1.前言
在上一篇文章《从零入手人工智能(4)------ 逻辑回归》中讲述了逻辑回归这个分类算法,今天我们的主角是决策树。决策树和逻辑回归这两种算法都属于分类算法,以下是决策树和逻辑回归的相同点:
分类任务:两者都是用于分类任务的算法。无论是决策树还是逻辑回归,它们的目标都是根据输入的特征(或变量)来预测样本的类别。这两种算法都接受一组特征作为输入,并输出一个类别标签。
预测类别:它们都可以预测样本属于哪个类别。无论是二分类问题还是多分类问题,决策树和逻辑回归都能够进行建模和预测。
处理特征:两者都可以处理多种类型的特征,包括数值型特征和类别型特征。
模型评估 :两者都可以使用相同的评估指标来评估模型的性能,如准确率、召回率、F1分数、AUC-ROC等。
虽然决策树和逻辑回归有上述相同点,但它在仍然存在差异。决策树和逻辑回归最大的差异在于它们的模型算法原理不同 :决策树 基于树形结构进行决策,通过一系列规则对数据进行分类。而逻辑回归 使用逻辑函数(如sigmoid函数)对输入特征进行建模,将线性模型的输出转换为概率值,然后根据概率值判断样本所属的类别。
由于决策树和逻辑回归有着诸多相似之处,所以本文就不额外过多的讲解,直接通过一个入门程序和一个进阶实战程序展示决策树 。
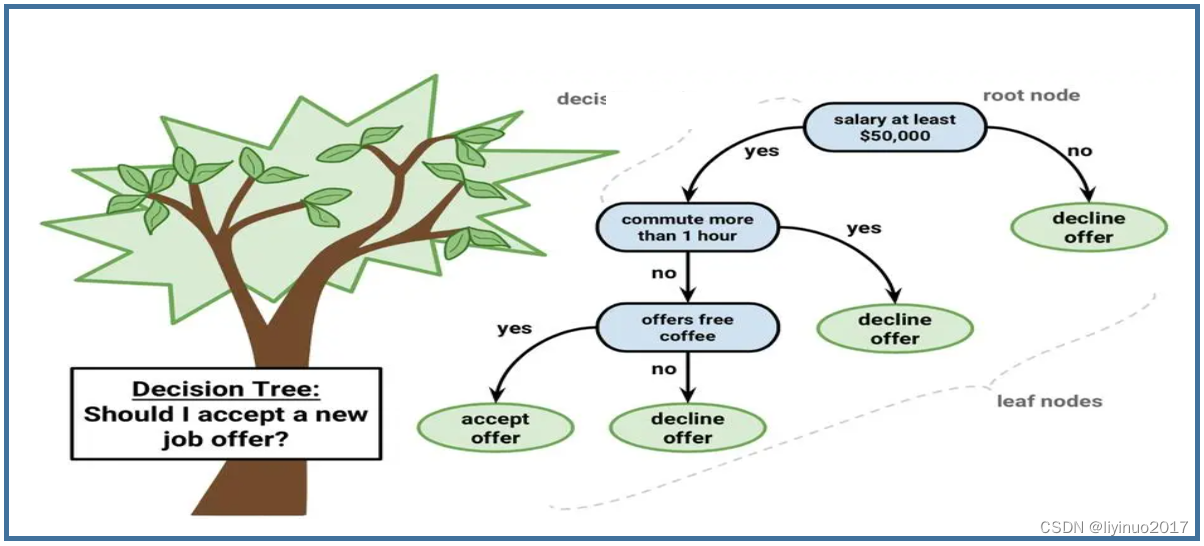
2.入门程序
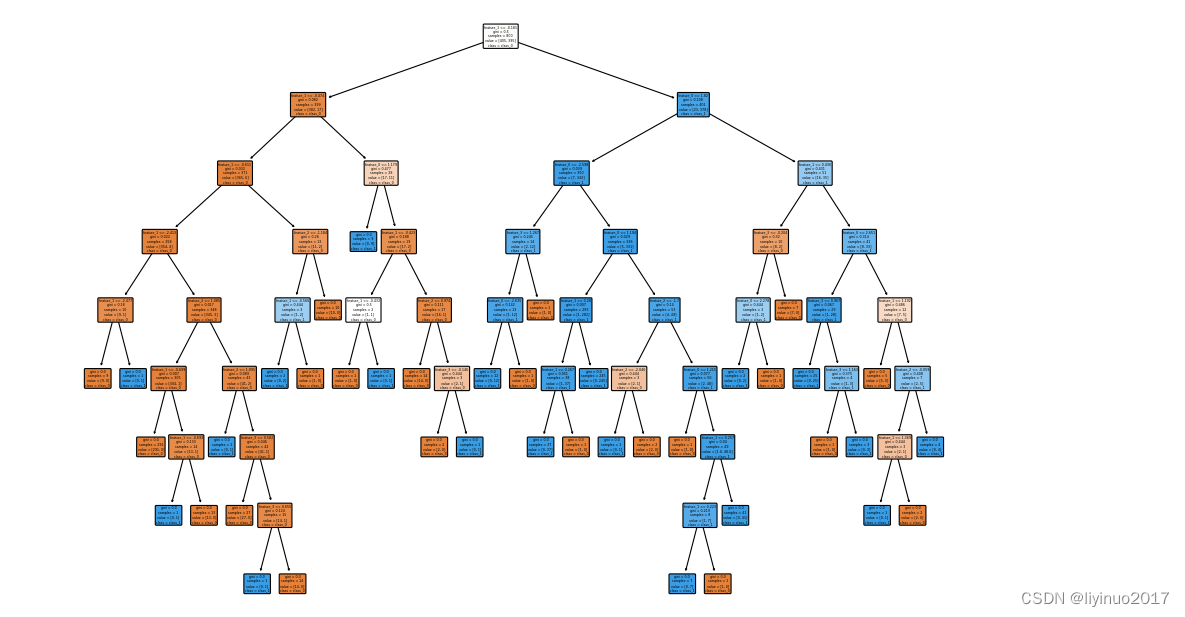
入门程序利用make_classification方法自动生成一组X和Y,其中X有4个特征。使用DecisionTreeClassifier方法建立一个决策树模型,训练模型后,提取模型特征,最后使用 plot_tree 函数可视化决策树的结构。
程序如下:
csharp
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 生成分类数据集
X, y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, shuffle=False)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树分类器
clf = DecisionTreeClassifier(random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 获取特征重要性
importances = clf.feature_importances_
indices = np.argsort(importances)[::-1]
# 打印特征排名
print("Feature ranking:")
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
# 绘制特征重要性
plt.figure()
plt.title("Feature importances")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), [f"Feature {i+1}" for i in indices])
plt.xlim([-1, X.shape[1]])
plt.show()
# 使用 plot_tree 函数可视化决策树的结构
fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(14, 10), dpi=80)
plot_tree(clf,
feature_names=['feature_{}'.format(i) for i in range(X.shape[1])],
class_names=['class_0', 'class_1'],
filled=True, rounded=True,
ax=axes)
plt.show()程序运行结果如下 :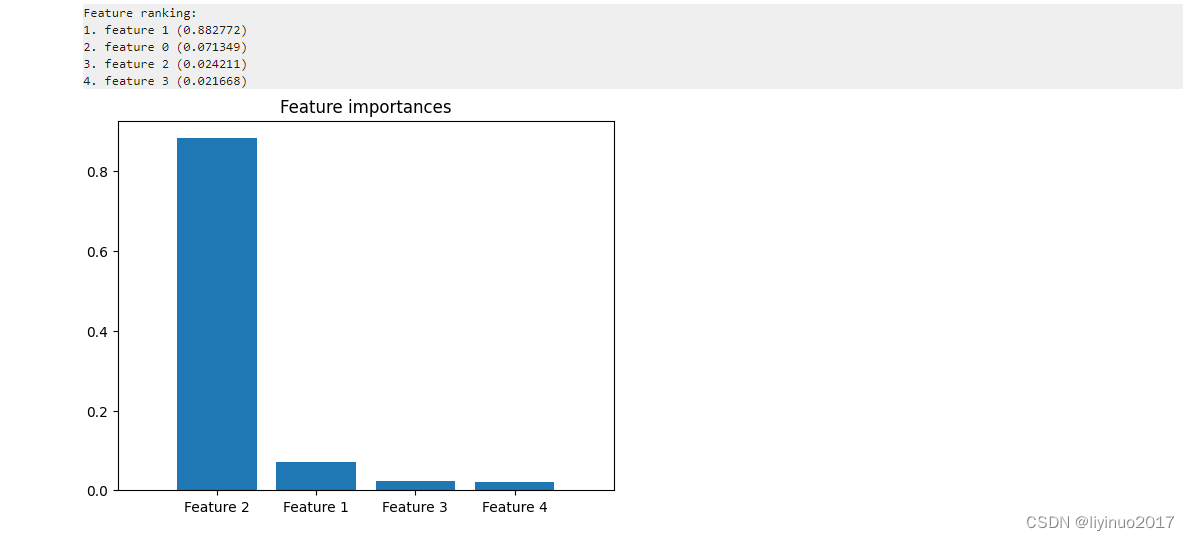
3.进阶实战
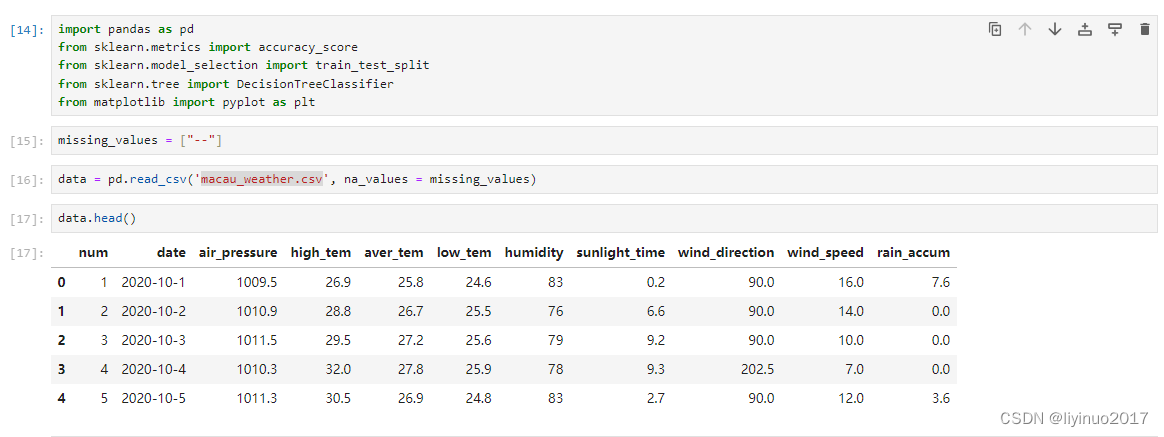
本实战程序的目的是:根据气象环境数据预测是否会下雨。利用数据表macau_weather.csv中的数据进行训练和测试。
(希望获取源码和测试数据的朋友请在评论区留言)
step1
读取macau_weather.csv中的数据,并可视化数据,根据可视化结果可知数据表中有以下数:
num、date、air_pressure、high_tem、aver_tem、low_tem、 humidity、sunlight_time 、wind_direction、wind_speed、rain_accum
其中rain_accum为目标值(标签:有雨、无雨),以下七个数据为特征变量:
air_pressure、high_tem、aver_tem、low_tem 、humidity、sunlight_time 、wind_direction、wind_speed
step2
数据表中的一共有426组数据(来源于426天的气象数据记录),检查每组数据是否完整,根据检查结果可知有0.7%的数据存在空缺
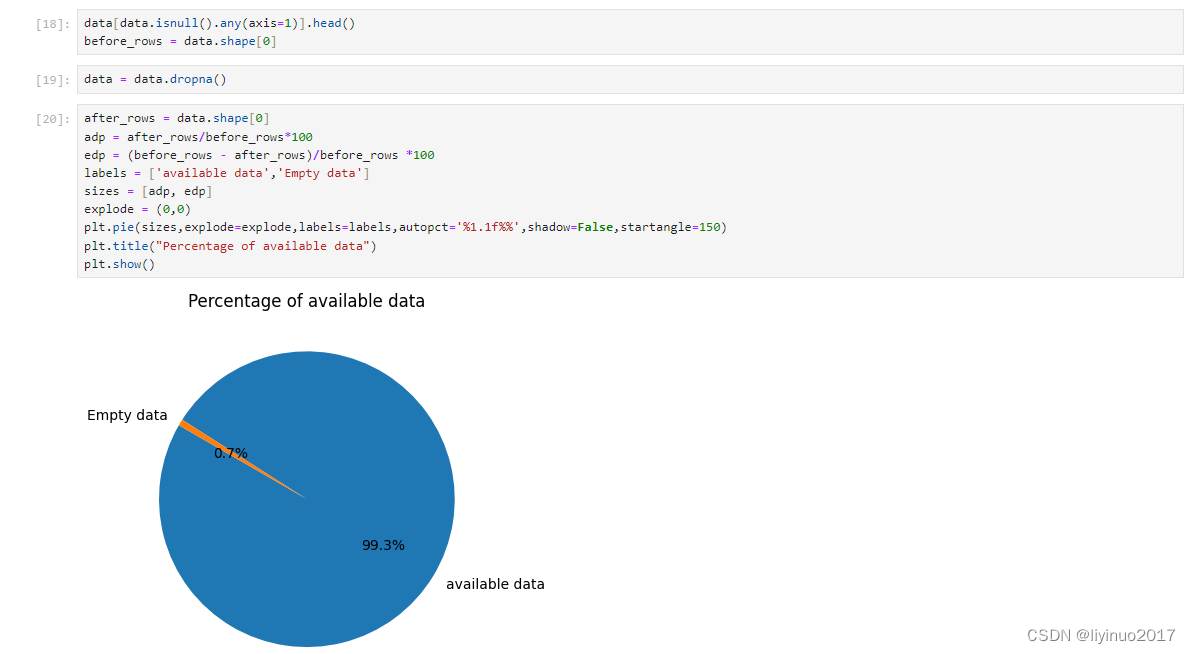
step3
将数据表中的rain_accum转换成1和0,0代表无雨1代表有雨。
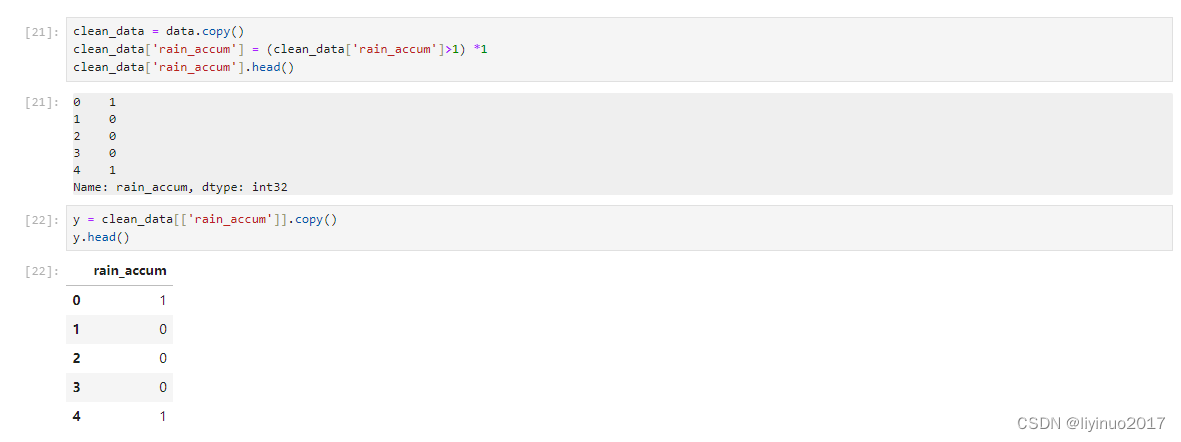
step4
使用DecisionTreeClassifier方法建立决策树模型,利用训练集数据训练模型。
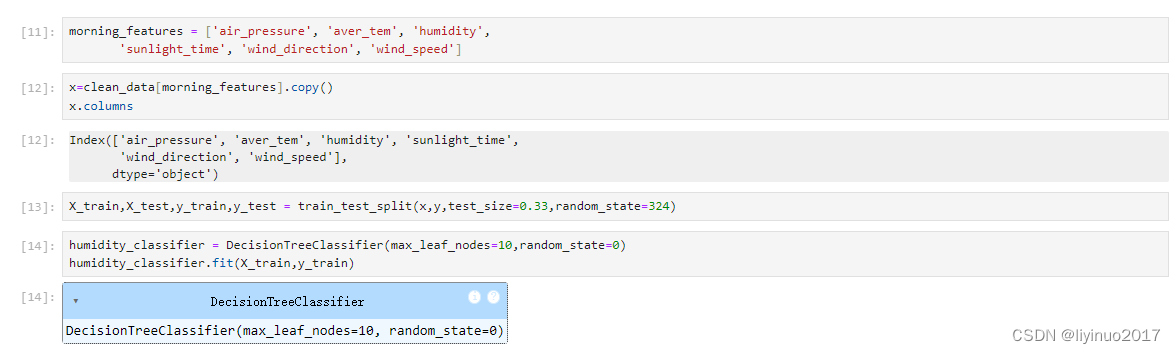
step5
利用模型和测试集数据,测试模型准确性,并可视化结果,根据可视化图标可知模型预测的准确性达到了87.1%。
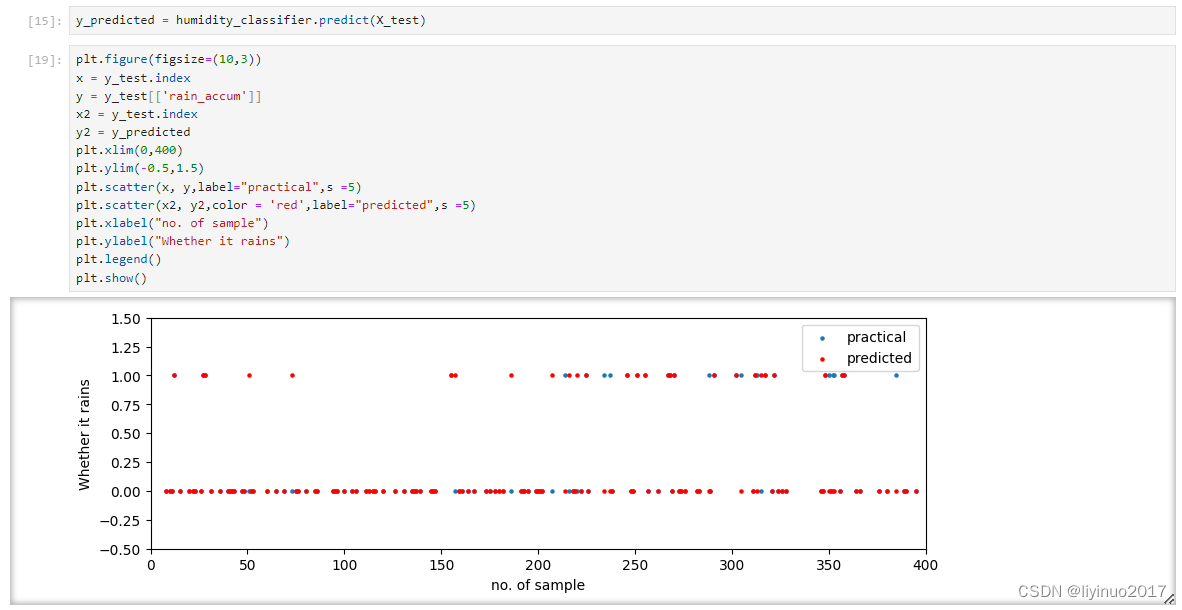
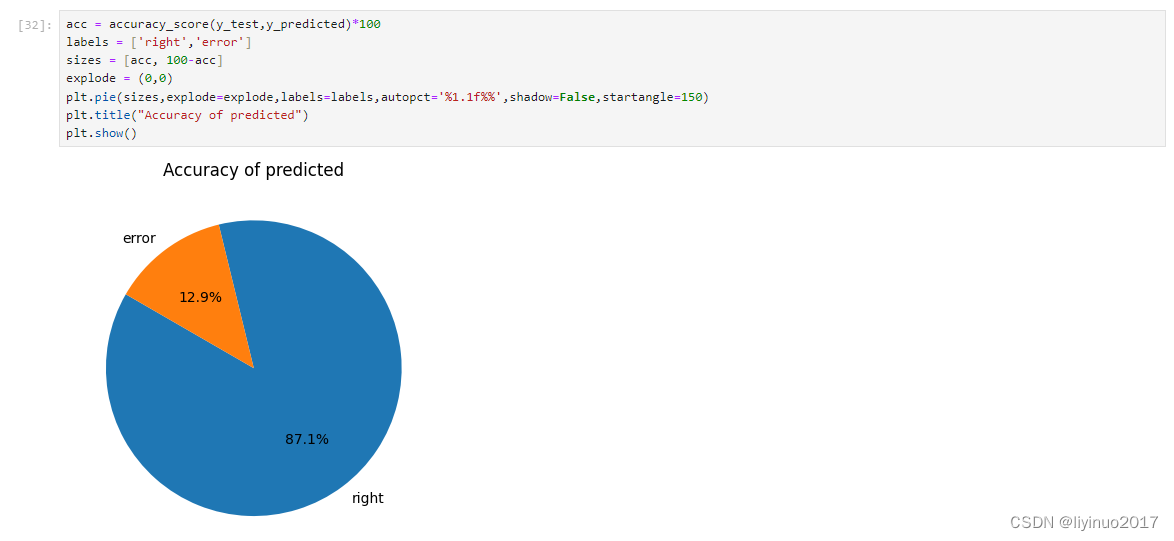
希望获取源码和测试数据的朋友请在评论区留言
创作不易希望朋友们点赞,转发,评论,关注!
您的点赞,转发,评论,关注将是我持续更新的动力!
CSDN:https://blog.csdn.net/li_man_man_man
今日头条:https://www.toutiao.com/article/7149576260891443724