 各位大佬好 ,这里是阿川的博客,祝您变得更强
各位大佬好 ,这里是阿川的博客,祝您变得更强
 个人主页:在线OJ的阿川
个人主页:在线OJ的阿川
大佬的支持和鼓励,将是我成长路上最大的动力
阿川水平有限,如有错误,欢迎大佬指正

Python 初阶
Python--语言基础与由来介绍
Python--注意事项
Python--语句与众所周知
数据清洗前 基本技能
数据分析---技术栈和开发环境搭建
数据分析---Numpy和Pandas库基本用法及实例
回归模型前 必看
数据分析---三前奏:获取/ 读取/ 评估数据
数据分析---数据清洗操作及众所周知
数据分析---数据整理操作及众所周知
数据分析---统计学基础及Python具体实现
数据分析---数据可视化Python实现超详解
数据分析---推断统计学及Python实现
目录
- 线性回归模型简介
-
- 相关关系
- 相关系数r
- 共线性问题
- 回归线
- 残差
- 拟合目标
- 线性回归模型预测拟合度
- 虚拟变量
- 逻辑回归模型简介
-
- 拟合程度
- 最优参数值
- 线性回归Python具体实现
- 逻辑回归Python具体实现
回归模型 是机器学习中很重要的一个数学模型
机器学习
- 简单线性回归
- 多元线性回归
- 逻辑回归

线性回归模型简介
相关关系
- 正相关
- 负相关
- 不相关

相关系数r
- 研究变量 之间 线性关系 的相关程度
- 即衡量已知数据 的相关性
- 越接近1 ,表示越接近线性正相关
- 越接近-1 ,表示越接近线性负相关
- 越接近0 ,表示越接近线性不相关

r = n ∑ x y − ( ∑ x ) ( ∑ y ) n ∑ x 2 − ( ∑ x ) 2 n ∑ y 2 − ( ∑ y ) 2 r=\frac{n\sum xy-(\sum x)(\sum y)}{\sqrt{n\\sum x\^2-(\\sum x)\^2n\\sum y\^2-(\\sum y)\^2}} r=n∑x2−(∑x)2n∑y2−(∑y)2 n∑xy−(∑x)(∑y)
r :皮尔逊积矩相关系数 ,表示两个变量间的线性关系强度 和方向 ,其阈值 为-1,1
x :通常作为自变量
y :通常作为因变量
∑ \sum ∑ :求和符号,表示加和一系列数值
在多元线性回归 中发现两个自变量相关系数r绝对值大 ,去除 其中的一个 自变量
例如:超过0.8或0.9可以考虑移除其中一个
- 因为一般认为相关系数大于0.8及以上 ,会导致严重共线性问题
共线性问题
- 若本身两个变量间 是高度相关 的,而处理过程 中将两个变量认为不相关/相互独立的 ,会导致 系数估计不准确 ,从而对预测 产生影响
例如:若男性和女性两个变量 分别设置两个虚拟变量 ,会导致共线性问题- 因为 男和女这两个变量本身是高度相关的 ,所以设置一个虚拟变量 即可 (1设成男,0设成女或者 1设成男,0设成女),且当 知道N-1虚拟变量值 时,可以直接推导出第n个值 ,说明 他们之间存在相关联 ,则 设第n个虚拟变量是没必要的 ,会导致共线性问题
回归线
- 去拟合 图中的数据点 ,尽可能的去靠近 图中每个数据点的直线

残差
- 回归线的实际观测值 与估计值(拟合值 )之间的差

拟合目标
- 让所有残差 的平方和最小
更专业的术语
- 最小二乘法
- 通过最小化残差 的平方和 来找到最好的模型参数
除了 相关系数r 也要 关注 p值
在独立双样本t/z检验 中有一个叫做p值
p值小 (拒绝原假设)
- 自变量对因变量有统计显著性影响
- 自变量对因变量有显著预测作用
p值大 (接受原假设)
- 自变量对因变量无统计显著性影响
- 自变量对因变量无显著预测作用

p值大 的自变量可选择剔除 (因为该自变量对因变量无显著预测作用 ),再进行多轮拟合 ,再反复调整 去求截距和系数,可以降低 对预测值的干扰 和误导
线性回归模型预测拟合度
R2 衡量 线性回归模型整体 的预测拟合度
- R2的范围值 0,1
- 越接近 1 ,说明模型的预测值与实际观察值相差越小 ,使得线性回归模型整体和实际高拟合
- 越接近 0 ,说明模型的预测值与实际观察值相差越大 ,使得线性回归模型整体和实际低拟合

R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2=1-\frac{\sum_{i=1}^{n} (y_i-\hat{y}i)^2} {\sum{i=1}^{n}(y_i-\bar{y})^2} R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2
y i y_i yi :第i个观测因变量值
y ˉ \bar{y} yˉ :所有观测因变量值的平均值
y ^ i \hat{y}_i y^i :由模型给出 的第i个观测的观测因变量值
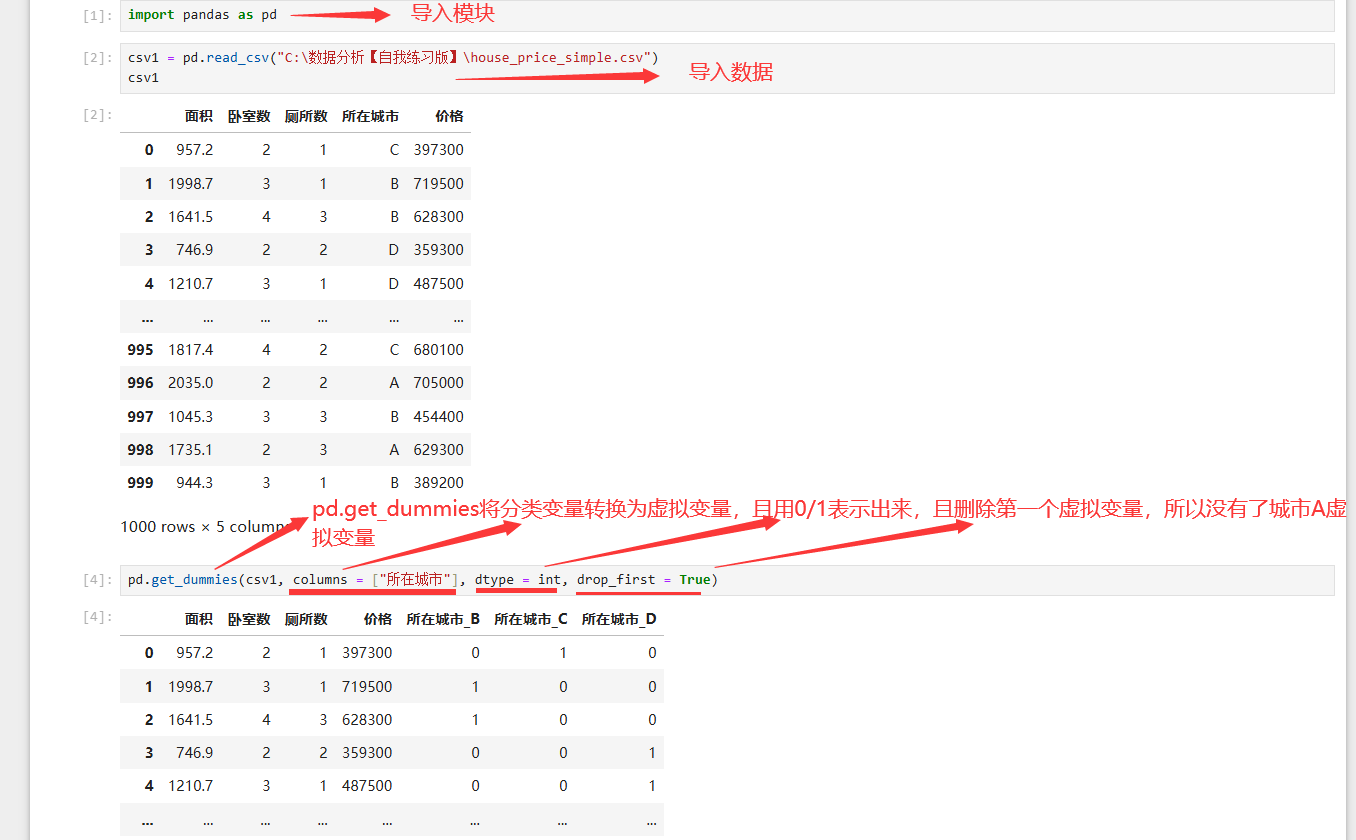
虚拟变量
在线性回归模型中表示分类变量 要引入虚拟变量
- 即只取0和1这两个值的变量
根据 分类的类别 ,若有n种类型 ,则引入n-1个虚拟变量
- 若引入n个虚拟变量 ,则会引起共线性问题
pd.get_dummies(DataFrame名, columns=" 分类变量", dtype=int, drop_first) 将分类变量 转化 为虚拟变量0/1 ,且删除 第1个引用的虚拟变量 (从而保持 n-1个虚拟变量 )
逻辑回归模型简介
逻辑回归
- 处理二分类问题 ,只 能在零和一之间
- 要设置阈值 ,一般为0.5 ,但可以根据具体情况来调整阈值
拟合程度
最大似然估计
- 需要用到数值优化算法 (例如其中的梯度下降 等)来寻找最优参数值

需要排除 高度相关的变量 ,否则 会导致 数值优化算法无法收敛 的问题,无法计算 出模型参数值
最优参数值
- 在这参数值下观察 到的样本出现 的概率是最大的 ,从而让模型预测 和样本之间差距越小
求出 最优参数值后 ,看p值
看自变量 的系数值 ,然后对 自然常数e 求系数的那个值的次方 ,反映的 是自变量对因变量的倍数影响

线性回归Python具体实现
简单线性回归 y=b0+mx
- 预测未知数据 ,用 自变量值 来预测因变量值
- 因变量 只受到一个自变量影响
多元线性回归 y=b0+b1x+b2x+...+bnxn
- 因变量 受到 多个自变量影响
- 自变量 应该相互独立 ,不应该高度相关
- 否则导致 对系数估计不准确
- 自变量 应该相互独立 ,不应该高度相关

y = b 0 + m x y= b_{0}+mx y=b0+mx
或者
y = b 0 + b 1 x + + b 2 x + . . + b n x n y= b_{0}+b_1x++b_2x+..+b_nx_n y=b0+b1x++b2x+..+bnxn
b = ∑ y i − m ( ∑ x i ) n b=\frac{\sum y_i-m(\sum x_i)}{n} b=n∑yi−m(∑xi)
m = n ( ∑ x i y i ) − ( ∑ x i ) n ( ∑ x i 2 ) − ( ∑ x i ) 2 m=\frac{n(\sum x_iy_i)-(\sum x_i)}{ n(\sum x_i^2)-(\sum x_i)^2} m=n(∑xi2)−(∑xi)2n(∑xiyi)−(∑xi)
y :因变量
b 0 b_0 b0 :y轴截距 ,可以视为 与常量1相乘
m, b 1 b_1 b1, b 2 b_2 b2... b n b_n bn :斜率 (也称系数 )
x :自变量
x i x_i xi :第i个观测 的自变量值
y i y_i yi :第i个观测 的因变量值
先安装 statsmodels库 ,并引入模块 :import statsmodels.api as sm

y=DataFrame名" " 提取因变量
x=DataFrame名.drop" ",axis=1 删除掉因变量从而提取自变量
或者
x=DataFrame名\[" "] 选择提取自变量

自变量1.corr(自变量2) 验证自变量间 的相关性
- 结果越接近1 说明越相关
- 结果越接近0 说明越不相关
或者
DataFrame名.corr() 自动对各变量 之间找相关系数

.abs() 得到所有元素绝对值
- 还可以搭配热力图heatmap,一眼看出颜色深浅
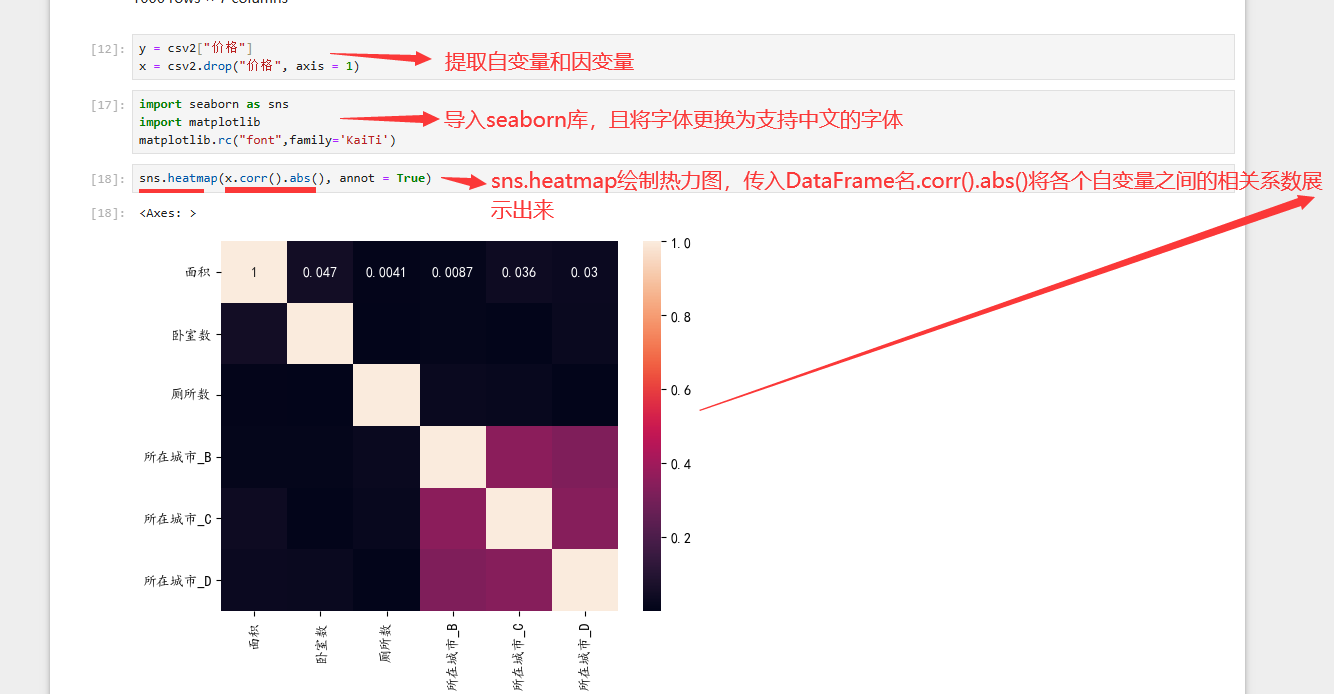
以相关系数0.8 作为阈值 ,进行筛选相关自变量 ,确保不会 导致共线性问题 ,然后 开始求截距
sm.add_constant(参数) 将截距常量1纳入模型
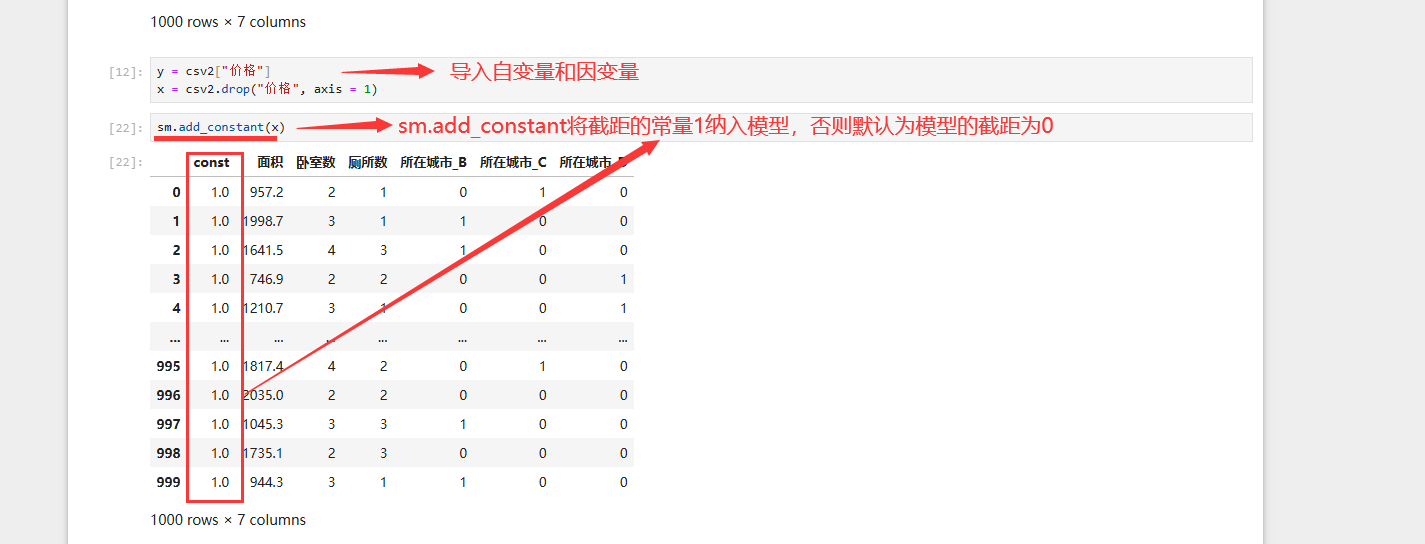
sm.OLS(因变量,自变量) 最小二乘法
.fit() 对数据进行拟合并生成一个实例
.summery() 对实例 进行展示

当得到线性回归模型后 ,进行预测
pd.Categorical(DataFrame分类变量, categories=" ") 将分类变量 转化为category类型
- categories 该参数 可以告诉系统虚拟变量的全部类型
再get_dummies() 将分类变量转化 为虚拟变量

线性回归模型.predict(传入包含所有自变量的DataFrame) 预测模型
- 要求:每列都是 模型中的自变量 (不多不少),这样每行 才是一个要预测的观测值

结构流程图

在模型中没有标准答案 ,去尝试 、调整 、验证模型
逻辑回归Python具体实现
逻辑回归 l o g ( p 1 − p ) = b 0 + b 1 x + b 2 x + . . + b n x n log(\frac{p}{1-p})=b_0+b_1x+b_2x+..+b_nx_n log(1−pp)=b0+b1x+b2x+..+bnxn
l o g ( p 1 − p ) = b 0 + b 1 x + b 2 x + . . + b n x n log(\frac{p}{1-p})=b_0+b_1x+b_2x+..+b_nx_n log(1−pp)=b0+b1x+b2x+..+bnxn
p = 1 1 + e − ( b 0 + b 1 x + b 2 x + . . + b n x n ) p=\frac{1}{1+e^{-(b_0+b_1x+b_2x+..+b_nx_n)}} p=1+e−(b0+b1x+b2x+..+bnxn)1
p :因变量y=1的概率 ( y是二元变量 ,只能取0或1 )
x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3,... x n x_n xn:预测变量
b 0 b_0 b0, b 1 b_1 b1, b 2 b_2 b2,..., b n b_n bn是回归系数
先导入模板 :import statsmodels.api as sm

pd.get_dummies (DataFrame, columns=" 分类变量", dtype=int, drop_first)将分类变量转化为虚拟变量
.corr() 排除共线性问题
.abs() 转化为绝对值
sm.add_constant() 截距常量1纳入模型

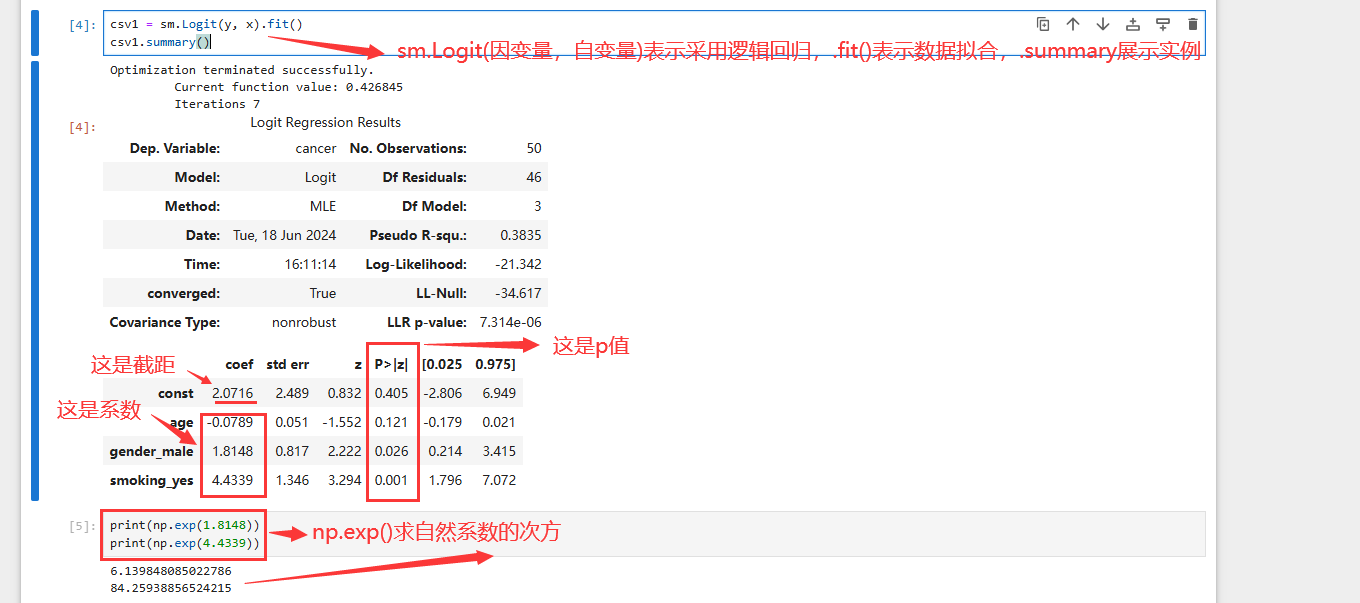
sm.Logit(因变量,自变量) 最大似然估计
.fit() 对数据进行拟合并生成实例
.summary() 查看输出
先看p值 看哪些变量没有显著预测作用 ,一般设置阈值 为0.05 ,再看 codf系数,但 要将该系数翻译成 自然语言e的倍数
np.exp() 计算e的多少次方
.predict() 预测模型

好的,到此为止啦,祝您变得更强
想说的话
实不相瞒,这篇博客写了9个小时以上(加上自己学习了三遍和纸质笔记,共十一小时 吧),很累 ,希望大佬支持
| 道阻且长 行则将至 |
|---|
个人主页:在线OJ的阿川大佬的支持和鼓励,将是我成长路上最大的动力 