
文章链接:https://arxiv.org/pdf/2405.18172
工程链接:https://colorful-liyu.github.io/anyfit-page/
今天和大家一起学习的是一种名为AnyFit的新型虚拟试穿系统,旨在解决现有技术在处理不同场景和服饰组合时出现的衣物风格不匹配和质量下降问题。通过引入轻量级、可扩展的Hydra Block操作符和并行注意力机制,AnyFit能够有效地将多种服饰特征注入主网络,实现高保真度的试穿效果。此外,通过合成多个模型的残差和实施mask区域增强策略,AnyFit显著提高了模型在真实世界场景中的鲁棒性和表达能力。实验结果表明,AnyFit在高清基准测试和实际数据上均超越了现有技术,能够生成细节丰富且逼真的试穿图像。
主要贡献
确立AnyFit为一种新颖的虚拟试衣(VTON)范式,能够熟练应对各种场景下任意服装组合的挑战,如下图1所示。AnyFit主要由两个同构的U-Net组成,即HydraNet和MainNet。前者负责提取细粒度的服装特征,而后者负责生成试穿效果。

可扩展性:AnyFit的一个显著特点是创新引入了Hydra编码块,仅在共享的HydraNet中并行化注意力矩阵,从而使每增加一个分支参数量仅增加8%,即可轻松扩展到任何数量的条件。这种并行化提案基于以下洞察:只有自注意力层对于隐式变形至关重要,其余组件主要作为通用特征提取器。研究者们进一步发明了Hydra融合块,以无缝整合Hydra编码的特征到MainNet中,并通过位置嵌入区分来自不同来源的编码。需要注意的是,当仅限于单一条件时,ReferenceNet或GarmentNet可以视为HydraNet的特定实例。
稳健性:观察表明,现有虚拟试穿(VTON)工作生成的图像在稳健性和质量上明显低于原始稳定扩散表现。受社区讨论的启发,提出了先验模型演化策略。这种创新方法涉及在模型家族(例如,一系列微调版本的SDXL)内合并参数变化,使得基础模型的多种能力能够独立演化。在训练前放大模型固有潜力,这种策略被证明为直观且高效的方法,特别是当面对双U-Net训练成本显著增加的问题时,这在之前的研究中被忽略。此外,引入了自适应mask增强,以进一步优化服装的合身度。它需要在训练阶段延长无解析mask区域的长度,使模型能够自主理解服装的整体形状,从而摆脱之前依赖于服装mask提示的局限。在推理过程中,根据目标服装的纵横比调整mask区域的形状,从而显著提升试穿效果,特别是对于长款服装(如风衣)。
方法
模型概述
如下图2所示,AnyFit的概述如下。AnyFit的骨干网络采用SDXL。给定一个人像图像 ( x h ∈ R H × W × 3 ) (x_h \in \mathbb{R}^{H \times W \times 3}) (xh∈RH×W×3) 和一个目标服装图像 x g ∈ R H × W × 3 x_g \in \mathbb{R}^{H \times W \times 3} xg∈RH×W×3,AnyFit旨在生成一个逼真的试穿图像 x t r x_{tr} xtr。使用OpenPose来获取无关服装的mask x m x_m xm 和调整不同服装尺寸的遮罩人像图像 x a g x_{ag} xag。将VTON视为图像修补的特例,致力于用服装图像 x g x_g xg 填充遮罩人像 x a g x_{ag} xag。主要的修补U-Net(MainNet)输入3个连接的组件,总计9个通道:噪声图像 z t z_t zt、隐变量图像 E ( x a g ) E(x_{ag}) E(xag) 和调整大小的mask x m x_m xm,其中 E ( ⋅ ) E(\cdot) E(⋅) 代表VAE编码。一个具有4个卷积层(4 ×4 核,2 ×2 步幅,16、32、64、128通道)的姿态引导器被包含进来,以对齐姿态图像 E ( x p ) E(x_p) E(xp) 和噪声 z t z_t zt。
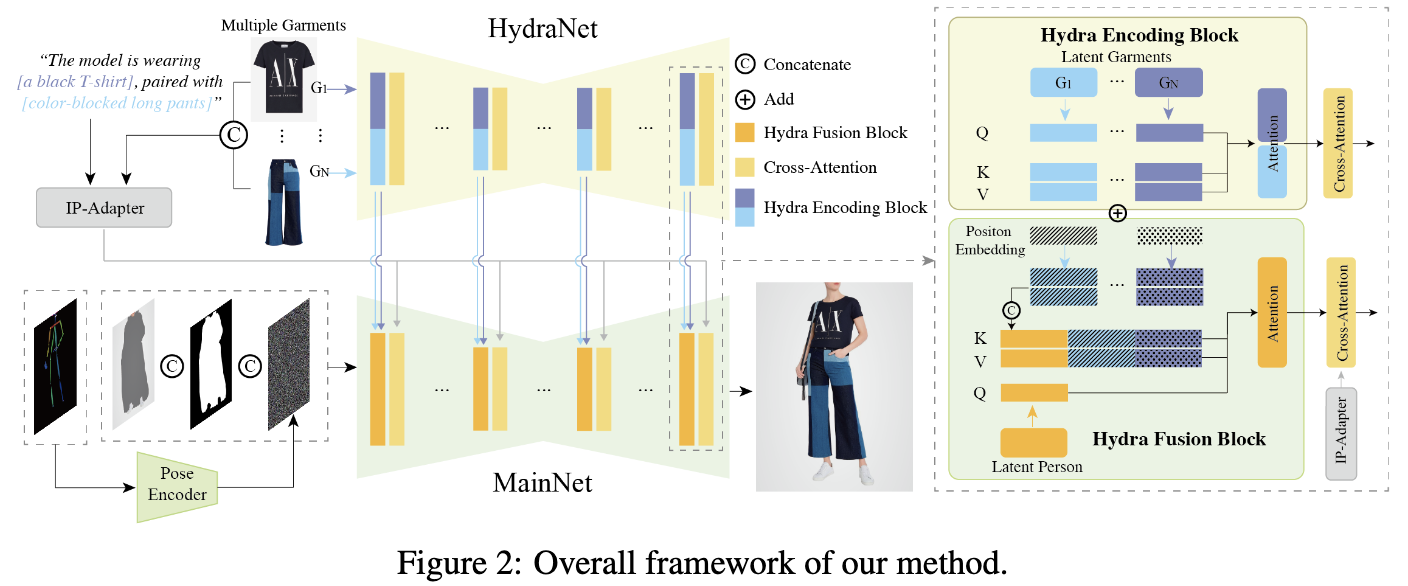
可扩展性:为了保留服装的细节,并支持单件和多件服装的VTON,采用了一个镜像MainNet的HydraNet来编码服装信息。它与MainNet共享相同的权重初始化,并根据条件数量并行化注意力矩阵,创建不同条件编码的Hydra编码块。
稳健性:在训练过程中,观察到mask 信息泄漏和质量下降等问题。为了解决这些问题,分别采用了自适应mask 增强和先验模型演化,这显著增强了模型在不同场景下的稳健性,且成本效益高且简单易行。
HydraNet用于多条件VTON
HydraNet。受在人像编辑领域成功实践的启发,本文引入了一个与主要生成网络(MainNet)同构的服装编码网络,以精确保留服装的细节。在处理多服装VTON时,一个直接的方法可能涉及复制多个服装编码网络以管理不同的条件。然而,这种方法会导致参数数量显著增加,使其计算量过于庞大。实验表明,对于具有相似内容的条件(如不同类型的服装),自注意模块在隐变量变形和将服装对齐到需要修补的位置方面起着至关重要的作用。相反,其他网络结构通常负责一般特征提取,可以在不同条件编码分支之间共享,而不会影响模型的性能。
有鉴于此,创新性地提出了用于多条件编码的HydraNet。它基于共享的Unet结构,并根据输入条件的数量并行化注意模块,从而构建Hydra编码块。具体来说,并行化具有相同初始权重的自注意矩阵,并将多条件键和值特征 { z h k i , z h v i } \{z^i_{hk},z^i_{hv}\} {zhki,zhvi} 输入到MainNet中,以编码服装的细粒度细节。需要注意的是,ReferenceNet或GarmentNet可以被视为限于单一条件的HydraNet特定实例。HydraNet仅需一次前向传播(时间步 t = 0)即可在MainNet的多次去噪步骤之前编码服装,每增加一个条件的额外时间和参数开销都很小,如下表2所示。

Hydra融合 。提出了一种高效且易于扩展的Hydra融合块,以替代MainNet中的自注意层,通过连接实现HydraNet到MainNet的特征注入。具体来说,给定来自HydraNet的键和值特征 { z h k i , z h v i } ∈ R b × l × c \{z^i_{hk},z^i_{hv}\} \in \mathbb{R}^{b \times l \times c} {zhki,zhvi}∈Rb×l×c,引入可学习的位置嵌入来区分来自不同源条件的特征。上标 i i i 表示不同的输入条件。随后,沿 l l l 维度连接键和值,以获得最终的 { z h k a l l , z h v a l l } ∈ R b × N l × c \{z^{all}{hk},z^{all}{hv}\} \in \mathbb{R}^{b \times Nl \times c} {zhkall,zhvall}∈Rb×Nl×c。
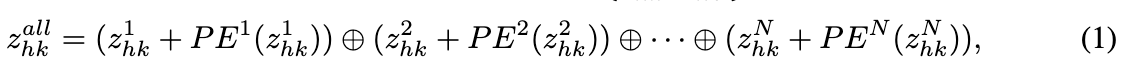
其中 N N N 表示输入条件的总数,PE表示位置编码,⊕表示连接。 z h v a l l z^{all}{hv} zhvall 采用类似的公式。面对来自MainNet的键和值特征 { z m k , z m v } ∈ R b × l × c \{z{mk}, z_{mv}\} \in \mathbb{R}^{b×l×c} {zmk,zmv}∈Rb×l×c 和连接后的HydraNet特征 { z h k a l l , z h v a l l } \{z^{all}{hk}, z^{all}{hv}\} {zhkall,zhvall},再次沿 l l l 维度连接相应特征到 { z c k , z c v } ∈ R b × ( N + 1 ) l × c \{z_{ck}, z_{cv}\} \in \mathbb{R}^{b×(N+1)l×c} {zck,zcv}∈Rb×(N+1)l×c,然后与 z m q z_{mq} zmq 进行后续的注意力计算。值得注意的是,通过利用并行化和连接的轻量化设计,HydraNet可以轻松扩展以执行任何数量条件的注入,从而在生成模型领域具有更广泛的应用潜力。
通过模型演化和mask增强实现稳健的VTON
先验模型演化 。与SDXL基础模型相比,SDXL修补模型的图像生成性能有所下降。研究者们将这种退化归因于修补预训练阶段中先前文本和图像之间的对齐被破坏。受开源社区的启发,开发了一种先验模型演化策略,该策略以极低的成本提升模型在生成服装图像时的强度和适应性,即使无需训练。具体而言,融合了三种不同且强大的模型权重来演化模型初始权重。这些模型包括:SDXL-base-1.0,具有修补能力的SDXL-inpainting-0.1,以及在生成服装和人像方面表现优异的DreamshaperXL alpha2。这些模型的参数权重分别记为 W b a s e , W i n p , W d s W_{base}, W_{inp}, W_{ds} Wbase,Winp,Wds。其演化公式如下:

其中 α \alpha α 和 β \beta β 是平衡系数,用于调节从SDXL-inpainting和DreamshaperXL获得的能力增强。重要的是,直接将SDXL-inpainting的conv输入层中的额外5个通道复制到合并模型中,并乘以 α \alpha α。然而, α \alpha α 和 β \beta β 的最优值并不明显。希望确定最优的 α \alpha α 和 β \beta β,以确保初始权重 W n e w W_{new} Wnew能够达到最佳的评估性能,即
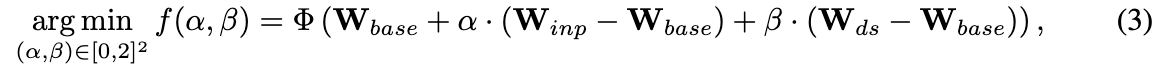
其中 Φ \Phi Φ 是一个不可微的评估函数。经验上,假设 f f f 对于平衡系数 ( α , β ) (\alpha, \beta) (α,β) 在大多数区域内表现出单调或凸性质。因此,将连续域 0 , 2 2 0, 2^2 0,22 离散化为一个步长为 δ = 0.1 \delta = 0.1 δ=0.1 的网格,并设计了离散贪婪算法1,以搜索最优的 ( α , β ) (\alpha, \beta) (α,β)。在算法中,选择20对固定的修补图像-文本对的CLIP得分作为评估函数 (\Phi)。得到的最优解为 ((\alpha, \beta) = (1.0, 1.1))。更多解释请参阅附录C.1。
自适应mask增强。以前的工作在跨类别试穿场景中通常表现出有限的稳健性,导致渲染的服装样式不准确,如下图6和图9所示。这主要是由于依赖于从服装解析中得出的无关mask ,这在训练期间往往会泄露服装形状的边缘。这种泄露可能导致生成的服装几乎完全覆盖无关mask区域。针对这些局限性,采用了一种直观且有效的方法,即自适应mask增强策略,大大增强了模型在跨类别试穿方面的稳健性。该策略主要包括训练期间的mask增强和推理期间的自适应延长。


具体而言,在训练期间,无关mask仅使用OpenPose身体关节检测提取,而不利用人体解析。以概率 P = 0.5 P = 0.5 P=0.5 对mask进行随机延长,延长系数 f ∼ U n i f o r m ( 1.2 , 1.5 ) f \sim Uniform(1.2, 1.5) f∼Uniform(1.2,1.5)。这种训练设置迫使模型自主确定最优的服装长度。在推理期间,评估铺展开的服装边界框的长宽比 σ \sigma σ。如果 \\sigma \> 1.2,按比例延长无关区域以匹配 σ \sigma σ,创建一个与服装样式相符合的自适应无关mask。实验验证了采用自适应mask增强的AnyFit能够自主确定适当的服装长度,产生在不同服装类别中的稳健试穿结果。
实验
定性结果
单服装试穿。图3和图4在VITON-HD、更具挑战性的专有数据和野外数据上提供了AnyFit与基线方法的定性比较,涵盖了开放服装和分层渲染场景。为了与基线方法进行公平比较,包括了在VITON-HD上训练的AnyFit的结果。AnyFit在保留复杂图案细节方面表现出色,这归功于HydraNet和IP-Adapter之间的有效协作。它还在语义级别上保持了正确的服装轮廓。这表明,通过mask 增强,AnyFit增强了对服装原始形状的回忆,而其他受mask 影响的模型往往会生成不正确的外观。先前的模型演化进一步增强了服装的纹理表示。值得注意的是,当在专有数据集上训练时,AnyFit会根据姿势自动填充内衣或解开衣物,而在VITON-HD上训练的版本则因缺乏此类训练数据而无法做到。
多服装试穿。下图5提供了使用编译的DressCode-multiple数据集进行多服装试穿的定性比较。首先,AnyFit展示了高保真的布料保留。由于位于不同条件分支中的独特和个体的Hydra-Blocks,AnyFit准确地描绘了上衣和下衣之间的分界线,并展示了连接处的合理过渡。相比之下,VTON-concat在串联后处理相对服装尺寸时处理不当,导致服装失真和模糊。与此同时,IDM-2Stage在上下衣交接处面临着伪影,因为在试穿一个服装时,它会掩盖另一个服装的部分。值得注意的是,尽管训练时一个服装呈现为平铺图像,另一个服装为从人物图像裁剪的扭曲布料,但在推理时,AnyFit在面对两种都作为平铺图像呈现的服装时仍然表现出色。

定量结果
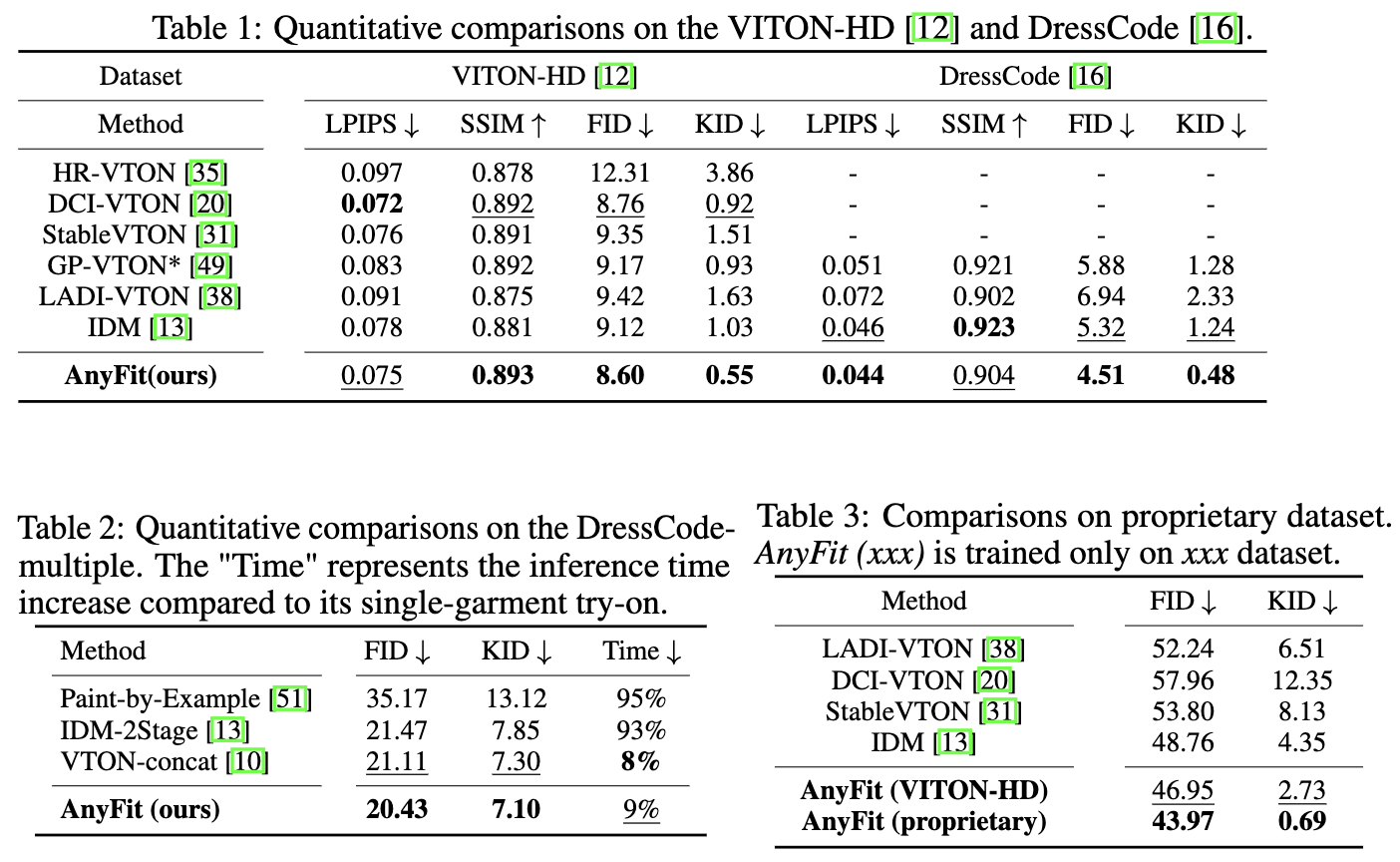
如下表1、2、3所示,在VITON-HD、DressCode、专有数据集和DressCode-multiple上进行了广泛的实验,结果一致表明AnyFit显著优于所有基线方法。这证实了AnyFit在单件服装和多件服装任务中在各种场景下提供优越的试穿质量的能力。此外,注意到AnyFit在未配对设置下在FID和KID指标方面显示出显著改善,展示了本文模型在跨类别试穿中的鲁棒性。
消融研究
Hydra Blocks。为验证本文提出的Hydra Blocks的有效性,直接使用一个条件化的单一HydraNet作为基线"w/o Hydra Block",实际上退化为ReferenceNet,同时编码顶部和底部服装条件,然后将它们连接到MainNet中。如下表4、图7和10所示,缺乏Hydra Block的模型往往在上衣和下衣交接处产生伪影。这些模型还经常允许一个服装的特征影响另一个,导致不正确的服装风格。然而,引入Hydra Block后,AnyFit始终展现出更稳定的结果。


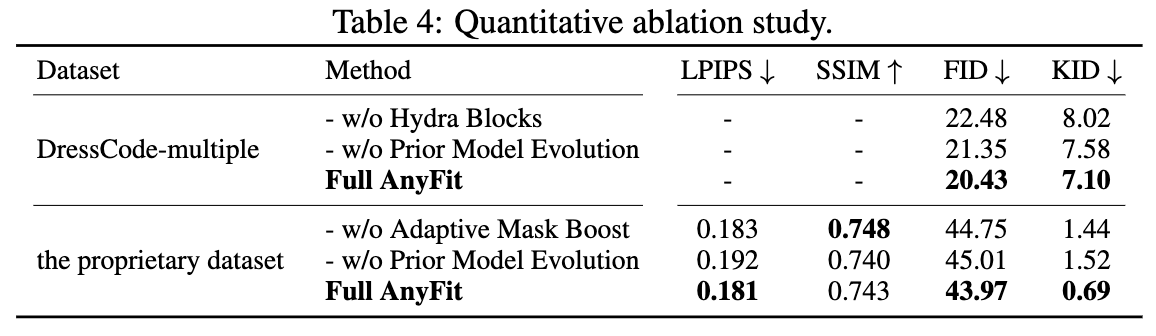
Prior Model Evolution。在下图12和6(a)中定性展示了Prior Model Evolution的效果。SDXL-evolved模型显著减少了伪影,并显著增强了鲁棒性,而没有Prior Model Evolution的输出通常具有过度饱和的颜色,以及与背景不协调的光照和阴影。模型能力的逐步增强在图6©中可视化。还在图7和表4中从经验和定量上验证了Prior Model Evolution策略的有效性。通过增强模型的初始能力,Prior Model Evolution减少了学习的难度,并显著提升了服装装配能力和标志保真度。


Adaptive Mask Boost。在上图6(b)和下图9中图示展示了先前方法中发现的信息泄露和mask 依赖的问题。在表4和图9中经验和定量上验证了Adaptive Mask Boost策略的有效性。该策略显著增强了模型对不同服装类别的鲁棒性,使其能够自主确定适当的服装长度,而不是依赖于mask 。此外,在推理过程中手动调整了长宽比σ,显示了自适应延伸的积极影响。

结论
AnyFit,这是一个适用于任何场景下任意服装组合的新颖而强大的VTON pipeline,为实现逼真的试穿效果迈出了关键性的一步。为支持多件服装试穿,AnyFit构建了具有轻量级和可扩展并行化注意力的HydraNet,促进了多件服装的特征注入。通过在真实场景中观察到的伪影,通过合成多模型的残差以及实施mask区域增强策略来提升其潜力。对高分辨率基准和真实数据的全面实验表明,AnyFit在各方面显著超越了所有基线方法。
更广泛的影响
随着生成图像的能力,AnyFit可能被用于违反知识产权或隐私规范的不当目的。因此,基于这些风险,强烈主张谨慎使用这项技术。
参考文献
1 AnyFit: Controllable Virtual Try-on for Any Combination of Attire Across Any Scenario