Hbase命令行
hbase(main):001:0> list #查看所有表
hbase(main):002:0> create 'member','id','personalAttr','socialAttr' #创建member表
hbase(main):003:0> list
hbase(main):004:0> scan 'member' #查看member内容
hbase(main):005:0> put 'member','201401','personalAttr:name','aa' #向member表中插入数据
hbase(main):006:0> put 'member','201401','personalAttr:gender','0'
hbase(main):007:0> put 'member','201401','personalAttr:age','21'
hbase(main):008:0> put 'member','201401','socialAttr:edu','e0'
hbase(main):009:0> put 'member','201401','socialAttr:job','p3'
hbase(main):010:0> put 'member','201401','socialAttr:imcome','m'
hbase(main):011:0> scan 'member'
hbase(main):012:0> disable 'member' #废弃member表
hbase(main):013:0> drop 'member' #删除member表
hbase(main):014:0> quit下面简单罗列Hbase和关系型数据库的区别:
- Hbase只提供字符串这一种数据类型,其他数据类型的操作只能靠用户自行处理,而关系型数据库有丰富的数据类型;
- Hbase数据操作只有很简单的插入、查询、删除、修改、清空等操作,不能实现表与表关联操作,而关系型数据库有大量此类SQL语句和函数;
- Hbase基于列式存储,每个列族都由几个文件保存,不同列族的文件是分离的,关系型数据库基于表格设计和行模式保存;
- Hbase修改和删除数据实现上是插入带有特殊标记的新记录,而关系型数据库是数据内容的替换和修改;
- Hbase为分布式而设计,可通过增加机器实现性能和数据增长,而关系型数据库很难做到这一点。
四、Pig
(一)Pig简介
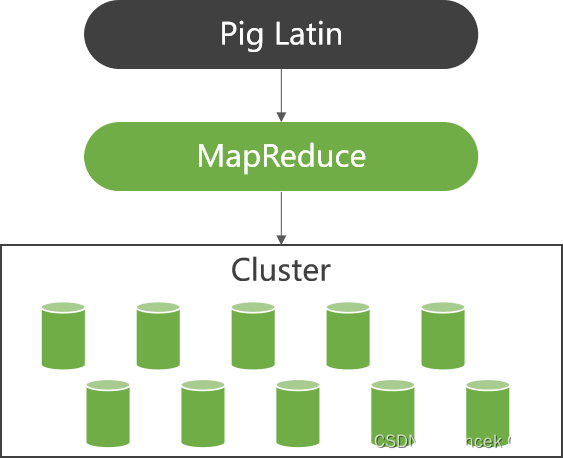
1、Pig基本框架
Pig相当于一个Hadoop的客户端,它先连接到Hadoop集群,之后才能在集群上进行各种操作。Pig的基本框架如下图所示。
2、Pig语法
(1)Pig Latin数据类型
① 基本数据类型
和大部分程序语言类似,Pig的基本数据类型为int、long、float、double、chararray和bytearray。
② 复杂数据类型
字符串或基本类型与字符串的组合,主要包含以下四种。Filed、Tuple、Bag、Map。
(2)Pig Latin运算符
Pig Latin提供了算术、比较、关系等运算符,这些运算符的含义和用法与其他语言(C,Java)相差不大。算术运算符包括加 (+),减 (-),乘 (*),除 (/),取余 (%) 和三目运算符(?:)。比较运算符包括等于 (==),不等 (!=)。
(3)Pig Latin函数
Pig Latin是由一系列函数(命令)构成的数据处理流,这些函数或是内置或是用户自定义,下表是最常用的几个命令。
| 操作名称 | 功能 |
|---|---|
| LOAD | 载入待处理数据 |
| FOREACH | 逐行处理Tuple |
| FILTER | 过滤不满足条件的Tuple |
| DUMP | 将结果打印到屏幕 |
| STORE | 将结果保存到文件 |
(二)Pig入门
1、Pig部署
由于Pig只相当于Hadoop的一个客户端,用户所写的Pig Latin经翻译器翻译后再提交集群执行,故只要在客户机上部署Pig即可。
[root@iClient ~]# sudo yum install pig2、Pig访问接口
Pig提供了类Shell方式的访问接口,用户在Linux Shell下输入Pig,然后回车即可进入Pig命令行接口(即grunt)。
【例3】 按要求完成问题:① 进入Pig命令行,查看并练习常用命令。② 使用Pig Latin实现WordCount。
解:
问题①即在Pig命令行中输入help即可。对于问题②假定cMaster上存在用户joe,并且joe用户在HDFS里有文件夹input(即相对路径为input,绝对路径为/user/joe/input),此目录下有一些文本文件,现用Pig实现此文件夹下所有文件里单词计数。
[root@iClient ~]# sudo -u joe pig #进入joe用户的Pig命令行
grunt> help; #查看Pig操作
grunt> A=load 'input; #载入待处理文件夹input
grunt> B=foreach A generate flatten(TOKENIZE((chararray)$0)) as word; #划分单词
grunt> C=group B by word; #指定按单词聚合,即同一个单词到一起
grunt> D=foreach C generate COUNT(B),group; #同一个单词出现次数相加
grunt> store D into 'out/wc-19'; #将处理好的文件存入HDFS下/user/joe/out/wc-19
grunt> dump D into; #将处理结果D打印到屏幕执行时,用户可以将结果存入HDFS,也可以将结果打印到屏幕,并且,只有最后两条语句才会触发MapReduce程序,这种"懒"策略有利于提高集群利用率。