代码及数据集下载传送门
数据分析与可视化-朝阳医院2018销售数据-ipynb+csv
实践内容
以朝阳医院2018年销售数据为例,目的是了解朝阳医院在2018年里的销售情况,这就需要知道几个业务指标,本次的分析目标是从销售数据中分析出以下业务指标:
(1)业务指标1:月均消费次数
月均消费次数 = 总消费次数 / 月份数(同一天内,同一个人所有消费算作一次消费)
(2)业务指标2:月均消费金额
月均消费金额 = 总消费金额 / 月份数
(3)客单价
客单价 = 总消费金额 / 总消费次数
(4)消费趋势(可视化展示,并根据可视化结果给出下属问题分析得出的结论)
a、分析每天的消费金额
b、分析每月的消费金额
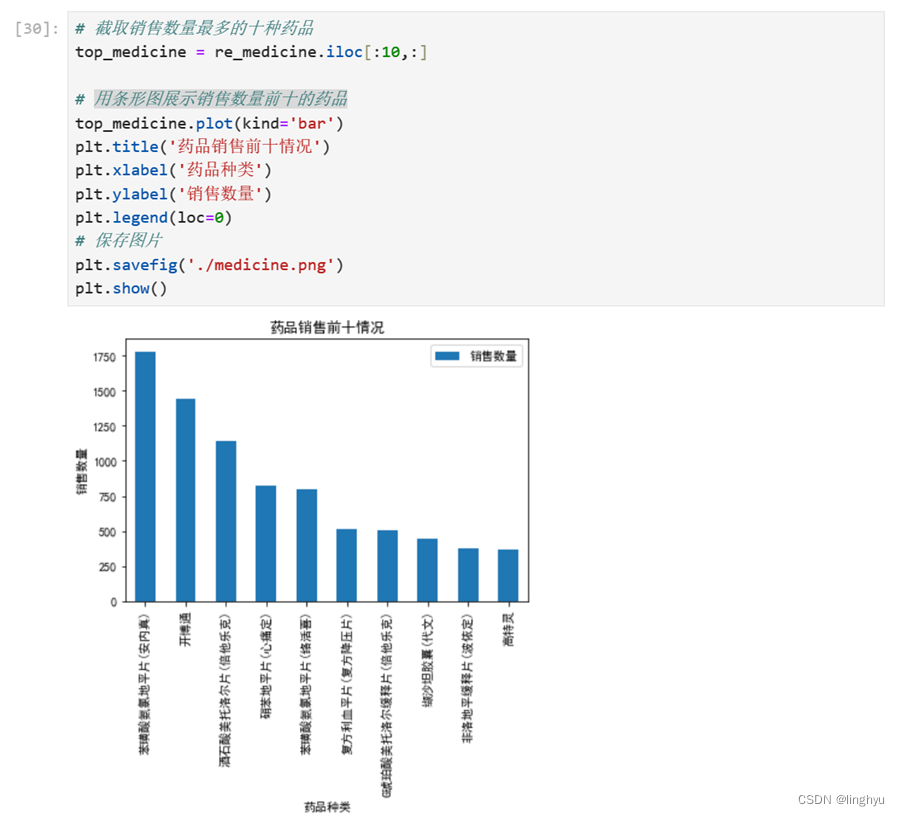
c、分析药品销售情况(截取销售数量最多的前十种药品,并用条形图展示结果)
数据分析基本过程 数据分析基本过程包括:获取数据、数据清洗、构建模型、数据可视化以及消费趋势分析。
过程及结果
数据获取
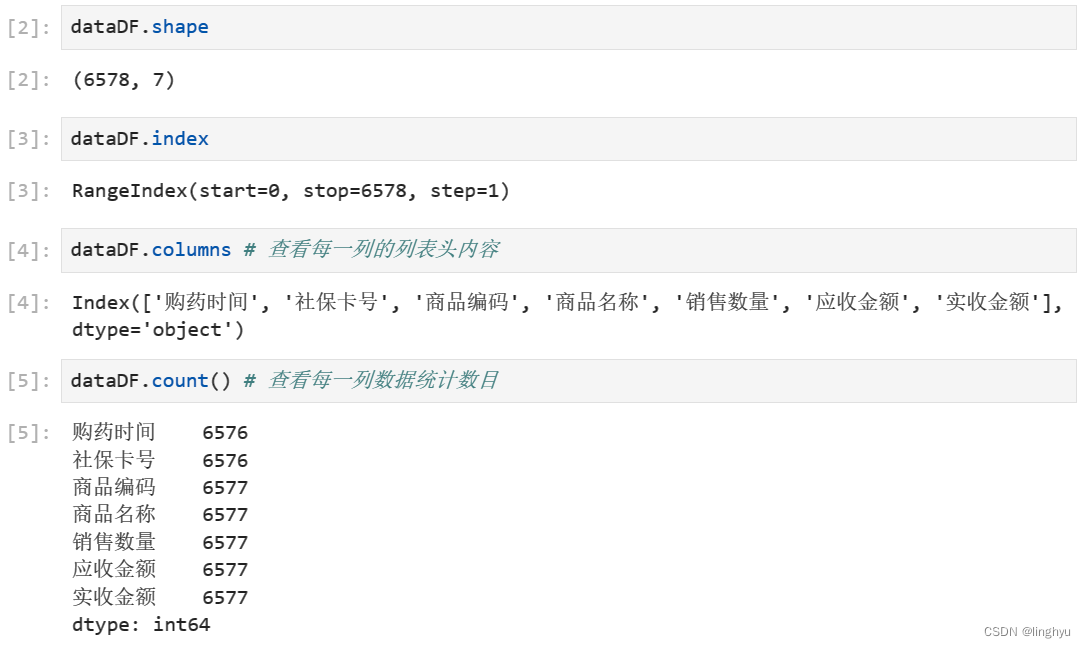
- 导入pandas库并读取数据,修改为DataFrame格式

- 描述数据
使用shape方法查看数据形状;使用columns方法查看每一列的列表头内容;使用count()方法# 查看每一列数据统计数目
数据分析:数据清洗过程包括:选择子集、列名重命名、缺失数据处理、数据类型转换、数据排序及异常值处理。
- 列明重命名
使用 rename 函数,把"购药时间" 改为 "销售时间"

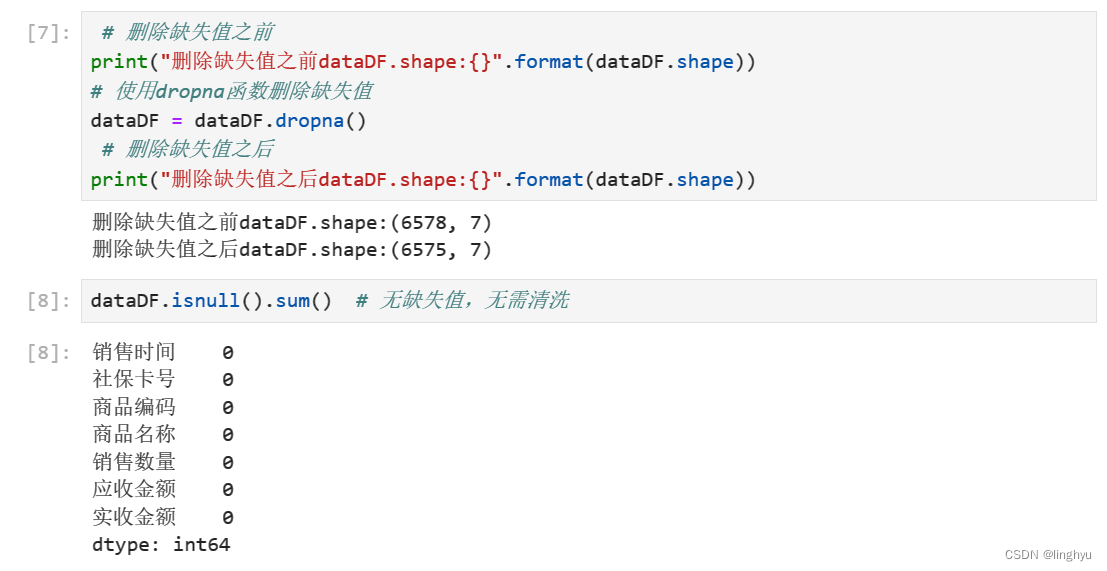
- 缺失数据处理
使用dropna函数删除缺失值
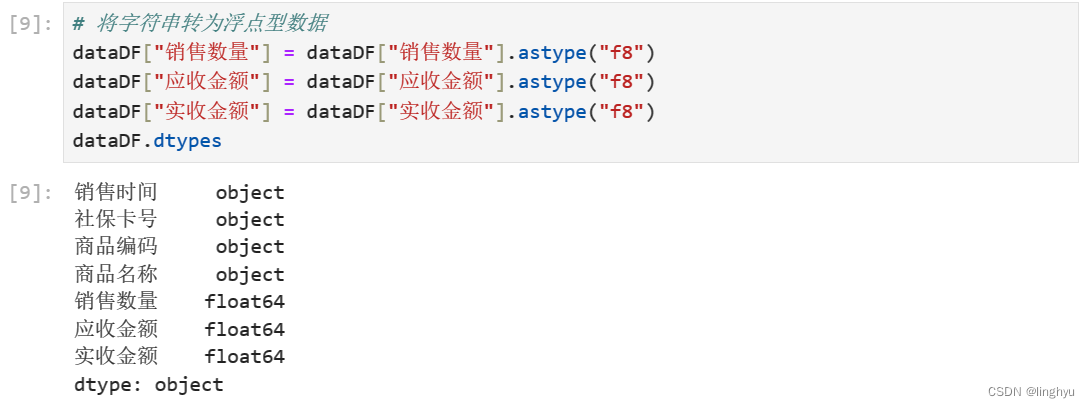
- 数据类型转换
将字符串转为浮点型数据
字符串转日期
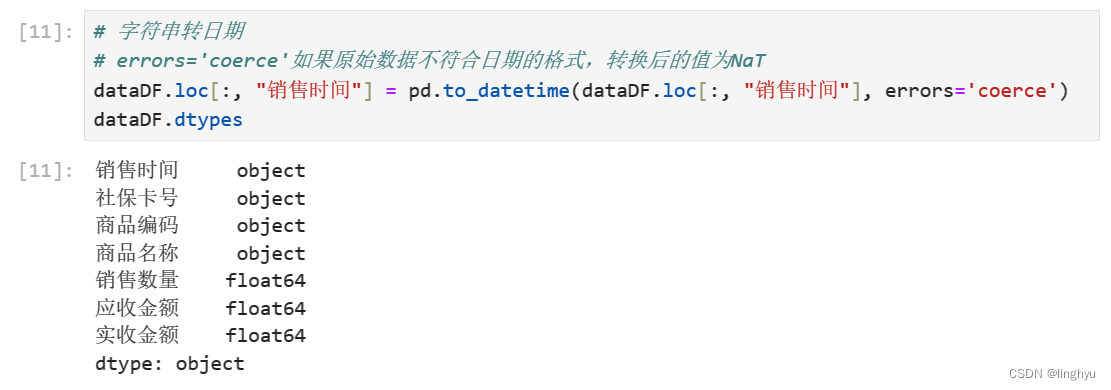
转换日期过程中不符合日期格式的数值会被转换为空值None,进行删除

- 特征化处理
将列表转行为一维数据Series类型, 获取"销售时间"这一列数据, 调用函数去除星期,获取日期进行修改
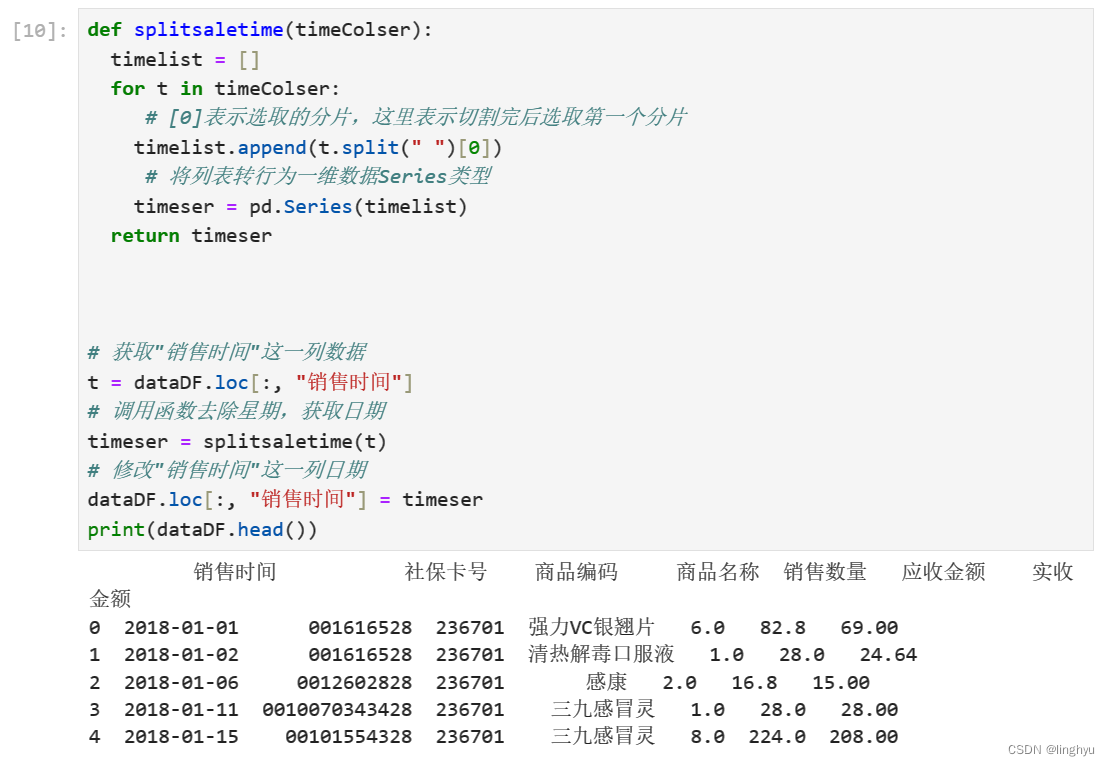
- 数据排序
按销售时间进行升序排序
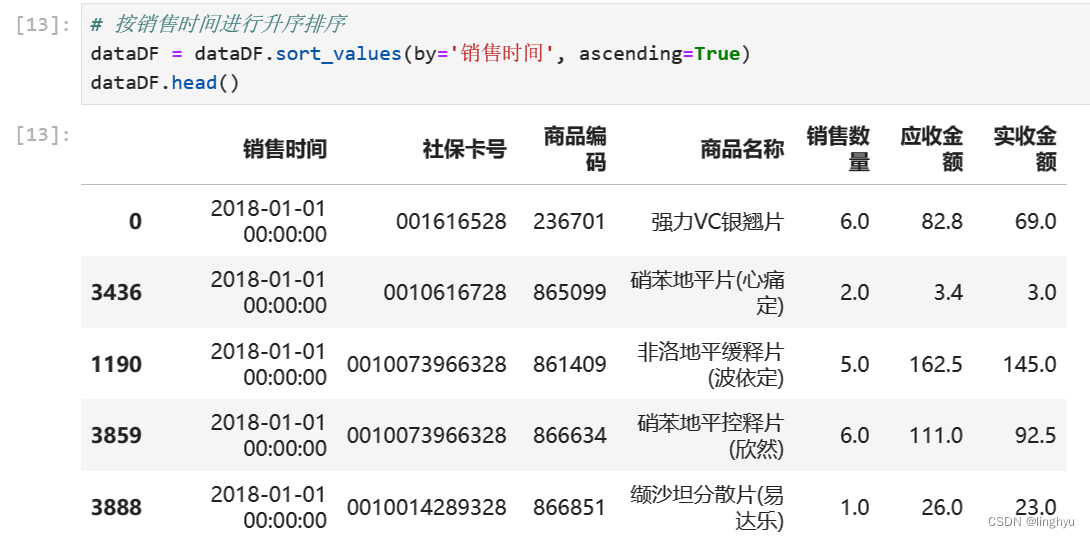
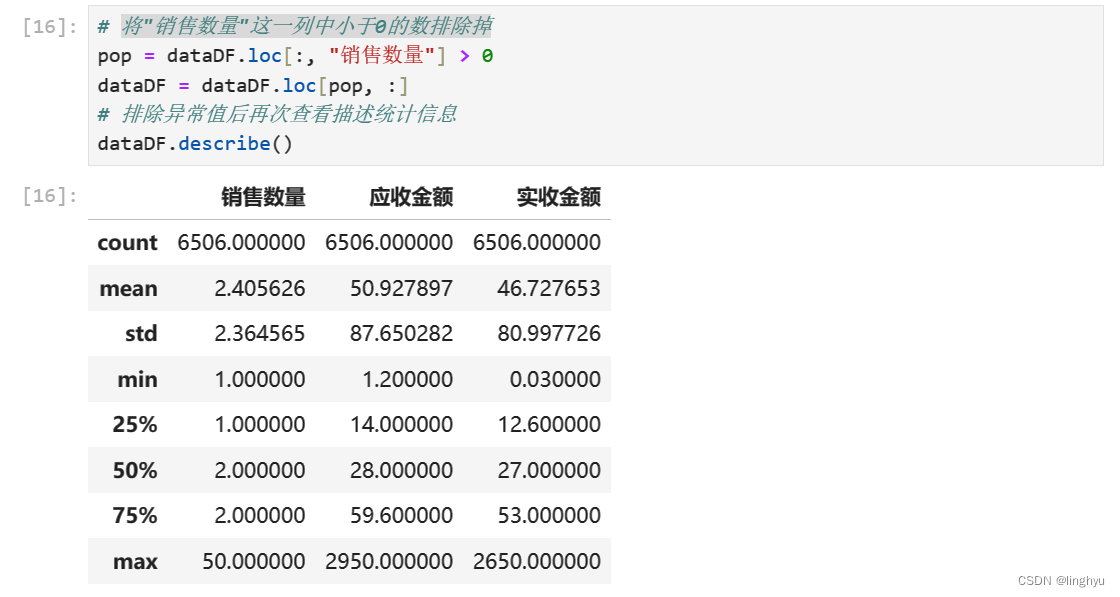
- 重置索引处理,查看描述统计信息
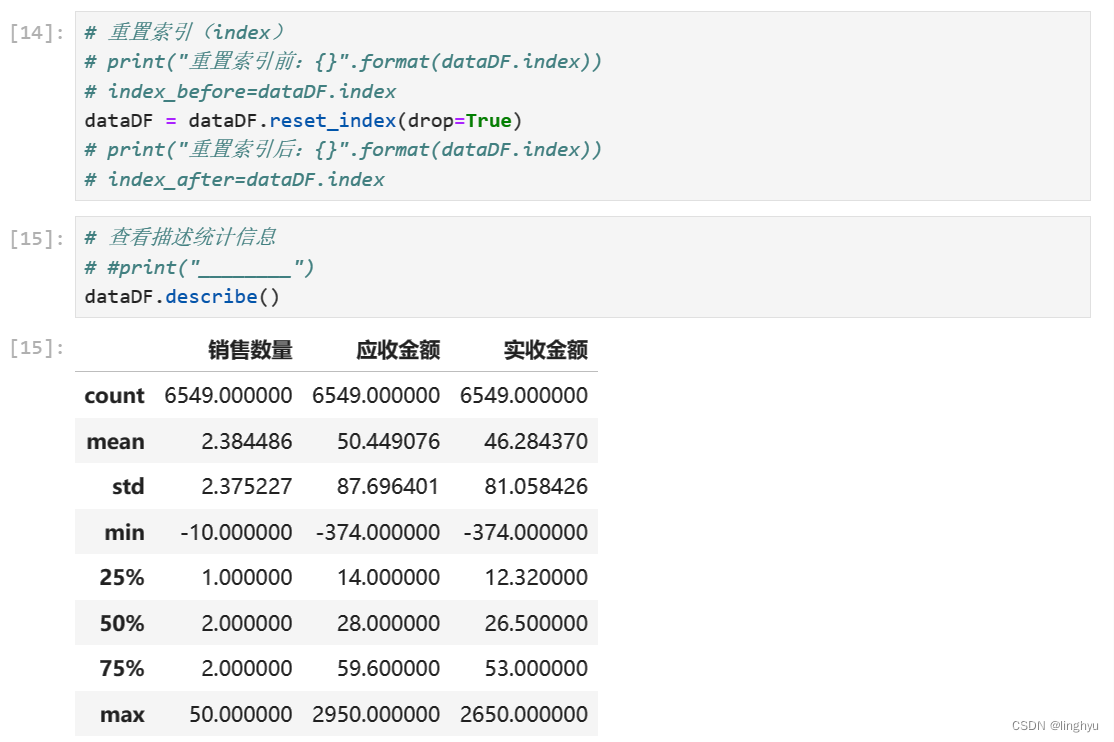
- 异常值处理
将"销售数量"这一列中小于0的数排除掉
构建模型及数据可视化 数据清洗完成后,需要利用数据构建模型(就是计算相应的业务指标),并用可视化的方式呈现结果。
- 删除重复数据后,计算总消费次数
使用.drop_duplicates方法清洗数据,查询数据有多少行

- 按销售时间升序排序
使用sort_values方法和reset_index方法

- 获取时间范围
分别获取最小最大时间值进行整除运算

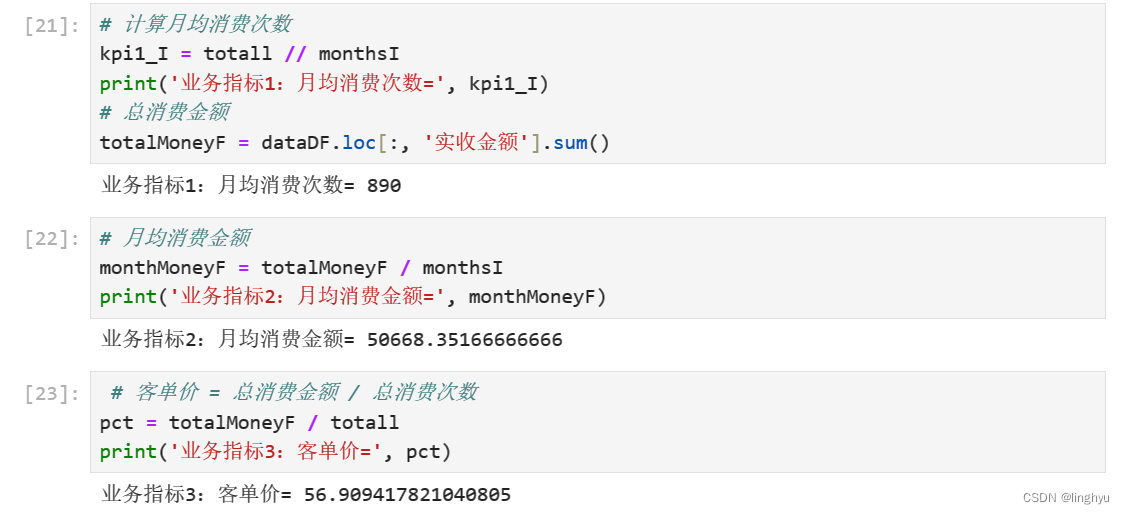
- 计算业务指标
月均消费次数 = 总消费次数 / 月份数(同一天内,同一个人所有消费算作一次消费)
月均消费金额 = 总消费金额 / 月份数
客单价 = 总消费金额 / 总消费次数
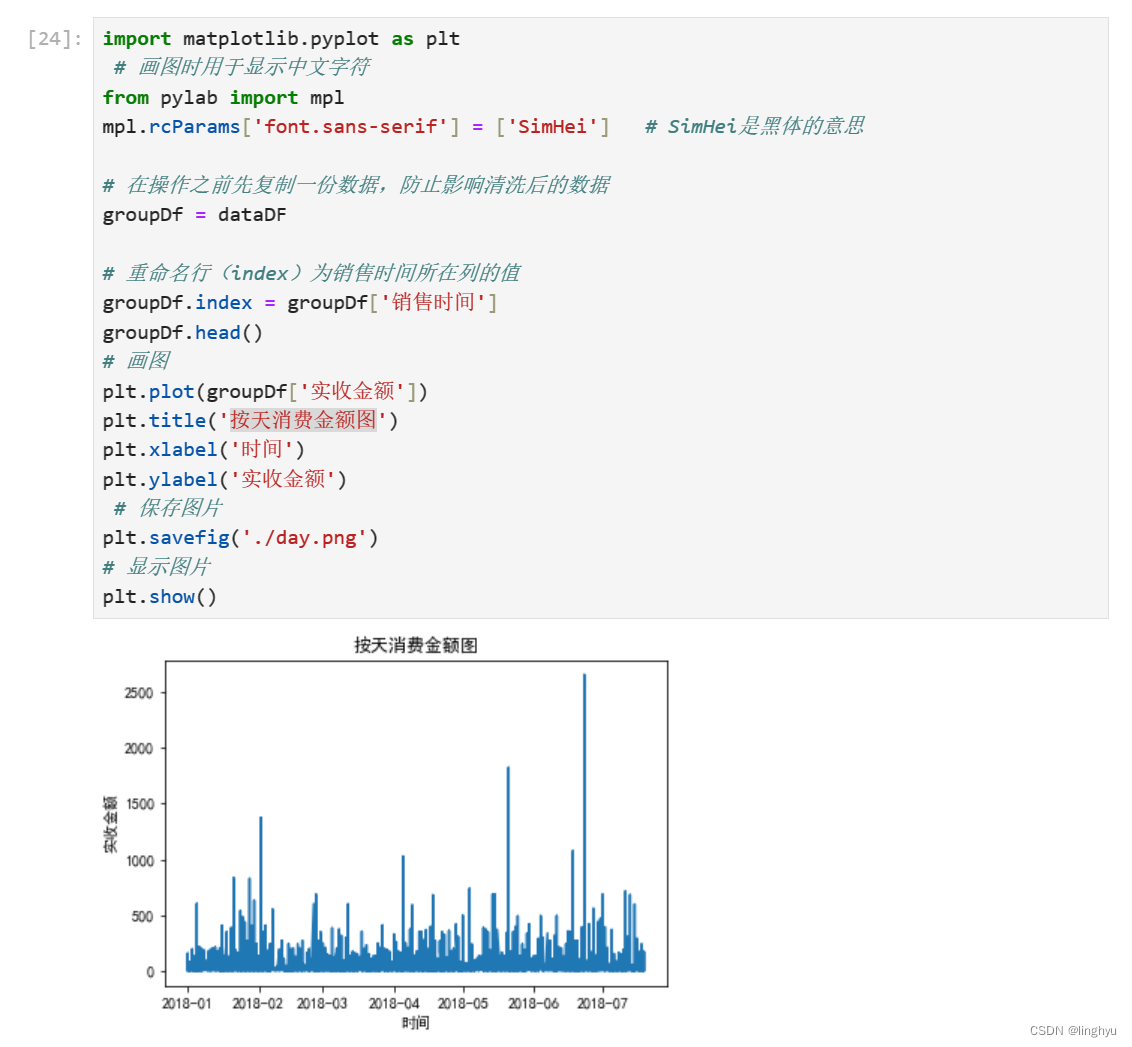
- 按天消费金额可视化
导入所需库,并初始化画图
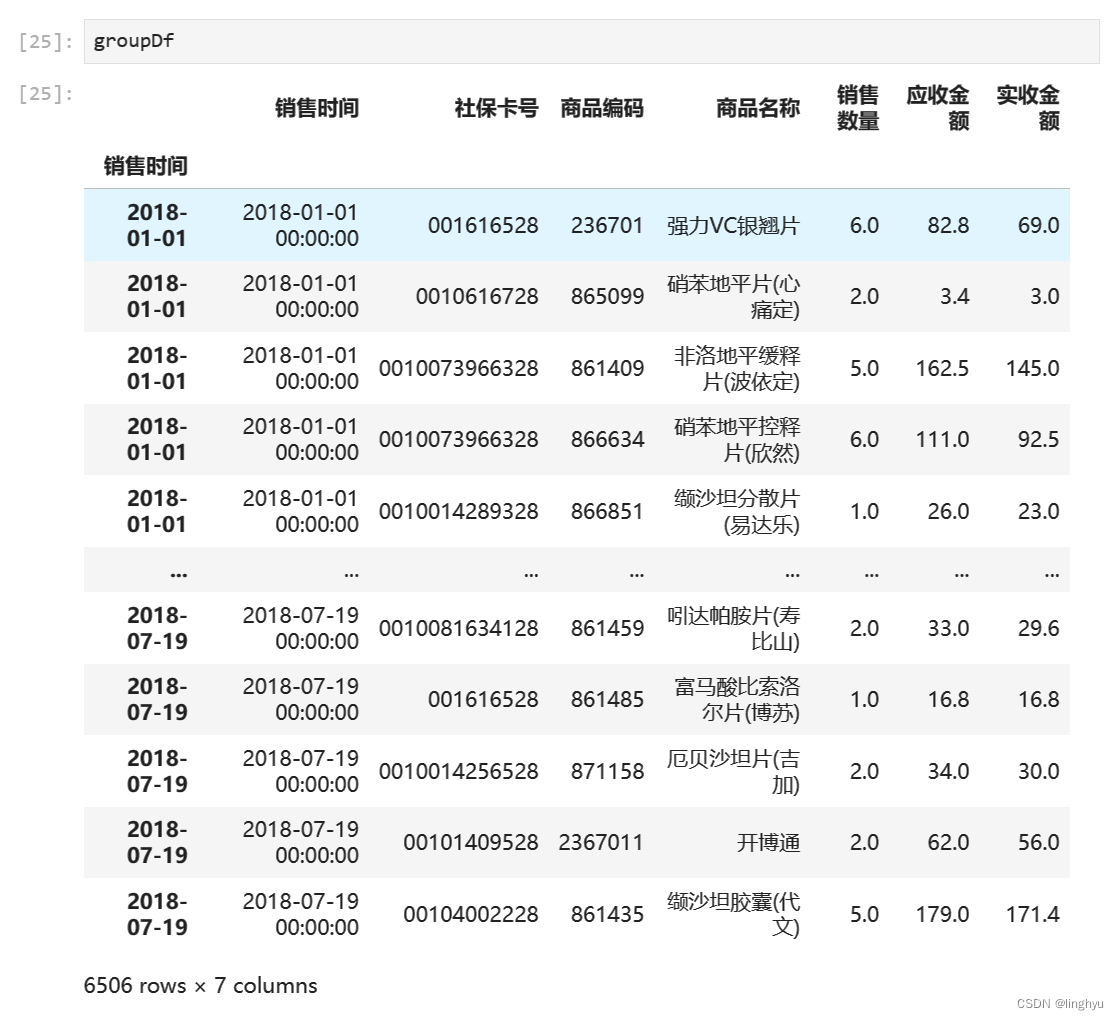
描述对象信息
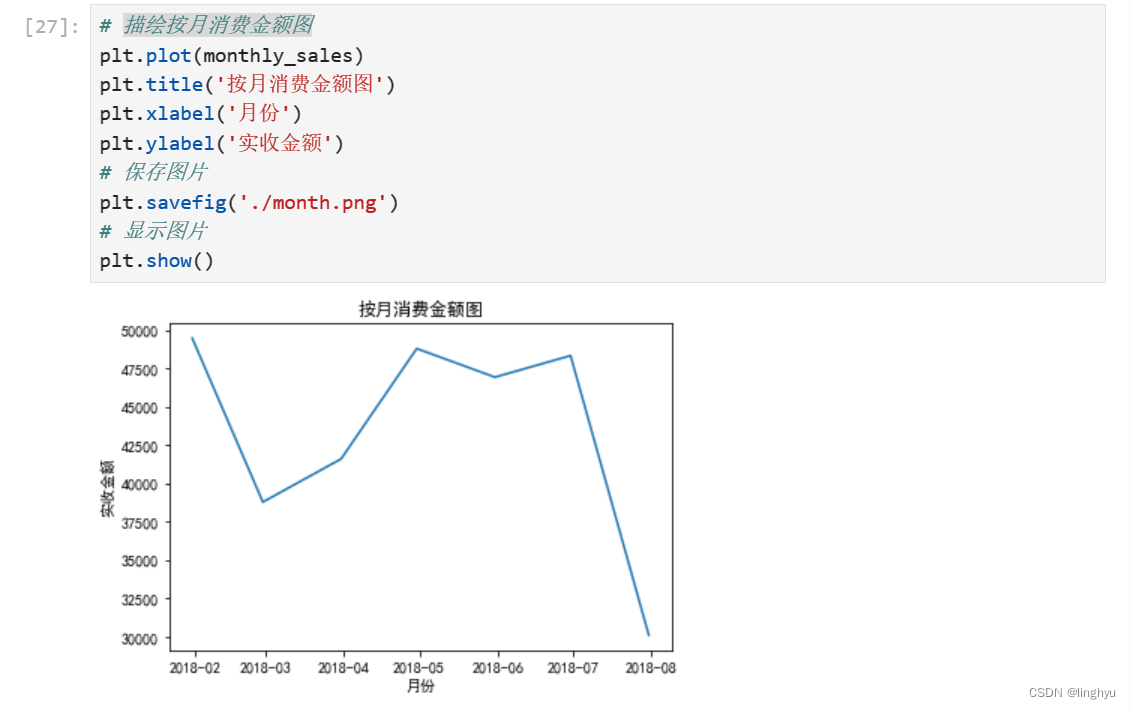
- 按月消费金额可视化
有天消费金额转换为月需要先进行一些处理
将'sale_date'列转换为datetime类型,设置为索引,按月份聚合数据
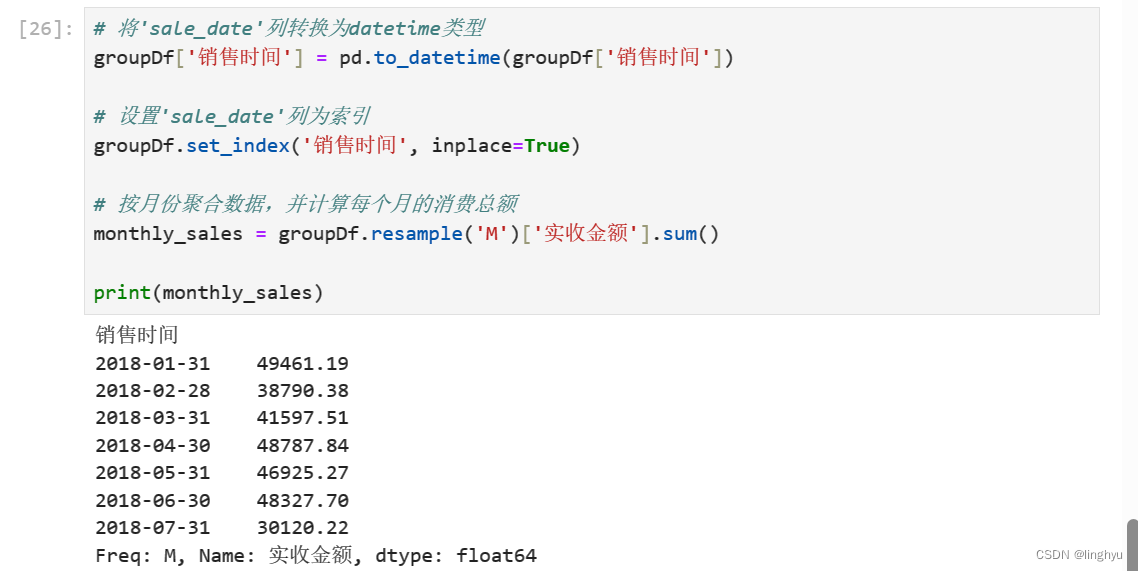
描绘按月消费金额图
- 药品销售前十情况可视化
聚合统计各种药品的销售数量,对药品销售数量按降序排序

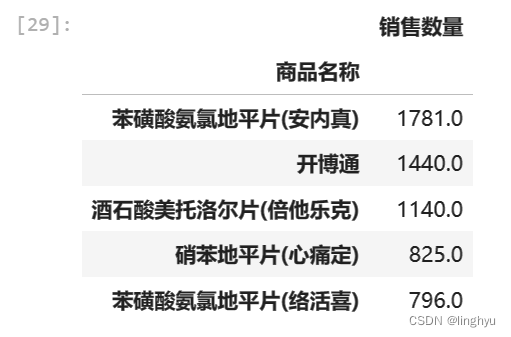
截取销售数量最多的十种药品,用条形图展示销售数量前十的药品