问题:String类型在pytorch中如何表示?
很遗憾,pytorch不是完备的语言库,而是面向数据计算的一个GPU加速库,因此没有内建对string的支持
我们会在做NLP的时候会遇到all string处理的问题,就比如说一句话,把这句话翻译成另外一个国家的语言,这里面肯定是要注意string的,那么作为深度学习的一个GPU加速库pytorch免不了要处理string,但是它内部又没有string的自带的表示方法,那如何表达string呢?
两种表示方法:
- One-hot
-
0,1,0,0,...
-
- Embedding
- Word2vec
- glove
one-hot之前已经讲过,这里简单回顾,比如要表达猫狗这两类,用一维向量0,1来表示cat,1,0来表示dog,因此是一种编码表示,我们其实是没有内建string的支持的,只是用一种数字的方法来替代了
26个字母只要编码为一个长度为26的向量,但对于汉字或者多国的语言,甚至其他的单词(英语单词常用的单词有上万个),那么单词如果用一个上万列向量的编码来表示,整个向量会变得会变得非常稀疏(也就是大部分元素是0,只有一个元素位置是1),更致命的是这个向量会因为语言之间(例如 i like 或 i love)的语义相关性(i dislike)语义相反性,但对于one-hot编码来说每一个位置代表一个意思,因此两个单词之间的相关性并没有在one-hot中得到体现,怎么解决这个问题?
在NLP里面有一个专门的embedding layer,就是解决怎么用数字的方法来表示一个语言并具有相关性的方法

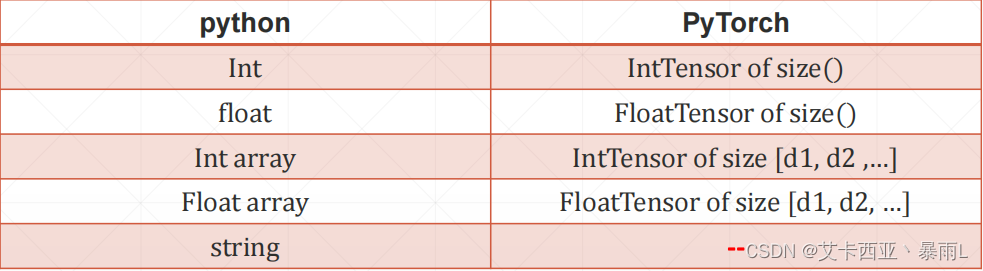
注意:一个tensor有可能被放置在CPU上,也有可能被放置在GPU上,对于GPU上的tensor,即使我们觉得可能它和CPU上的tensor是一个东西,但是对于pytorch来说并不是,GPU上的tensor会在中间加cuda
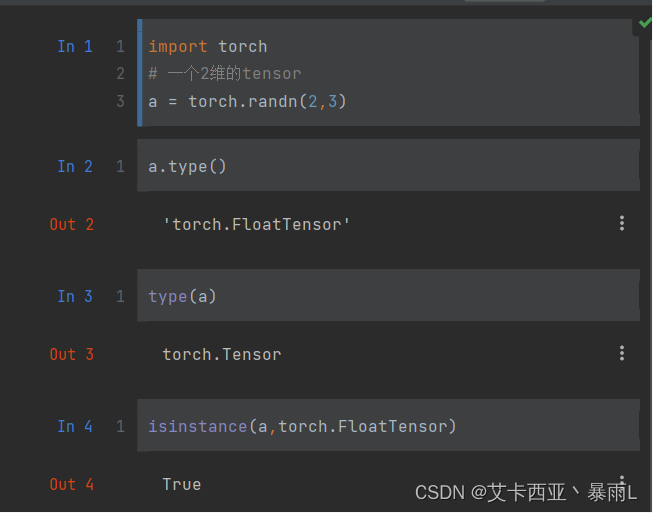
x.cuda()会返回gpu上的一个引用
数据一样,放的位置不一样,造成的类型不一样
标量
1.3是0维,但是1.3是1维,长度为1的Tensor

问题:dimension为0的数据用来表示什么?
最常见的就是计算loss,计算输出值跟我们期待的那个值之间的误差,误差最终求和平均后会得到一个标量,这个标量就称之为loss,这个loss用的最多的就是一个dimension为0的标量,如果用instance把它打印出来的话可以看到是一个size为0的某一种数据类型
问题:如何得到变量的shape
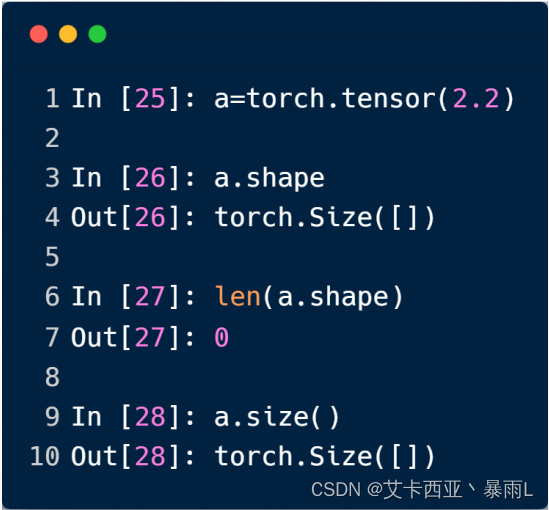
a.shape对应的是a.size()函数,shape是一个成员,而size()是一个成员函数
dimension为1
数学中叫做向量,pytorch中统一称之为张量
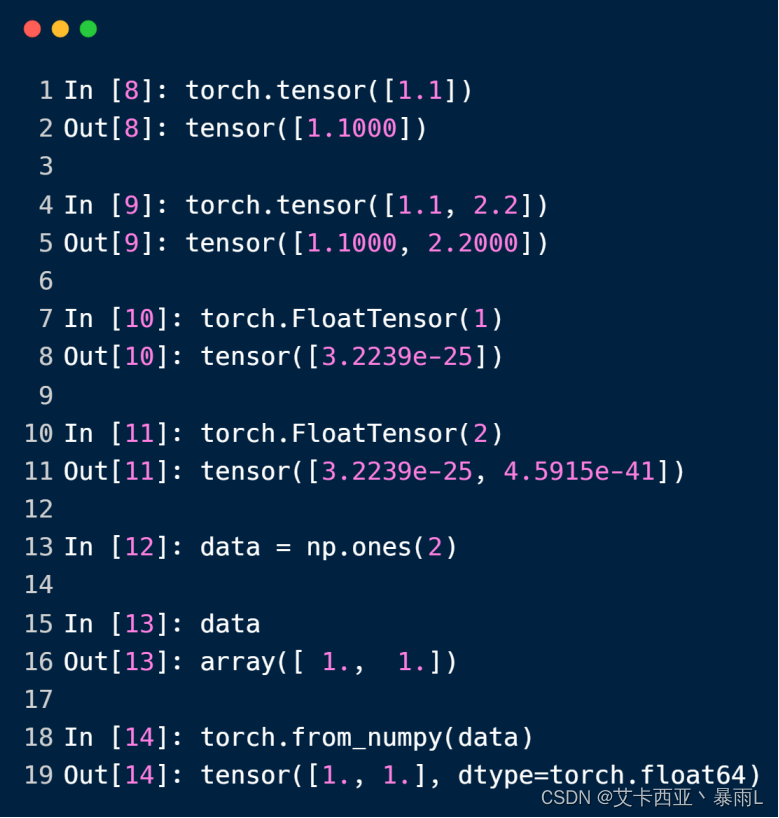
.tensor()的时候指定的是具体的数据
.FloatTensor()的时候是随机初始化的,只需要接收数据的shape
问题:dimension为1的tensor一般用在哪?
用在bias(偏移量),偏移量的维度一般都是1维的
神经网络线性层的输入
28,28\]=\>\[784
pytorch 0.3之前dimension=0是不存在的
为了区分标量0.3和长度为1的向量0.3就引入了dimension=0
如何得到dimension为1向量的shape

可以用.shape也可以用.size()函数
问题:如何区分dimension、size(或者叫shape)?
比如说2维的tensor,这个2维的2的意思就是dimension,size是整个shape
dimension就是size的长度
size就是指代的tensor具体的形状
dimension为2
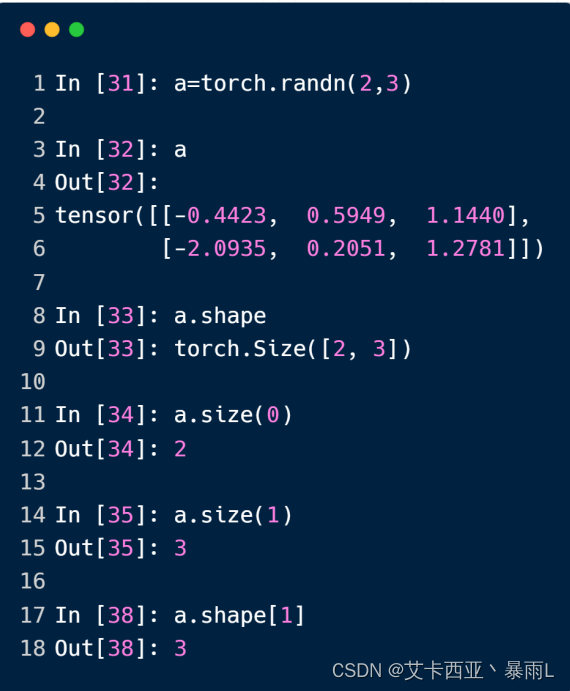
dimension=2经常使用的例子
带有batch的线性层的输入,例如1张图片用784的dimension为1的tensor来表达,但是如果一次要输入多张图片怎么办?
把多张图片叠在一起,每一张图片用784位的向量来表示,因此这个tensor的维度就是2,这个tensor的size就是4,784
第一个维度的4表示哪一张照片,每一张照片跟着的784这样的一个维度表示这个照片的具体数据内容
dimension为3
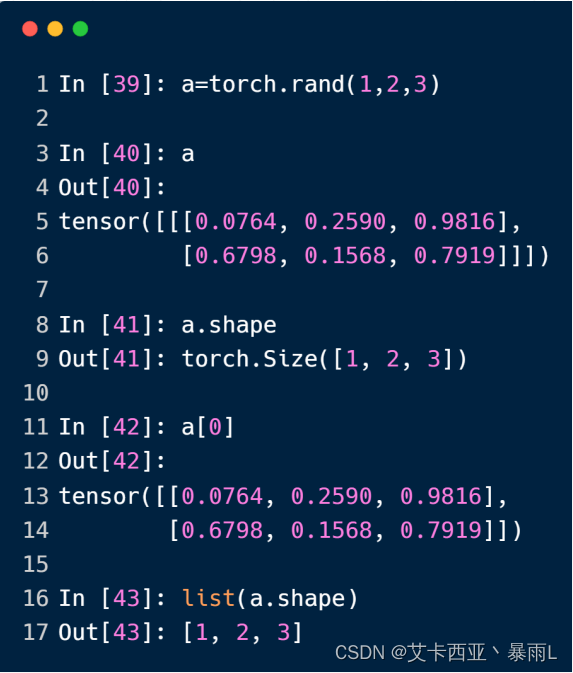
对于三维的tensor用一个非常广泛的使用场景RNN,对于一个RNN来说,一句话有10个单词,每个单词用one-hot编码,比如说用100位这样的向量来编码

10个单词word是W,每一句话的feature是F用100位的向量来表示,如10,100
如果要一次送入多句话的话我们要将batch插在中间10,20,100,10个单词每一次送20句话每一个单词用一个100维的向量来表示,所以20表示20句句子

dimension为4
对于4维的tensor适合图片这种类型CNN
2,3,28,28
1是通道数,对于灰色图片来说通道数是1,彩色图片的通道数是3
有2张照片,每一张照片有3个通道,每个通道的长宽为28×28
额外知识
除了可以用shape获取tensor的形状,还可以用获取tensor元素的总数4704=23 28*28
除了len(a.shape)可以返回shape的长度以外(即tensor的维度),a.dim()也可以返回tensor的维度,并且更加直观