ZooKeeper快速入门系列
ZooKeeper的概述
什么是ZooKeeper?
ZooKeeper是一个开源的分布式协调服务,旨在管理和协调分布式应用程序。它提供了一个简单的接口,允许开发人员实现分布式系统中常见的协调任务,如选举、配置管理、命名服务、分布式锁等。
ZooKeeper的特点和功能
-
协调服务: ZooKeeper提供了一致性和可靠性的协调服务,使得分布式应用程序可以在不同节点之间协同工作。
-
分布式锁: ZooKeeper可以用于实现分布式锁,确保在分布式环境中对共享资源的访问是有序的。
-
命名服务: ZooKeeper可以用作命名服务,帮助分布式系统管理节点和服务的命名空间。
-
配置管理: 开发人员可以使用ZooKeeper来集中管理分布式系统的配置信息,实现动态配置更新。
-
分布式协调: ZooKeeper提供了诸如分布式队列、分布式通知等功能,帮助开发人员构建复杂的分布式系统。
-
高可用性: ZooKeeper本身设计为高可用的,通过在集群中多个节点之间复制数据来实现容错性。
使用ZooKeeper的原因
-
ZooKeeper提供了分布式系统中必需的协调和通知机制,确保不同节点之间的一致性和顺序性。这对于实现分布式锁、分布式队列、领导者选举等关键功能至关重要。
-
ZooKeeper可以用作集中式的配置管理工具,帮助管理和同步分布式系统中的配置信息。这使得动态配置更新变得更加简单和可靠。
-
ZooKeeper本身设计为高可用的系统,通过在多个节点之间复制数据来实现容错性。这使得ZooKeeper在关键的分布式环境中能够提供可靠的服务。
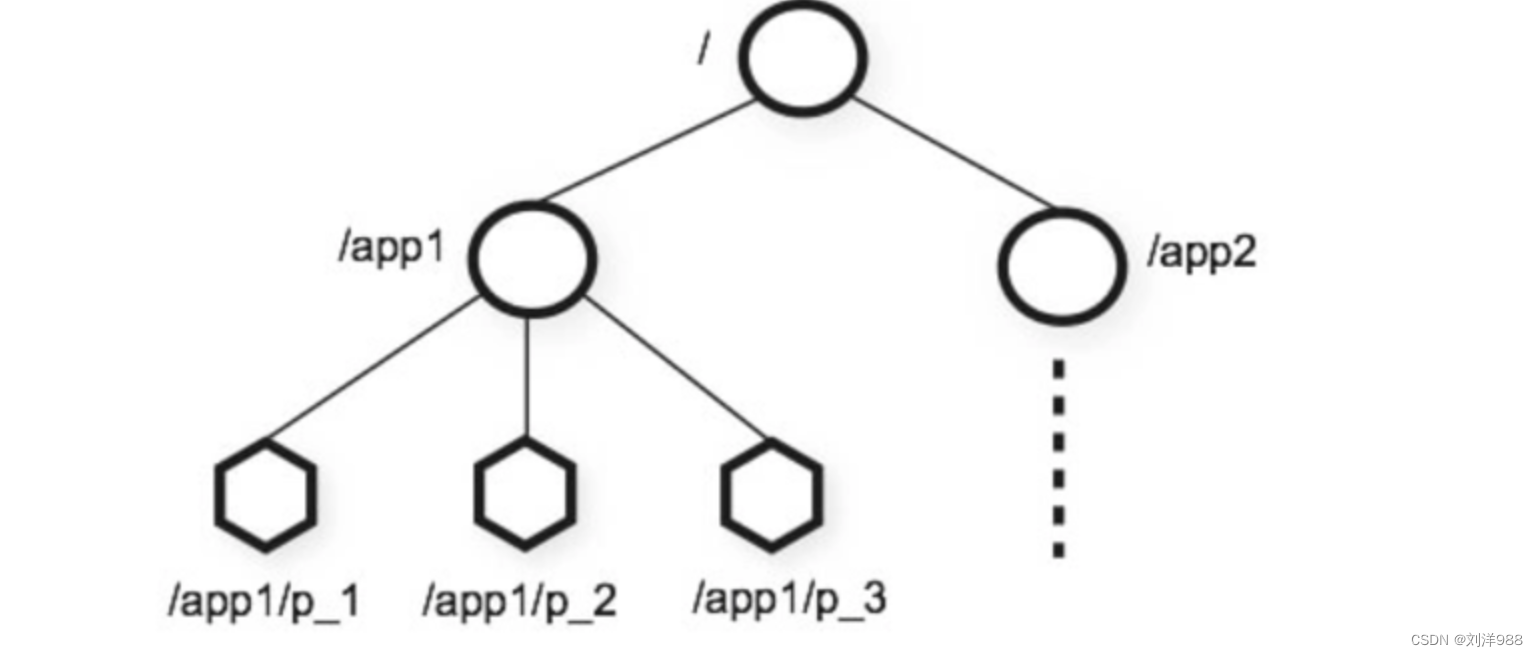
ZooKeeper数据模型
ZooKeeper是一个树形目录服务,每一个节点都被称为ZNode,每个节点
上都会保存自己的数据和节点信息。 节点可以拥有子节点,同时也允许少量
(1MB)数据存储在该节点上。
ZNode节点类型:
- PERSISTENT 持久化节点
- EPHEMERAL 临时节点 :-e
- PERSISTENT_SEQUENTIAL 持久化顺序节点 :-s
- EPHEMERAL_SEQUENTIAL 临时顺序节点 :-es
ZooKeeper安装
环境准备
ZooKeeper服务器是用Java创建的,它运行在JVM之上。安装JDK7或更高版本。
上传
将下载的ZooKeeper放到/export/software目录下
解压
进入/export/software目录下,将tar包解压到/export/servers目录下
tar -xzvf apache-ZooKeeper-3.5.6-bin.tar.gz -C /export/servers
添加环境变量
在/etc/profile全局配置文件中,添加:
export ZK_HOME=/export/servers/apache-zookeeper-3.5.6-bin
export PATH= P A T H : PATH: PATH:ZK_HOME/bin
ZooKeeper配置
配置zoo.cfg
进入到conf目录拷贝一个zoo_sample.cfg并完成配置
#进入到conf目录
cd /export/servers/apache-zookeeper-3.5.6-bin/conf
#拷贝
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg
#进入目录
cd /export/data
#创建zooKeeper存储目录
mkdir zkdata
#修改zoo.cfg
vi /export/servers/apache-zookeeper-3.5.6-bin/conf/zoo.cfg
修改存储目录:dataDir=/export/data/zkdata
启动ZooKeeper
cd /export/servers/apache-zookeeper-3.5.6-bin/bin
./zkServer.sh start
查看ZooKeeper状态
./zkServer.sh status
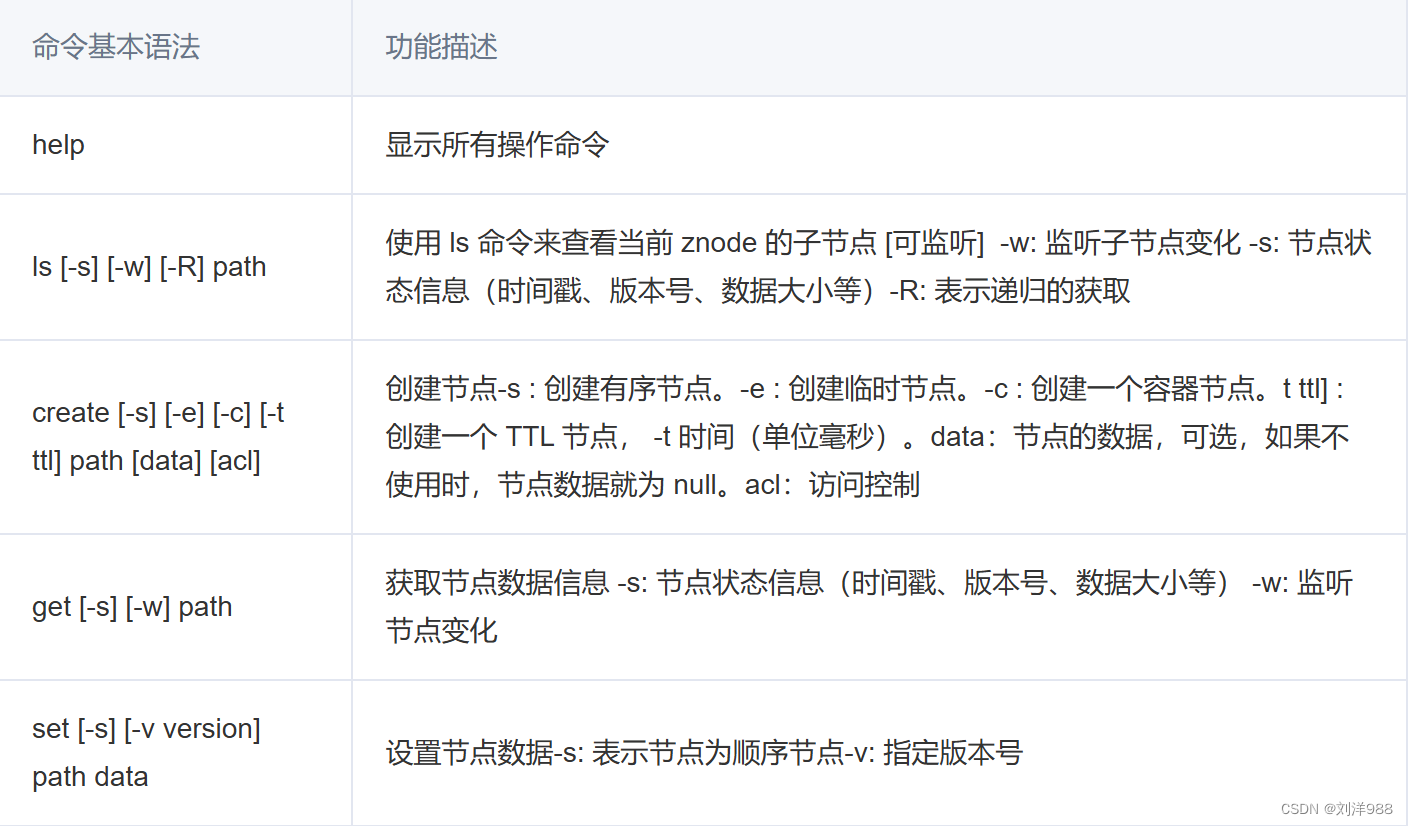
ZooKeeper命令行操作
服务端常用命令
启动 ZooKeeper 服务:
./zkServer.sh start
查看 ZooKeeper 服务状态:
./zkServer.sh status
停止 ZooKeeper 服务:
./zkServer.sh stop
重启 ZooKeeper 服务:
./zkServer.sh restart
Zookeeper客户端常用命令
连接ZooKeeper服务端:
./zkCli.sh --server ip:port
断开连接:
quit
显示指定目录下节点
ls 目录
创建持久化节点:
create /节点path # 创建持久化节点但不设置值
create /节点path value # 创建持久化节点并且设置值
获取节点值:get /节点path
设置节点值:
set /节点path value
删除单个节点:
delete /节点path
删除包含子节点的节点:
deleteall /节点path
创建临时节点:
create -e /节点path value
创建顺序节点:
create -s /节点path value
查询节点详细信息:
ls -s /节点path
常见服务端命令
https://zookeeper.apache.org/doc/r3.8.3/zookeeperCLI.html