
一个认为一切根源都是"自己不够强"的INTJ
 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客
专栏:每日一题------举一反三
Python编程学习
Python内置函数
目录
[分治法(Divide and Conquer):](#分治法(Divide and Conquer):)
[空间与时间的权衡(Space-Time Tradeoff):](#空间与时间的权衡(Space-Time Tradeoff):)
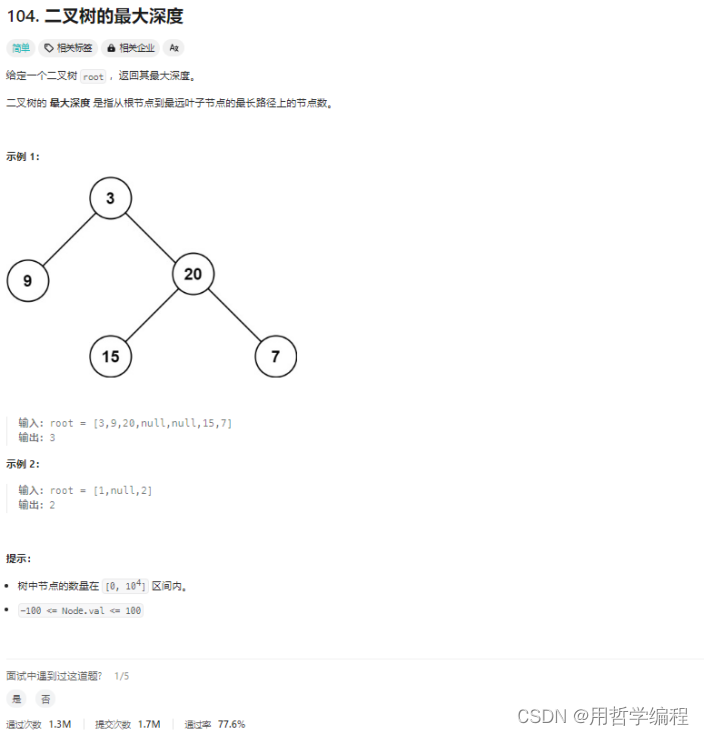
题目链接:https://leetcode.cn/problems/maximum-depth-of-binary-tree/description/
我的写法
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
int maxDepth(struct TreeNode* root) {
if(!root)
{
return 0;
}else{
int left_max=maxDepth(root->left);
int right_max=maxDepth(root->right);
return 1+(left_max>right_max?left_max:right_max);
}
}
这段代码是一个用于计算二叉树最大深度的递归函数。下面是对这段代码的点评:
代码功能
代码定义了一个名为 maxDepth 的函数,它接受一个指向二叉树根节点的指针 root,并返回该二叉树的最大深度。
代码结构
- 基本情况处理:
- 如果 root 为 NULL(即树为空),则返回深度 0。
- 递归调用:
- 分别递归调用 maxDepth 函数计算左子树和右子树的最大深度,分别存储在 left_max 和 right_max 变量中。
- 结果计算:
- 通过比较 left_max 和 right_max 的大小,返回较大的值加上 1(代表当前节点)作为整棵树的最大深度。
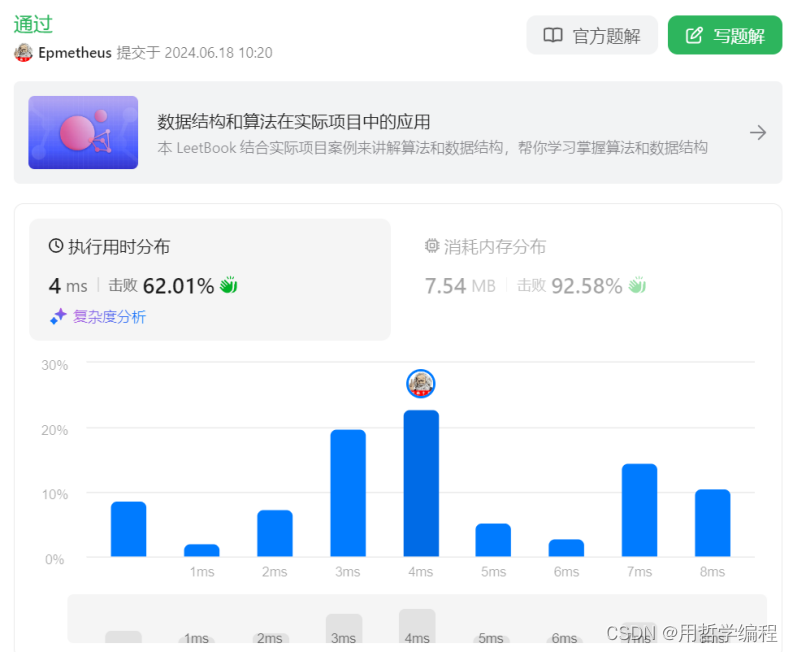
时间复杂度分析
- 时间复杂度:O(n),其中 n 是二叉树中的节点数。每个节点仅被访问一次,因为每个节点只参与一次递归调用。
空间复杂度分析
- 空间复杂度:O(h),其中 h 是二叉树的高度。这是因为在递归调用过程中,系统栈的深度最多为树的高度。在最坏情况下(当树是一个链表时),空间复杂度为 O(n)。
总结
这段代码简洁高效,正确地实现了计算二叉树最大深度的功能。它利用递归的特性,通过比较左右子树的深度来确定当前树的最大深度,是一种典型的分治策略的应用。代码的时间复杂度为线性,空间复杂度与树的高度成正比,整体性能良好。
我要更强
在计算二叉树的最大深度时,通常情况下,上述代码已经非常高效,因为它的时间复杂度是 O(n),空间复杂度是 O(h),其中 n 是节点数,h 是树的高度。然而,如果我们考虑极端情况,例如树非常不平衡,空间复杂度可能会接近 O(n)。为了进一步优化空间复杂度,我们可以考虑使用迭代方法而不是递归,这样可以避免递归调用栈的空间开销。
优化方法:迭代(使用队列)
我们可以使用广度优先搜索(BFS)来计算树的深度,这种方法通常使用队列来实现。每次迭代处理一层的节点,从而计算出树的深度。这种方法的空间复杂度仍然是 O(w),其中 w 是树的宽度(即一层中节点最多的数量),但在最坏情况下(树非常不平衡),w 可能会接近 n,因此这种方法在空间复杂度上并没有显著优化,但它避免了递归调用栈的开销。
下面是使用队列实现的迭代方法的完整代码:
cpp
#include <stdlib.h>
// 定义树节点结构
typedef struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
// 定义队列节点结构
typedef struct QueueNode {
TreeNode *node;
struct QueueNode *next;
} QueueNode;
// 定义队列结构
typedef struct Queue {
QueueNode *front;
QueueNode *rear;
int size;
} Queue;
// 初始化队列
void initQueue(Queue *q) {
q->front = q->rear = NULL;
q->size = 0;
}
// 入队操作
void enqueue(Queue *q, TreeNode *node) {
QueueNode *newNode = (QueueNode *)malloc(sizeof(QueueNode));
newNode->node = node;
newNode->next = NULL;
if (q->rear == NULL) {
q->front = q->rear = newNode;
} else {
q->rear->next = newNode;
q->rear = newNode;
}
q->size++;
}
// 出队操作
TreeNode *dequeue(Queue *q) {
if (q->front == NULL) {
return NULL;
}
QueueNode *temp = q->front;
TreeNode *node = temp->node;
q->front = q->front->next;
if (q->front == NULL) {
q->rear = NULL;
}
free(temp);
q->size--;
return node;
}
// 计算树的最大深度
int maxDepth(TreeNode *root) {
if (root == NULL) {
return 0;
}
Queue queue;
initQueue(&queue);
enqueue(&queue, root);
int depth = 0;
while (queue.size > 0) {
int levelSize = queue.size;
for (int i = 0; i < levelSize; i++) {
TreeNode *node = dequeue(&queue);
if (node->left != NULL) {
enqueue(&queue, node->left);
}
if (node->right != NULL) {
enqueue(&queue, node->right);
}
}
depth++;
}
return depth;
}这段代码通过队列实现了广度优先搜索,每次迭代处理一层的节点,从而计算出树的深度。这种方法的时间复杂度仍然是 O(n),但空间复杂度在最坏情况下可能会接近 O(n),因为它需要存储每一层的节点。在实际应用中,这种方法的性能通常与递归方法相当,但在处理大型或不平衡的树时,它可能会有更好的表现。
哲学和编程思想
上述代码和方法体现了以下哲学和编程思想:
分治法(Divide and Conquer):
- 递归方法中,通过将问题分解为更小的子问题(左子树和右子树的最大深度)来解决原始问题。这是一种典型的分治策略,通过解决子问题并合并结果来解决整个问题。
递归(Recursion):
- 递归是一种编程技巧,其中函数调用自身来解决问题。在计算树的最大深度时,递归方法通过递归地计算子树的深度来确定整个树的深度。
迭代(Iteration):
- 迭代是另一种编程技巧,通过循环重复执行一组操作来解决问题。使用队列的迭代方法通过遍历树的每一层来计算深度,而不是像递归那样深入到树的底部。
抽象(Abstraction):
- 在代码中,树节点和队列都被抽象为结构体,这有助于隐藏实现细节并提供清晰的接口。这种抽象使得代码更易于理解和维护。
数据结构的选择:
- 选择合适的数据结构是编程中的一个重要决策。在这里,队列被用来实现广度优先搜索,因为它允许按层处理节点,这是计算树深度的关键。
空间与时间的权衡(Space-Time Tradeoff):
- 递归方法使用较少的代码量,但可能会消耗较多的栈空间。迭代方法虽然代码更复杂,但避免了递归调用栈的空间开销。这种权衡是编程中常见的,需要根据具体情况选择最合适的方法。
优化(Optimization):
- 在编程中,优化通常意味着在时间复杂度和空间复杂度之间找到平衡。迭代方法尝试通过减少空间使用来优化递归方法,尽管在某些情况下这可能不会带来显著的改进。
实用主义(Pragmatism):
- 在实际编程中,选择最简单、最直接的解决方案往往是最佳实践。递归方法虽然可能消耗更多空间,但它的简洁性和直观性使其成为许多程序员的首选。迭代方法则提供了另一种选择,特别是在空间受限的情况下。
这些哲学和编程思想指导着程序员在面对问题时如何设计算法和编写代码,以实现高效、可维护和可理解的解决方案。
举一反三
根据上述哲学和编程思想,以下是一些技巧和建议,可以帮助你在编程和问题解决中举一反三:
理解问题本质:
- 在开始解决问题之前,深入理解问题的本质和需求。这有助于你选择合适的算法和数据结构。
分治法应用:
- 当面对可以分解为子问题的问题时,考虑使用分治法。例如,排序算法(如快速排序和归并排序)和搜索算法(如二分查找)都是分治法的应用。
递归与迭代的转换:
- 学会将递归算法转换为迭代算法,或者反之。这种转换可以帮助你理解算法的底层逻辑,并在必要时优化空间或时间复杂度。
抽象思维:
- 在设计数据结构和算法时,尝试抽象出问题的核心概念。这有助于你创建通用的解决方案,这些解决方案可以应用于类似的问题。
选择合适的数据结构:
- 根据问题的特点选择最合适的数据结构。例如,如果需要频繁插入和删除元素,链表可能是一个好选择;如果需要快速查找,数组或哈希表可能更合适。
空间与时间的权衡:
- 在设计算法时,始终考虑时间和空间的权衡。有时候,牺牲一些空间可以显著提高时间效率,反之亦然。
优化意识:
- 始终寻找改进算法性能的机会。这可能包括减少不必要的计算、使用更有效的数据结构或算法,或者利用问题的特性来简化解决方案。
实用主义:
- 在实际编程中,选择最简单、最直接的解决方案。复杂的解决方案可能看起来很酷,但它们往往更难以维护和理解。
学习和模仿:
- 研究经典算法和数据结构,理解它们的设计思想和应用场景。通过模仿这些经典解决方案,你可以学习到许多通用的编程和问题解决技巧。
#### 实践和反思:- 通过实际编写代码来解决问题,并在解决后反思你的解决方案。思考是否有更好的方法,以及如何将这些方法应用到未来的问题中。
通过将这些技巧和思想应用到实际编程和问题解决中,将能够提高编程能力,并能够更有效地解决各种问题。记住,编程不仅仅是写代码,更是一种思维方式和解决问题的艺术。